




 本文详细介绍如何使用Selenium进行自动化测试,包括安装配置Selenium、ChromeDriver,通过Python脚本控制浏览器操作,以及使用WebDriverWait和XPath定位元素,实现页面加载等待和元素查找的高级技巧。
本文详细介绍如何使用Selenium进行自动化测试,包括安装配置Selenium、ChromeDriver,通过Python脚本控制浏览器操作,以及使用WebDriverWait和XPath定位元素,实现页面加载等待和元素查找的高级技巧。
anaconda prompt
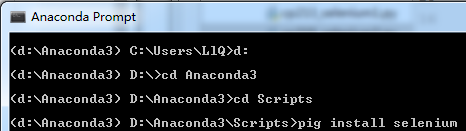
go to scripts to install: pip install selenium
check your chrome version
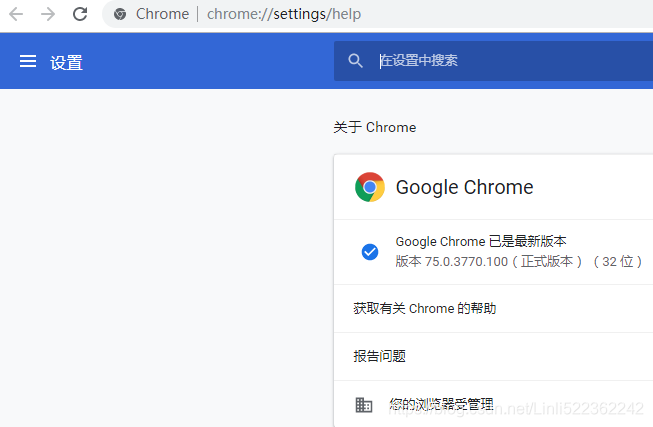
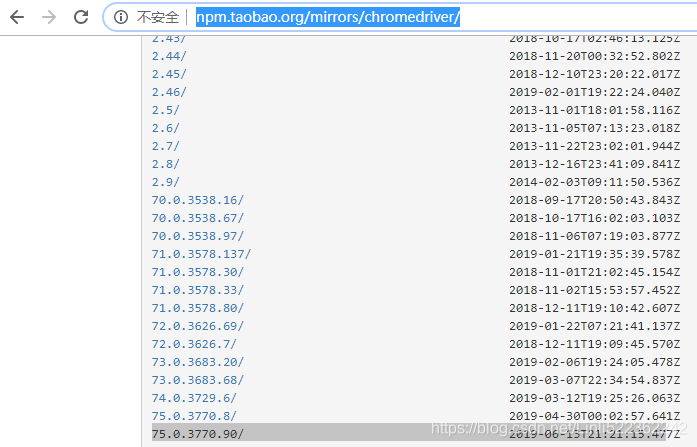
Then go to http://npm.taobao.org/mirrors/chromedriver/
for downloading chromedriver

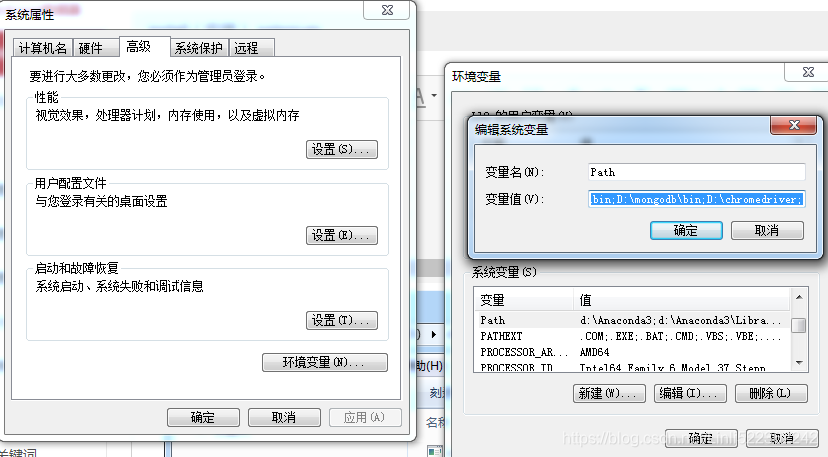
Add the folder director to system environment's "Path"
###########################################################################################
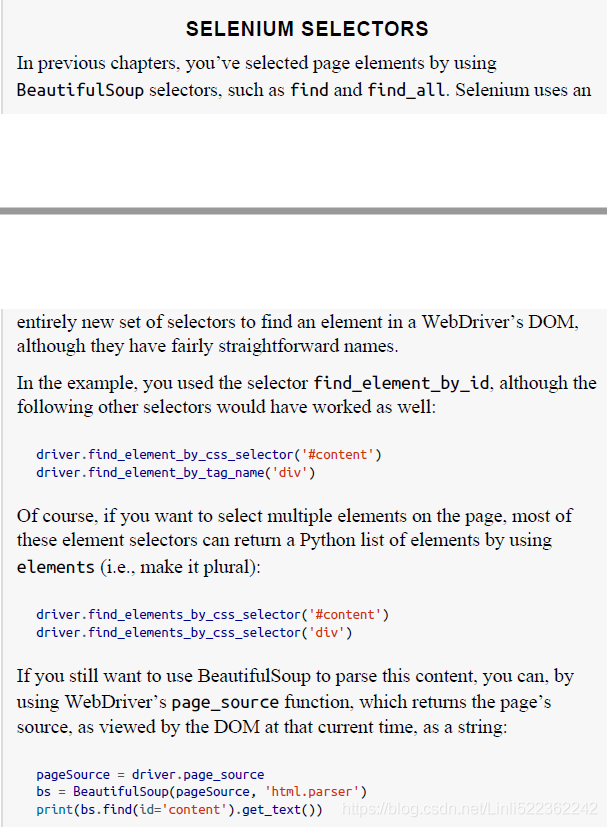
Example 1:


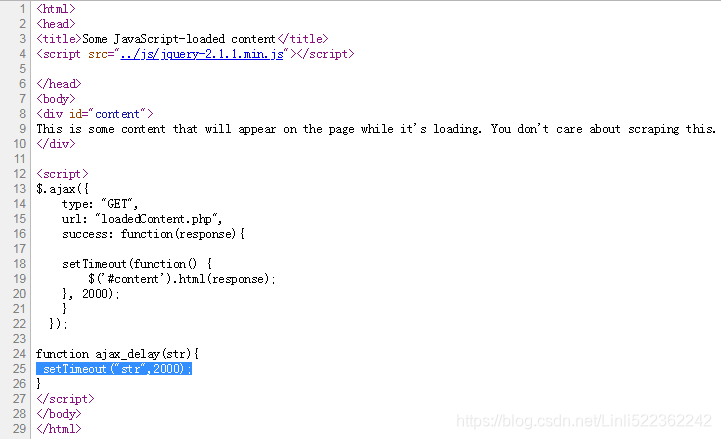
from selenium import webdriver
import time
# driver = webdriver.PhantomJS(executable_path='D:/phantomjs-2.1.1-windows/bin/phantomjs')
driver = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver')
driver.get("http://pythonscraping.com/pages/javascript/ajaxDemo.html")
time.sleep(1)
print(driver.find_element_by_id('content').text)
driver.close()
###########################################################################################
Example2:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver') driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html') try: # WebDriverWait and expected_conditions(EC), # both of which are combined here to form what Selenium calls an implicit wait. element = WebDriverWait(driver, 10).until( # locator is an abstract query language, using the By object, # which can be used in a variety of ways, including to make selectors. #<button id="loadedButton">A button to click!</button> EC.presence_of_element_located( (By.ID, 'loadedButton') ) ) finally: #<div id="content"> #print(driver.find_element(By.ID, "content").text) print(driver.find_element_by_id('content').text ) driver.close()
#improvement##########################


from selenium import webdriver
import time
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import StaleElementReferenceException
##
def waitForLoad(driver):
elem = driver.find_element_by_tag_name('html')###################
count = 0
while True:
count +=1
if count>20: #with a time-out of 10 seconds=20*0.5seconds = 10seconds
print('Timing out after 10 seconds and returning')
return
time.sleep(.5) #This script checks the page every half second
try:
#“watching” an element in the DOM when the page initially loads,
# and then repeatedly calling that element
elem == driver.find_element_by_tag_name('html')###################
except StateElementReferenceException:
#the element is no longer attached to the page’s DOM and the site has redirected
return
driver = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver')
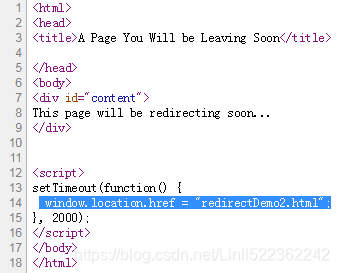
driver.get('http://pythonscraping.com/pages/javascript/redirectDemo1.html')
waitForLoad(driver)
print(driver.page_source)
################################################################################
#my favorite -- xpath
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
driver = webdriver.Chrome(executable_path='D:/chromedriver/chromedriver')
driver.get('http://pythonscraping.com/pages/javascript/redirectDemo1.html')
try:
# Here you’re providing it a time-out of 15 seconds
# and an XPath selector that looks for the page body content to accomplish the
# same task:
bodyElement = WebDriverWait(driver, 15).until(EC.presence_of_element_located(
(By.XPATH, '//body[contains( text(), "This is the page you are looking for!" )]')
) )
print(bodyElement.text)
except TimeoutException:
print('Did not find the element')



















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









