







Robot Framework介绍:
是一个基于Python的,可扩展的关键字驱动的测试自动化框架。它是为了端到端的验收测试(End-To-End Acceptance Test)以及验收测试驱动开发(Acceptance-Test-Driven Development, ATDD)而设计的。
因此它可以应用于测试,当验证需要涉及多个不同技术和接口的分布式、异构的应用程序。
特点:
1.易读易写:用关键字驱动语法,测试用例易于理解和编写以及维护。
2.可以通过外部文件(如Excel、CSV)或内部变量表达式来实现数据驱动。
3.有丰富的库生态系统,包括内置的库和第三方库,可以扩展其功能和支持各种测试需求,如Selenium库用于Web自动化测试、Requests库用于API测试等。
4.支持自定义关键字。
5.它可以和jenkins持续集成
6.跨平台,可以在多种操作系统上运行,并且支持多种脚本语言
7.支持生成详细的测试报告和log
安装python,基于已安装好的python3.8版本示例
安装Robot Framework
pip install robotframework -i https://pypi.douban.com/simple/(安装robotframework,也可以指定版本pip install robotframework==版本号)
robot --version(查看安装版本)
Robot Framework 6.1.1 (Python 3.8.10)----------示例版本
安装robotframework-ride
RIDE是Robot Framework的可视化UI界面工具,专用于编写测试用例,比直接写代码方便
pip install robotframework-ride -i https://pypi.douban.com/simple/ 一般下载最新版就行,老版本可能会闪退
升级命令:pip install -U https://github.com/robotframework/RIDE/archive/master.zip
安装seleniumlibrary库:pip install robotframework-seleniumlibrary
查看安装结果:pip list命令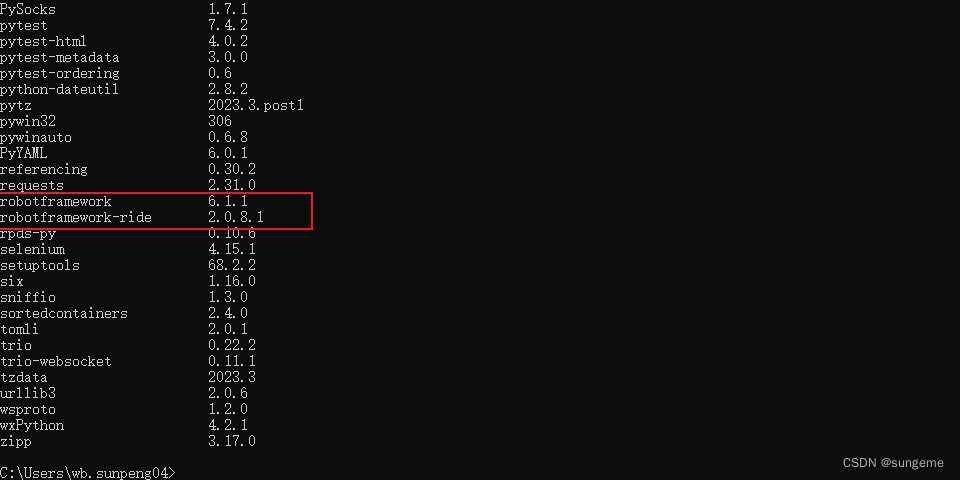
安装完成后桌面没有exe执行文件解决:
1、鼠标在空白桌面右击,新建,新建快捷方式,我命名为RIDE
2、在弹出层填写 绝对路径\\python.exe -c"from robotide import main; main()"
注意:Python位置更改为自己的安装位置
安装完成后就可以打开RIDE了,按F5可以查看安装的关键字库,例如selenium2library(注意selenium2library已经不支持新版),如果没有库,就使用命令下载一个,然后重启RIDE:pip install robotframework-seleniumlibrary
这里所使用的配置:

配置浏览器驱动
最新驱动下载地址:https://googlechromelabs.github.io/chrome-for-testing/(注意适配chrome新版)
RIDE界面介绍
主界面介绍
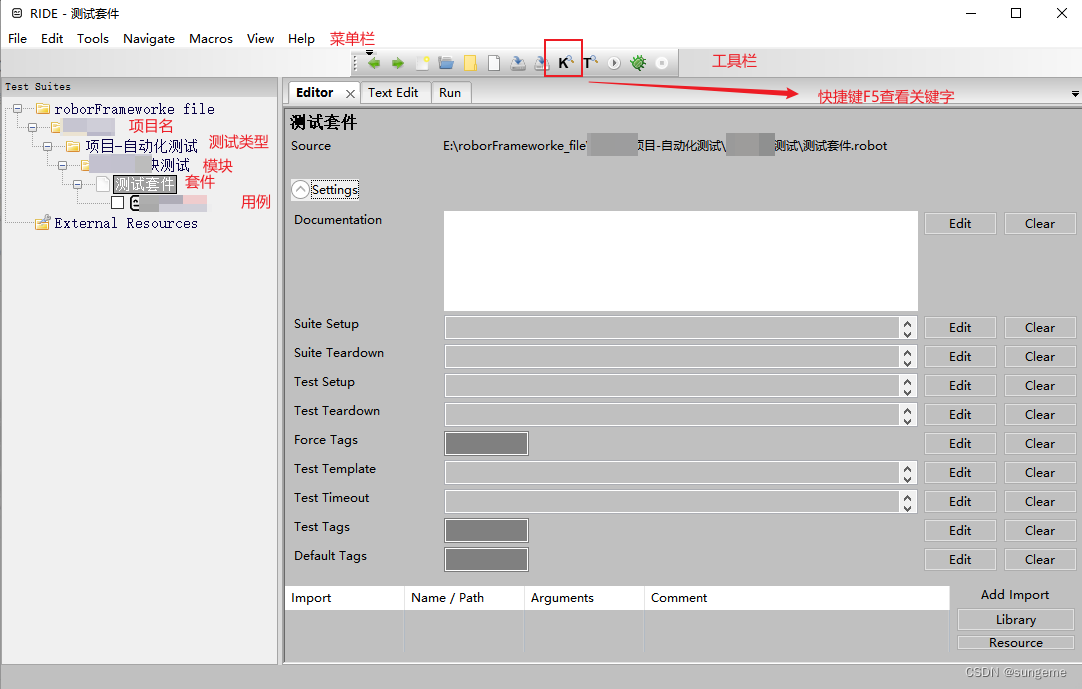
用例界面介绍
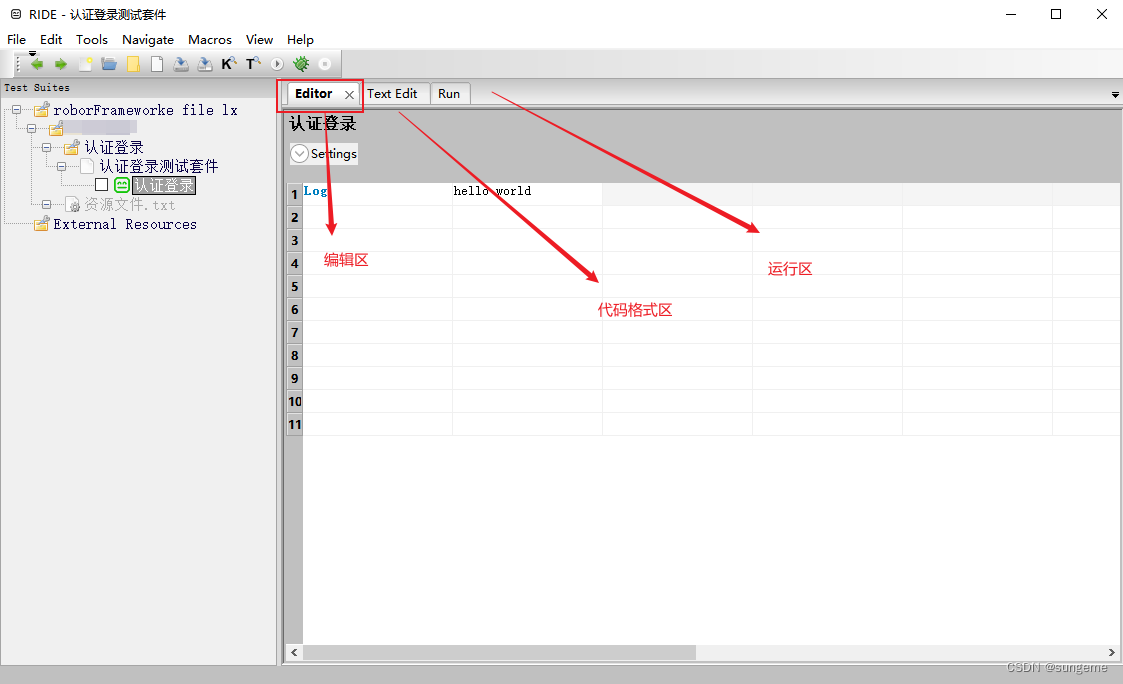
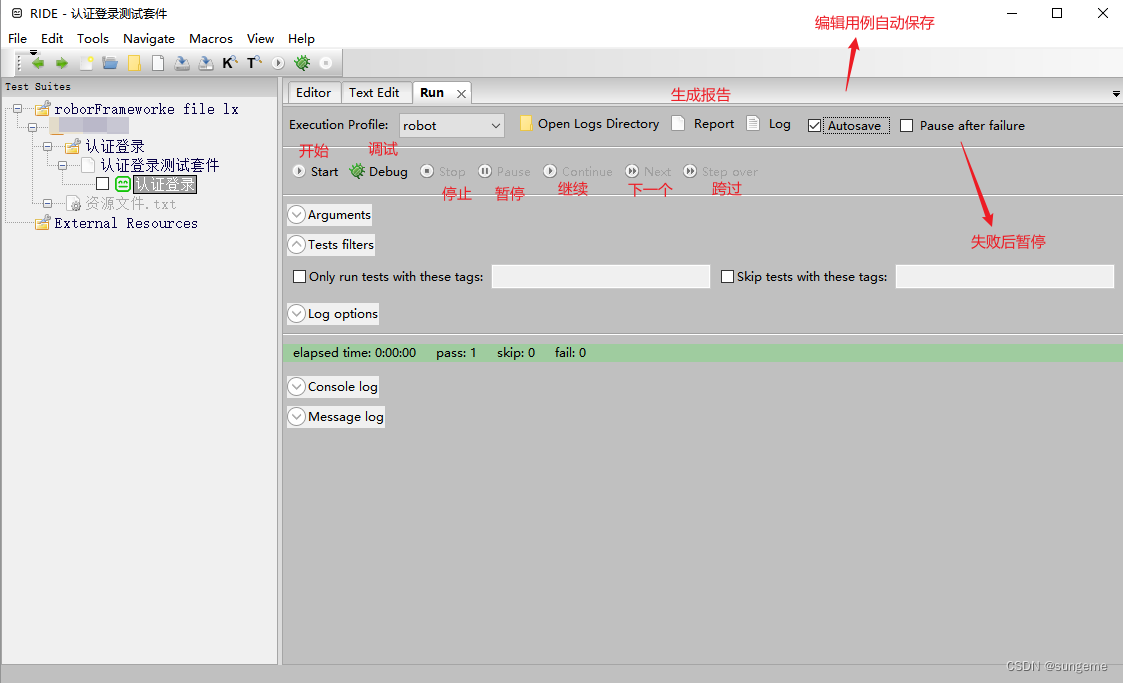
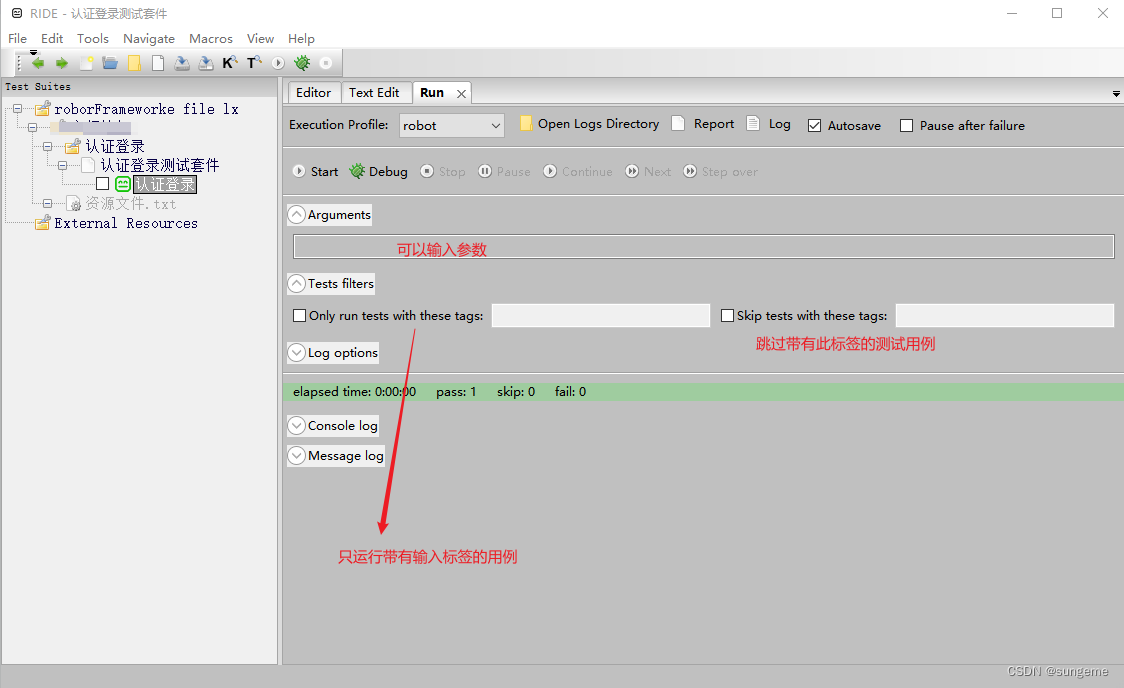
RF基本使用
测试套件
1、设置:(说明,测试套件之前执行的关键字,测试套件之后的关键字,测试用例之前,测试用例之后,测试用例模块,测试用例超时时间,强制标记,默认标记)
2、导入外部的扩展库或者是资源文件
3、自定义变量
4、元数据
快捷键技巧
关键字补全:Ctrl + Shift + 空格
查看关键字详情:鼠标放在关键字上,按住Ctrl
建立项目
注意
RIDE有个小bug:
当目录下面没有测试套件的时候,那么同级的其它目录将不会显示,只有存在测试套件的时候,才会展示其它目录
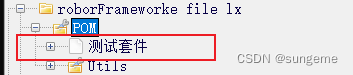
1.项目必须选择 Dictionarv
2.测试套件是测试用例的载体。资源文件是自定义关键字的载体。
3、自定义的资源文件和关键字是无法直接使用的,需要在测试套件(不能在项目,只能在测试套件)里面导入资源文件
新建项目
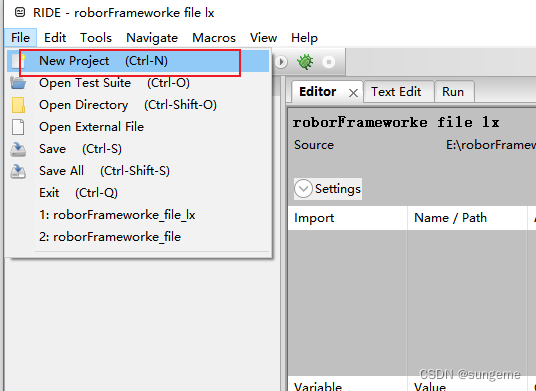
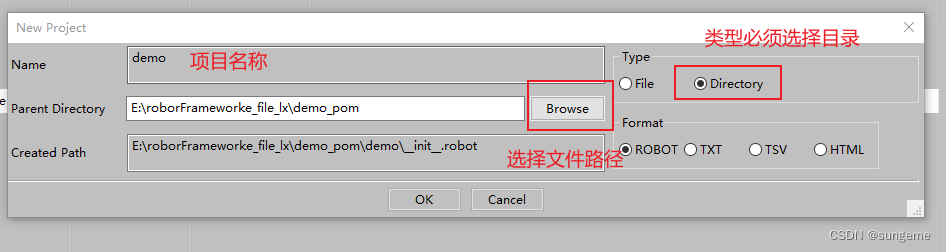
创建套件
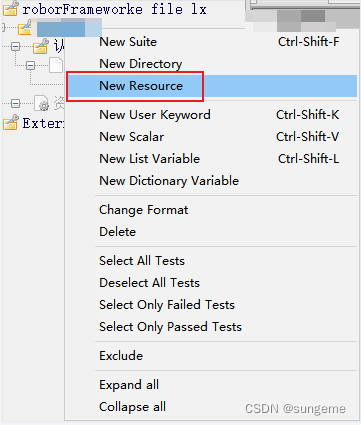
套件下创建测试用例
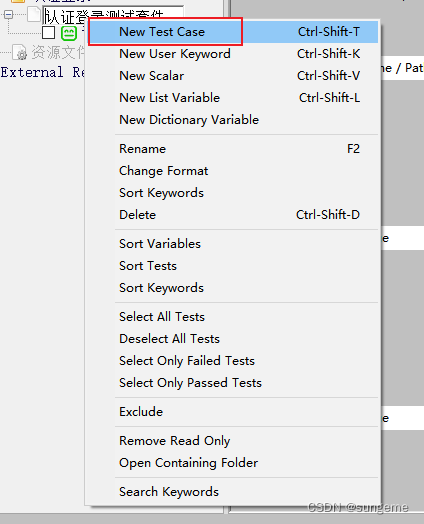
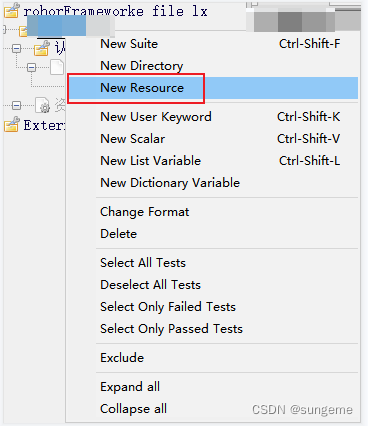
创建资源文件以自定义关键字

