



 文章介绍了Linux内核直接映射(direct-map)在64位系统中处理内存访问的问题,尤其是碎片化导致的性能影响。MikeRapoport的补丁集引入了__GFP_UNMAPPED标志,以减少内核通过pageallocator分配内存时对direct-map的碎片化。这种方法通过缓存未映射页面,集中分配,以减轻碎片并提高性能,尤其是在频繁加载BPF程序的系统中。
文章介绍了Linux内核直接映射(direct-map)在64位系统中处理内存访问的问题,尤其是碎片化导致的性能影响。MikeRapoport的补丁集引入了__GFP_UNMAPPED标志,以减少内核通过pageallocator分配内存时对direct-map的碎片化。这种方法通过缓存未映射页面,集中分配,以减轻碎片并提高性能,尤其是在频繁加载BPF程序的系统中。
关注了就能看到更多这么棒的文章哦~
Reducing direct-map fragmentation with __GFP_UNMAPPED
By Jonathan Corbet
March 20, 2023
DeepL assisted translation
https://lwn.net/Articles/926020/
内核的直接映射(direct map)使得 kernel 可以在自己的地址空间内访问到系统中所有物理内存,至少在 64 位系统上是这样。这个看似简单的功能现在被证明是很难持续维护的,难以在保证当前系统要求的情况下同时保持良好的性能。解决这个问题的最新一个尝试就是 Mike Rapoport 的一组补丁集,为内核的 page allocator 可以更好里支持 direct-map。
Direct-map fragmentation
在一个系统的运行过程中,内核很可能最终需要访问几乎每一个内存 page;如果不出意外的话,它需要加载可执行程序的代码段(executable text),并在把匿名页(anonymous page)交给用户空间进程之前进行清理。direct-map 对于这项工作显然是有用的,有很多系统因为缺乏足够的地址空间所以无法支持完整的 direct-map,它们所面临的困难就可以让我们意识到 direct-map 多么有用。内核的大部分操作(包括其内部大部分的内存访问),都是使用 direct-map 的地址,而不是为内核空间单独创建一个映射。
因此,对 direct-map 的高效访问是很重要的;它的管理方式可以给访问的效率带来很大影响。为了理解这个问题,可以快速复习一下 page-table (页表)的工作原理。虽然页表看起来像一个简单的线性数组,用来把 page-frame 编号映射到物理页上去,但实践中并不能采用这种方式;相反,页表是作为一个稀疏的层次结构(sparse hierarchy)实现的。下面是 2013 年 LWN 文章中首次使用的解释虚拟地址的简单图示:
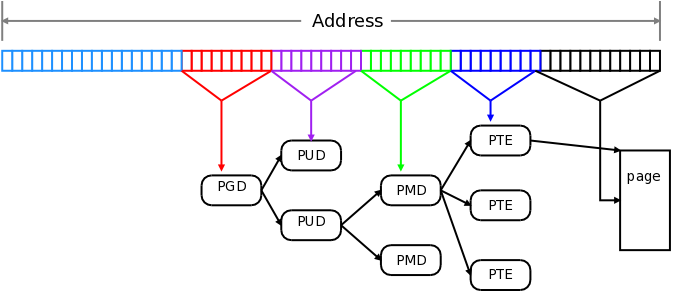
[虚拟地址转换]
这张图显示了四层页表:页全局目录(PGD, page global directory)、页上层目录(PUD,page upper directory)、页中层目录(PMD, page middle directory)和页表项(PTE, page-table entry)。目前的系统可以在 PGD 和 PUD 之间增加第五层,名为 P4D。虚拟地址的翻译解析涉及到层级结构的每一级;如果相关的数据不在处理器的 cache 中,这个过程可能需要花费很长时间。为了提高性能,处理器有一个 translation lookaside buffer(TLB),用于 cache 少量最近翻译的结果地址。如果在 TLB 中找到了这个地址,就可以避免遍历页表了;因此,提高 TLB 命中率可以显著提高系统的性能。
提高 TLB 使用率的一个方法是使用 huge page。一个 huge page 就是在一个更高级别的目录(PMD 或 PUD)中有一个特殊的条目,表示地址翻译在这里就可以停止。一个 PMD 级的 huge page(在大多数架构上)大小是 2MB;一个 PMD 级的 huge page 可以取代 512 个 PTE 级("base")page,所有这些都可以通过一个 TLB 条目来访问到。通常一个 PUD 级的 huge page 可以支持 1GB 的空间,进一步扩大了 TLB 条目的涵盖范围。
