






 本文介绍了在微服务架构中,如何利用Prometheus监控业务指标,包括Logging、Metrics和Tracing三支柱的作用,重点讲解了如何通过Prometheus的Counter、Gauge和Histogram类型指标来监控和管理任务运行状态、请求量和响应时间等业务层面的数据。
本文介绍了在微服务架构中,如何利用Prometheus监控业务指标,包括Logging、Metrics和Tracing三支柱的作用,重点讲解了如何通过Prometheus的Counter、Gauge和Histogram类型指标来监控和管理任务运行状态、请求量和响应时间等业务层面的数据。
Prometheus 监控业务指标
在 Kubernetes 已经成了事实上的容器编排标准之下,微服务的部署变得非常容易。但随着微服务规模的扩大,服务治理带来的挑战也会越来越大。在这样的背景下出现了服务可观测性(observability)的概念。
在分布式系统里,系统的故障可能出现在任何节点,怎么能在出了故障的时候快速定位问题和解决问题,甚至是在故障出现之前就能感知到服务系统的异常,把故障扼杀在摇篮里。这就是可观测性的意义所在。
可观测性
可观测性是由 logging, metrics, tracing 构建的, 简称为可观测性三支柱。
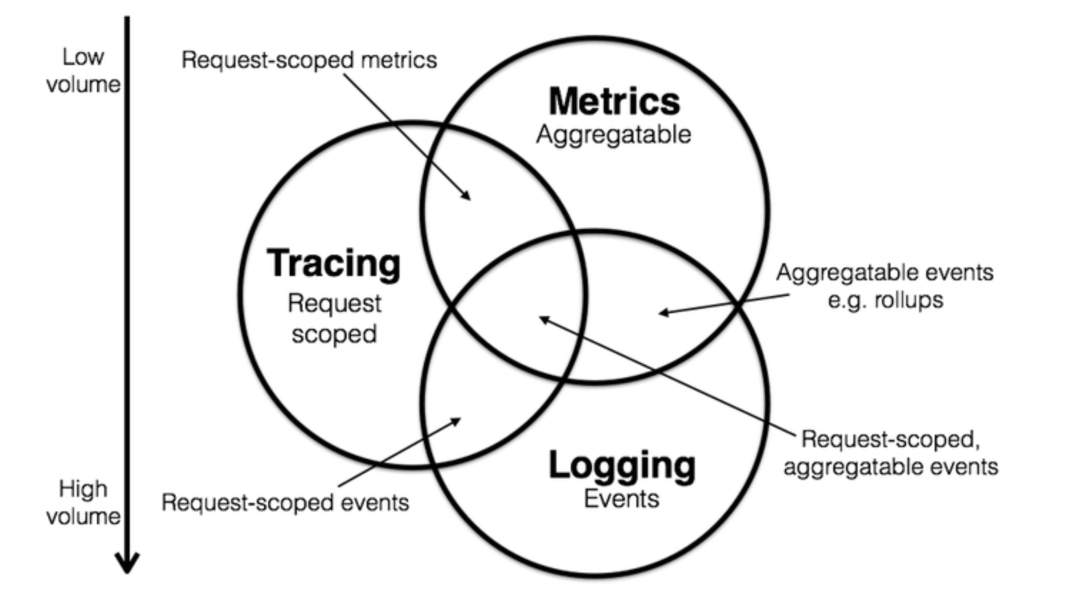
-
Lgging,展现的是应用运行而产生的事件或者程序在执行的过程中间产生的一些日志,可以详细解释系统的运行状态,但是存储和查询需要消耗大量的资源。所以往往使用过滤器减少数据量。
-
Metrics,是一种聚合数值,存储空间很小,可以观察系统的状态和趋势,但对于问题定位缺乏细节展示。这个时候使用等高线指标等多维数据结构来增强对于细节的表现力。例如统计一个服务的 TBS 的正确率、成功率、流量等,这是常见的针对单个指标或者某一个数据库的。
-
Tracing,面向的是请求,可以轻松分析出请求中异常点,但与 logging 有相同的问题就是资源消耗较大。通常也需要通过采样的方式减少数据量。比如一次请求的范围,也就是从浏览器或者手机端发起的任何一次调用,一个流程化的东西,我们需要轨迹去追踪。
这篇文章讨论的主题就是可观测性中的 metrics。在 k8s 作为基础设施的背景下,我们知道 K8s 本身是个复杂的容器编排系统,它本身的稳定运行至关重要。与之相伴的指标监控系统 Promethues 也已经成为了云原生服务下监控体系的事实标准。
相信大家对资源层面比如 CPU,Memory,Network;应用层面比如 Http 请求数,请求耗时等指标的监控都有所了解。那么业务层面的指标又怎么利用 Prometheus 去监控和告警呢?这就是这篇文章的核心内容。
以我们一个业务场景为例,在系统中有多种类型的 task 在运行,并且 task 的运行时间各异,task 本身有各种状态包括待执行、执行中、执行成功、执行失败等。如果想确保系统的稳定运行,我们必须对各个类型的 task 的运行状况了如指掌。比如当前是否有任务挤压,失败任务是否过多,并且当超过阈值是否告警。
为了解决上述的监控告警问题,我们先得了解一下 Prometheus 的指标类型
指标
指标定义
在形式上,所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
指标的名称(metric name)可以反映被监控样本的含义(比如,http_request_total - 表示当前系统接收到的HTTP请求总量)。指标名称只能由ASCII字符、数字、下划线以及冒号组成并必须符合正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名称只能由ASCII字符、数字以及下划线组成并满足正则表达式[a-zA-Z_][a-zA-Z0-9_]*。
指标类型
Prometheus定义了4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
Counter
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是 Counter 类型的监控指标。一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
通过 counter 指标我们可以和容易的了解某个事件产生的速率变化。
例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
Gauge
Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,我们可以直接查看系统的当前状态
node_memory_MemFree
Summary