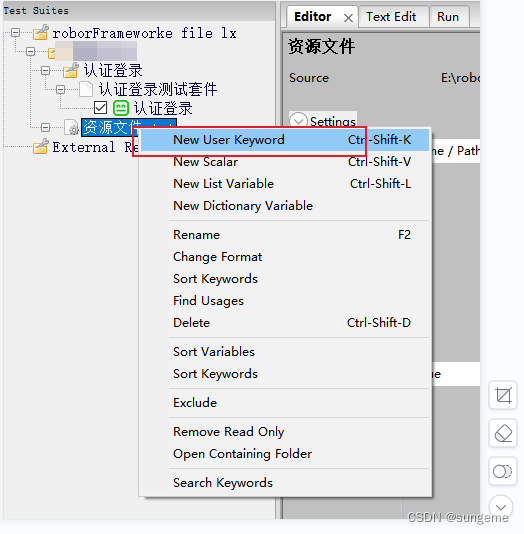
在资源文件下创建一个新的自定义关键字
例如: 想实现默认关键字Log一样的功能,我就可以叫print,打印
注意这里新版创建时需要填写Arguments参数变量,这里设置了几个变量,调用时就要传递几个,作为内部使用
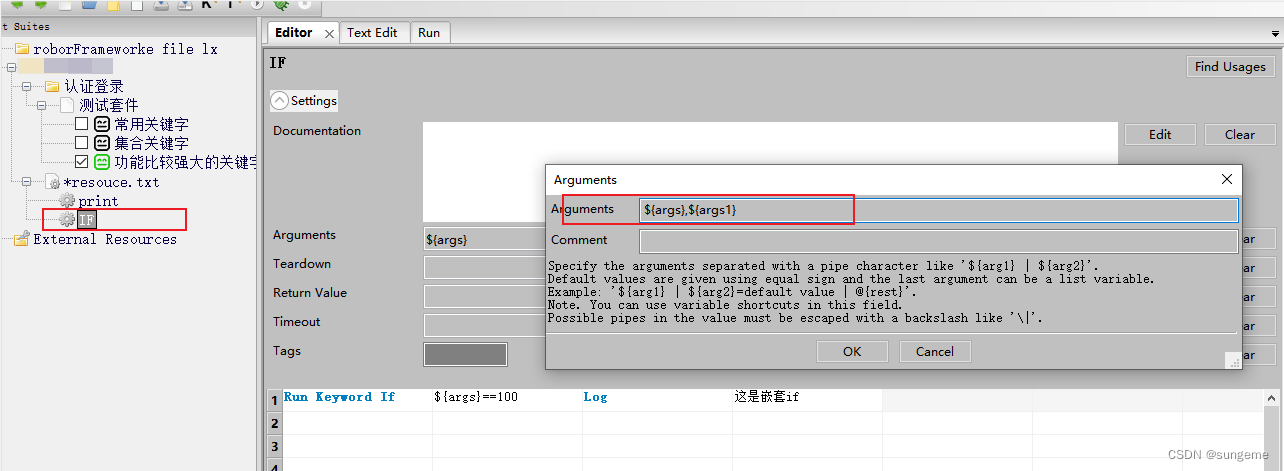
注意参数要清除一下,因为参数有值,如果不清楚,引用的时候必须要填写一个值,在这里清除: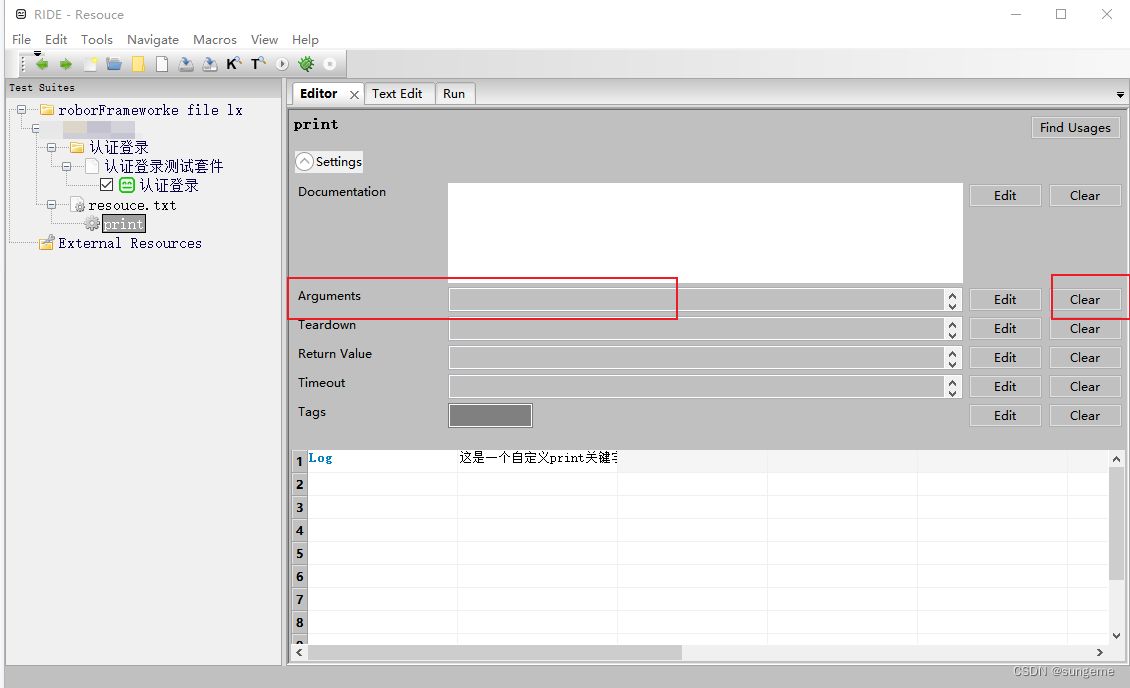
填入关键字的运行内容
资源文件导入使用
自定义的资源文件和关键字是无法直接使用的,需要在测试套件(不能在项目,只能在测试套件)里面导入资源文件
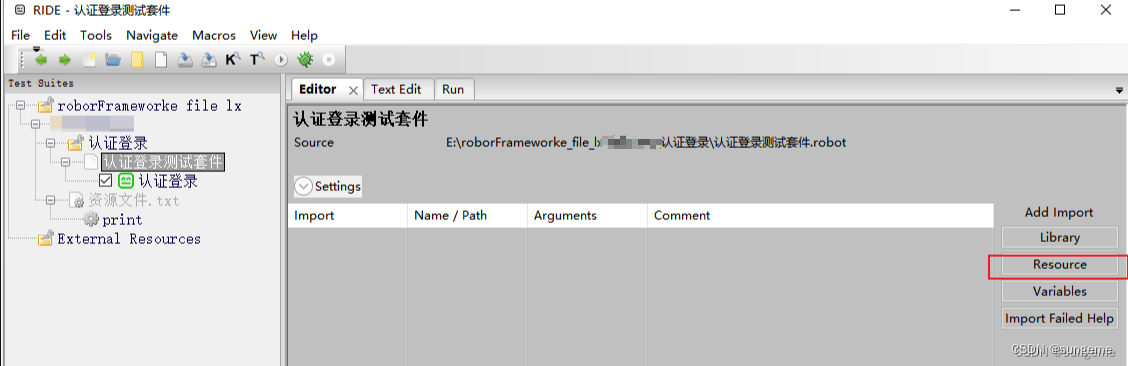
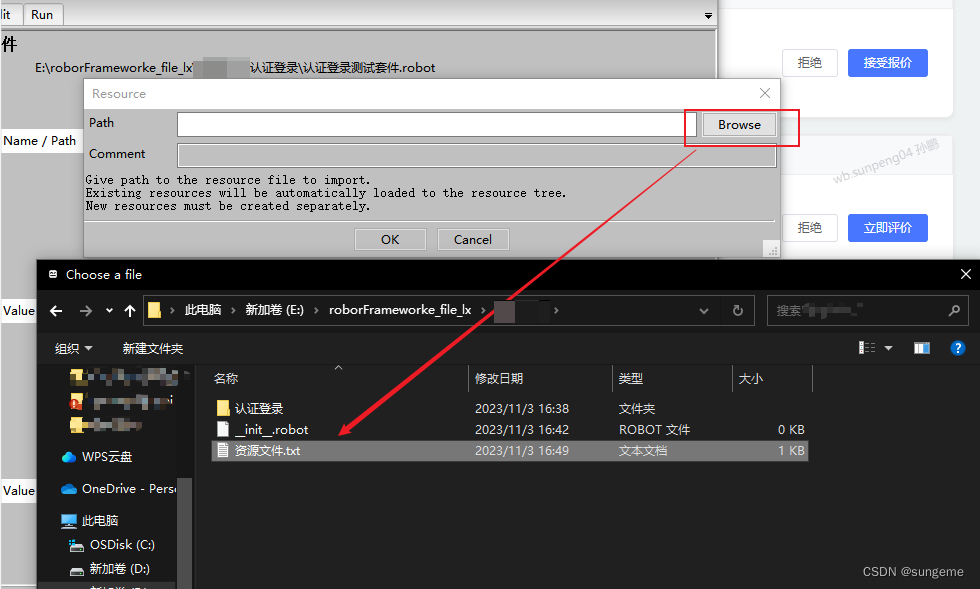
导入后:
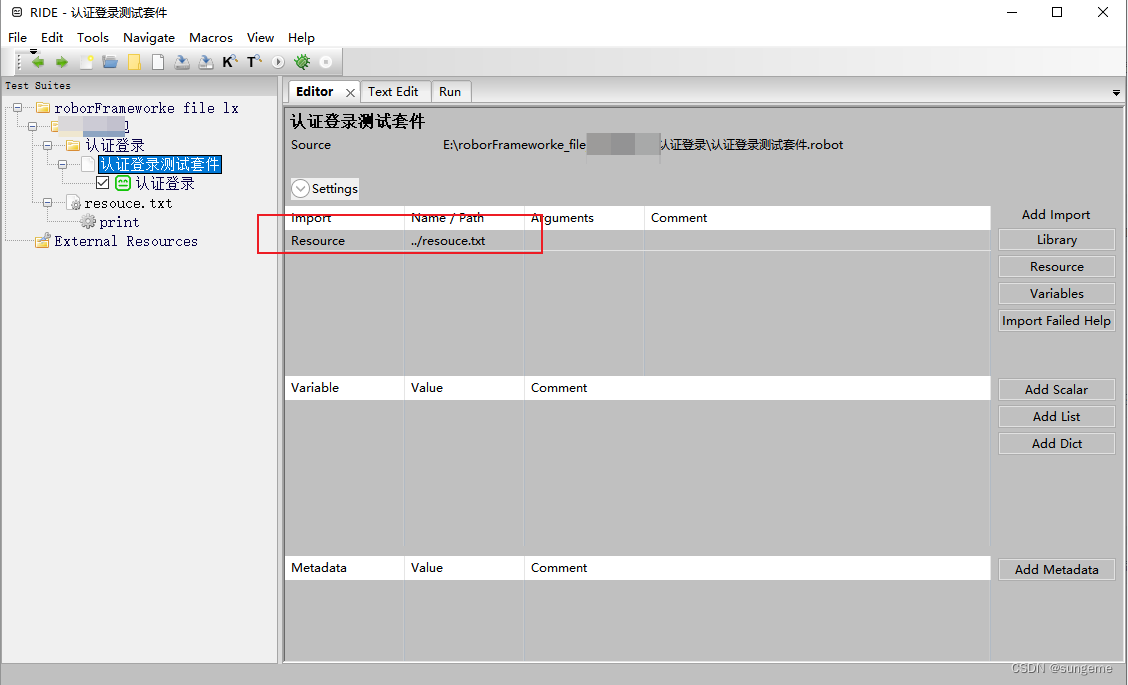
进行关键字调用
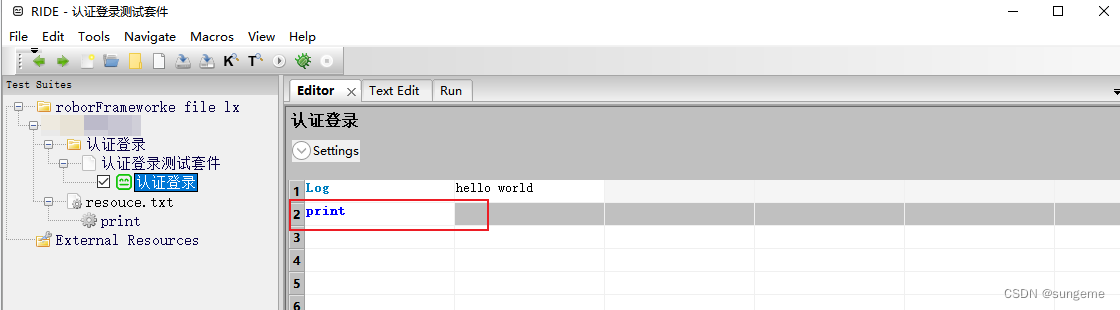
运行:
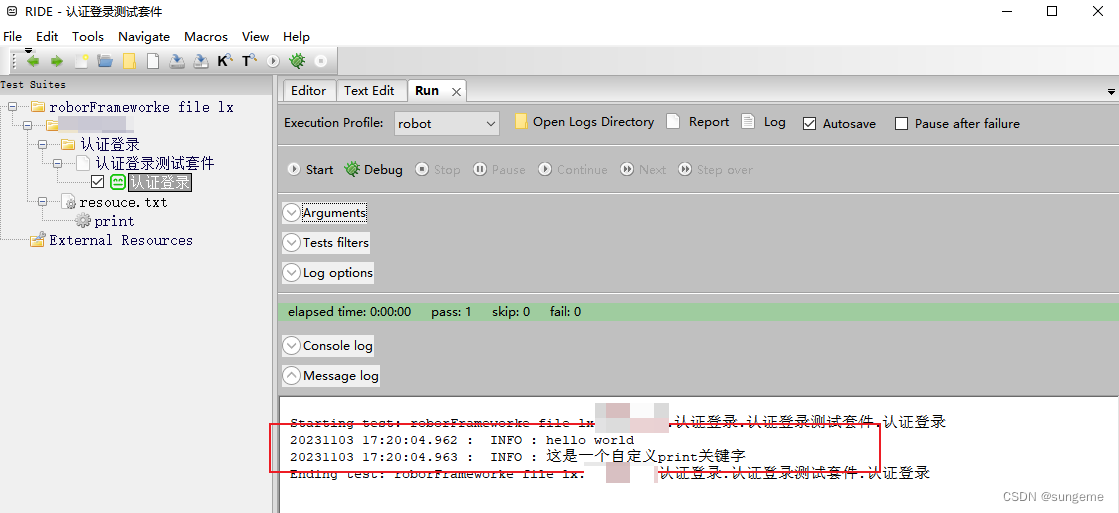
RF常用类库
1、标准库(自带)
安装位置:python根路径+\Lib\site-packages\robot\libraries
BuitIn(测试库)
Collections(集合)
Datatime(时间库)
2、扩展库(通过pip安装)
安装位置:Lib\site-packages
例如要做WEB自动化,就必须要引入新的库,例如SeleniumLibrary
安装:pip install robotframework-seleniumlibrary
接口自动化:ReqiestsLibrary
安装:pip install robotframework-requests
APP自动化:APPiumLibrary
安装:pip install robotframework-appiumlibrary
关键字
查看库的关键字(F5)
查看关键字的信息:
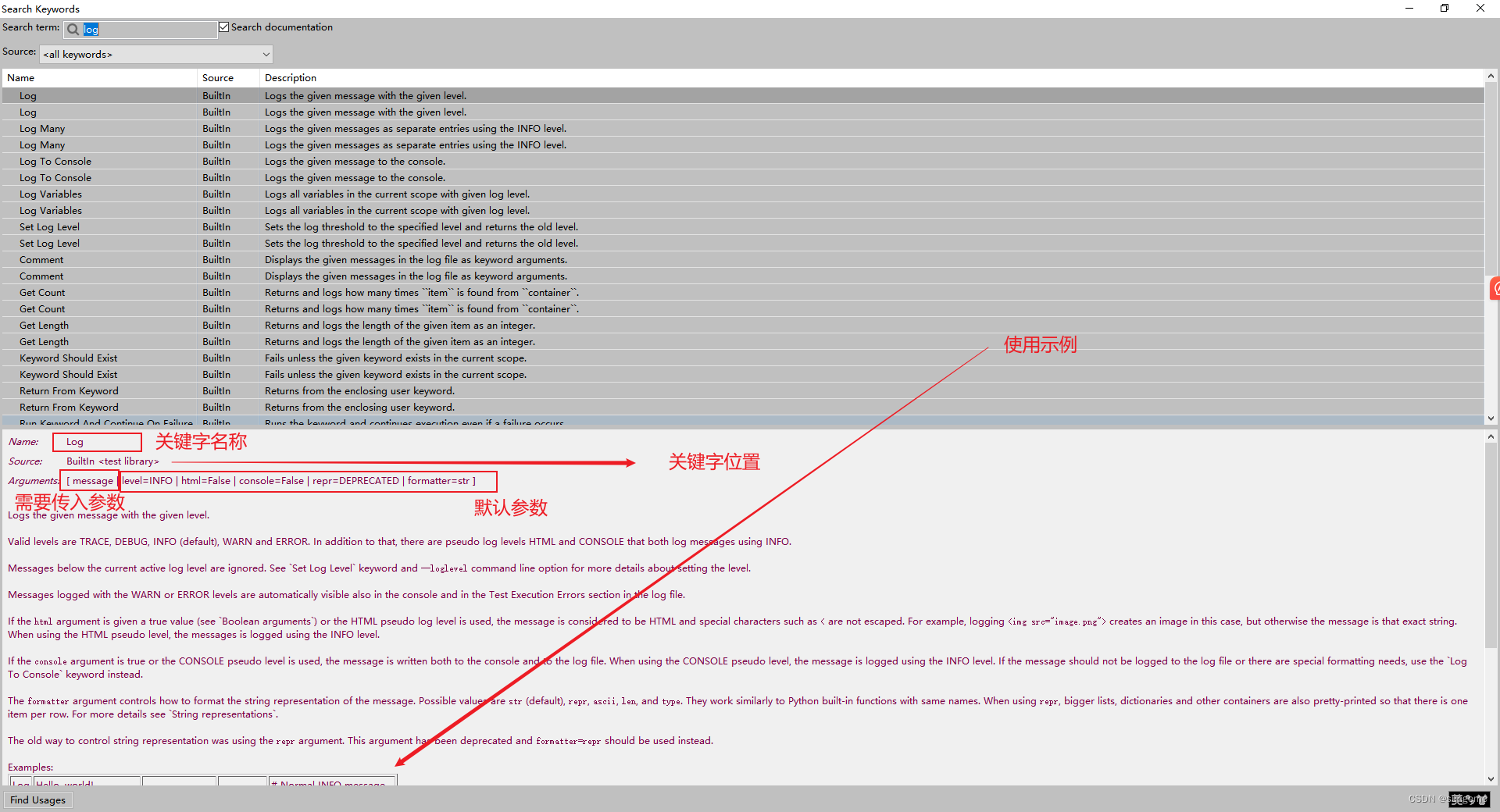
常用关键字
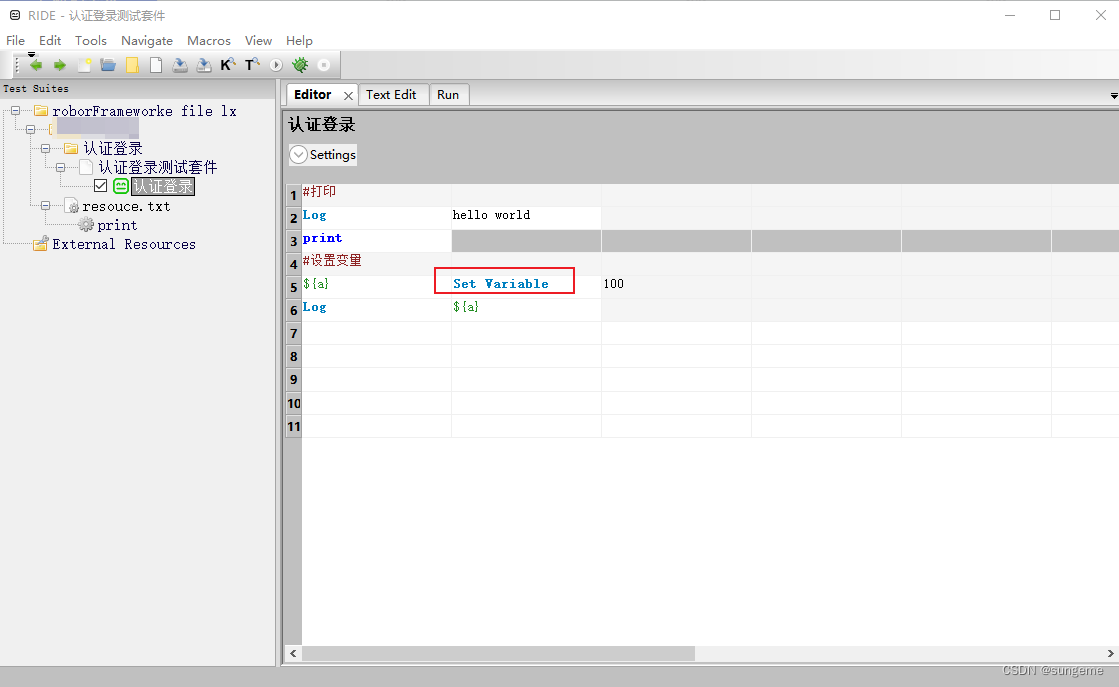
1.打印:Log hello world #打印
2.设置变量:${a} Set Variable 100 #设置值为100的变量${a}
3.获得系统时间 ${time} Get Time #获取时间给变量${time}
4.强制等待:sleep 2 #强制等待2秒
5.字符串拼接:${str} 暗物质 蛋糕 以及石头
自定义关键字的使用在“建立项目”目录中
集合关键字
1.${列表变量名}、@{列表变量名}创建列表
关键字格式:${list} Create List apple orange banana
打印关键字:Log ${list}
输出结果:\['apple', 'orange', 'banana'\]
2.@{list}创建列表,必须用Log Many打印,更利于做循环
关键字格式:@{list} Create List apple orange banana
打印关键字:Log Many @{list}
日志:
@{list} = \[ apple | orange | banana \]
apple
orange
banana
2.${字典变量名}创建字典
${dict} Create Dictionary 苹果=apple 红色=red
Log ${dict}
输出结果:
${dict} = {'苹果': 'apple', '红色': 'red'}
{'苹果': 'apple', '红色': 'red'}
获取所有的key
get dictionary Keys
如果按快捷键,没有出来提示,说明当前没有引入包含这个关键字的库
加入集合库
加入集合库需要在测试套件里面加:
1.进入测试套件
2.点击Library(用来导入外部资源文件)
3.直接输入集合标准库Collections(集合)
获取所有的值
${values} Get Dictionary Values ${dict}
Log ${values}
通过key获取value
${key\_value} Get From Dictionary ${dict} 苹果
Log ${key\_value}
其他(python)关键字
1、调用python方法Evaluate
第一行:${random\_int}(设置变量名) Evaluate(调用python方法关键字) random.randint(1,10)(使用方法) modules=random(导入方法)
2、调用外部.py文件关键字 Import Library
首先用Import Library导入.py文件
注意导入的时候有个坑,在资源管理器直接复制文件路径,路径分隔符用的是\\斜杠,但是RIDE无法识别,要替换成/斜杠,例如:E:Project/test.py
示例:现在有一个py文件,内容如下:
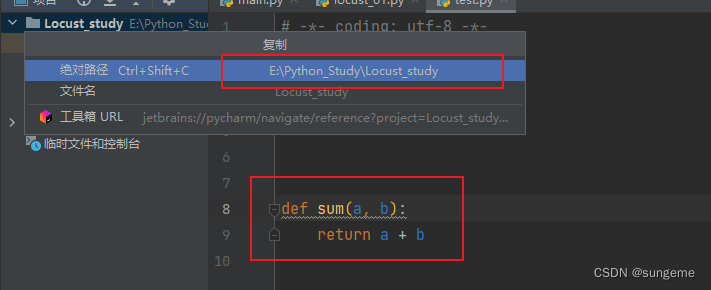
注意:
-
复制路径时要把\改为/
-
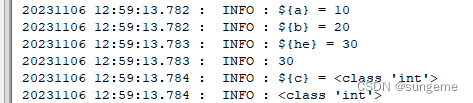
RIDE里面要对数字进行转换,否则只能拼接,因为默认是字符串

