







 本文介绍如何使用OpenMP的reduction指令对二维数组中的元素进行最小值计算,并准确获取该最小值的位置。通过三种不同方法对比,展示了自定义规约函数在效率上的优势。
本文介绍如何使用OpenMP的reduction指令对二维数组中的元素进行最小值计算,并准确获取该最小值的位置。通过三种不同方法对比,展示了自定义规约函数在效率上的优势。
题目:请利用OpenMP 中指令 reduction 编写程序实现对实数数组 x(i,j) = (i + j) / (i * j) (i,j = 1~100) 取最小值并指出最小值对应的下标。
解答思路:初步使用并行思路和reduction子句求出最小值,记录最小值所在的行和列下标。
#include <stdio.h>
#include <omp.h>
#include <time.h>
/*
请利用指令 reduction 编写程序实现对实数数组 x(i,j) = (i + j) / (i * j) (i,j = 1~10) 取最小值并指出最小值对应的下标。
*/
#define m 100
#define n 100
double x_min = 1000;
int min_i, min_j;
int i, j;
double x[m + 1][n + 1];
int main()
{
clock_t start, finish;
double Total_time;
int tid, nthreads;
start = clock();
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
x[i][j] = (float)(i + j) / (i * j);
}
}
omp_set_nested(1);
omp_set_dynamic(0);
omp_set_num_threads(20);
#pragma omp parallel for private(tid, nthreads, i, j) shared(x) reduction(min \
: x_min)
for (i = 1; i <= m; i++)