Summary 主用用于统计和分析样本的分布情况。比如某 Http 请求的响应时间大多数都在 100 ms 内,而个别请求的响应时间需要 5s,那么这中情况下统计指标的平均值就不能反映出真实情况。而如果通过 Summary 指标我们能立马看响应时间的9分位数,这样的指标才是有意义的。
例如
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.# TYPE go_gc_duration_seconds summarygo_gc_duration_seconds{quantile="0"} 3.98e-05go_gc_duration_seconds{quantile="0.25"} 5.31e-05go_gc_duration_seconds{quantile="0.5"} 6.77e-05go_gc_duration_seconds{quantile="0.75"} 0.0001428go_gc_duration_seconds{quantile="1"} 0.0008099go_gc_duration_seconds_sum 0.0114183go_gc_duration_seconds_count 85
Histogram
Histogram 类型的指标同样用于统计和样本分析。与 Summary 类型的指标相似之处在于 Histogram 类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于 Histogram 指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。同时对于Histogram的指标,可以通过 histogram_quantile() 函数计算出其值的分位数。
例如
# HELP prometheus_http_response_size_bytes Histogram of response size for HTTP requests.# TYPE prometheus_http_response_size_bytes histogramprometheus_http_response_size_bytes_bucket{handler="/",le="100"} 1prometheus_http_response_size_bytes_bucket{handler="/",le="1000"} 1prometheus_http_response_size_bytes_bucket{handler="/",le="10000"} 1prometheus_http_response_size_bytes_bucket{handler="/",le="100000"} 1prometheus_http_response_size_bytes_bucket{handler="/",le="1e+06"} 1prometheus_http_response_size_bytes_bucket{handler="/",le="+Inf"} 1prometheus_http_response_size_bytes_sum{handler="/"} 29prometheus_http_response_size_bytes_count{handler="/"} 1
应用指标监控
暴露指标
Prometheus 最常用的方式是通过 pull 去抓取 metrics。所以我们首先在服务通过 /metrics 接口暴露指标,这样 Promethues server 就能通过 http 请求抓取到我们的业务指标。
接口示例
server := gin.New()server.Use(middlewares.AccessLogger(), middlewares.Metric(), gin.Recovery())server.GET("/health", func(c *gin.Context) {c.JSON(http.StatusOK, gin.H{ "message": "ok",})})server.GET("/metrics", Monitor)func Monitor(c *gin.Context) {h := promhttp.Handler()h.ServeHTTP(c.Writer, c.Request)}
定义指标
为了方便理解,这里选取了三种类型和两种业务场景的指标
示例
