



 文章讨论了内核抢占模型的发展历程,从最初的不支持抢占到全抢占,以及实时抢占带来的问题。作者提出采用延迟抢占策略,让调度器控制CPU决策,以平衡吞吐量和实时任务性能。概念验证显示该方案可能有效,但仍面临体系结构支持和调度器优化的挑战。
文章讨论了内核抢占模型的发展历程,从最初的不支持抢占到全抢占,以及实时抢占带来的问题。作者提出采用延迟抢占策略,让调度器控制CPU决策,以平衡吞吐量和实时任务性能。概念验证显示该方案可能有效,但仍面临体系结构支持和调度器优化的挑战。
关注了就能看到更多这么棒的文章哦~
Revisiting the kernel's preemption model, part 2
By Jonathan Corbet
October 2, 2023
ChatGPT translation
https://lwn.net/Articles/945422/
在上周的内容中,有介绍了一个需要抢占执行长时间指令的内核代码的情况,其引发了对内核处理抢占的方式进行更深入的重新审视。内核支持多种抢占模式,从“none”(内核代码完全不可抢占)到realtime(内核几乎总是可抢占)。更好地利用内核的抢占机制似乎是解决眼下这个问题的解决方案,但似乎还有更好的选择。简而言之,内核开发人员希望让调度器(scheduler)完全控制CPU调度决策。
How we got here
对话的转折点是由Thomas Gleixner的这条消息引发的,他先回顾了事物发展过程。最初,不支持内核代码的抢占,就像在旧的Unix系统中一样。随着观察到问题之后,开始把 cond_resched() 调用分散放置到内核观察到(或怀疑)运行时间过长并导致问题的代码路径上去。每个这种调用都是给调度程序(scheduler)的一个信号,告诉它如果需要可以切换到另一个线程。
后来,内核获得了"自愿抢占"功能,将数百个现有的 might_sleep() 调用转化为额外的调度点。添加这些调用是作为一种调试辅助工具,用于捕获从不可睡眠上下文中调用潜在休眠函数的情况;它们表示这个地方是可以重新调度,但并不是表示这个地方非常适合发起重新调度。这些调用之所以被使用,是因为它们已经存在,并且方便用于此目的。
后来,全抢占(full preemption)使内核可以在任意点被抢占,实时抢占(realtime preemption)可以让(大多数)持有锁的代码也可以被抢占。
Gleixner称,这个发展过程,恰恰展示了用错误的方式来解决一个问题的过程:
这里的方法是:阻止调度程序做决策,然后通过启发式方法来减轻后果。
这是错误的,因为它将资源控制从调度程序移出到没有权利控制资源的随机代码中。
他指出,实时抢占工作多年前也遇到了类似的问题。使内核代码在持有锁时也可以被抢占,对于改善latency(这是实时工作的重点)是有好处的,但在吞吐量方面会带来代价。在任何时候都可以发生抢占时,锁的争抢问题就变得更加严重。通常,一个线程会导致另一个线程变为可运行状态(runnable),此时新线程将抢占第一个线程。但如果第一个线程持有新线程所需要的锁,那么就会导致马上停下来,发生一个上下文切换。这会降低性能。
在这种情况下,最好避免在第一个线程持有锁时进行抢占。在realtime方案里,是通过引入"延迟抢占(lazy preemption)"来解决这个问题。这段代码尚未进入mainline内核,它的目的就是希望避免在一个非实时任务会抢占另一个非实时任务的情况下发生过多的抢占。如果当前运行的任务持有一个锁,那么调度器将设置一个"延迟抢占"标志,而不是立即抢占该任务。一旦锁被释放了,就可以进行抢占了。Gleixner表示,这个改动把那些关注吞吐量的任务的性能恢复了不少回来,并且不会损害实时任务的响应时间。
现在正在讨论的问题类似:启用一个完全可抢占的内核,而不损害那些关注吞吐量的任务的性能,其中许多任务在启用自愿抢占(voluntary preemption)或根本不抢占内核(no kernel preemption at all)时表现更好。Gleixner表示,解决方案可以是采用跟realtime工作中的方案类似的方法。
Lazy preemption for the mainline
要更好地理解提出的方案,如果有一些简要背景可能会有所帮助。当内核配置为完全抢占(full preemption)时,它维护了一个"抢占计数(preemption count)",简单来说是用来跟踪任何一个时刻阻止当前任务抢占的情况。其操作在LWN相关文章中有所描述,其中包括这个图表:
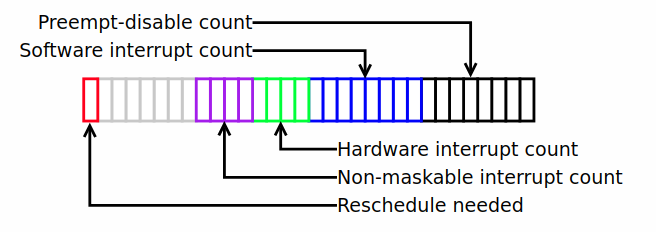
每当发生某些事情需要阻止抢占时,例如调用 preempt_disable() 或中断到来,抢占计数的相应的子字段就会递增。当不再满足该条件时,例如调用 preempt_enable() 时,计数就会递减。每当计数降至零时,内核就知道可以调用调度程序来决定哪个任务此刻对CPU有最高的需求。
