






DPDK作为网络编程中比较火的一个工具包,必然有许多优势,值得一学。
参考资料:
https://www.jianshu.com/p/0ff8cb4deaef
Intel® DPDK技术
Intel® DPDK全称Intel Data Plane Development Kit,是intel提供的数据平面开发工具集,为Intel architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,它不同于Linux系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。目前已经验证可以运行在大多数Linux操作系统上,包括FreeBSD 9.2、Fedora release18、Ubuntu 12.04 LTS、RedHat Enterprise Linux 6.3和Suse EnterpriseLinux 11 SP2等。DPDK使用了BSDLicense,极大的方便了企业在其基础上来实现自己的协议栈或者应用。
需要强调的是,DPDK应用程序是运行在用户空间上利用自身提供的数据平面库来收发数据包,绕过了Linux内核协议栈对数据包处理过程。Linux内核将DPDK应用程序看作是一个普通的用户态进程,包括它的编译、连接和加载方式和普通程序没有什么两样。DPDK程序启动后只能有一个主线程,然后创建一些子线程并绑定到指定CPU核心上运行。
DPDK与传统网络协议栈处理对比
DPDK对从内核层到用户层的网络流程相对传统网络模块进行了特殊处理,下面对传统网络模块结构和DPDK中的网络结构做对比
传统linux网络层:
硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层
用户层收包-->网络层--->逻辑层--->业务层
dpdk网络层:
硬件中断--->放弃中断流程
用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
对比后总结
dpdk优势:
- 减少了中断次数。
- 减少了内存拷贝次数。
- 绕过了linux的协议栈,进入用户协议栈,用户获得了协议栈的控制权,能够定制化协议栈降低复杂度
dpdk劣势
- 内核栈转移至用户层增加了开发成本.
- 低负荷服务器不实用,会造成内核空转.
DPDK的组成
DPDK核心组件由一系列库函数和驱动组成,为高性能数据包处理提供基础操作。内核态模块主要实现轮询模式的网卡驱动和接口,并提供PCI设备的初始化工作;用户态模块则提供大量给用户直接调用的函数。
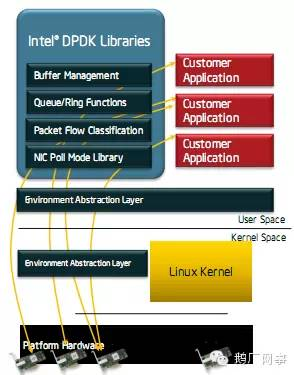
图3 DPDK架构图
EAL(Environment Abstraction Layer)即环境抽象层,为应用提供了一个通用接口,隐藏了与底层库与设备打交道的相关细节。EAL实现了DPDK运行的初始化工作,基于大页表的内存分配,多核亲缘性设置,原子和锁操作,并将PCI设备地址映射到用户空间,方便应用程序访问。
Buffer Manager API通过预先从EAL上分配固定大小的多个内存对象,避免了在运行过程中动态进行内存分配和回收来提高效率,常常用作数据包buffer来使用。
Queue Manager API以高效的方式实现了无锁的FIFO环形队列,适合与一个生产者多个消费者、一个消费者多个生产者模型来避免等待,并且支持批量无锁的操作。
Flow Classification API通过Intel SSE基于多元组实现了高效的hash算法,以便快速的将数据包进行分类处理。该API一般用于路由查找过程中的最长前缀匹配中,安全产品中根据Flow五元组来标记不同用户的场景也可以使用。
PMD则实现了Intel 1GbE、10GbE和40GbE网卡下基于轮询收发包的工作模式,大大加速网卡收发包性能。

