



近年来,随着加密货币行业的蓬勃发展,各种迷因币(meme coins)也在此浪潮之中纷纷崛起。然而,在专门用于创造迷因币的平台"pump.fun"上,绝大多数迷因币都无法真正成功发行和上市。
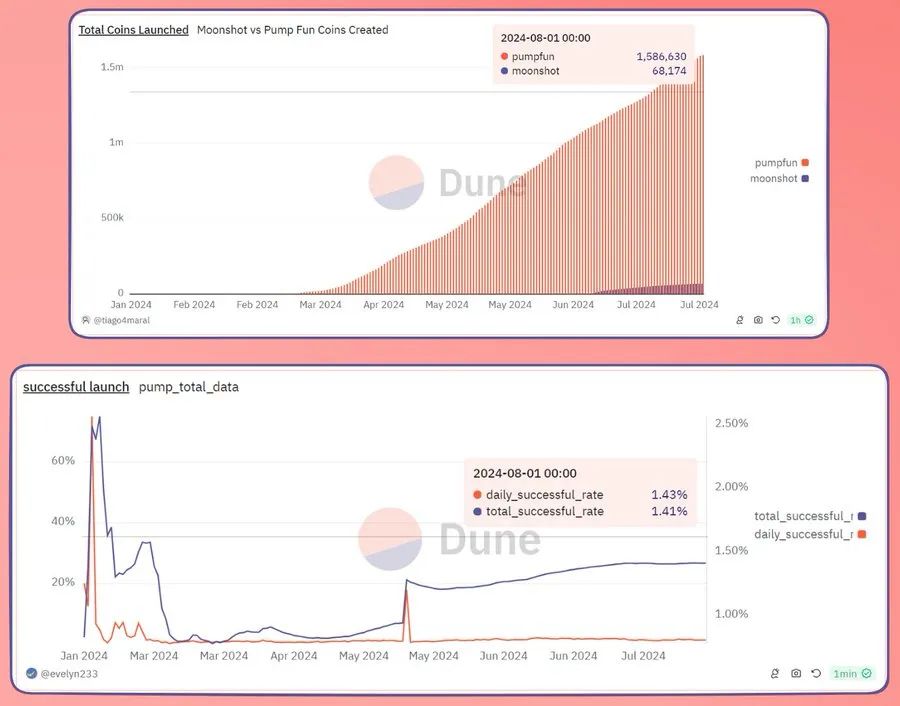
最新的数据显示,近日Solana迷因发行平台Pump.fun累计收益已突破8000万美元,但是却只有1.41%的代币能从发行平台成功进到去中心化交易所(DEX)交易。这些数据令人不禁思考,MEME币热潮是否正在走向终结?普通投资者是否仍可以通过MEME币发家致富?
Pump.fun允许任何人只要提供名称、代码和JPG图片即可快速部署迷因币,费用甚至低于2美元,且用户无需提供任何启动资金,流动池资金皆从社群筹集,一旦代币市值成功达到6.9万美元,12000美元的流动性将被自动存入Raydium并销毁LP代币。
根据Dune Analytics的数据,在"pump.fun"上创建的加密货币中,只有1.41%最终在Solana去中心化金融协议Raydium上上市交易。这一比例自5月以来一直徘徊在1.21%到1.41%之间,最高达到2.56%,发生在今年2月16日。也就是目前为止Pump.fun发行的代币总数为158万,其中只有22300个实际登上了Raydium。

对此,风投合伙人AdamCochran表示,成功率的定义是市值达到6.9万美元,并且成功上线去中心化交易所,而这个数值一直停滞在1.4%。与此同时,没有新的MEME币项目能够突破2000万美元的完全稀释估值(FDV,一种衡量加密货币在完全流通情况下的总价值的指标)门槛,这一切都表明MEME币的泡沫开始消退了。
有人附和并强调,这些迷因币战场绝对不是为了初学者所建立的,呼吁大家远离。创建MEME币绝对不是一条通往致富的捷径。与其将资金投入到那些不太可能成功的MEME币项目中,不如把精力集中在更有发展潜力的加密货币领域。毕竟,创业的成功率也不过10%左右,而MEME币项目的成功率竟然还不到2%。想要在加密货币市场中获得丰厚回报,需要长期的专注、充分的研究和审慎的决策。

然而,其他评论者认为这个成功率并不反映整体迷因币市场的情况。匿名加密货币评论员Bunjil认为,pump.fun并没有毁掉迷因币,这只是表明pump.fun使迷因币创造变得多么容易。
尽管只有少数代币成功推出,但这些代币为pump.fun带来了可观的费用收入。据了解,Pump.fun会收取1%的交易费,直到该代币达到一定的市值门槛。在某些时期,Pump.fun的收入甚至超过了以太坊(ETH)。DeFil Llama的数据显示,pump.fun在24小时内收取了约86.4万美元费用,比以太坊同期的55万美元高出约57%。
此外,pump.fun也在海外名人之间掀起一股热潮,包括跨性别媒体人CaitlynJenner、美国名人IggyAzalea、A咖杰森(JasonDerulo)等多位名人,从5月以来都使用自己的形象透过pump.fun创建并推广加密代币。

总的来说,当下的MEME热潮可能正在逐步退散,我们或将目睹迷因币市场的洗牌与重塑。这无疑给正在兴起的MEME热潮带来了一丝降温,引发了人们对于在加密世界中"一本万利"的再次思考。不过也有人坚持认为,迷因币仍然在加密货币生态系统中扮演着重要的角色。无论如何,未来MEME币市场是否还有其他发展空间,业内人士都需持谨慎态度。


















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











