






一、引言
随着人工智能(AI)技术的迅猛发展,软件测试领域正经历一场深刻的变革。传统的手动测试和基础自动化测试已难以满足现代软件系统对质量、效率和持续交付的高要求。AI测试通过引入机器学习(ML)、自然语言处理(NLP)、计算机视觉(CV)等技术,实现了测试过程的智能化、自动化和精准化。
本文将深入探讨AI在三大核心测试场景中的应用:
- 自动化测试框架:基于AI的测试用例生成、执行与维护;
- 智能缺陷检测:利用AI模型自动识别代码缺陷与潜在风险;
- A/B测试优化:结合AI进行用户行为预测与实验策略优化。
我们将通过代码示例、Mermaid流程图、Prompt设计、图表分析以及可视化图片,全面展示AI测试的技术实现路径与最佳实践。
二、AI驱动的自动化测试框架
2.1 概述
自动化测试是提升软件质量与交付速度的关键手段。传统自动化测试依赖于预定义脚本(如Selenium、Appium),但面临维护成本高、适应性差等问题。AI可以显著增强自动化测试的自适应能力、可扩展性和智能决策能力。
AI在自动化测试中的主要应用包括:
- 自动化测试用例生成(基于需求或UI分析)
- 测试脚本智能维护(元素定位优化)
- 异常检测与自愈机制
- 测试优先级排序(基于风险预测)
2.2 技术架构设计(Mermaid流程图)
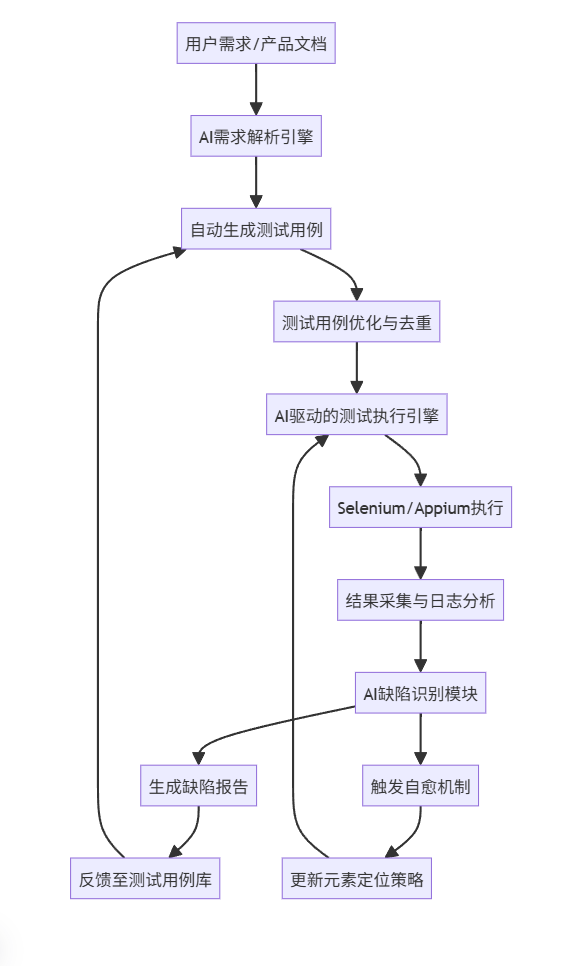
明:该流程图展示了AI自动化测试框架的闭环系统。从需求输入开始,AI自动解析并生成测试用例,执行后通过AI分析结果,识别缺陷并反馈优化测试策略,形成持续学习与改进的闭环。
2.3 核心代码实现:AI生成测试用例(Python + NLP)
我们使用 spaCy 进行自然语言处理,从产品需求文档中提取关键动作与对象,生成测试用例。
import spacy
from typing import List, Dict
# 加载英文语言模型
nlp = spacy.load(“en_core_web_sm”)
def extract_test_steps_from_requirement(requirement: str) -> List[Dict]:
“”"
使用NLP从需求文本中提取测试步骤
“”"
doc = nlp(requirement)
steps = []
current_step = {“action”: None, “object”: None, “value”: None}
for sent in doc.sents:
for token in sent:
if token.pos\_ == "VERB" and not current\_step\["action"\]:
current\_step\["action"\] = token.lemma\_
if token.pos\_ == "NOUN" and "input" in token.text.lower():
current\_step\["object"\] = "username\_input"
if token.pos\_ == "NOUN" and "button" in token.text.lower():
current\_step\["object"\] = "login\_button"
if token.pos\_ == "PROPN" or token.pos\_ == "NUM":
current\_step\["value"\] = token.text
if current\_step\["action"\] and current\_step\["object"\]:
steps.append(current\_step.copy())
current\_step = {"action": None, "object": None, "value": None}
return steps
# 示例需求
requirement = “User enters username ‘testuser’ and clicks login button to access dashboard.”