图4 DPDK的核心组件
图4展示了DPDK核心组件的依赖关系,详细介绍可以参考《Intel Data Plane Development kit:Software Architecture Specification》。
DPDK的核心技术
PMD
当前Linux操作系统都是通过中断方式通知CPU来收发数据包,我们假定网卡每收到10个据包触发一次软中断,一个CPU核心每秒最多处理2w次中断,那么当一个核每秒收到20w个包时就占用了100%,此刻它没做其它任何操作。
DPDK针对Intel网卡实现了基于轮询方式的PMD(Poll Mode Drivers)驱动,该驱动由API、用户空间运行的驱动程序构成,该驱动使用无中断方式直接操作网卡的接收和发送队列(除了链路状态通知仍必须采用中断方式以外)。目前PMD驱动支持Intel的大部分1G、10G和40G的网卡。
PMD驱动从网卡上接收到数据包后,会直接通过DMA方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理数据包,这个过程非常简洁。如果要是让Linux来处理收包过程,首先网卡通过中断方式通知协议栈对数据包进行处理,协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否本机的socket,满足条件则会将数据包拷贝一份向上递交给用户socket来处理,不仅处理路径冗长,还需要从内核到应用层的一次拷贝过程。
大页表
为实现物理地址到虚拟地址的转换,Linux一般通过查找TLB来进行快速映射,如果在查找TLB没有命中,就会触发一次缺页中断,将访问内存来重新刷新TLB页表。Linux下默认页大小为4K,当用户程序占用4M的内存时,就需要1K的页表项,如果使用2M的页面,那么只需要2条页表项,这样有两个好处:第一是使用hugepage的内存所需的页表项比较少,对于需要大量内存的进程来说节省了很多开销,像oracle之类的大型数据库优化都使用了大页面配置;第二是TLB冲突概率降低,TLB是cpu中单独的一块高速cache,一般只能容纳100条页表项,采用hugepage可以大大降低TLB miss的开销。
DPDK目前支持了2M和1G两种方式的hugepage。通过修改默认/etc/grub.conf中hugepage配置为“default_hugepagesz=1Ghugepagesz=1G hugepages=32 isolcpus=0-22”,然后通过mount –thugetlbfs nodev /mnt/huge就将hugepage文件系统hugetlbfs挂在/mnt/huge目录下,然后用户进程就可以使用mmap映射hugepage目标文件来使用大页面了。测试表明应用使用大页表比使用4K的页表性能提高10%~15%。
CPU亲缘性
多线程编程早已不是什么新鲜的事物了,多线程的初衷是提高整体应用程序的性能,但是如果不加注意,就会将多线程的创建和销毁开销,锁竞争,访存冲突,cache失效,上下文切换等诸多消耗性能的因素引入进来。这也是Ngnix使用单线程模型能获得比Apache多线程下性能更高的秘籍。
为了进一步提高性能,就必须仔细斟酌考虑线程在CPU不同核上的分布情况,这也就是常说的多核编程。多核编程和多线程有很大的不同:多线程是指每个CPU上可以运行多个线程,涉及到线程调度、锁机制以及上下文的切换;而多核则是每个CPU核一个线程,核心之间访问数据无需上锁。为了最大限度减少线程调度的资源消耗,需要将Linux绑定在特定的核上,释放其余核心来专供应用程序使用。
同时还需要考虑CPU特性和系统是否支持NUMA架构,如果支持的话,不同插槽上CPU的进程要避免访问远端内存,尽量访问本端内存。
NUMA
为了解决单核带来的CPU性能不足,出现了SMP,但传统的SMP系统中,所有处理器共享系统总线,当处理器数目越来越多时,系统总线竞争加大,系统总线称为新的瓶颈。NUMA(非统一内存访问)技术解决了SMP系统可扩展性问题,已成为当今高性能服务器的主流体系结构之一。
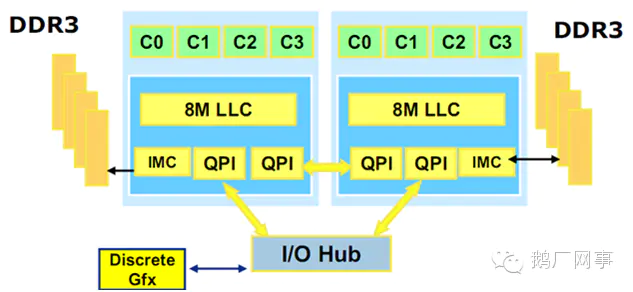
NUMA系统节点一般是由一组CPU和本地内存组成。NUMA调度器负责将进程在同一节点的CPU间调度,除非负载太高,才迁移到其它节点,但这会导致数据访问延时增大。下图是2颗CPU支持NUMA架构的示意图,每颗CPU物理上有4个核心。
dpdk内存分配上通过proc提供的内存信息,使cpu尽量使用靠近其所在节点的内存,避免访问远程内存影响效率。

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