内核的 direct-map 是使用 huge page 创建的,从而减少内核空间代码所占用的 TLB 空间,这个效果完全可以测量出来。但是有一个问题:某个 huge page 是由相应的 page directory 中的一个条目来管理的,这意味着整个 page 都使用同样的访问权限。如果内核需要改变一个 huge page 中某些 base page 的权限,就必须先将这个 huge page 分解成较小的 page,这样就会在访问性能上出现损失。
越来越多的内核开发者发现他们需要改变 direct-map 的权限。例如,各种地址空间隔离机制可能会将一些 page 从 direct-map 中完全移除,从而避免被不必要地访问到。对既可写又可执行的 page 越来越严格禁止,这意味着,如果内核需要将可执行的代码加载到它的地址空间,它必须将包含了目标内存区域的那些 huge page 分割开,以便删除写入权限并且添加可执行权限;例如,当内核模块和 BPF 程序被加载时就会发生这种情况。
分割一个 huge page 来加载一个 module 或 BPF 程序,或者对一些内存进行隔离,这些并不是什么大麻烦。但是,随着系统的运行,这种情况可能会反复发生,随着时间的推移,direct-map 会变得碎片化。例如,在经常加载 BPF 程序的系统中,可能会看到 direct-map 出现了严重的碎片化,性能就会变得很糟糕。这个问题引出了一系列的工作,比如 BPF 程序专用的内存分配器,旨在将对 direct map 的影响降到最低。
Improving the page allocator
Rapoport 的 patch 通过增加一个新的分配 flag 也就是__GFP_UNMAPPED 来解决这个问题。当内核代码使用这个 flag 分配一个或多个 page 时,在返回给调用者之前,会被从直 direct map 中移除。不过,这里带来的好处不仅仅是从 direct map 中移除,而且还有 page allocator 为 __GFP_UNMAPPED 分配所维护的 cache。
当第一次出现这样的分配请求时,allocator 分配器将从 direct map 中移除一个 PMD 大小的 huge page,使用其中的一部分来满足请求,并保留其余部分以满足未来的请求。被释放的不在继续 map 的 page 也会被保留在该缓存中。这样一来,这些特殊的请求就会被集中在同一块内存区域,避免了 direct map 整体的碎片化。还有一个必不可少的 shrinker 工作,会在内存紧张时被调用,从而把__GFP_UNMAPPED 缓存中的 page 都释放给内核其他地方使用。
这组 patch 包括了这个新功能的两处使用地点。其中之一是在 x86 的 module_alloc()实现中,它为 loadable kernel module 分配空间。另一个是在 memfd_secret()的实现中,它会将分配的空间从 direct-map 中完全移除,使其不能被内核访问。
patch 中没有提供基准测试结果,所以现在还不能真正量化它对系统性能有多少改善。不管怎样,性能影响会严重依赖于工作负载。但是,这里正在解决的问题已经进行了深入的分析,而且 direct map 的碎片影响在过去就已经被测量出来过了。因此,基本可以确定会有某种解决方案需要被合并进来。这次的最新的尝试是否就是那个最终解决方案,这还有待观察。很可能这是即将举行的 LSFMM/BPF 会议要解决的问题之一。
全文完
LWN 文章遵循 CC BY-SA 4.0 许可协议。
欢迎分享、转载及基于现有协议再创作~
长按下面二维码关注,关注 LWN 深度文章以及开源社区的各种新近言论~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









