







RobotFramework框架
一、简介和特点
基于python开发的、可扩展的,以关键字驱动的自动化测试框架
-
数据驱动:
数据驱动是把测试用例的数据放到excel、yaml里面,然后通过改变excel或者yaml文件里面的数据,达到控制测试用例的执行过程
-
关键字驱动:
把项目中的一些业务逻辑或基本的操作封装成一个一个的关键字,然后调用不同的关键字或者关键字的组合实现不同的业务逻辑
-
特点:
- 编写用例更方便,可以以robot,txt,html等格式
- 自动生成htm格式的测试报告(unittest:htmltestrunner,pytest:allure)
- 自带很多类库,支持很多扩展库
- 可以根据我们业务逻辑的需要自定义关键字(登录,下订单,评论)
- 支持非GUI方式运行,还可以和Jenkins持续集成
二、搭建RF测试环境
-
先安装python,并配置环境变量
-
pip install robotframework
-
pip install robotframework-ride(生成快捷方式)
-
检查是否安装完成
pip list
三、RIDE的基本使用
-
测试套件
-
Edit标签:
Setting 设置
加载外部文件(扩展库,资源文件,变量文件,帮助文档)
定义内部变量
定义元数据
-
四、RF类库和扩展库
-
标准库(RF自带的库,不需要额外安装)
BuitIn
Collections(集合库)
DateTime(时间库)
Screenshot(截屏库)
-
扩展库(需要通过pip命令额外安装的库)
-
web自动化:SeleniumLibrary
安装:pip install robotframework-seleniumlibrary
-
接口自动化:RequestLibrary
安装:pip install robotframework-request
-
app自动化:AppiumLibrary
安装:pip install robotframework-appiumlibrary
-
存储的位置:E:\SoftWare\Python\Lib\site-packages
-
五、RF的基本使用
六、RF关键字
-
常规关键字
*** Settings *** Library Collections *** Test Cases *** 测试用例test Log 码尚学院 # 打印 # 定义变量 ${a} set variable 100 log ${a} # 获取系统时间 ${time} get time log ${time} # 字符串拼接 ${str} catenate 百里 星瑶 微微 log ${str} ${str} catenate SEPARATOR= # \ \ \ 百里 \ \ \ 星瑶 \ \ \ 微微 log ${str} # 创建列表 ${list} Create list 百里 星瑶 微微 log ${list} @{list} Create list 百里 星瑶 微微 log many @{list} # 字典关键字 ${dic} create dictionary name=百里 age=38 # 获取字典所有key log ${dic} ${keys} Get Dictionary Keys ${dic} log ${keys} # 获取字典所有values ${values} get dictionary values ${dic} log ${values} # 通过key取value ${value} get from dictionary ${dic} name log ${value}*** Settings *** Library Collections Library Screenshot *** Test Cases *** 常规关键字 Log 码尚学院 # 打印 # 定义变量 ${a} set variable 100 log ${a} # 获取系统时间 ${time} get time log ${time} # 字符串拼接 ${str} catenate 百里 星瑶 微微 log ${str} ${str} catenate SEPARATOR= # \ \ \ 百里 \ \ \ 星瑶 \ \ \ 微微 log ${str} # 创建列表 ${list} Create list 百里 星瑶 微微 log ${list} @{list} Create list 百里 星瑶 微微 log many @{list} # 字典关键字 ${dic} create dictionary name=百里 age=38 # 获取字典所有key log ${dic} ${keys} Get Dictionary Keys ${dic} log ${keys} # 获取字典所有values ${values} get dictionary values ${dic} log ${values} # 通过key取value ${value} get from dictionary ${dic} name log ${value} 复杂关键字 # 执行python方法 ${rand} evaluate random.randint(1, 101) modules=random log ${rand} ${time} evaluate time.time() modules=time log ${time} # 执行py文件里面的关键字 ${x} evaluate int(10) ${y} evaluate int(20) import library E:/test.py ${result} sum ${x} ${y} log ${result} #流量控制if ${a} set variable 86 run keyword if ${a}<60 log 不及格 ... ELSE IF ${a}<80 log 一般 ... ELSE log 优秀 #流程控制for FOR ${a} IN apple orcale banana log ${a} END #列表方式 @{list} create list apple orcale banana FOR ${a} IN @{list} log ${a} END #写法3 FOR ${a} IN RANGE 1 11 Run Keyword If ${a}==6 Exit For Loop Log ${a} END # 截图 Take Screenshot
七、准备WEB自动化环境
-
web自动化关键字
*** Settings *** Library SeleniumLibrary *** Test Cases *** # 打开浏览器并且加载网页 打开浏览器 Open Browser url=http://www.baidu.com browser=chrome # 设置隐式等待 Set Browser Implicit Wait 3 Sleep 2 # 设置浏览器最大化 Maximize Browser Window Sleep 2 # 设置浏览器的宽度和高度 Sleep 2 Set Window Size 600 800 # 获得浏览器的宽度和高度 Sleep 2 ${width} ${height} Get Window Size Sleep 2 # 回退 Go Back # 前进 Go To http://www.csdn.com # 刷新 Reload Page # 获得标题 ${title} Get Title # 获得浏览器地址 ${location} Get Location # 关闭浏览器 Close Browser
八、元素定位
前提:元素或属性必须唯一
八种元素定位方式:id\name\link_text\partial_link\xpath\css\class_ame\tag_name
绝对路径:以/开头,绝对路径是从网页的第一个标签开始查询元素
xpath=/html/body/div[1]/div/div[5]/div/div/form/span[1]/input
相对路径:以//开头,相对路径是从网页的任意标签开始查询元素
-
相对路径+索引定位 //form/span/input
-
相对路径+属性定位 //input[@autocomplete=“off”]
-
相对路径+部分属性值定位
- 以什么开头 //input[starts-with(@autocomplete,‘of’)]
- 以什么结尾 //input[substring(@autocomplete,2)=‘ff’]
- 包含 //input[contains(@autocomplete,‘of’)]
-
相对路径+通配符定位
- //*[@id=‘kw’]
- 一般不建议大家复制xpath使用
- 复制的xpath性能较低
- 复制的xpath比我们手写的要复杂
- 有些元素是动态的,复制的xpath完全失效
-
相对路径+文本定位
- //span[text()=“按图片搜索”]
-
CSS定位
-
绝对路径
xpath=html>body>div[1]>div>div[5]>div>div>form>span[1]>input
-
相对路径