运行日志:
3、流程控制——if结构关键字 Run Keyword If
普通if
if结构,关键字为Run Keyword If
if结构下,进行ELSE IF,需要在第一个格子加三个点...,来表示这是一个执行区域
示例:

结果:
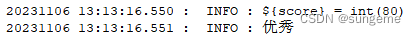
如果if后面是多条件判断,可以用and:

嵌套if
需要在自定义关键字中单独定义使用
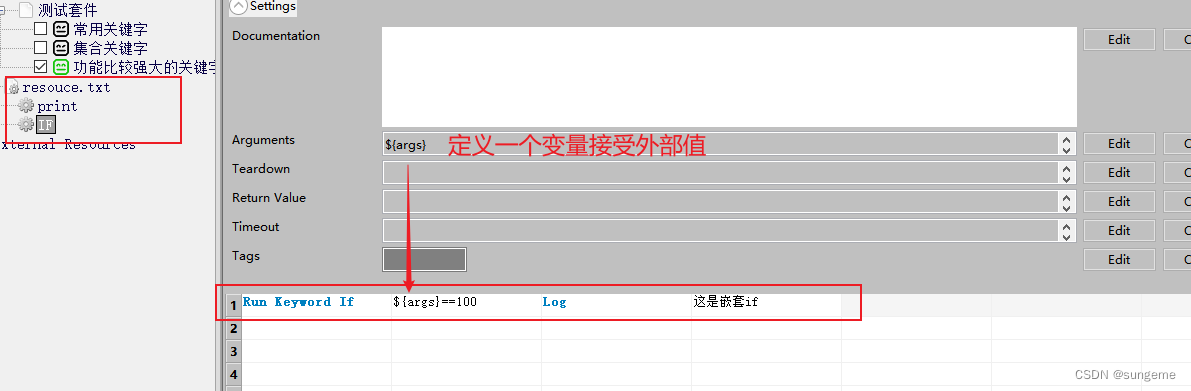
调用时把值传入变量:
运行:

4、FOR循环关键字
普通循环
FOR ${value} IN apple orange banana
Log ${value}
END

循环容器
@{list} Create List apple1 orange2 banana3
FOR ${value} IN @{list}
Log ${value}
END

循环加if
FOR ${value} IN RANGE 1 11
Run Keyword If ${value}==5 Exit For Loop
Log ${value}
END

SeleniumLibaray-Web_UI应用
准备工作
1、下载谷歌浏览器
2、下载谷歌浏览器驱动,版本需要与谷歌浏览器一致
安装SeleniumLibaray
安装seleniumlibrary库:pip install robotframework-seleniumlibrary
导入
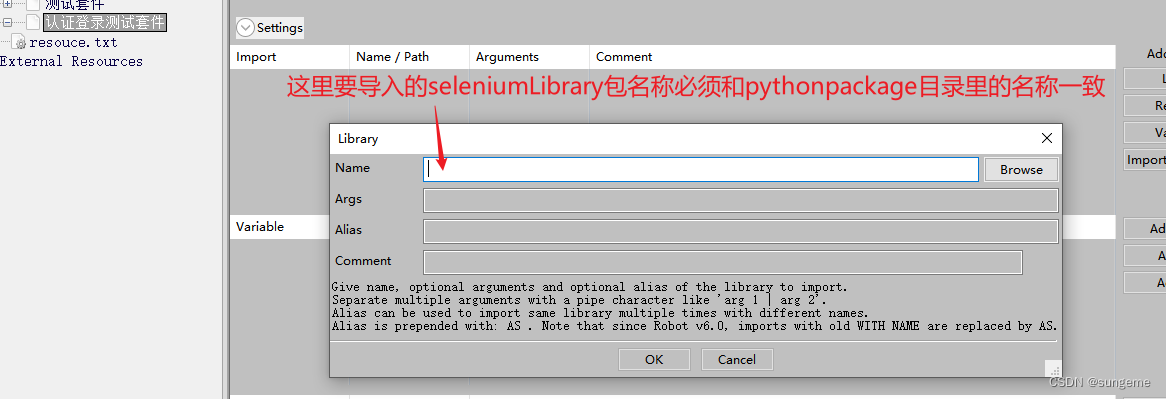
去python目录里复制名称进行导入

导入后:
如果是黑色的就导入成功,是红色的就导入失败

使用SeleniumLibrary库中的基础关键字
#打开浏览器
Open Browser URL chrome
#设置隐式等待
Set Browser Implicit Wait 10
#设置浏览器大小
sleep 2
Set Window Size 1920 1080
#获得窗口大小
sleep 2
${width} ${height} Get Window Size
Log ${width}
Log ${height}
#返回上一步
sleep 2
Go Back
sleep 2
#前进一步
Go To https://login.netease.com/accounts/login
sleep 2
#刷新
Reload Page
#获得标题
sleep 2
${title} Get Title
#获取路径
sleep 2
${location} Get Location
#关闭浏览器
Close Browser
元素定位
八大元素定位方式:https://www.cnblogs.com/renshengruxi/p/12511654.html
XPath定位方法学习:https://zhuanlan.zhihu.com/p/342903085
robotFramework元素定位方式:https://www.jianshu.com/p/69ecaa14325e
robotFramework常用断言:https://blog.youkuaiyun.com/u013250071/article/details/118027199
SeleniumLibrary关键字参考:http://testingpai.com/article/1595507246622
示例使用
注:当元素定位不到时,可能是什么原因?
1.查看页面是否加载完成
2.查看这个元素是否有特殊的属性,例如:disabled,readonly,style="display:none"
3.可能会有frame或者iframe嵌套框架,直接定位是定位不到的,需要切换
frameset是框架集,frame框架,iframe子框架
4.可能是一个动态元素,随机变化
5.代码是否写的不对:需要确认定位方式、定位信息、所在页面正确
6.没有加合理的等待,有时我们的网速不好、内存不够页面就会加载不出来
7.浏览器开了新窗体,如:你在 a 页面,打开了 b 页面,这时想操作 b 页面的元素,无法操作,原因就是元素的 driver 有指向,指向的就是 a 页面;这时采取切换窗体,切换浏览器句柄
8.定位到元素后无法操作,可能是遮挡和覆盖,可以利用鼠标悬浮到其他位置,这样遮挡就会消失
9.当你定位到元素后,提示了警告框、提示框,需要先处理这两个框
10.元素是否是可见的,如:元素中有个属性是不可见的,那我们无论如何都是定位不到
11.在当前页面并未展示到目标元素,我们可以利用边滚动边查找的方式
线性demo示例:
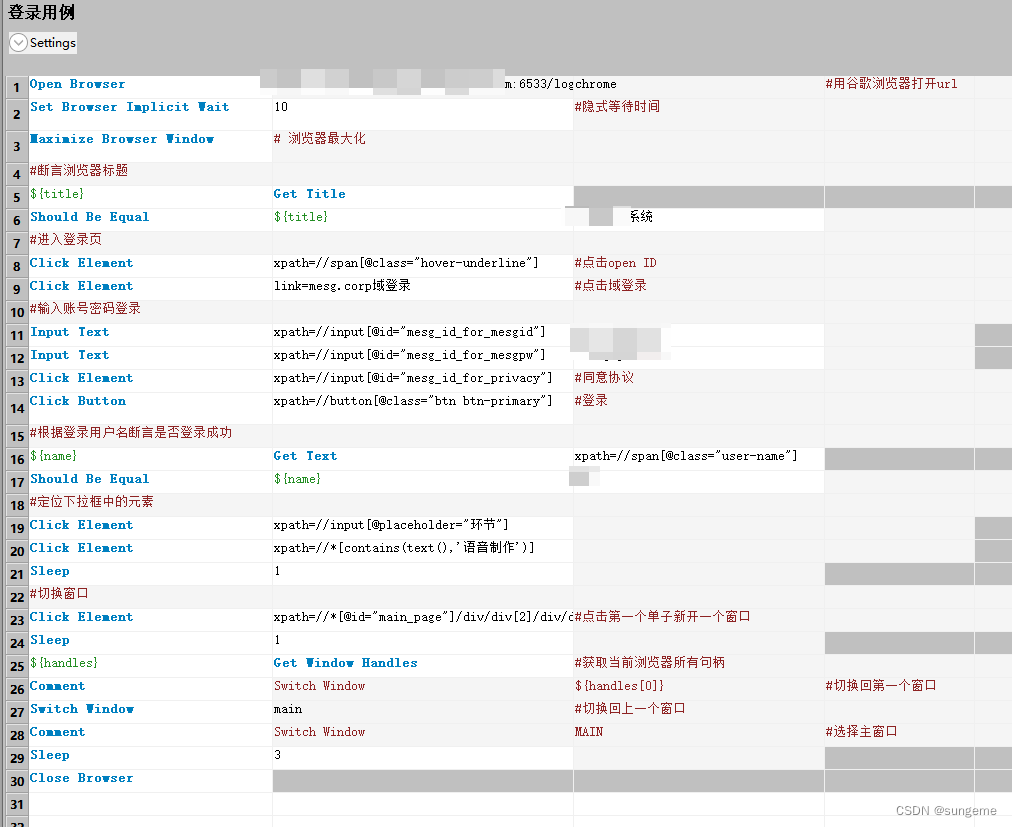
其他UI元素处理方式
1、嵌套
进入嵌套框架
Select Frame 元素表达式
#跳出框架
Unselect Frame
2、下拉框(针对option标签)
#通过下标定位
Select From List By Index 元素表达式 下标数字
#通过文本
Select From List By Label 元素表达式 文本
#通过值
Select From List By Value 元素表达式 value值
3、定位一组元素
有时候元素的属性都一致,需要通过定位一组元素来定位
实例取第n个
${ele\_list} Get WebElements class="el-select-dropdown\_\_item"
Click Element ${ele\_list\[n\]} #下标n为想要定位的那一个元素
4、弹窗处理
js弹窗一般分为三种:
1.alert 只有一个确定按钮
#点击alert的确定按钮
Handle Alert #点击确定
2.confirm 有确定和取消按钮
3.prompt 有确定有取消还可以输入文本
可以新建一个html后缀的文件输入以下代码,在浏览器打开试验一下:
<html>
<head></head>
<body>
<input type="button" onclick="javascript:alert(这是一个alert弹窗)" value="alert弹窗"/>
<input type="button" onclick="javascript:confirm(这是一个confirm弹窗)" value="alert弹窗"/>
<input type="button" onclick="javascript:prompt(这是一个prompt弹窗)" value="alert弹窗"/>
<body>
<html>
可以在RIDE里面搜索一下alert看一下如何处理这一类弹窗,其他的一样
5、浏览器窗口切换
注意事项:以前切换浏览器的关键字是select window by handle,但在新版的seleniumLibrary库里,此关键字已失效。这里使用的是seleniumLibrary6.1.3,切换浏览器的关键字为:Switch Window
示例:
#切换窗口
1、Click Element 元素表达式 #通过点击or其它时间新开一个窗口
2、Sleep 1
3、${handles} Get Window Handles #获取当前浏览器所有句柄,等同于Selenium的driver.window\_handles
4、Switch Window ${handles\[0\]} #切换回第一个窗 等同于Selenium的
5、Switch Window MAIN #选择主窗口(如果有需要可以使用MAIN值切换到第一个窗口)
switch\_to.window()
特殊场景
1、执行js脚本
操作UI页面的元素,总是会不时的报出各种异常,例如执行自动化脚本时,从下拉列表中选择其中某一项,有可能就回报一个元素不可交互的错误Element not interactable : has no size and location,这种一般是元素在页面被隐藏,加了延时和采用了鼠标去悬浮(RF里有个关键字叫mouse over也就是selenium的move\_to\_element),但都没有解决这个问题,这个时候一般会用js去执行。
-
js中的元素定位,像通过id,name等,在实际项目中,太理想了,一般通过这种方法都基本定位不到,所以往往会采用更复杂的方式去定位才能找到,例如xpath和css
-
RF的第三方库SeleniumLibrary有一个关键字叫[Execute Javascript], 它可以执行js脚本,也可以是js文件
示例:

这样就可以去进行js脚本的运行,当然也可以单独封装,把会变动的值当做参数传入,更灵活,例如当Selenium无法点击时,如果要用js,就可以封装元素点击方法:
js点击方法封装
Execute Javascript document.evaluate('${locator}',document, null, XPathResult.ORDERED\_NODE\_SNAPSHOT\_TYPE, null).snapshotItem(0).click()
技巧:
如果不确定自己的js写的对不对,可以在开发者工具中的控制台进行验证:
滚动条操作
1、操作浏览器滚动条
如果是浏览器自带的滚动条,直接使用window.scrollTo(x,y)
示例:
Execute Javascript window.scrollTo(0,1000) #向下移动1000个像素
window.scrollTo(0, document.body.scrollHeight) #滑动到最底部
window.scrollTo(200, 0) #横向移动
2、操作页面内部滚动条
注:如果body的高度为 100% 后,它的内容高度就被限制成跟视窗一样的高度了。这时候无法超出视窗范围,所以使用window.scrollTo(x,y)是会失效的,要用别的方法操作内嵌的页面滚动条
所以要换另一种方法,对内嵌滚动条进行操作
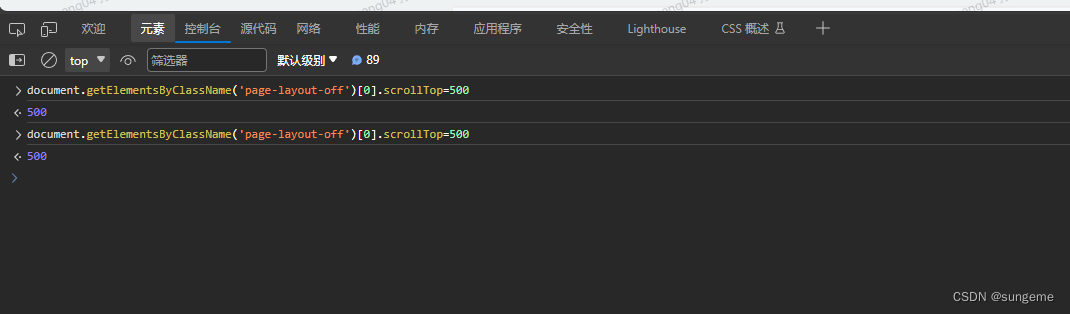
1、先右键检查滚动条

2、得到所在的class类名,操作内嵌滚动条
Execute Javascript document.getElementsByClassName('滚动条所在类名')\[0\].scrollTop=500
2、js弹窗处理
Handle Alert关键字
1、Handle Alert #默认点击确定
2、Handle Alert DISMISS #点击取消
3、Handle Alert LEAVE #保持打开
4、${message} Handle Alert #接受警报并获取信息,可用于断言
3、鼠标键盘事件
键盘
模拟按键:Press Keys
注:Press Key在SeleniumLibrary 4.0版本中已启用
作用:对定位元素模拟用户按键
参数:两个必选参数locator定位符和key按键
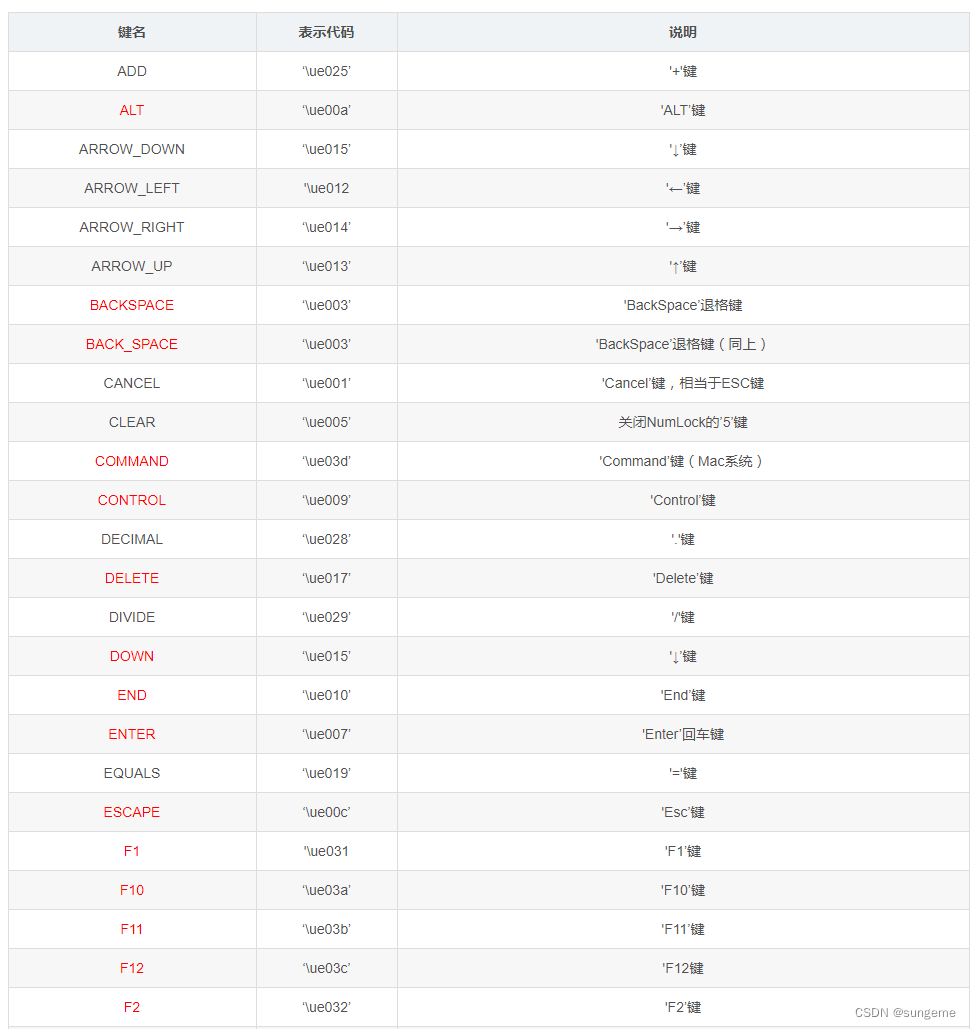
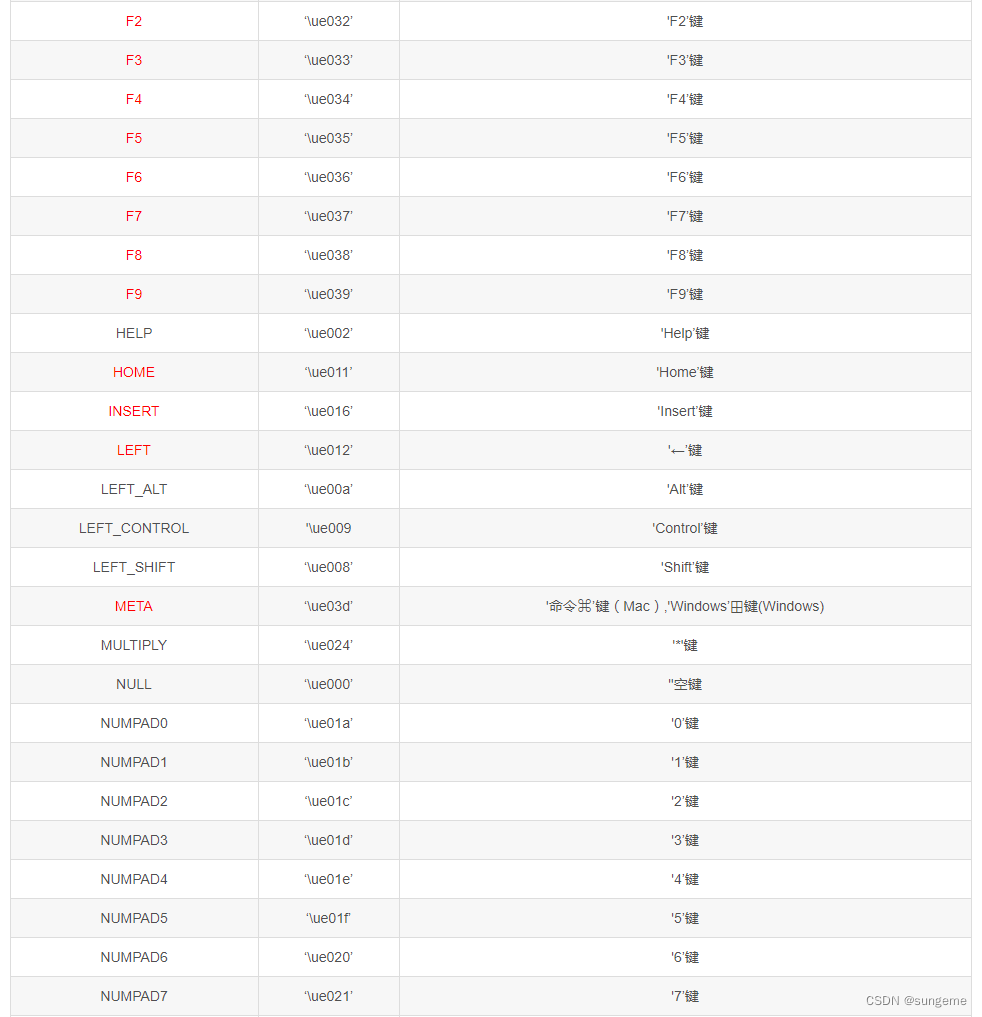
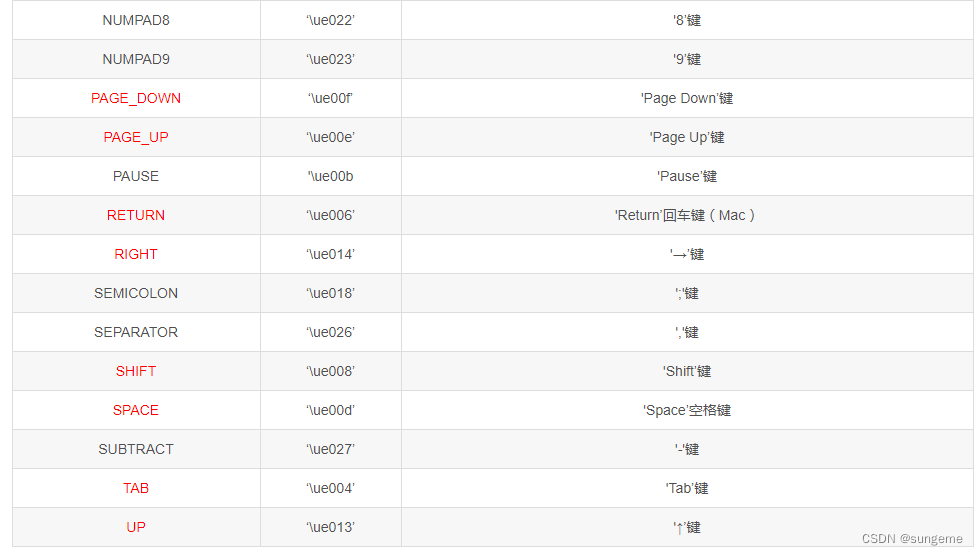
key:按键可以是一个字母、或者\\开始的按键的ASCII码值
关键字说明:

示例:向当前活动浏览器发送Enter键(如果只是操作按键,无需写元素表达式,用None代替,作用域为当前窗口)

按键ASCII码值:
鼠标
SeleniumLibrary提供了一组关键字来模拟鼠标操作,如点击、悬停、拖放等。
Click Element:单击指定的元素。
Double Click Element:双击指定的元素。
Right Click Element:右击指定的元素。
Mouse Down On Element:在指定的元素上按下鼠标按钮。
Mouse Up On Element:在指定的元素上释放鼠标按钮。
Mouse Over:将鼠标悬停在指定的元素上。
Drag And Drop:拖放一个元素到另一个元素。
示例:
\*\*\* Settings \*\*\*
Library SeleniumLibrary
\*\*\* Test Cases \*\*\*
Mouse Operations
Open Browser URL chrome
Click Element xpath=//button\[@id='myButton'\] # 单击指定的按钮
Double Click Element css=#myElement # 双击指定的元素
Right Click Element id=myElement # 右击指定的元素
Mouse Down On Element xpath=//div\[@class='drag-source'\] # 在源元素上按下鼠标按钮
Mouse Up On Element xpath=//div\[@class='drop-target'\] # 在目标元素上释放鼠标按钮
Mouse Over xpath=//a\[@class='tooltip'\] # 将鼠标悬停在链接上
Drag And Drop xpath=//div\[@id='source'\] xpath=//div\[@id='target'\] # 拖放元素从源到目标
Close Browser
4、断言(SeleniumLibrary断言和RF系统断言)
SeleniumLibrary常见:
Page Should Contain Element:断言页面中存在指定的元素。
Page Should Not Contain Element:断言页面中不存在指定的元素。
Element Should Be Visible:断言指定元素可见。
Element Should Not Be Visible:断言指定元素不可见。
Element Should Be Enabled:断言指定元素可用。
Element Should Be Disabled:断言指定元素不可用。
Element Text Should Be:断言指定元素的文本内容。
Element Should Contain:断言指定元素包含指定文本。
Element Should Not Contain:断言指定元素不包含指定文本。
Title Should Be:断言页面标题。
Robot Framework(RF)系统内置常用:
Should Be True:断言一个条件为真。
Should Be False:断言一个条件为假。
Should Be Equal:断言两个值相等。
Should Not Be Equal:断言两个值不相等。
Should Be Equal As Numbers:断言两个数值相等。
Should Be Equal As Strings:断言两个字符串相等。
Should Contain:断言一个字符串包含另一个字符串。
Should Not Contain:断言一个字符串不包含另一个字符串。
Should Match:断言一个字符串匹配指定的模式。
Should Not Match:断言一个字符串不匹配指定的模式。
5、各种等待
默认情况下,Selenium会自动等待页面加载完成
-
隐式等待:Set Selenium Implicit Wait
-
显示等待:Wait Until Keyword Succeeds
SeleniumLibrary常见:
Wait Until Element Is Visible:等待直到元素可见。
Wait Until Element Is Not Visible:等待直到元素不可见。
Wait Until Element Is Enabled:等待直到元素可用。
Wait Until Element Is Disabled:等待直到元素不可用。
Wait Until Page Contains Element:等待直到页面包含指定元素。
Wait Until Page Does Not Contain Element:等待直到页面不包含指定元素。
Wait Until Element Contains:等待直到元素包含指定文本。
Wait Until Element Does Not Contain:等待直到元素不包含指定文本。
Wait Until Element Attribute Contains:等待直到元素属性包含指定值。
Wait Until Element Attribute Does Not Contain:等待直到元素属性不包含指定值。
Robot Framework(RF)系统内置常见:
Wait Until Keyword Succeeds:等待直到关键字执行成功。
Wait Until Keyword Fails:等待直到关键字执行失败。
Wait Until Page Contains:等待直到页面包含指定文本。
Wait Until Page Does Not Contain:等待直到页面不包含指定文本。
Wait Until Element Is Visible:等待直到元素可见。
Wait Until Element Is Not Visible:等待直到元素不可见。
Wait Until Element Is Enabled:等待直到元素可用。
Wait Until Element Is Disabled:等待直到元素不可用。
Wait Until Element Contains:等待直到元素包含指定文本。
Wait Until Element Does Not Contain:等待直到元素不包含指定文本。
6、特殊场景
1)文件上传
如果我们按照用户的操作来上传文件,步骤会非常繁琐,而且操作系统的文件夹操作需要另一个库AutoItLibrary的支持,来对操作系统窗口定位和操作,非常麻烦。
这里我们有一个更好的选择,分析上传文件按键的html代码,它实质上是一个<input>元素。