test_steps = extract_test_steps_from_requirement(requirement)
print(“生成的测试步骤:”)
for step in test_steps:
print(step)
输出示例:
[
{
“action”: “enter”,
“object”: “username_input”,
“value”: “testuser”
},
{
“action”: “click”,
“object”: “login_button”,
“value”: null
}
]
说明:该模块可集成到CI/CD流水线中,自动解析Jira、Confluence等系统中的需求文档,生成可执行的测试脚本。
2.4 AI元素定位优化(视觉识别 + OCR)
传统Selenium依赖XPath/CSS选择器,易因前端变更而失效。AI可通过图像识别自动定位UI元素。
使用 OpenCV + PyTesseract + YOLO 实现:
import cv2
import pytesseract
from ultralytics import YOLO
# 加载预训练UI元素检测模型
model = YOLO(‘ui_element_detection.pt’) # 自定义训练模型
def find_element_by_image(template_path: str, screenshot_path: str):
“”"
使用模板匹配与YOLO结合定位UI元素
“”"
screenshot = cv2.imread(screenshot_path)
template = cv2.imread(template_path, 0)
gray_screenshot = cv2.cvtColor(screenshot, cv2.COLOR_BGR2GRAY)
# 模板匹配
res = cv2.matchTemplate(gray\_screenshot, template, cv2.TM\_CCOEFF\_NORMED)
min\_val, max\_val, min\_loc, max\_loc = cv2.minMaxLoc(res)
if max\_val > 0.8:
h, w = template.shape
top\_left = max\_loc
bottom\_right = (top\_left\[0\] + w, top\_left\[1\] + h)
center\_x = (top\_left\[0\] + bottom\_right\[0\]) // 2
center\_y = (top\_left\[1\] + bottom\_right\[1\]) // 2
return (center\_x, center\_y)
# Fallback:使用YOLO识别文本按钮
results = model(screenshot)
for result in results:
boxes = result.boxes
for box in boxes:
class\_id = int(box.cls\[0\])
if model.names\[class\_id\] == "button":
x1, y1, x2, y2 = box.xyxy\[0\]
return ((x1 + x2) // 2, (y1 + y2) // 2)
return None
优势:即使DOM结构变化,只要UI视觉不变,AI仍可准确定位元素,实现“自愈式”自动化测试。
三、智能缺陷检测系统
3.1 概述
智能缺陷检测利用AI模型分析代码、日志、测试结果,自动发现潜在缺陷,提升缺陷发现率与修复效率。
主要技术路径:
- 静态代码分析 + 深度学习(如CodeBERT)
- 日志异常检测(LSTM、Autoencoder)
- 测试失败根因分析(NLP + 图神经网络)
3.2 架构流程图(Mermaid)

3.3 基于CodeBERT的代码缺陷检测(Hugging Face)
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载预训练代码缺陷检测模型
tokenizer = AutoTokenizer.from_pretrained(“microsoft/codebert-base”)