*** Settings *** Library SeleniumLibrary *** Test Cases *** # 打开浏览器并且加载网页 元素定位 Open Browser url=http://www.baidu.com browser=chrome Set Browser Implicit Wait 2 # id定位 Input Text id=kw 自动化测试 Click Element id=su # name定位 Input Text name=wd 自动化测试 Click Element id=su # link_text链接文本定位 Click Element link=新闻 # particl_link 部分链接 Click Element partial link=新 Sleep 3 # xpath定位 Input Text xpath=/html/body/div[1]/div/div[5]/div/div/form/span[1]/input 自动化测试 Click Element id=su Input Text xpath=//input[starts-with(@autocomplete,'of')] 自动化测试 Input Text xpath=//input[substring(@autocomplete,2)='ff'] 自动化测试 Input Text xpath=//input[contains(@autocomplete,'of')] 自动化测试 Input Text xpath=//*[@id='kw'] 自动化测试 Input Text xpath=//span[text()="按图片搜索"] 自动化测试 Click Element id=su # CSS定位 # 通过ID定位 Input Text css=#kw 自动化测试 Click Element id=su # 通过class定位 Input Text css=input.s_ipt 自动化测试 Click Element id=su # 清空元素 Clear Element Text id=kw -
九、操作元素的关键字
-
操作元素
*** Settings *** Library SeleniumLibrary *** Test Cases *** 常规元素操作 Open Browser http://www.baidu.com chrome # 获取元素文本信息 ${text} Get Text xpath=//a[@href='http://news.baidu.com'] # 获取元素属性 ${attribute} Get Element Attribute xpath=//a[@href='http://news.baidu.com'] class 鼠标和键盘关键字 Open Browser http://www.baidu.com chrome # 双击元素 Double Click Element id=kw # 键盘事件 Press Key id=kw autotest Sleep 3 Close Browser 断言关键字(系统断言) # 系统断言 ${a} Set Variable zhangsan Should Be Empty ${a} Should Be Equal ${a} ZHANGSAN ignore_case=True Should Be True 1=2 Should Contain zhangsan zhan ignore_case=False Should Start With zhangsan zh Should End With zhangsan an Length Should Be zhangsan 8 Open Browser https://www.baidu.com chrome Sleep 3 slenium断言 Open Browser https://www.baidu.com chrome Sleep 5 # 断言页面是否包含hao123这个字段 Page Should Contain hao123 # 断言页面中是否包含有id=kw的元素 Page Should Contain Element id=kw 元素等待关键字 Open Browser https://www.baidu.com chrome Set Browser Implicit Wait 3 # 针对当前浏览器 Set Selenium Implicit Wait 3 # 针对所有浏览器 # 等待元素包含指定的文本 Wait Until Element Contains xpath=//a[@href='http://news.baidu.com'] 新闻 3 Sleep 3 # 等待元素可用 Wait Until Element Is Enabled link=新闻 3 # 等待元素可见 Wait Until Element Is Visible link=新闻 3 # 等待页面包含指定的文本 Wait Until Page Contains 百度一下 3 # 等待页面包含指定元素 Wait Until Page Contains Element id=kw Close Browser
十、项目实战