那么我们可以直接对它input text,输入的文本就是文件的路径。

2)单选框RadioBox和复选框CheckBox操作
注:当有时click element locator和select checkbox locator无法选择框体时,可以尝试按键操作press key \\ue00d表示按下空格键。关键字表示:焦点放在单选框后 自动按下空格键
单选框:
单选框RadioBox的操作比较简单,直接按照用户逻辑,要选哪项直接click就可以了
复选框:
复选框CheckBox的操作稍微麻烦一点,麻烦不在点击动作本身,而是复选框是可以取消点击的。
第一次点击是选中,第二次点击是取消,所以在点击之前最好确定被点击的选项是否已经被选中。
判断框体是否存在于页面:
使用"Page Should Contain Element"关键字来检查复选框是否存在于页面上
例如:
Page Should Contain Element xpath=//input\[@type='checkbox'\]
判断复选框是否被选中:
使用"Get Element Attribute"关键字获取复选框的"checked"属性值。如果该属性值为"true",则表示复选框被选中;如果为"false"或属性不存在,则表示复选框未被选中。
示例:
${checked} Get Element Attribute xpath=//input\[@type='checkbox'\]@checked # 获取复选框的"checked"属性值
Run Keyword If '${checked}' == 'true' Log 复选框被选中 # 如果复选框被选中,则输出日志
Run Keyword If '${checked}' == 'false' or '${checked}' == '' Log 复选框没有被选中或不存在 # 如果复选框未被选中,则输出日志
分层
Web自动化中,针对于用例,可以采用POM模式进行封装解耦合,可以提高测试脚本的可维护性、可读性和可重用性。
POM模式将页面对象抽象为独立的类,每个页面都有对应的页面对象,封装了页面的元素和操作,使测试脚本与页面的实现细节分离。
特点
1.分离页面和测试逻辑:POM模式将测试脚本与页面的实现细节分离,使测试脚本只关注测试逻辑,而不需要关注页面的具体实现细节。这样可以提高测试脚本的可读性和可维护性。
2.封装页面元素和操作:每个页面都有对应的页面对象,页面对象封装了页面的元素和操作方法。测试脚本可以直接调用页面对象提供的方法来执行操作,而不需要关心元素的定位和操作细节。这样可以提高测试脚本的可重用性和可靠性。
3.高度可维护性:由于页面对象封装了页面的元素和操作,当页面发生变化时,只需要修改页面对象的代码而不需要修改大量的测试脚本。这样可以减少维护成本并提高测试脚本的稳定性。
分层设计
不分层的时候:线性的脚本对于后期的维护很不利,数据是没有独立的
目的:
提高自动化测试的效率、可维护性和可扩展性。
1.提高效率:自动化分层可以根据测试的优先级和需求,有选择地执行不同层次的测试。这样可以节省执行时间和资源,并集中精力于关键的测试场景。
2.提高可维护性:通过将测试脚本按照功能和层次进行组织,自动化分层设计使得测试脚本更易于维护。当应用程序发生变化时,只需要修改相关层次的测试脚本,而不需要修改所有的测试脚本。
3.提高可复用性:提高测试脚本的可复用性。通过将通用的功能和操作封装到底层的模块中,可以在不同的测试脚本中重复使用这些模块,提高测试脚本的复用性和效率。
4.提高可扩展性:允许根据需要添加新的层次和功能模块,当应用程序的功能增加或变化时,可以扩展测试框架,添加新的测试层次和模块,而不会对现有的测试脚本产生太大影响。
5.提高可读性和可理解性:通过将测试脚本按照功能和层次进行组织,自动化分层设计让测试脚本更易于阅读和理解。每个层次的测试脚本关注特定的功能和目标,使得测试脚本更加清晰和可读。
UI自动化大体可以分为几个层次:页面元素层(资源文件),业务逻辑层(基于页面元素层),测试用例层(这一层可以做数据驱动)
分层:页面元素层(资源文件),业务逻辑层(资源文件),测试用例层(测试套件)
-
注意分层时有个bug:
-
当一个目录下没有测试套件的时候,例如这个只有资源文件
-
那么重启RIDE时,将不会显示这个资源文件,看起来这个目录好像空的一样。
-
要么创建一个占位的空测试套件,要么把这个txt资源文件先导入其他目录中,就会显示了
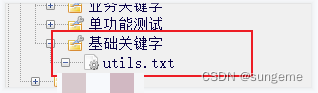
公共部分
1.为每个关键字编写关键字定义,针对一些通用操作设计基类,主要是为了提高项目的代码重用性。关键字定义应该包含与页面操作相关的关键步骤,如点击按钮、输入文本等。关键字可以使用Robot Framework的内置关键字或自定义关键字。可用于被元素层调用(SeleniumLibrary等类库进行二次封装)
2.也可也可定义公共的配置变量,例如url,正向的用户名和密码
3.也可以封装一些用例过程中会使用到的通用关键字,如随机生成数据,文件处理等等
示例结构
在这里面,对SeleniumLibrary库进行了二次封装。同时也封装了公共的打开/关闭浏览器的操作,可用于用例的前后置,无需每次都单独创建。
SeleniumLibrary二次封装
为了更方便对元素的操作以及后续维护,二次封装SeleniumLibrary库,提高健壮性
同时也是为了方便后续维护,假如某天,SeleniumLibrary库中的某个方法被放弃了,如果涉及到多个地方,那每一处都需要修改,太麻烦。这里由于进行了二次封装,到时只需要修改此处的资源文件就可以了,其他地方还是引用此处的资源文件,便于管理和维护。
几个思路示例:
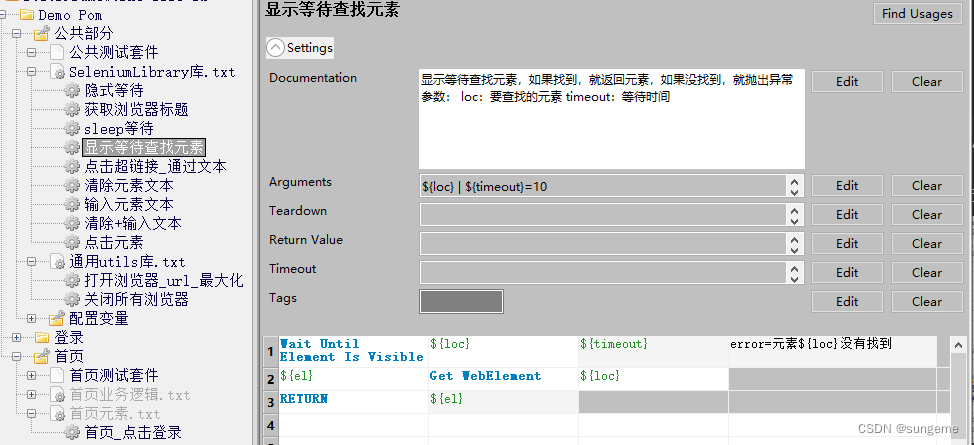
显示等待查找元素
设置显示等待,可以在其他需要查找元素的地方都引用显示等待,先进行元素查找再操作,不然有可能会因为操作过快而导致用例中断报错
由于是通用的方法,所以元素和等待时间设为动态参数,这里时间给了一个默认值
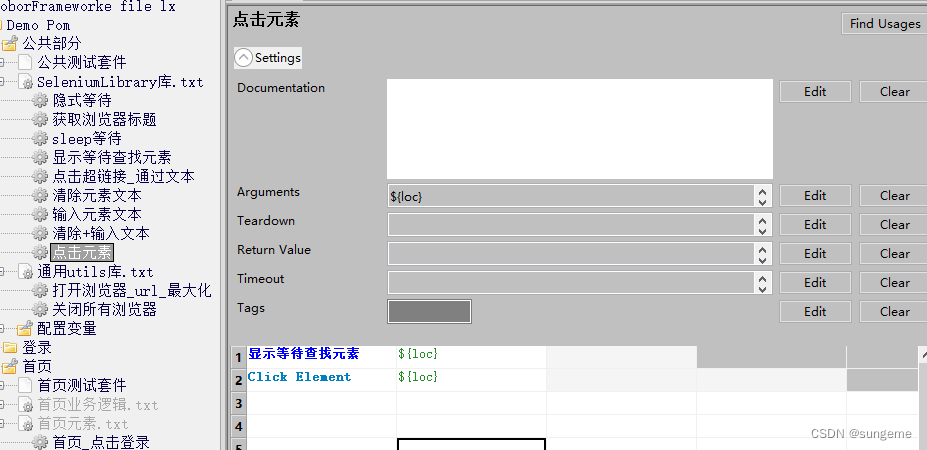
点击元素
引用了显示等待关键字,先对元素进行查找,再进行操作。防止元素还没加载,便进行了点击,从而导致产生报错。
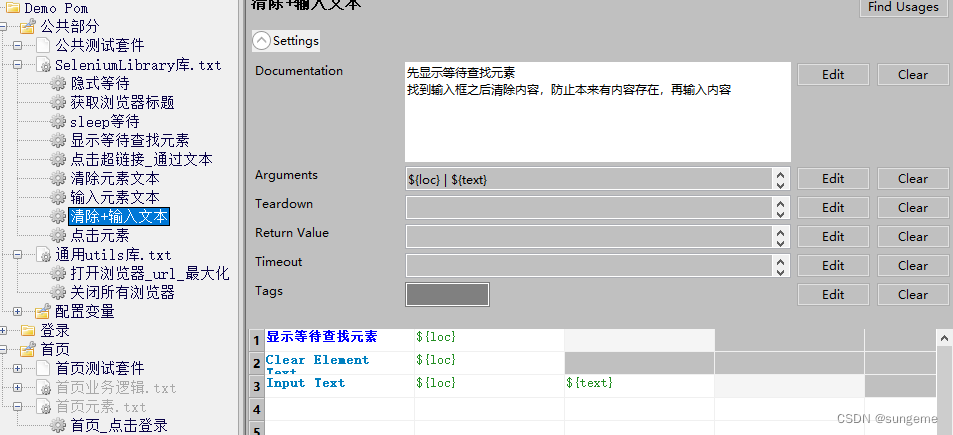
清除+输入文本
先显示等待查找元素
找到输入框之后清除内容,防止本来有内容存在,再输入内容会导致错误产生
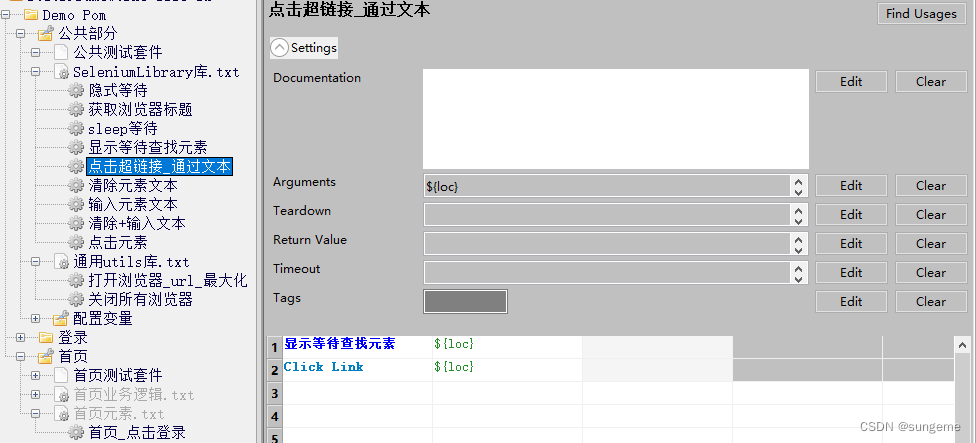
通过文本进入超链接
因为某些按钮会跳转到另一个页面,也就是a标签,超链接,所以可以通过这种方法更便捷的替代Click Element关键字
以上是一些二次封装关键字的示例,只要涉及到需要调用库的时候,都可以对库本身的关键字进行二次封装
Page Objects(创建页面对象)
根据被测试应用程序的不同页面或功能,为每个页面创建一个页面对象,页面对象下还可继续创建子页面。页面对象应该包含与该页面相关的关键元素和操作。可以在Robot Framework中创建一个库文件,用于定义每个页面对象的关键字和操作,想要实现的行为,其中的一些操作可以调用公共部分的关键字。对于一些参数可以预留形参,为DDT创造条件。
1.为每个页面模块创建页面对象,以目录形式体现
2.页面模块下还可以逐层建立子模块
3.在最终要测试的模块下创建分层的载体:
1)元素资源文件(抽离出业务层,单独维护页面的元素,和单一元素的操作,对于参数可以单独预留参数)
2)业务逻辑资源文件(基于元素资源文件,进行业务的组合,以实现想要的行为操作)
3)测试套件(调用定义的业务关键字,进行用例执行)
后续更新维护
如果应用程序的页面结构或功能发生变化,只需更新对应的页面对象和关键字定义即可,而无需修改大量的测试用例。这种模块化的设计使得测试用例更易于维护和重用。
示例
为了方便示例,以百度登录为例
可以看到,打开https://www.baidu.com,进入到百度的首页,如果要进行登录的话,就要在首页对登录按钮进行操作,跳转至登录页面。
这时就可以对首页部分进行页面对象的创建
思路 1.创建页面对象 2.在页面对象下分别创建:首页测试套件、首页元素(资源文件).txt、首页业务逻辑(资源文件).txt
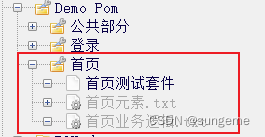
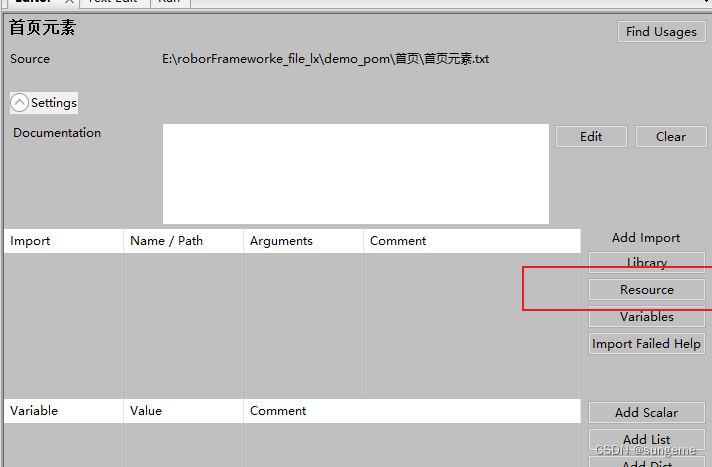
元素层
定义当前页面元素关键字,进行单一元素的操作,提供给业务层进行调用,组合成整个业务业务操作。
注:操作方面如果涉及到操作关键字,就可以使用自己二次封装的库了
在元素层进行封装库的导入
在首页元素中,进行单一操作的关键字定义
如:点击登录
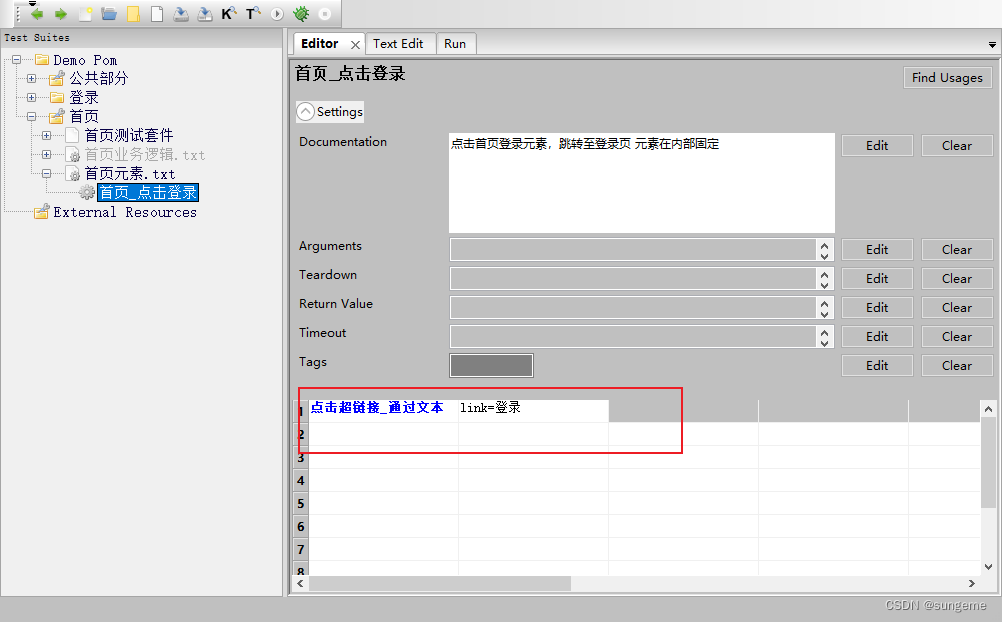
业务层
把元素资源文件,导入到业务逻辑层,使其可以进行业务操作关键字的组成
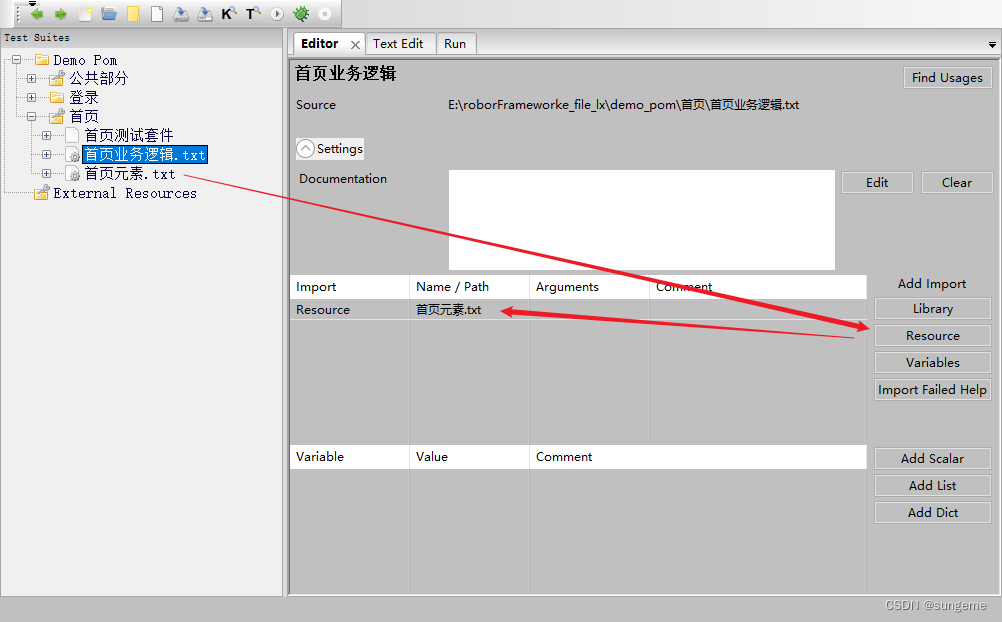
因为这里在首页没有复杂的操作,只点击了一下登录按钮,所以看起来这么封装就好像多此一举。但在实际的项目工程,随着用例和涉及的操作越来越多,不管怎样,还是进行细致的分层比较好。
导入之后根据想要在当前页面进行的操作,进行业务的组装:
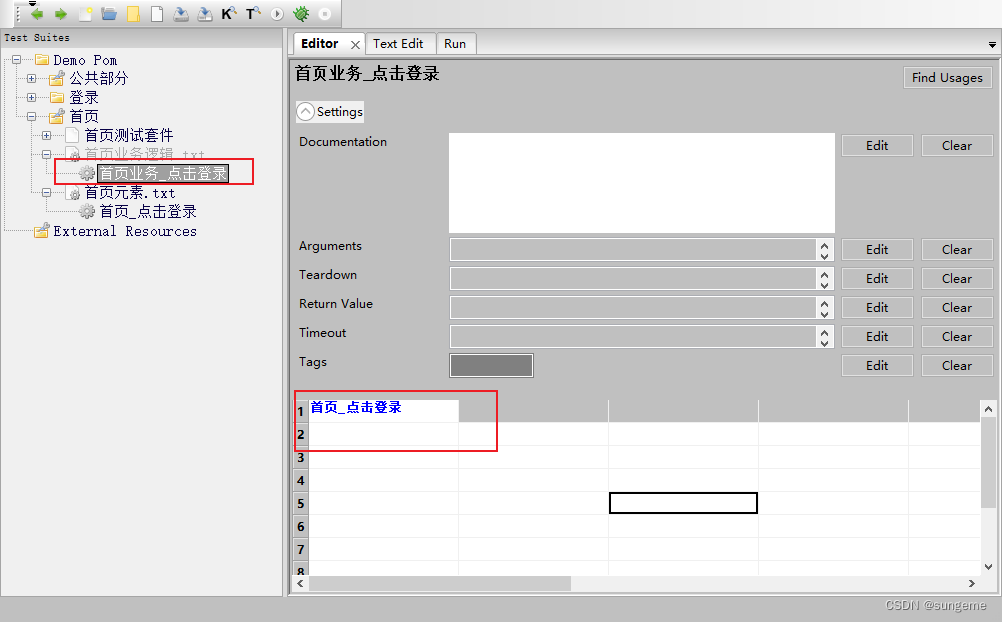
这里也可以对定义的业务关键字进行测验证测试,简单的示例一下
思路:跳转页面后,需要判断是否真的已经跳转,那就要获取登录页的一些信息做判断
既然要获取信息,就要使用到SeleniumLibrary库中的某些关键字,需要进行二次封装