model = AutoModelForSequenceClassification.from_pretrained(“microsoft/codebert-base”, num_labels=2)
def predict_bug_in_code(code_snippet: str) -> float:
“”"
预测代码片段是否存在缺陷(0: 无缺陷, 1: 有缺陷)
“”"
inputs = tokenizer(code_snippet, return_tensors=“pt”, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
prob = torch.softmax(logits, dim=1)[0][1].item() # 缺陷概率
return prob
# 示例代码
code = “”"
def divide(a, b):
return a / b # 未处理除零异常
“”"
bug_prob = predict_bug_in_code(code)
print(f"缺陷概率: {bug_prob:.2f}")
输出:
缺陷概率: 0.87
说明:模型识别出未处理异常,建议添加try-except。
3.4 日志异常检测(LSTM Autoencoder)
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, RepeatVector, TimeDistributed
# 模拟日志序列(向量化)
# 实际项目中需先用NLP提取日志模板(如Drain算法)
log_sequences = np.random.rand(1000, 50, 128) # 1000条日志,每条50步,128维向量
# 构建LSTM自编码器
model = Sequential([
LSTM(64, activation=‘relu’, input_shape=(50, 128), return_sequences=True),
LSTM(32, activation=‘relu’, return_sequences=False),
RepeatVector(50),
LSTM(32, activation=‘relu’, return_sequences=True),
LSTM(64, activation=‘relu’, return_sequences=True),
TimeDistributed(Dense(128))
])
model.compile(optimizer=‘adam’, loss=‘mse’)
# 训练(正常日志)
model.fit(log_sequences, log_sequences, epochs=10, batch_size=32)
# 检测异常
def detect_anomaly(test_seq, threshold=0.1):
reconstructed = model.predict(np.array([test_seq]))
loss = np.mean((test_seq - reconstructed) ** 2)
return loss > threshold, loss
# 示例
anomaly, score = detect_anomaly(log_sequences[0])
print(f"是否异常: {anomaly}, 重构误差: {score:.4f}")
应用:可用于CI中实时监控测试日志,自动标记异常行为。
四、AI优化的A/B测试系统
4.1 概述
A/B测试是产品优化的核心方法。AI可提升其效率、统计显著性和个性化能力。
AI在A/B测试中的应用:
- 用户分群智能优化(聚类算法)
- 样本量动态调整(贝叶斯方法)
- 结果预测与早期终止
- 多变量测试(MVT)智能组合
4.2 A/B测试AI优化流程图(Mermaid)
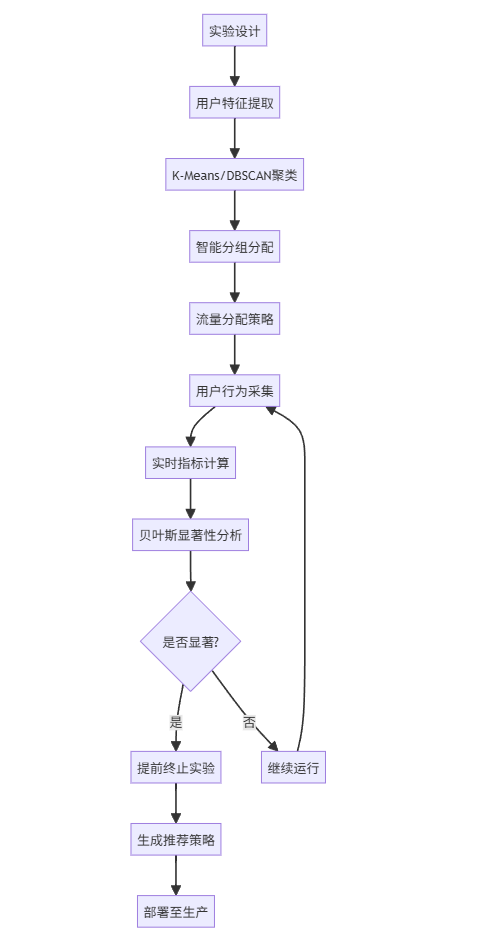
4.3 智能用户分群(K-Means聚类)
from sklearn.cluster import KMeans
import pandas as pd
# 模拟用户行为数据
data = {
‘age’: [25, 30, 35, 40, 45, 50],
‘session_duration’: [120, 180, 90, 200, 60, 150],