{
for (j = 1; j <= n; j++)
{
tid = omp_get_thread_num();
nthreads = omp_get_num_threads();
if (x[i][j] < x_min)
{
x_min = x[i][j];
min_i = i;
min_j = j;
}
// printf("*****inner:tid = %d,nthreads = %d,x[%d][%d] = %lf\n", tid, nthreads, i, j, x[i][j]);
}
// printf("*****outer:tid = %d,nthreads = %d,x[%d][%d] = %lf\n", tid, nthreads, min_i, min_j, x_min);
}
printf("min:--------x[%d][%d] = %lf \n", min_i, min_j, x_min);
// finish = clock();
// Total_time = (double)(finish - start) / CLOCKS_PER_SEC; //单位换算成秒
// printf("%f seconds\n", Total_time);
return 0;
}
运行截图
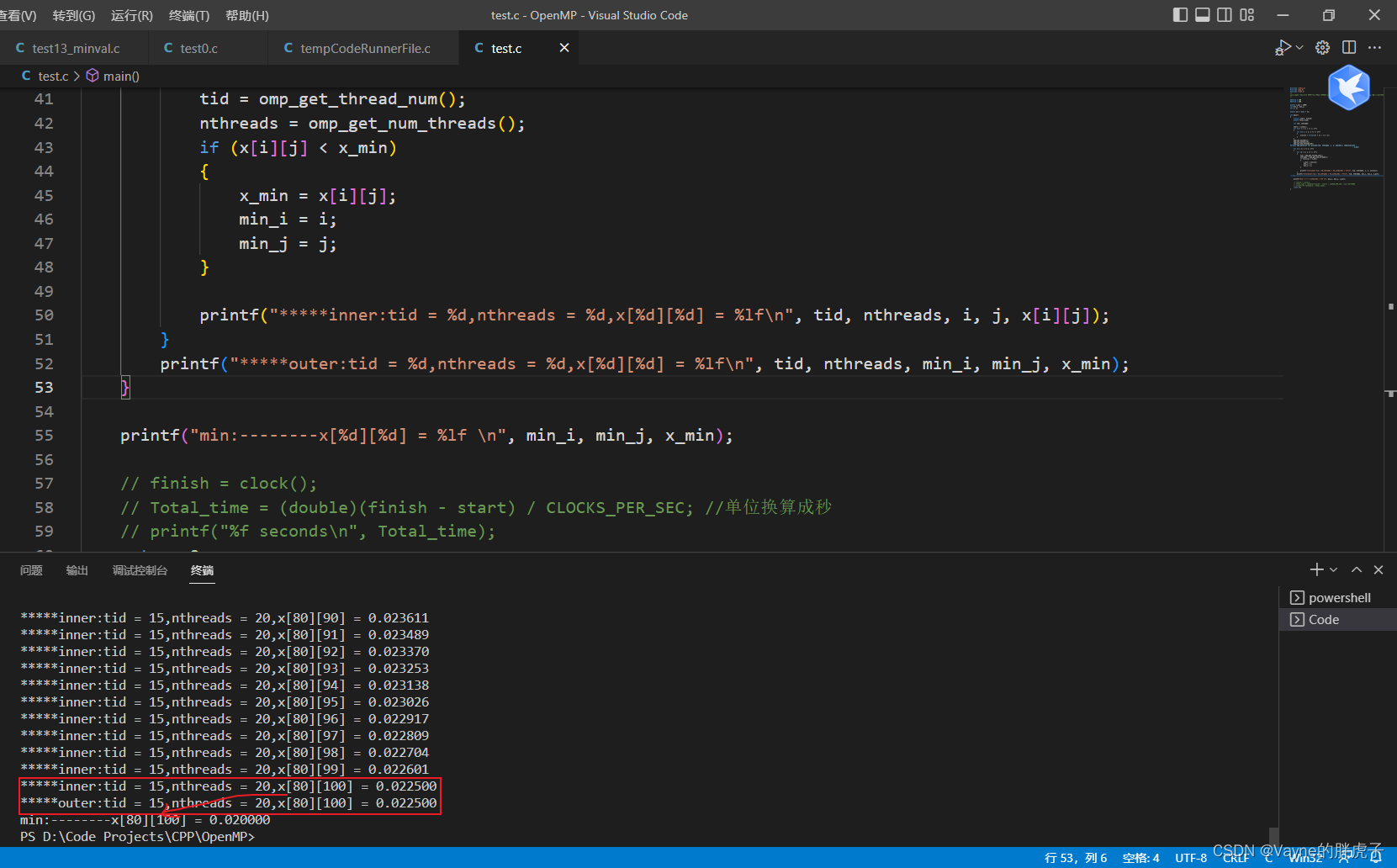
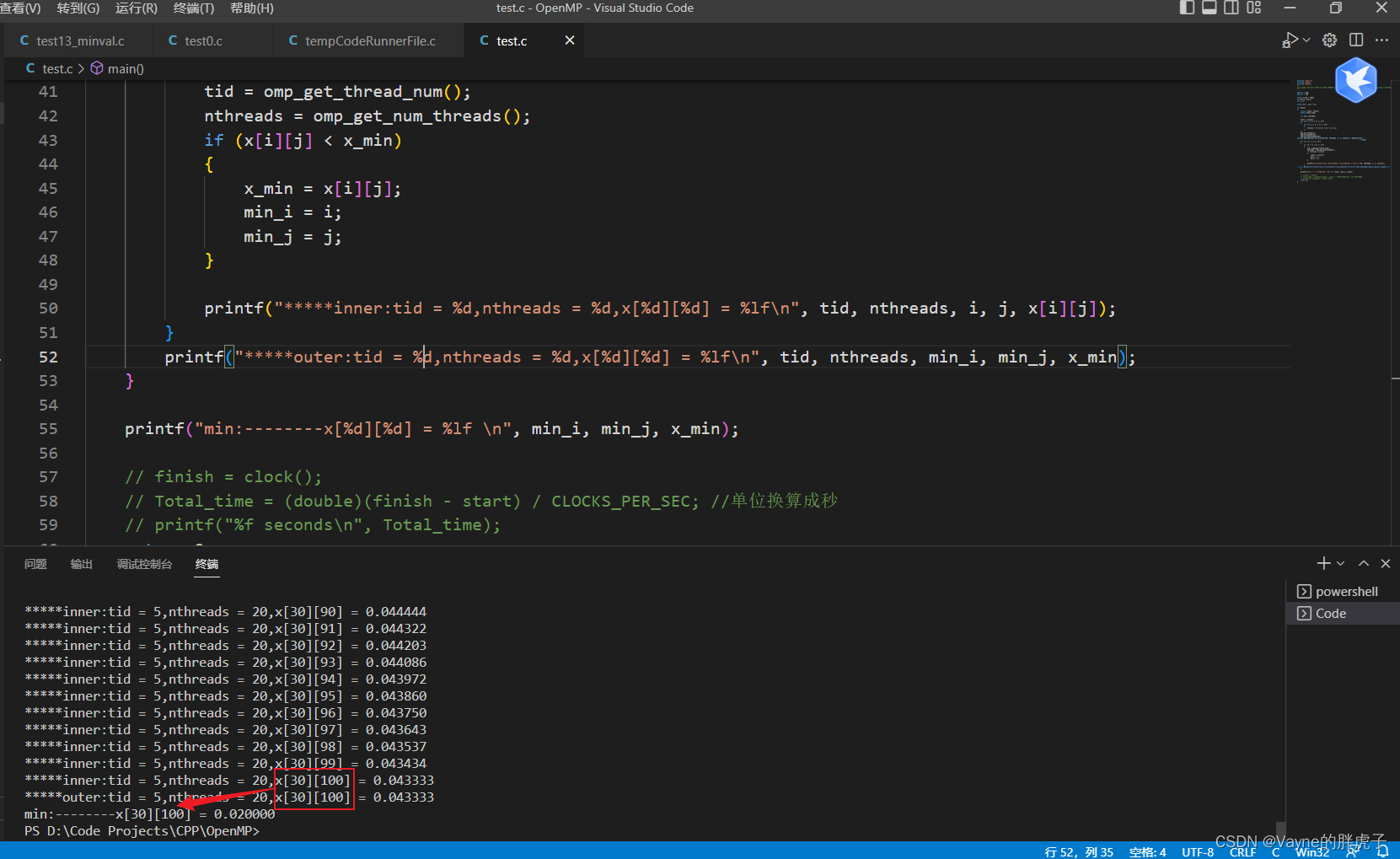
存在的问题:以上程序求出的最小值是正确的,但是下标是有问题的,因为并行之后,不同的线程执行顺序是不固定的,reduction子句里面在进行规约的时候,只能把一个最值给正确拿到,但是i,j下标输出的确实最后一个执行的线程中的最小值的i,j下标。
所以我们可以初步使用最笨的方法,写一个查找函数,从二维数组找到最值,输出其i,j下标,但是很明显,这种方法的效率是很低的,与我们使用并行算法改进效率初衷相悖,代码如下:
#include <stdio.h>
#include <omp.h>
#include <time.h>
/*