可以看到跳转后的界面是这样的,就可以获取账号登录几个文本来进行判断
在自己的SeleniumLibrary库二次封装获取元素文本关键字
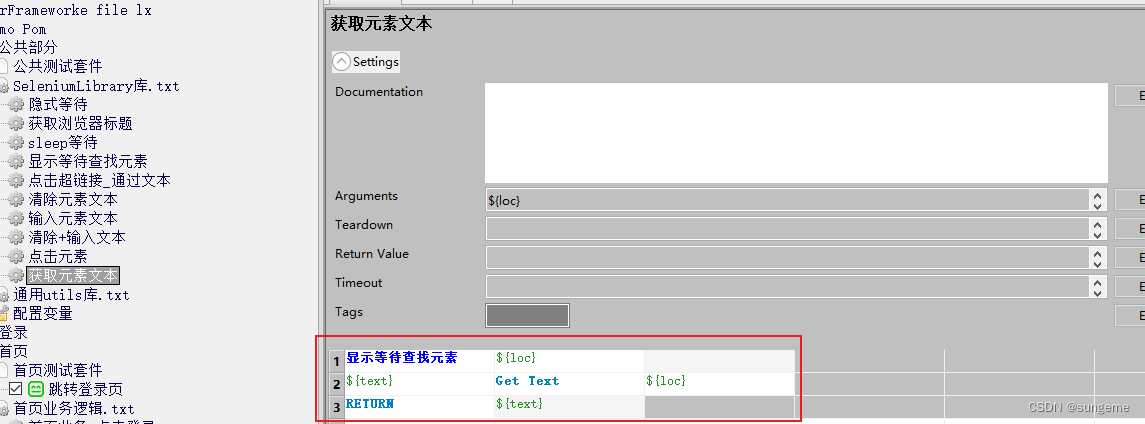
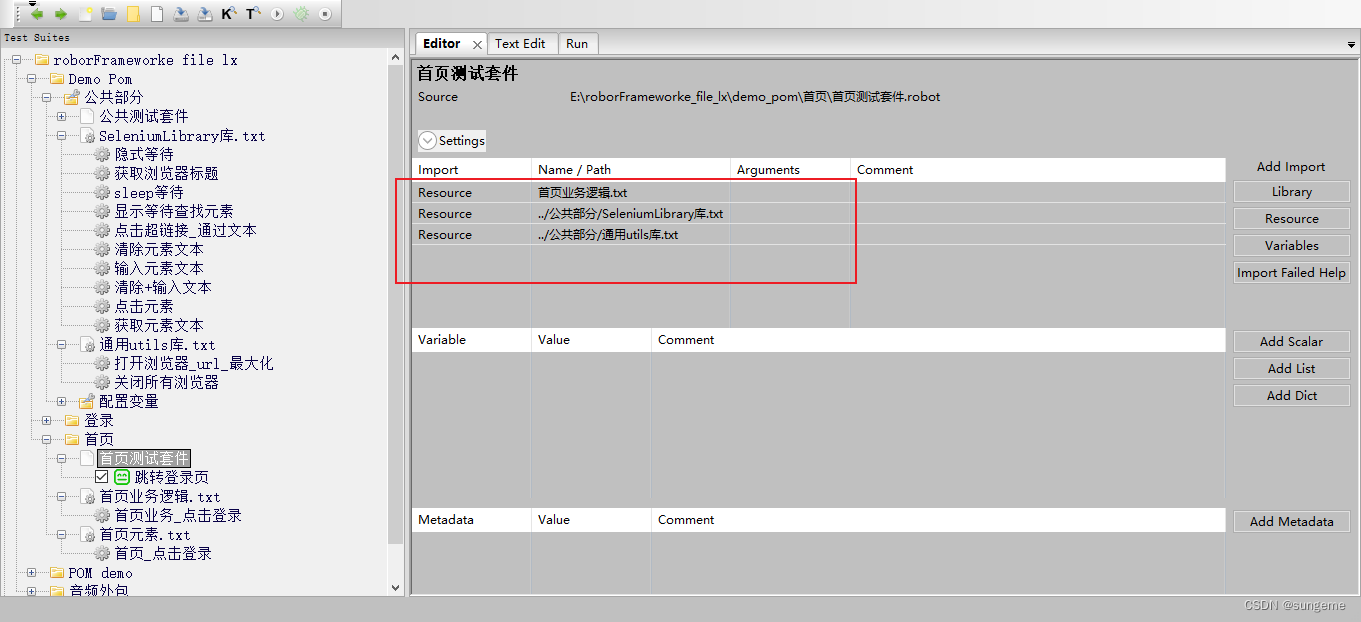
在测试套件中导入需要用到的库
首页业务逻辑:调用定义的业务关键字进行业务操作
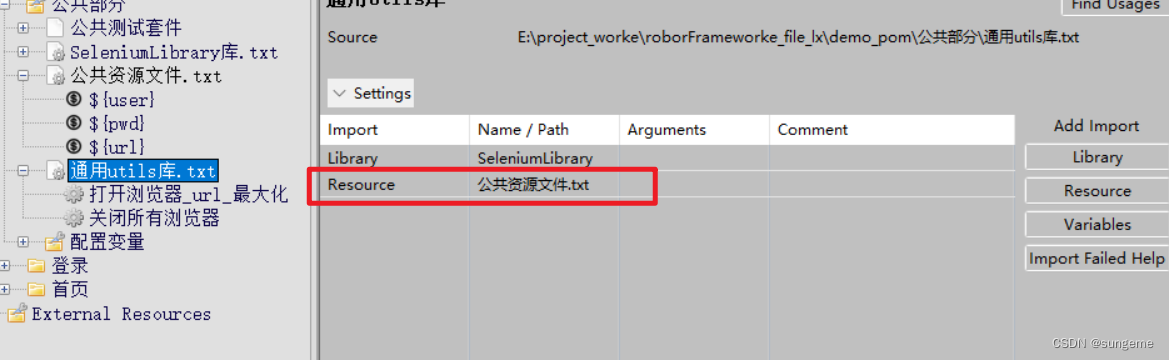
SeleniumLibrary库:这里需要使用到定义的获取元素文本,来进行断言
通用utils库:需要用到这个库中的打开/关闭浏览器操作,作为用例的前后置
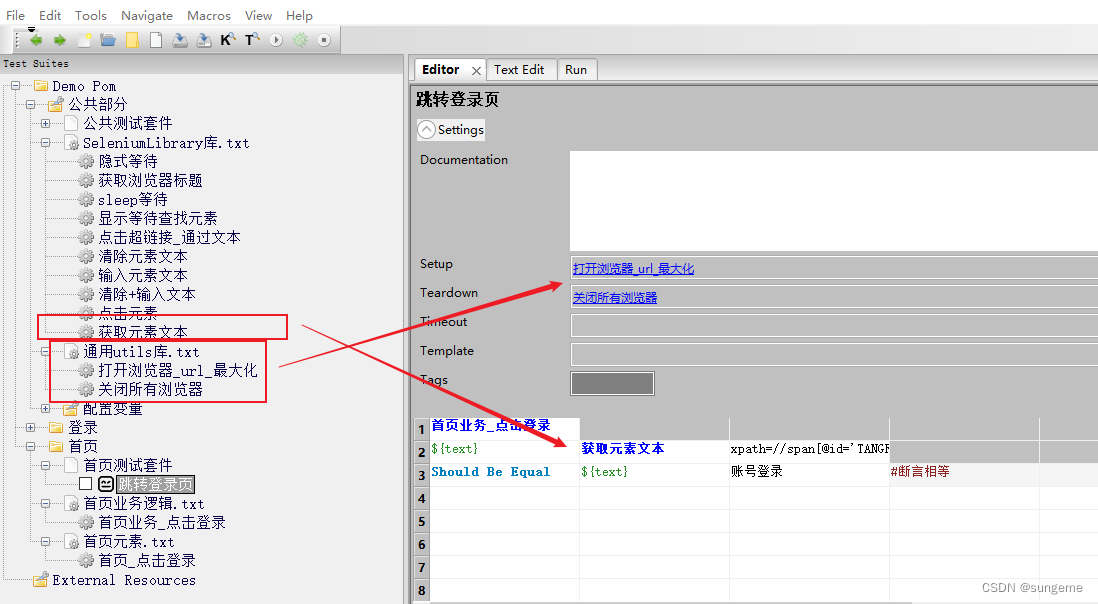
测试用例层
创建一个Test Case,进行用例的编写,并进行断言处理
因为这里只进行了一个点击跳转业务操作,不用考虑数据驱动,所以断言直接在内部处理。
注:某些需要数据驱动的测试(比如登录需要验证不同的账号密码的正确性),比如测试输入框的内容,页面上有很多输入框,在输入框中要输入很多次数据进行验证,负数、0、小数、整数、中文、英文、特殊字符及组合输入。不能说每个输入框、每次输入都写一个测试用例进行验证,通过复制粘贴去修改内容,多麻烦。这时候用上数据驱动,就会省事很多,所以就需要用到数据驱动,输入不同的值,并且用不同的值进行断言,这些都是动态的。
验证了跳转登录页的可行性,再继续完成登录页面的业务:
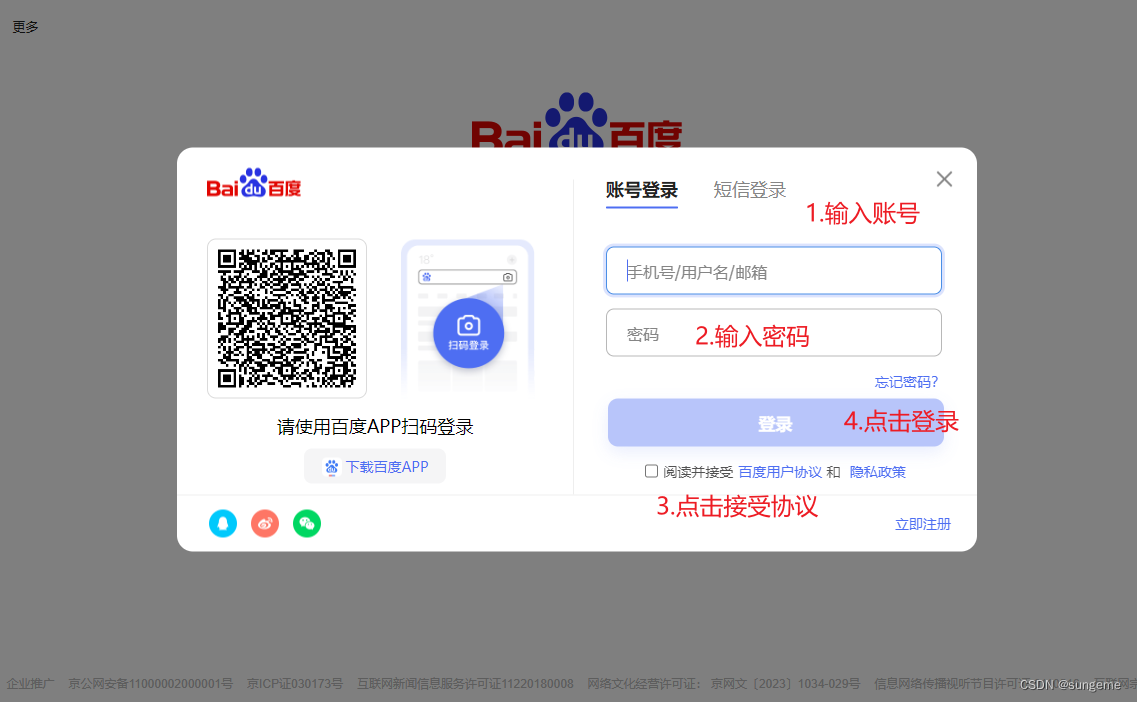
可以看到正向的用例至少要包含这四个步骤,这里以正向用例其中的,手机号登录成功为例
使用和刚才一样的页面分层方法:
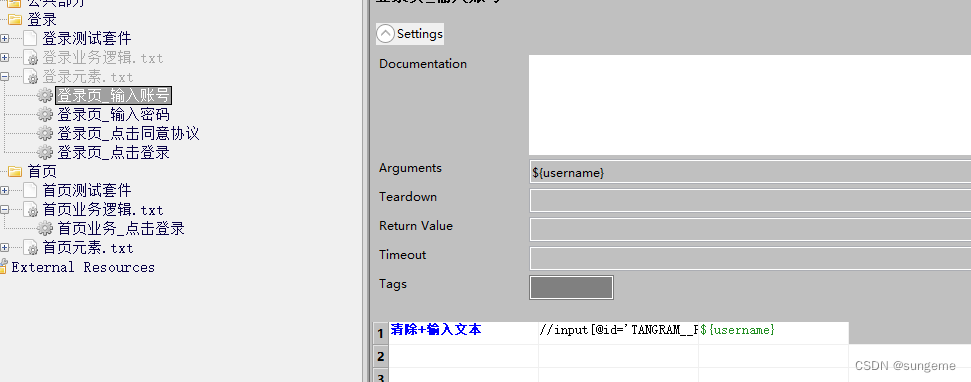
元素层1
1、同样的,先在元素层导入需要使用到的公共库
2、定义每个元素的操作关键字,动态数据可以用参数形式
业务层2
1、在业务层进行操作的封装,导入需要用到的元素层资源文件
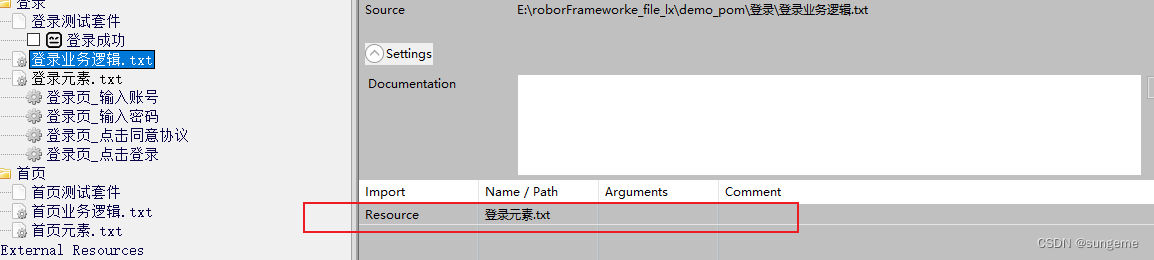
2、进行操作的封装(注意这里登录也许需要用到 从首页跳转至登录页 的操作,所以要在这个资源文件中导入首页业务逻辑,调用首页业务进行业务组合,也是为了方便后续做数据驱动。如果要做数据驱动,那打开/关闭浏览器的操作就需要在业务里体现,不能放在测试套件中)
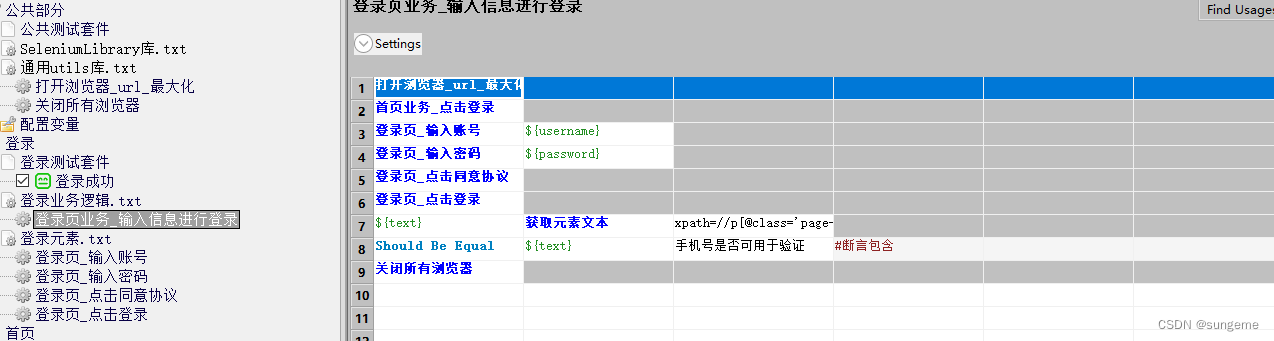
用例层3
1、在用例层测试套件中调用所需要的业务
调用业务层,另外utils库中定义了打开/关闭浏览器的操作作为用例的前后置使用
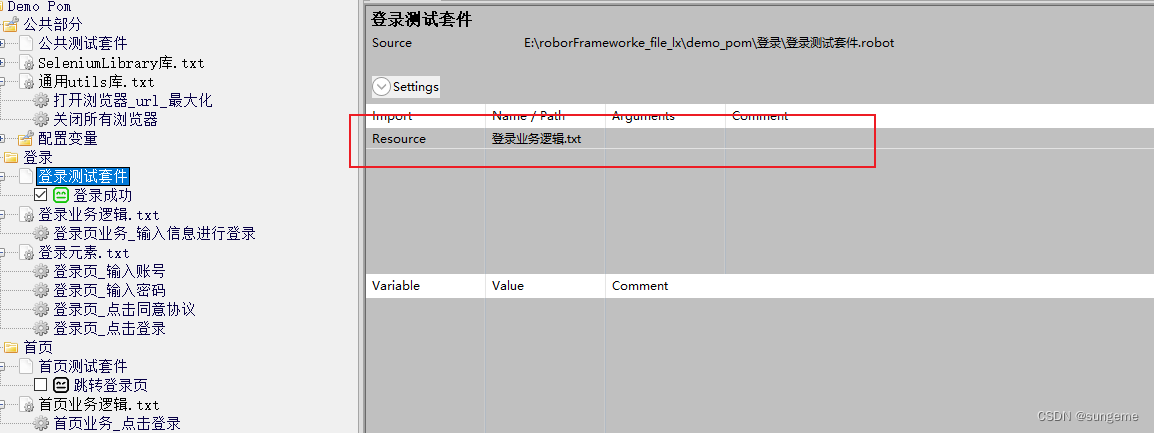
用例层调用业务层实现用例的执行