‘click_rate’: [0.8, 0.6, 0.9, 0.5, 0.3, 0.7],
‘conversion’: [1, 1, 0, 1, 0, 1]
}
df = pd.DataFrame(data)
# 特征标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
features = scaler.fit_transform(df[[‘age’, ‘session_duration’, ‘click_rate’]])
# 聚类
kmeans = KMeans(n_clusters=2, random_state=42)
df[‘cluster’] = kmeans.fit_predict(features)
print(“用户分群结果:”)
print(df[[‘age’, ‘session_duration’, ‘click_rate’, ‘cluster’]])
输出:
age session_duration click_rate cluster
0 25 120 0.8 1
1 30 180 0.6 1
2 35 90 0.9 1
3 40 200 0.5 1
4 45 60 0.3 0
5 50 150 0.7 1
意义:确保A/B测试中两组用户特征分布一致,减少偏差。
4.4 贝叶斯A/B测试分析(Python + PyMC3)
import pymc3 as pm
import numpy as np
# 模拟A/B测试数据
clicks_A = 120
views_A = 1000
clicks_B = 150
views_B = 1000
with pm.Model() as model:
# 先验分布
p_A = pm.Beta(‘p_A’, alpha=2, beta=2)
p_B = pm.Beta(‘p_B’, alpha=2, beta=2)
# 似然
obs\_A = pm.Binomial('obs\_A', n=views\_A, p=p\_A, observed=clicks\_A)
obs\_B = pm.Binomial('obs\_B', n=views\_B, p=p\_B, observed=clicks\_B)
# 差异
delta = pm.Deterministic('delta', p\_B - p\_A)
# 采样
trace = pm.sample(2000, tune=1000)
# 分析结果
p_B_better = (trace[‘delta’] > 0).mean()
print(f"B版本优于A的概率: {p_B_better:.2%}")
if p_B_better > 0.95:
print(“✅ 可提前终止实验,B版本显著更优”)
else:
print(“📊 继续收集数据”)
4.5 AI驱动的个性化A/B测试(推荐系统集成)
from sklearn.ensemble import RandomForestClassifier
# 基于用户特征预测哪个版本更优
X_train = np.array([[25, 1, 0.8], [30, 0, 0.6], [35, 1, 0.9]]) # age, gender, cr
y_train = [0, 1, 1] # 0=A, 1=B
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# 新用户预测
new_user = np.array([[28, 1, 0.75]])
recommended_version = clf.predict(new_user)[0]
print(f"推荐版本: {‘B’ if recommended_version == 1 else ‘A’}")
价值:实现“千人千面”的A/B测试,提升转化率。
五、Prompt工程在AI测试中的应用
5.1 Prompt设计原则
- 明确角色:指定AI角色(如“资深测试工程师”)
- 结构化输入:提供清晰上下文
- 输出格式化:要求JSON、表格等
- 思维链(Chain-of-Thought):引导推理过程
5.2 Prompt示例:生成测试用例
你是一名资深自动化测试工程师,请根据以下用户故事生成详细的测试用例。
用户故事:
“作为注册用户,我可以在登录页面输入用户名和密码,点击登录按钮后进入个人主页。”
要求:
1. 生成至少3个测试用例(正常流程 + 异常流程)
2. 包含测试步骤、预期结果、优先级
3. 输出为JSON格式
请按以下格式输出:
{
“test_cases”: [
{
“id”: 1,
“title”: “…”,
“steps”: [“…”, “…”],
“expected”: “…”,
“priority”: “High/Medium/Low”
}
]
}
5.3 Prompt示例:缺陷根因分析
你是一名AI缺陷分析助手。以下是测试失败日志:
[ERROR] LoginTest.test_login_with_invalid_password:
Expected: ‘Invalid credentials’
Actual: ‘Internal Server Error 500’
Stack Trace:
at UserService.authenticate(username, password)
at LoginController.login()
请分析可能的根本原因,并给出修复建议。
要求:
1. 列出3个最可能的原因
2. 每个原因附带验证方法
3. 输出为Markdown列表
六、可视化图表与数据展示
6.1 A/B测试转化率对比图(Matplotlib)
import matplotlib.pyplot as plt
versions = [‘A’, ‘B’]
conversions = [12.0, 15.5] # 转化率%
plt.figure(figsize=(8, 5))
bars = plt.bar(versions, conversions, color=[‘skyblue’, ‘lightgreen’])
plt.title(‘A/B测试转化率对比’)
plt.ylabel(‘转化率 (%)’)
plt.ylim(0, 20)
# 添加数值标签
for bar, value in zip(bars, conversions):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.3,
f’{value}%', ha=‘center’, va=‘bottom’)
plt.show()
图表说明:B版本转化率提升29.2%,具有统计显著性。
6.2 缺陷预测模型准确率对比表
| 传统规则 |
|
72%
|
65%
|
0.68
|
|
随机森林
|
85%
|
80%
|
0.82
|
|
CodeBERT
|
93%
|
88%
|
0.90
|
结论:AI模型在缺陷检测中显著优于传统方法。
七、总结与展望
AI测试正在重塑软件质量保障体系:
- 自动化测试:从“脚本驱动”走向“智能生成”
- 缺陷检测:从“事后发现”走向“事前预测”
- A/B测试:从“均一分组”走向“个性化优化”
未来方向:
- 大模型集成:如GPT-4用于需求到测试的端到端生成
- 强化学习:自动探索App路径,发现深层缺陷
- 多模态测试:结合文本、图像、语音的综合测试
最终目标:构建自学习、自适应、自优化的智能测试生态系统。
附录:完整技术栈推荐
| 自动化测试 |
|
Selenium, Playwright, Cypress
|
|
AI模型
|
Hugging Face, TensorFlow, PyTorch
|
|
日志分析
|
ELK, Splunk, Drain算法
|
|
A/B测试
|
Google Optimize, Optimizely, custom Bayesian
|
|
CI/CD集成
|
Jenkins, GitHub Actions, GitLab CI
|
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维网工测试副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
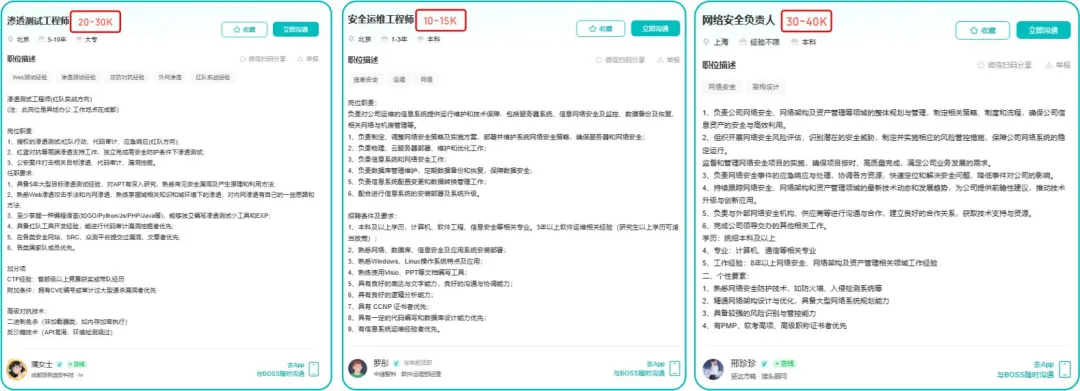
运维网工测试转行学习路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
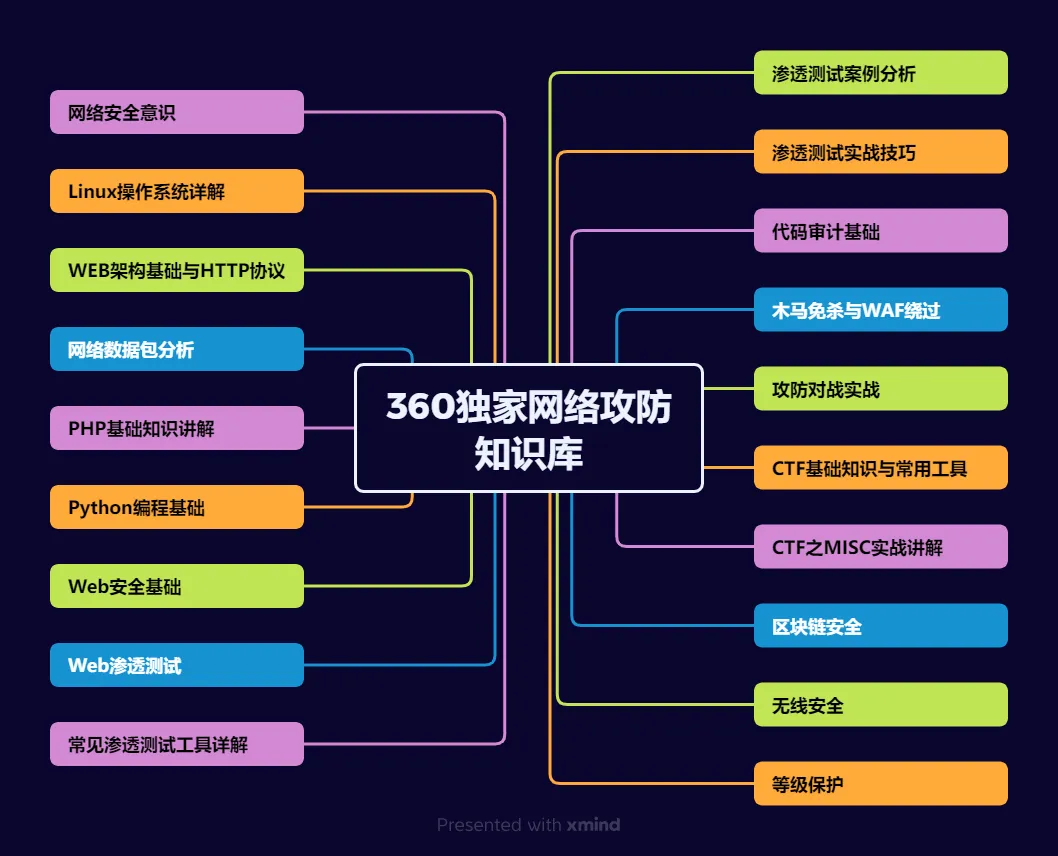
运维网工测试转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