然而,调用调度器的开销是很大的,因此最好在没有更改正在运行的任务时避免发起这些调用。避免这些调用,就是 "需要重新调度(reschedule needed)" 这个bit的作用。该位具有反向意义;如果设置了它,那么不需要重新调度。只要该位设置了,抢占计数就不会为零,不会进行任何到调度器的调用。当发生需要重新调度的情况,例如唤醒了更高优先级的任务时,该位可以被清除,并且等到其余计数降至零的时候,调度器就会被调用。
在非抢占内核中,唯一可以强制进行重新调度的事情就是当前任务的时间片到期。这种行为对于面向吞吐量的工作负载是有益的,允许任务在相对长的时间内不被打断持续运行。但是存在限制,让任务运行超过其时间片可能会导致latency问题。长时间运行的内核代码可能会导致这种情况发生;避免此问题是将 cond_resched() 调用放在长时间运行的内核函数中的动机。由于内核无法被抢占,它必须选择在这种情况下放弃CPU。
Gliexner的提议是希望在完全可抢占的内核中保留这种行为。在他的理想世界中,调度器会将删除现有的无抢占和自愿抢占模式;只剩下完全抢占。抢占计数的维护会始终进行,就像大多数发行版现在使用的 PREEMPT_DYNAMIC 模式一样。但会有一个小小的调整:如果系统配置为更加关注吞吐量,那么通常会清除"reschedule needed"这个bit的代码路径只有在当前时间片用尽的情况下才会执行清除操作。否则,将会设置一个独立的"reschedule eventually" bit,该bit不包含在抢占计数内。
这个改变将导致当前任务在其时间片剩余一部分的情况下继续执行,哪怕有另一个具有足够高优先级来抢占它的任务也是一样。这个行为只有少数几个地方例外,比如在返回到用户空间之前的系统调用中可能会发生抢占,这种情况哪怕在当前不支持抢占的内核中也可能发生。此时将会检查"reschedule eventually" bit,从而导致可能切换到另一个任务。
在内核中,任务可能被抢占的另一个时机是在调度器中断发生时。如果调度器注意到当前任务的时间片已经耗尽,它将检查"reschedule eventually"标志位。如果该标志被设置,那么"reschedule needed"标志位将被清除,抢占计数将降为零,然后在下一个机会就发生抢占。
相反,如果系统配置为低延迟模式,例如用于桌面应用,那么将不使用"reschedule eventually"标志位,内核将完全支持抢占。
通过这种方式重新设计调度程序,Gleixner 表示可以删除大量实现其他抢占模式的代码,这些代码似乎并没有得到广泛的使用。这将允许去除大约1,400个"cond_resched()"调用,并让调度器完全负责CPU调度决策。如果这一解决方案能够实现,那么它看起来将显著改进内核目前的工作方式。
Makeing it work
这个方案能够成功吗?Gleixner在制定了一个概念验证实现并测量了其性能后,认为可以。“如果这个验证合理,验证结果让我非常有信心,那么现在就是一个机会,可以用100到200行可理解的代码来替代约3000行不堪入目的代码。”Linus Torvalds表示同意:“我认为你已经证明了这个概念”。
当然,从概念验证实现到成为生产内核发布的重新设计的调度程序之间还有一些工作要做。至少存在两个障碍。首先,有四种体系结构(alpha、hexagon、m68k和um(用户模式Linux))不支持抢占计数机制;目前的情况是,它们将无法支持新的调度程序。Matthew Wilcox迅速提出建议,认为这个问题更加可以推动这些体系结构被删除了,但实际上增加抢占计数的支持可能不是很难。
另一个问题是,CPU调度器是一个微妙且复杂的东西,Gleixner实际上并不是一个调度器开发人员。这里肯定会出现性能问题,需要适当的技能来解决。Gleixner已经明确表示,他不具备解决这些问题的技能:
"这是我想展示的所有内容,我不打算再花更多的时间在这上面,因为我已经有太多其他事情要处理,而且由此产生的调度程序问题显然超出了我的专业领域。
尽管如此,我对任何试图通过在其中添加更多的"cond*()"等修补措施来进一步改进 preempt=NONE 模型的尝试表示永久反对。
因此,换句话说,简化和改进调度程序的路径已经铺平,但为了实现这一目标,其他人将不得不推动这项工作的完成。截至目前,还没有人站出来承担这个角色。情况可能会改变,但不应指望立即用上这个重新设计过的调度器;这是一种需要一段时间才能慢慢解决的改动。不过,一旦实现了这一点,好处应该是相当大的。
全文完
LWN 文章遵循 CC BY-SA 4.0 许可协议。
欢迎分享、转载及基于现有协议再创作~
长按下面二维码关注,关注 LWN 深度文章以及开源社区的各种新近言论~


















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