var (//HTTPReqDuration metric:http_request_duration_secondsHTTPReqDuration *prometheus.HistogramVec//HTTPReqTotal metric:http_request_totalHTTPReqTotal *prometheus.CounterVec// TaskRunning metric:task_runningTaskRunning *prometheus.GaugeVec)func init() {// 监控接口请求耗时// 指标类型是 HistogramHTTPReqDuration = prometheus.NewHistogramVec(prometheus.HistogramOpts{Name: "http_request_duration_seconds",Help: "http request latencies in seconds",Buckets: nil,}, []string{"method", "path"})// "method"、"path" 是 label// 监控接口请求次数// 指标类型是 CounterHTTPReqTotal = prometheus.NewCounterVec(prometheus.CounterOpts{Name: "http_requests_total",Help: "total number of http requests",}, []string{"method", "path", "status"}) // "method"、"path"、"status" 是 label// 监控当前在执行的 task 数量// 监控类型是 GaugeTaskRunning = prometheus.NewGaugeVec(prometheus.GaugeOpts{Name: "task_running",Help: "current count of running task",}, []string{"type", "state"})// "type"、"state" 是 labelprometheus.MustRegister(HTTPReqDuration,HTTPReqTotal,TaskRunning,)}
通过上述的代码我们就定义并且注册了我们的想要监控的指标。
生成指标
示例
start := time.Now()c.Next()duration := float64(time.Since(start)) / float64(time.Second)path := c.Request.URL.Path// 请求数加1controllers.HTTPReqTotal.With(prometheus.Labels{"method": c.Request.Method,"path": path,"status": strconv.Itoa(c.Writer.Status()),}).Inc()// 记录本次请求处理时间controllers.HTTPReqDuration.With(prometheus.Labels{"method": c.Request.Method,"path": path,}).Observe(duration)// 模拟新建任务controllers.TaskRunning.With(prometheus.Labels{"type": shuffle([]string{"video", "audio"}),"state": shuffle([]string{"process", "queue"}),}).Inc()// 模拟任务完成controllers.TaskRunning.With(prometheus.Labels{"type": shuffle([]string{"video", "audio"}),"state": shuffle([]string{"process", "queue"}),}).Dec()
抓取指标
Promethues 抓取 target 配置
# 抓取间隔scrape_interval: 5s# 目标scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['prometheus:9090']- job_name: 'local-service'metrics_path: /metricsstatic_configs:- targets: ['host.docker.internal:8000']
在实际应用中静态配置 target 地址不太适用,在 k8s 下 Promethues通过与 Kubernetes API 集成目前主要支持5种服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
指标展示如下图:
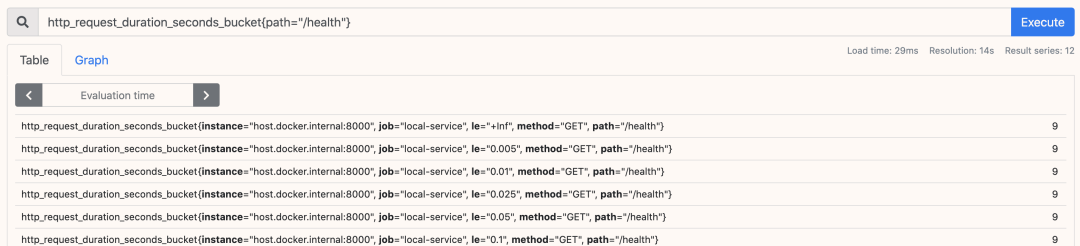

来源:https://www.lxkaka.wang/app-metrics/

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