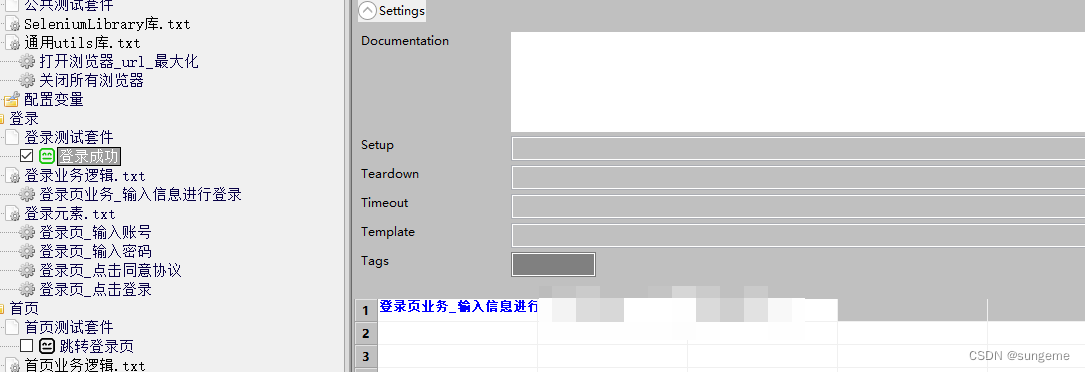
层级关系总结
供给关系:公共类--->元素层--->业务层--->用例层
底层:针对元素的通用操作实现:SeleniumLibrary库和通用utils库
模块层(根据项目的模块进行分层):
1、元素层:针对页面单个的元素操作,统一定义为页面元素关键字,给业务层调用
2、业务逻辑层:针对页面具体想要实现的行为方法,调用元素层的单一操作进行组合,定义为单个业务关键字,业务也就是最终想要实现的测试用例。
--为了更方便后续维护,也是为了减少用例编写的步骤冗余,尽量把每个页面单独定义为关键字。例如这个登录,需要打开首页,再点击登录,那就可以把首页的操作,单独定义在首页模块里,其他地方(如其他业务文件)需要使用到首页里的操作,直接调用资源文件就好了,不用每次都要单独写一遍,很大程度减少了冗余编写时间。
3、测试用例层:调用业务层的方法,组合实现想要的用例
设置公共资源变量
有时一些常量,可以使用公共变量管理起来。用例里面调用变量名即可,防止后续如果发生更改,就要一个用例一个用例去找。例如正向用户名和密码,如果密码进行了变更,就不用一条一条去修改了,直接改动变量值即可,方便维护
1、在公共部分进行新增变量
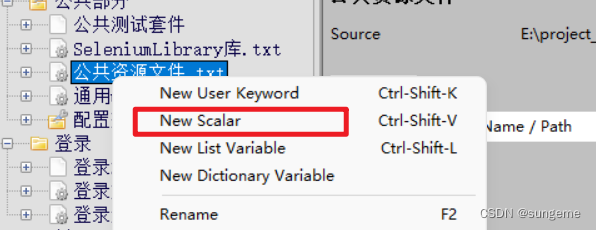
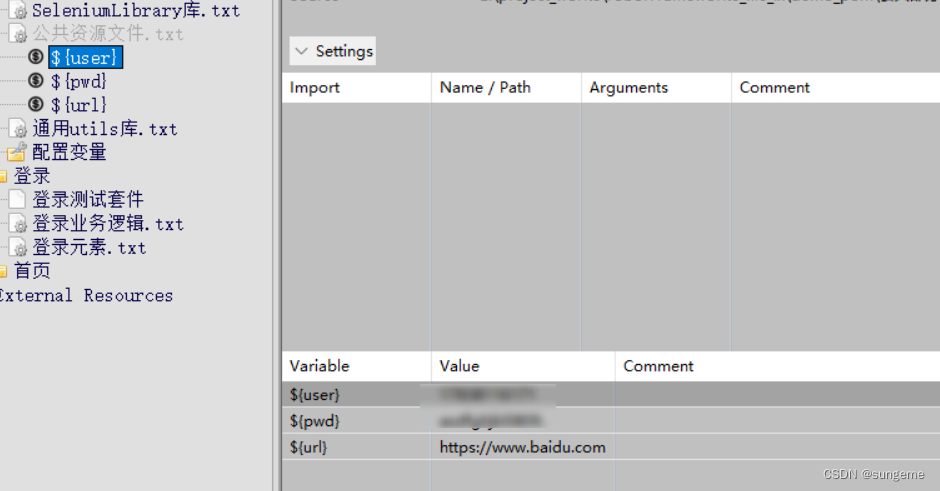
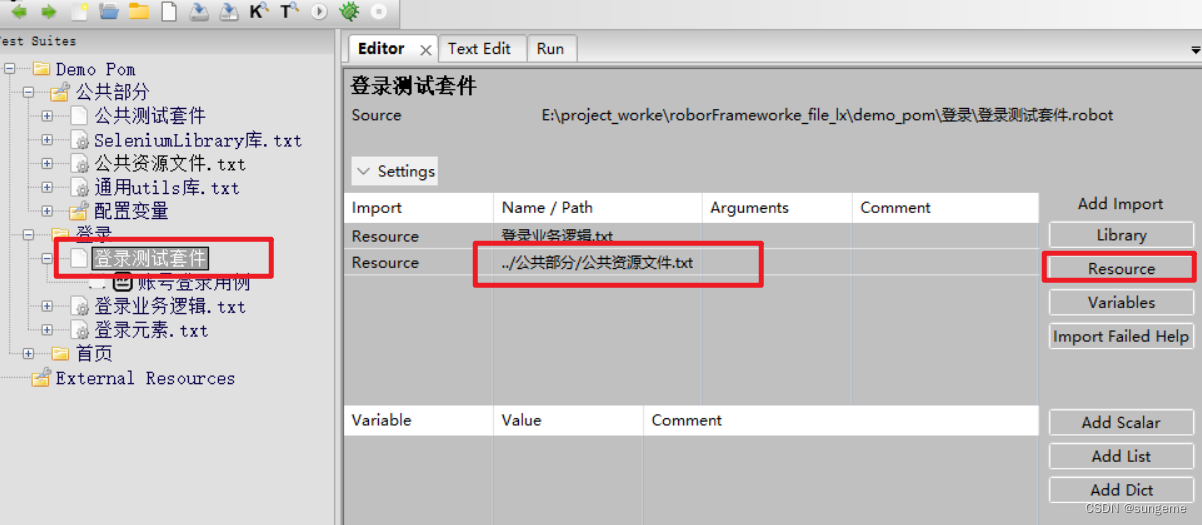
2、新增后,在用到的地方进行资源文件的导入和调用
例如导入正向登录用户名和密码
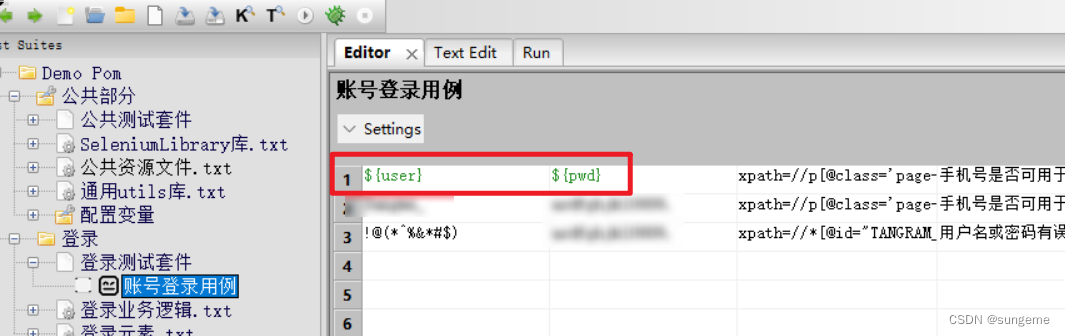
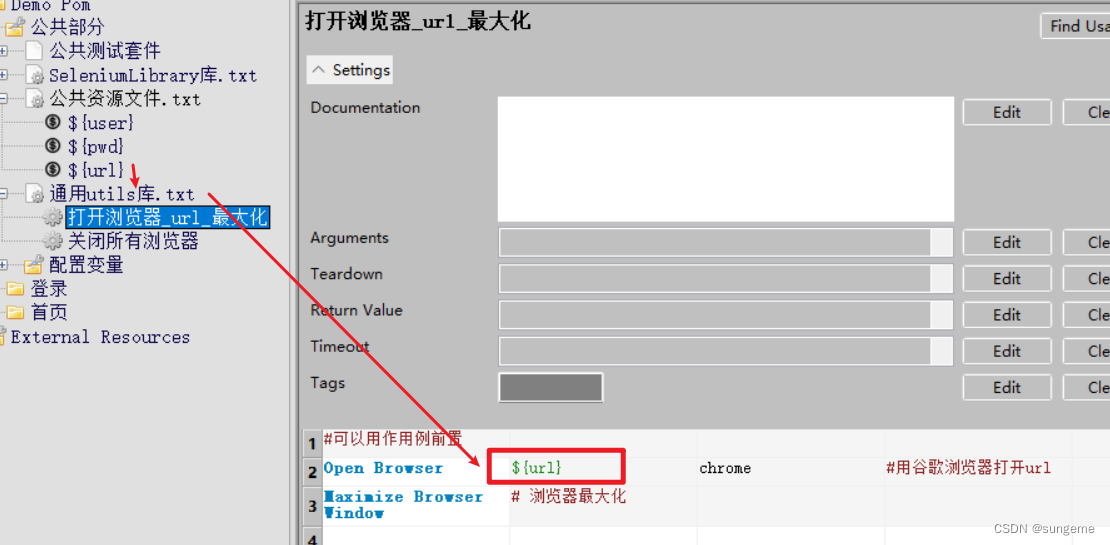
用例里面调用:
打开url调用:
DDT
DDT(Data-Driven Testing)数据驱动
简介
数据驱动是一种测试方法,就像在开车时需要遵循交通规则一样,测试也需要遵循一些规则。在数据驱动的测试中就可以使用数据来指引测试的进行
数据驱动的目的:
想象一下,如果要测试一个的登录功能。传统的方法是手动输入用户名和密码,然后点击登录按钮,再观察是否成功登录。但是如果想测试不同的用户名和密码组合,这会变得非常耗时和繁琐
而数据驱动在应对这样的场景时,会更高效的处理。可以将不同的用户名和密码组合存储在一个容器中,提供给测试脚本,脚本会依次读取数据表中的用户名和密码,并自动进行登录操作。这样只需要准备好测试数据,然后启动测试脚本,它会自动执行所有的测试步骤,提高测试效率,减少重复劳动,更加灵活地定义和管理测试数据,同时还能覆盖更多的测试情况
优点:
涵盖更广:数据驱动的测试可以通过使用各种数据组合来增加测试覆盖范围,从而更全面地测试系统的不同方面和功能。