请利用指令 reduction 编写程序实现对实数数组 x(i,j) = (i + j) / (i * j) (i,j = 1~10) 取最小值并指出最小值对应的下标。
*/
#define m 100
#define n 100
double x_min = 1000;
int min_i, min_j;
int i, j;
double x[m + 1][n + 1];
int *returnRes(double arr[m + 1][n + 1], double ele)
{
int res[2] = {0};
int *p = res;
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
if (arr[i][j] == ele)
{
res[0] = i;
res[1] = j;
}
}
}
return p;
}
int main()
{
clock_t start, finish;
double Total_time;
int tid, nthreads;
start = clock();
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
x[i][j] = (float)(i + j) / (i * j);
}
}
omp_set_nested(1);
omp_set_dynamic(0);
omp_set_num_threads(20);
#pragma omp parallel for private(tid, nthreads, i, j) shared(x) reduction(min \
: x_min)
for (i = 1; i <= m; i++)
{
for (j = 1; j <= n; j++)
{
tid = omp_get_thread_num();
nthreads = omp_get_num_threads();
if (x[i][j] < x_min)
{
x_min = x[i][j];
min_i = i;
min_j = j;
}
// printf("*****inner:tid = %d,nthreads = %d,x[%d][%d] = %lf\n", tid, nthreads, i, j, x[i][j]);
}
// printf("*****outer:tid = %d,nthreads = %d,x[%d][%d] = %lf\n", tid, nthreads, min_i, min_j, x_min);
}
int *res = returnRes(x, x_min);
printf("min:--------x[%d][%d] = %lf \n", res[0], res[1], x_min);
// printf("min:--------x[%d][%d] = %lf \n", min_i, min_j, x_min);
finish = clock();
Total_time = (double)(finish - start) / CLOCKS_PER_SEC; //单位换算成秒
printf("%f seconds\n", Total_time);
return 0;
}
上面的returnRes函数就起到了返回最小值i,j下标的作用,通过在网上查找,我们得到了利用OpenMP reduction子句可以自定义规约函数,我们可以定义成结构体,里面分别是元素值,i下标,j下标,通过比较元素值来判断结构体的大小,从而整体返回一个结构体,这个时候下标也会一起返回出来。代码见下面:
#include <stdio.h>
#include <omp.h>
#include <time.h>
/*
请利用指令 reduction 编写程序实现对实数数组 x(i,j) = (i + j) / (i * j) (i,j = 1~10) 取最小值并指出最小值对应的下标。
*/
#define m 100
#define n 100
double x[m + 1][n + 1];
struct compare
{
float val;
int index;
int index1;
};
struct compare add_matrix(struct compare X, struct compare Y)