-
示例
*** Settings *** Library SeleniumLibrary *** Test Cases *** 登录 Open Browser http://ihrm-java.itheima.net/#/login chrome Clear Element Text name=username Clear Element Text name=password Sleep 5 Input Text name=username 13800000002 Input Text name=password 888itcast.CN764%... Click Button xpath=//*[@id="app"]/div/form/button Sleep 3 Close Browser 查询商品(框架及下拉框) # 进入框架 Select Frame name=menu-frame # 选择元素 # 跳出框架 Unselect Frame # 进入新框架 Select Frame name=main-frame # 选中下拉框中的数据 Select From List By Index name=brand_id 4 Select From List By Value name=brand_id 9 Select From List By Label name=brand_id 联想 删除商品 # 定位一组元素 ${ele_list} Get WebElements xpath=//img[@src='abc'] Click Element ${ele_list}[0] # 点击alert按钮 Sleep 2 Handle Alert # 直接点确定 Handle Alert action=Dismiss # 取消 Handle Alert timeout=10s # 超时接受 Handle Alert DISMISS # 超时取消 ${message} Handle Alert 新网页操作 Select Frame name=header-frame Click Element link=查看网店 Sleep 3 # 进入到新网页操作 Switch Window new
问题
-
线性脚本,不利于后期维护
-
没有分层封装的思想
京东的仓库:日用品,书籍,电器
分层:页面的元素层,业务逻辑层,测试用例层(数据驱动)
-
数据是没有独立的
分层目的:主要增加脚本的重复利用
项目的三层架构
- 页面元素层
- 业务逻辑层
- 测试用例层
-
业务逻辑层调用页面元素层,测试用例层调用业务逻辑层
-
为什么要分层
实现页面元素,公共方法,公共数据,测试用例集中式管理
增加脚本重复利用率
增加脚本的可维护性
Jenkins持续集成RF
- 在Jenkins里面安装robotframework插件
RF扩展
- 发送电子邮件
- 执行js脚本
- 鼠标键盘事件
- 验证码处理
- 断言
- 接口自动化
- APP自动化
-
web自动化
语言:python、java
设计模式:PO模式、关键字驱动
用例管理:unittest/pytest
日志监控:logger
二次封装:selenium二次封装,yaml二次封装,excel二次封装,数据库二次封装
测试报告:htmltestrunner/allure,日志的定制
数据驱动ddt,parameterice
版本控制:git,集成pycharm
容器技术:docker
最核心的:自主独立的搭建一套自动化框架
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
网工/运维/测试副业方向
运维网工,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
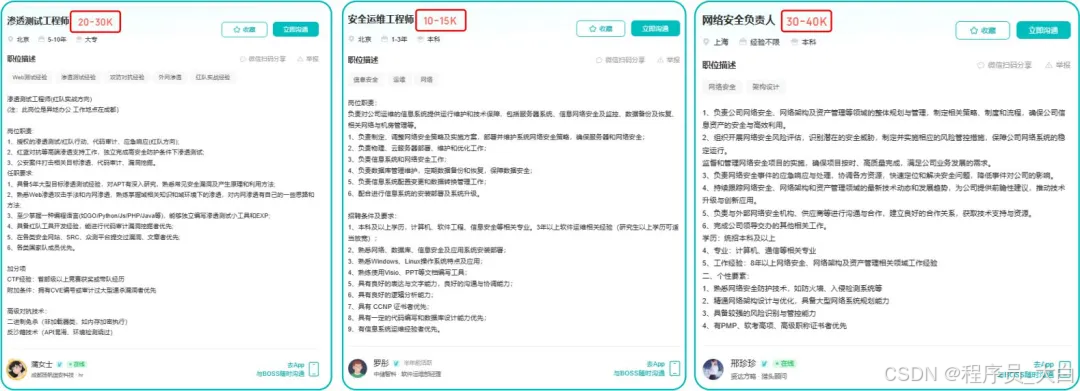
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维和网工测试人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
网工运维测试转行学习网络安全路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
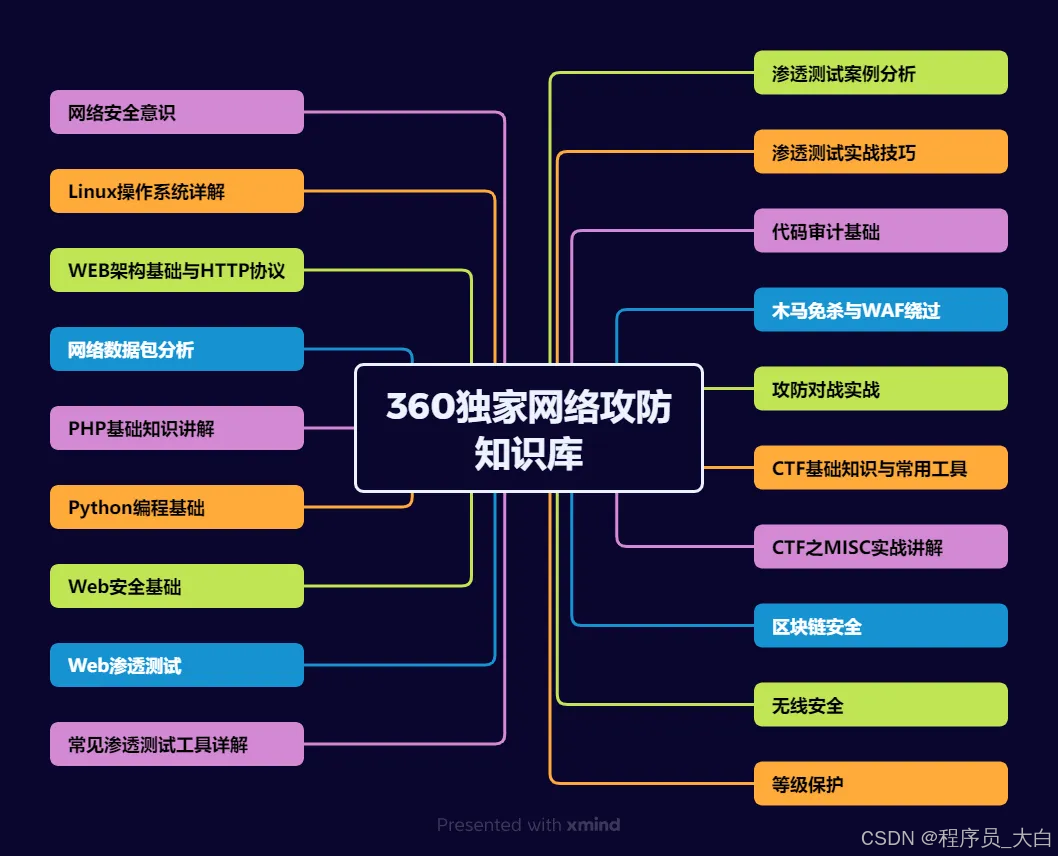
运维网工测试转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 9110
9110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