可重复性:使用相同的测试代码和数据,可以重复执行数据驱动的测试,确保测试结果的一致性和可重复性。
看一个场景:
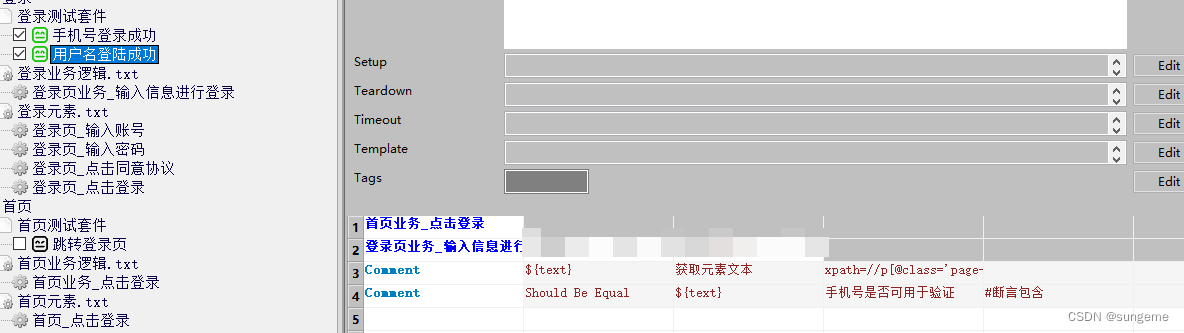
这里有两个登录成功的用例,他们的步骤是相同的,那就可以对他们进行数据驱动
这时需要对测试脚本进行一些调整,对于要做DDT的用例,打开/关闭浏览器的夹具就不适用了。而不需要做数据驱动的用例,夹具依然合适,可以把数据驱动套件和不需要数据驱动的套件区分开,数据驱动套件不使用夹具,不需要数据驱动的用例使用夹具。
示例
注
-
打开/关闭浏览器,放在业务中
-
定义断言,获取元素文本数据,元素作为文本传入(因为登录成功和登录失败需要获取的元素文本值不一样)
-
断言的文本设定成参数,也是因为登录成功和登录失败的值不一致
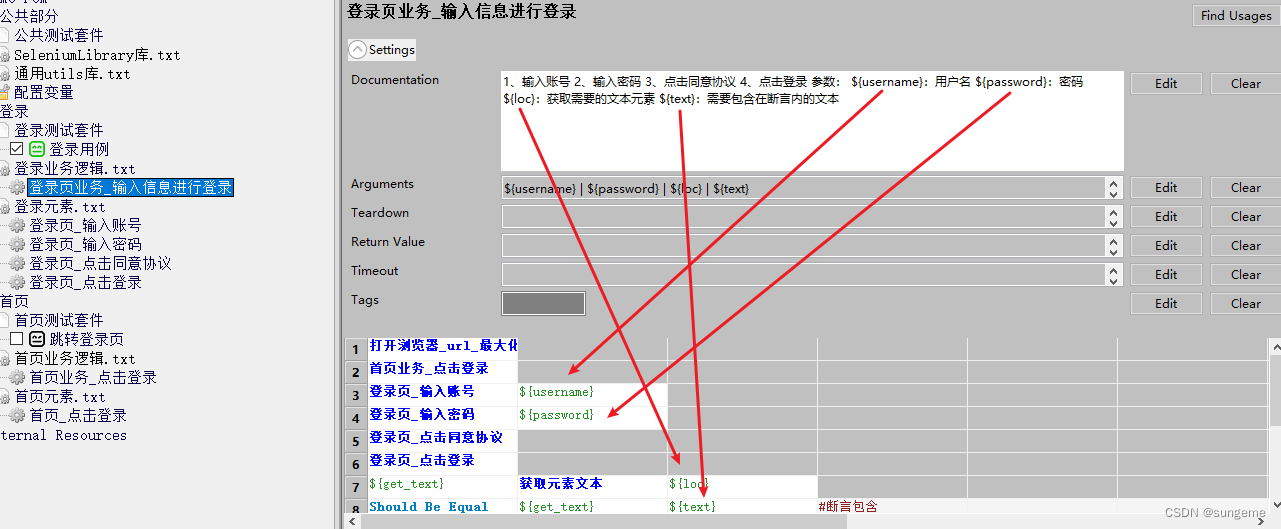
因为登录业务可能会被其他业务调用,登录之后想要进行其他操作,所以这里要把这几个参数给一个正向的默认值,这样其他地方如果要用,直接调用即可,不用再麻烦的传入参数了
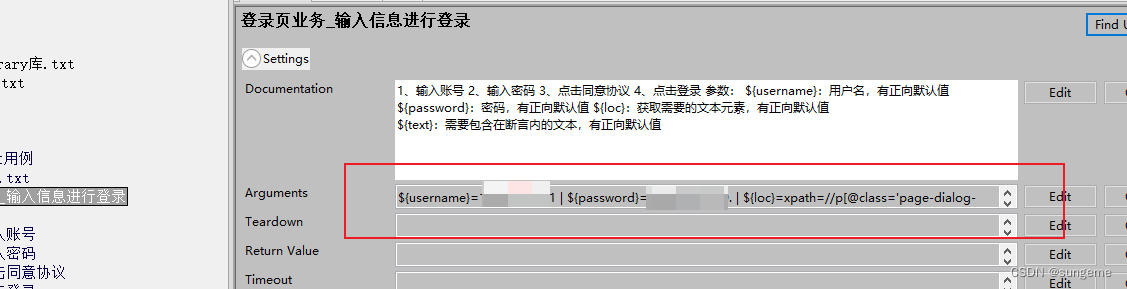
使用
1、用例页中有一个模版:
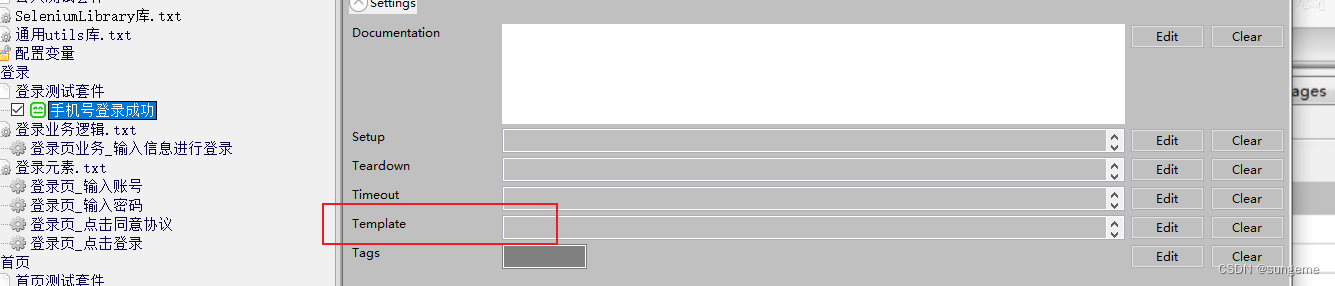
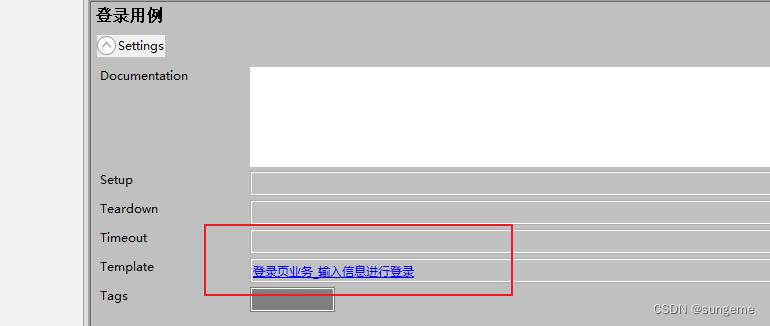
2、导入定义的登录业务关键字:
3、设置不同组合的账号密码,和需要断言的元素以及断言值
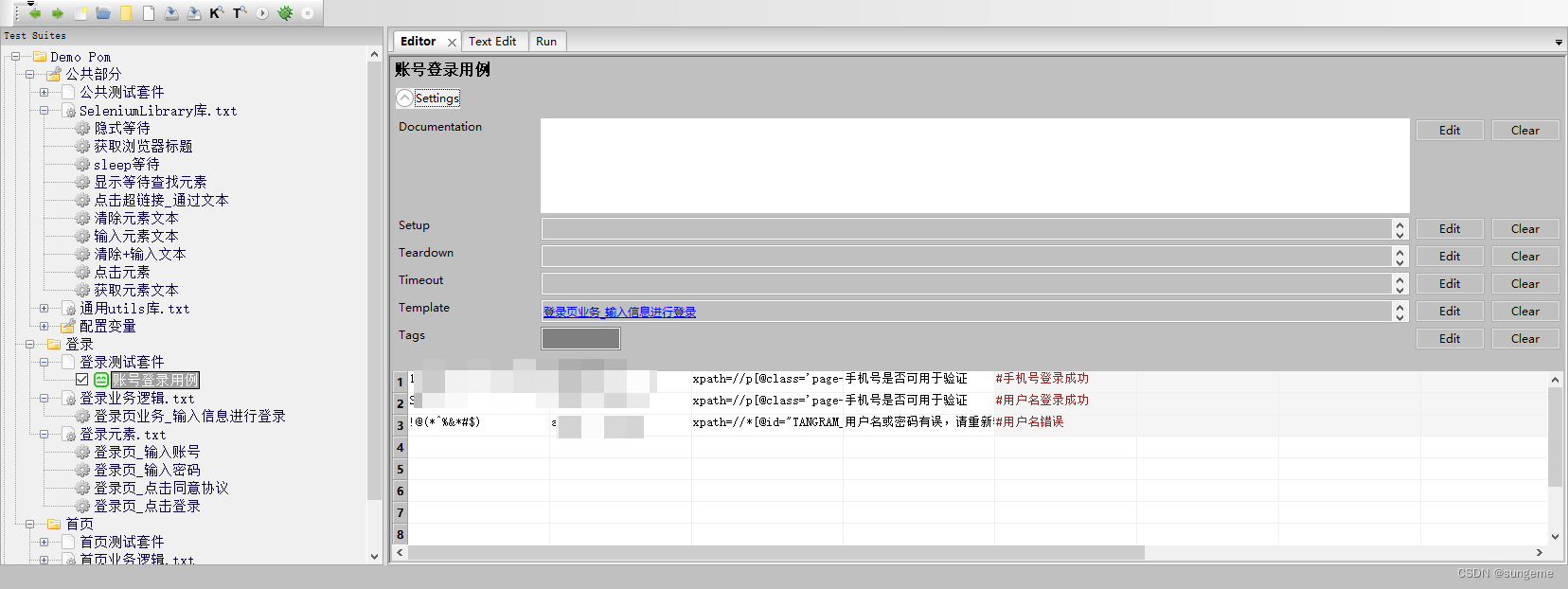
4、运行一下,全部通过,数据驱动完成
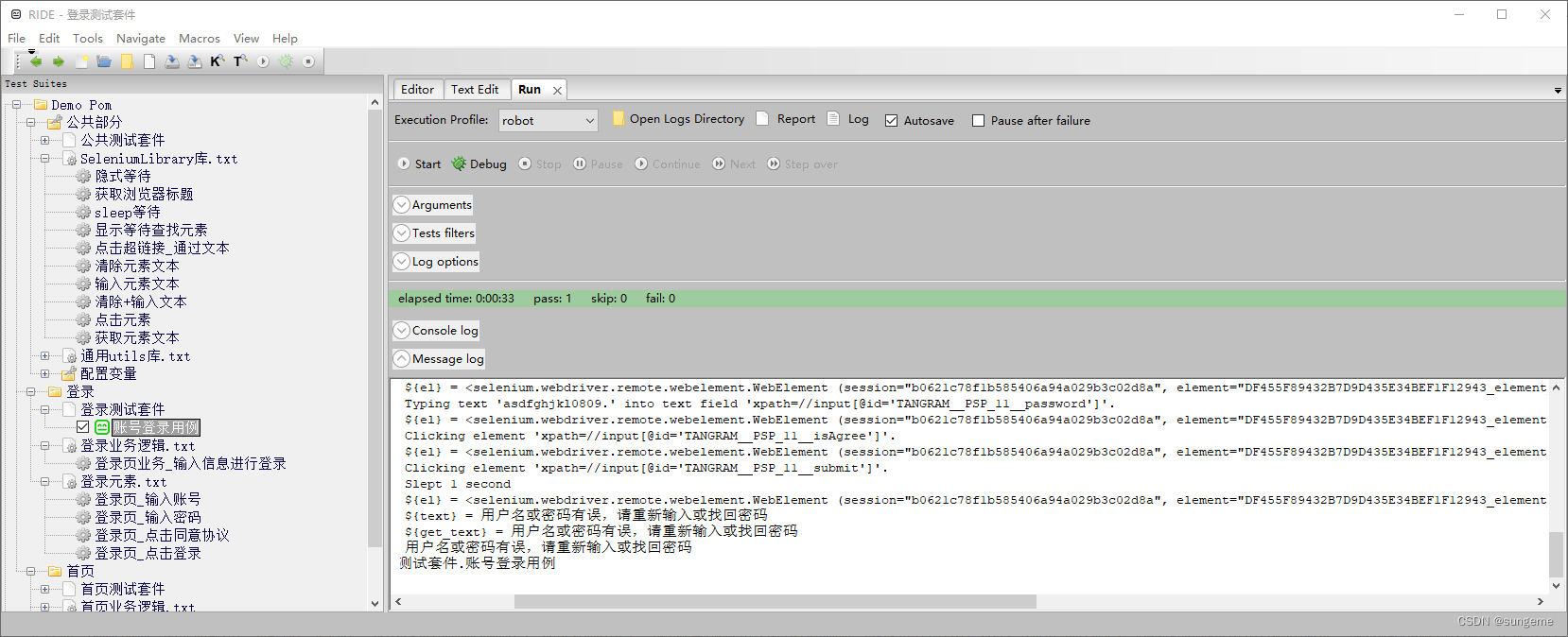
注意事项:
1、有时候断言会报错,例如断言错误场景时,这里的文本出现的会比元素慢,所以立马获取文本是获取不到的:
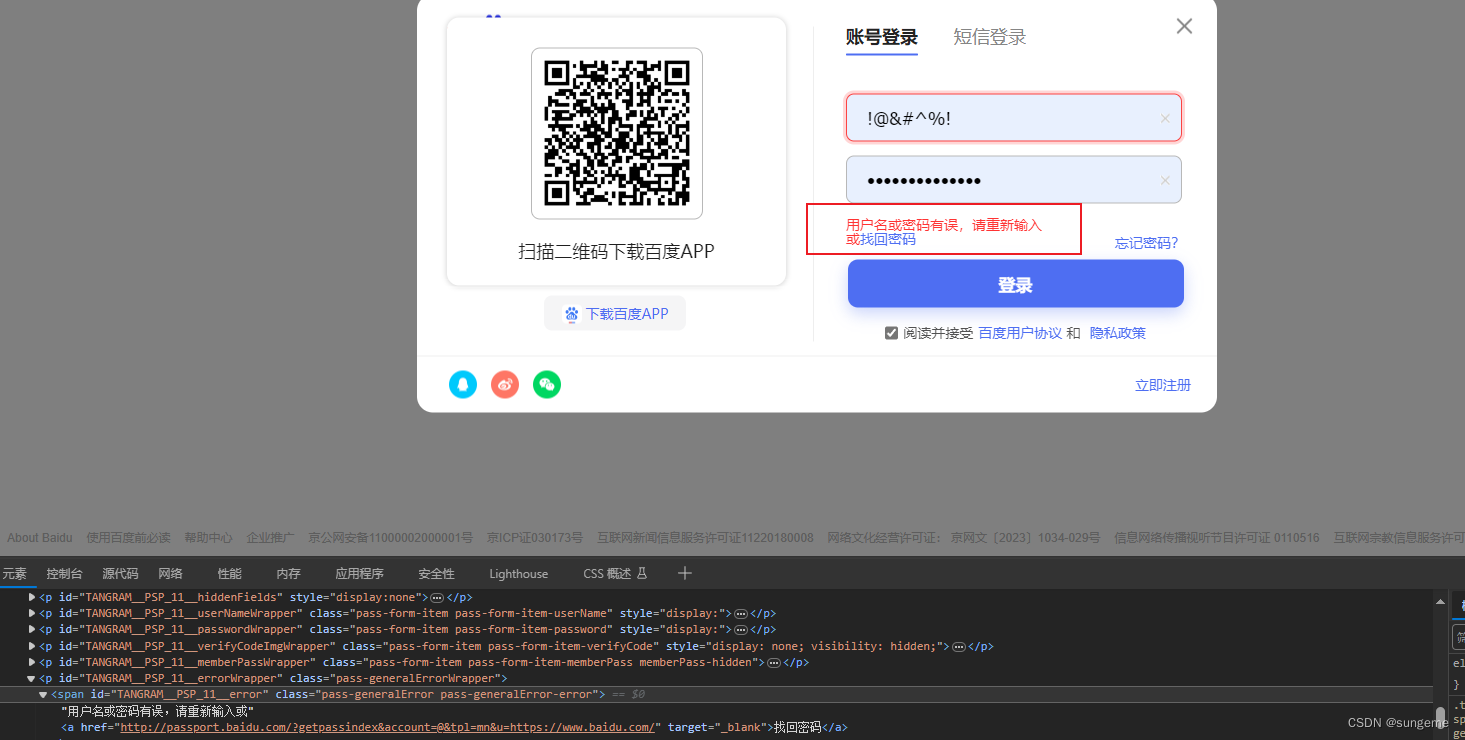
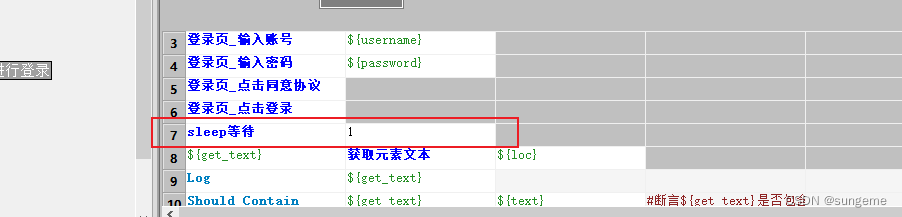
因此要在业务中使用sleep等待一下
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维网工测试副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
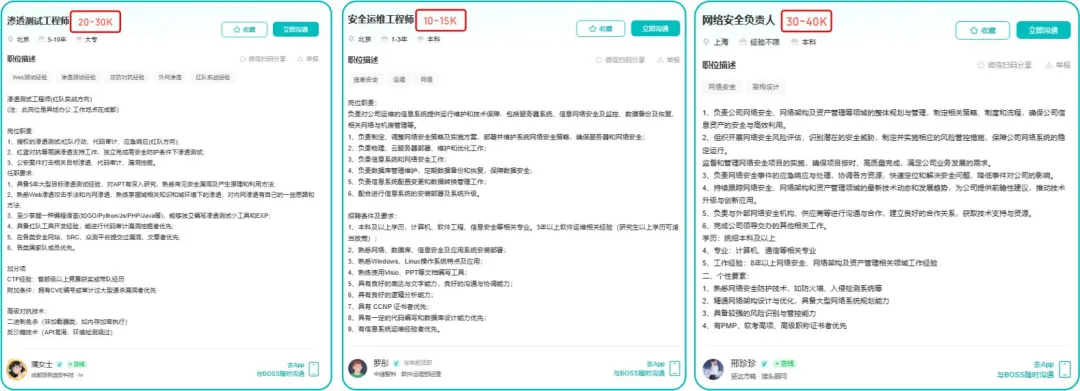
运维网工测试转行学习路线
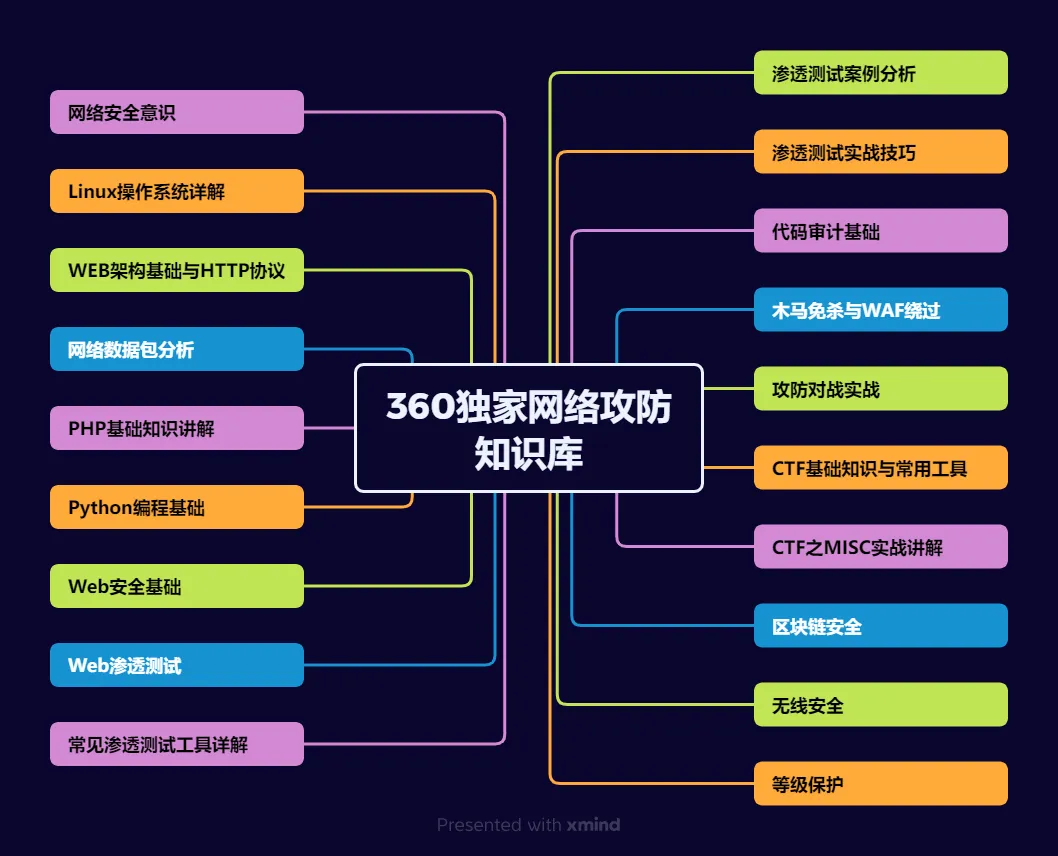
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维网工测试转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