{
struct compare temp;
if (X.val < Y.val)
{
temp.val = X.val;
temp.index = X.index;
temp.index1 = X.index1;
}
else
{
temp.val = Y.val;
temp.index = Y.index;
temp.index1 = Y.index1;
}
return temp;
}
int main()
{
int tid, nthreads;
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
x[i][j] = (float)(i + j) / (i * j);
}
}
double x_mymin = 1000;
int mymin_i, mymin_j;
// omp_set_nested(1);
omp_set_dynamic(0);
omp_set_num_threads(10);
struct compare mymin;
mymin.val = x[1][1];
mymin.index = 1;
mymin.index1 = 1;
int i = 1;
int j = 1;
clock_t begin, end;
begin = clock();
#pragma omp declare reduction(p_add_matrix \
: struct compare \
: omp_out = add_matrix(omp_out, omp_in)) initializer(omp_priv = {100})
{
#pragma omp parallel for private(tid, nthreads, i, j) shared(x) reduction(p_add_matrix \
: mymin)
for (i = 1; i <= m; i++)
{
for (j = 1; j <= n; j++)
{
tid = omp_get_thread_num();
nthreads = omp_get_num_threads();
if (x[i][j] < mymin.val)
{
mymin.val = x[i][j];
mymin.index = i;
mymin.index1 = j;
}
// printf("*****inner:tid = %d,nthreads = %d,x[%d][%d] = %lf\n", tid, nthreads, i, j, x[i][j]);
}
// printf("*****outer:tid = %d,nthreads = %d,x[%d][%d] = %lf\n", tid, nthreads, mymin.index, mymin.index1, mymin.val);
}
}
printf("mymin:--------x[%d][%d] = %lf ", mymin.index, mymin.index1, mymin.val);
end = clock();
double cost;
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("CLOCKS_PER_SEC is %d\n", CLOCKS_PER_SEC);
printf("time cost is: %lf secs\n", cost);
return 0;
}
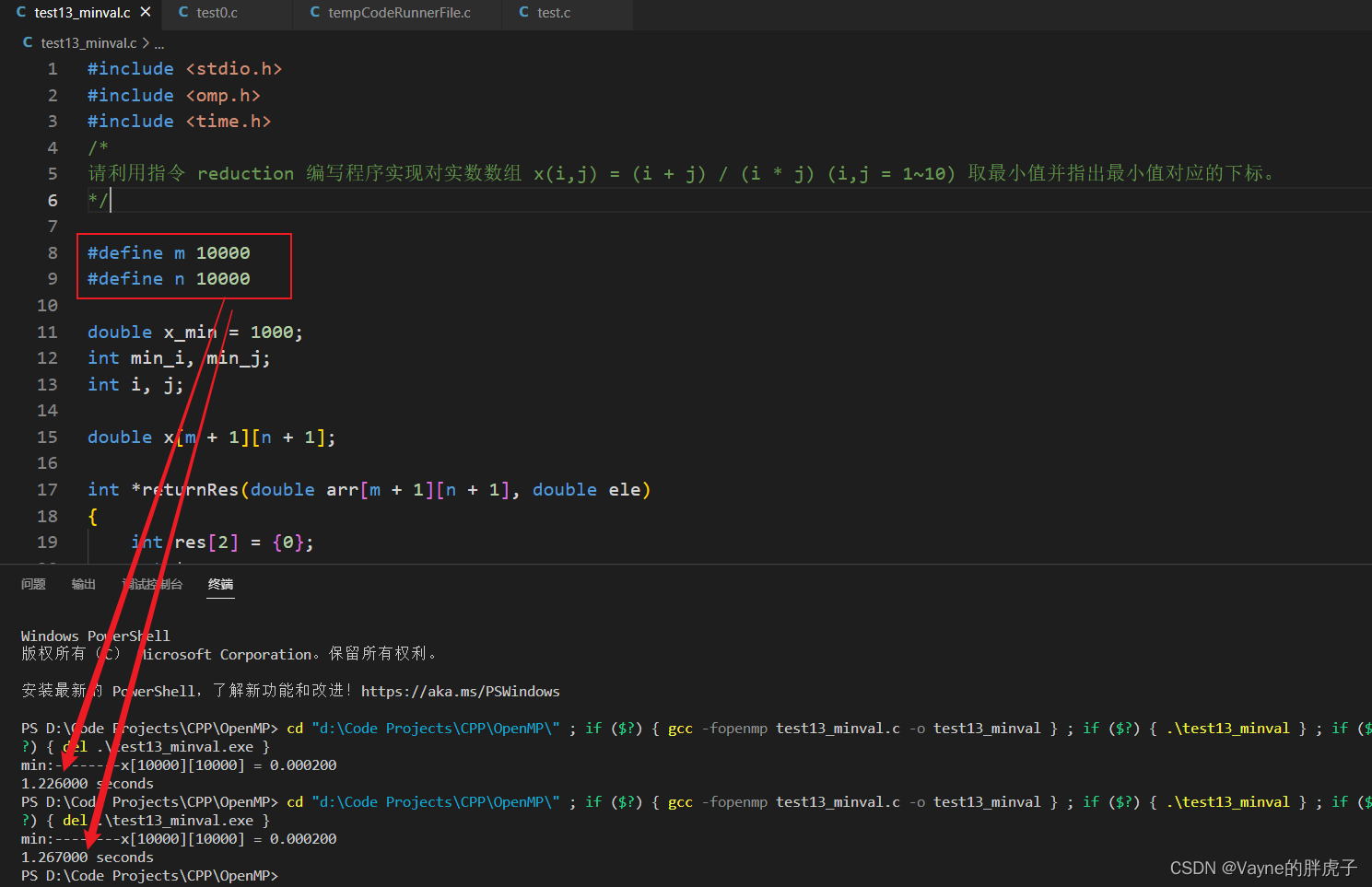
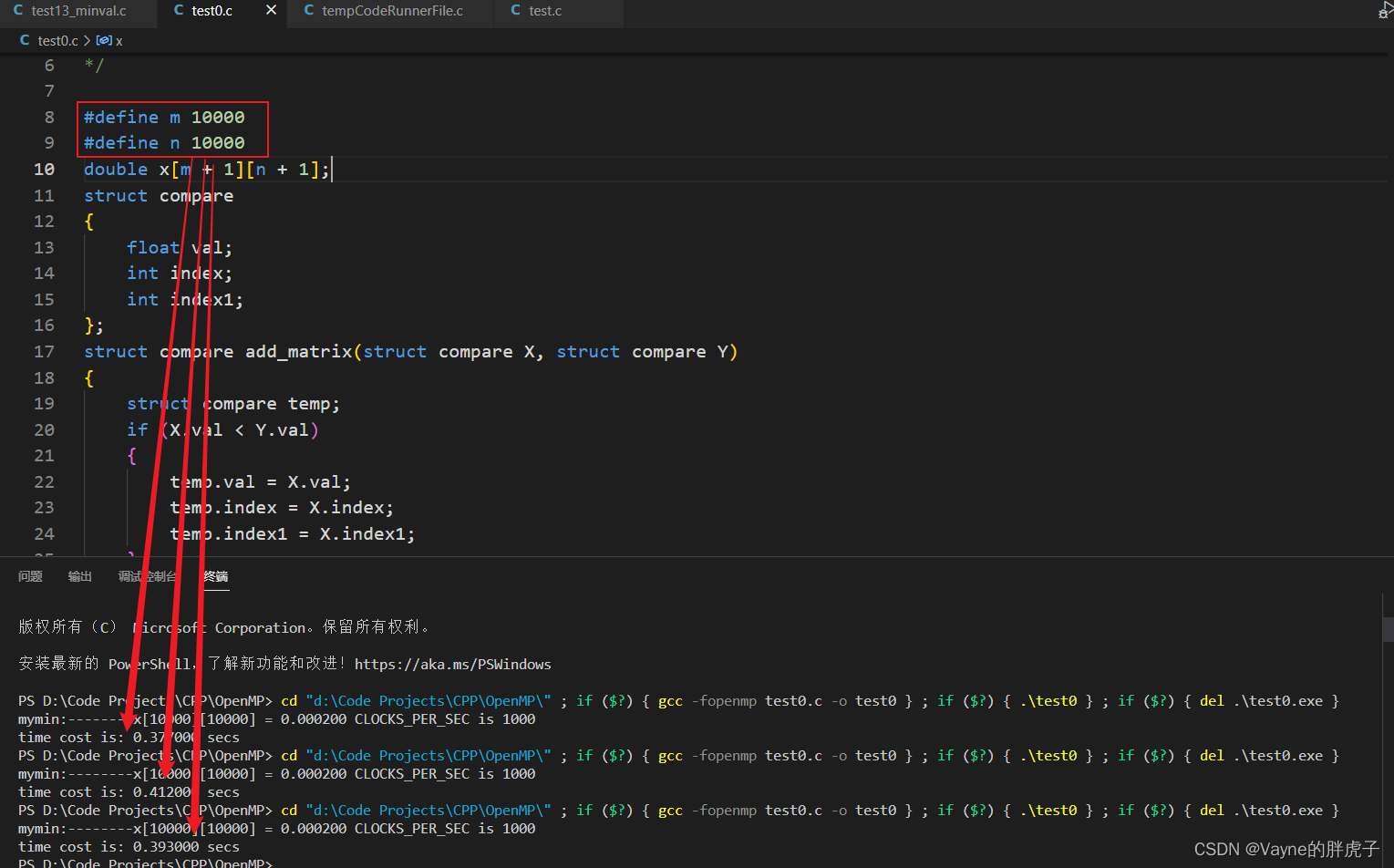
通过调节m,n的值可以测试程序运行的时间,会发现这种方式比单独写一个查找函数的方式要快非常多!下面有运行时间的截图哦,最后感谢我的舍友健神!
1.带查找函数的:(矩阵规模 10000*10000):1.3S左右
2.自定义规约函数的:(矩阵规模 10000*10000):0.4S左右,加速比提高了三倍多!

















 9223
9223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









