







一、基础准备
1. 环境搭建
工欲善其事必先利其器,废话不多说。我们先开始搭建环境。
# 创建项目目录
mkdir InterfaceTesting
# 切换到项目目录下
cd InterfaceTesting
# 安装虚拟环境创建工具
pip install virtualenv
# 创建虚拟环境,env代表虚拟环境的名称,可自行定义
virtualenv env
# 启动虚拟环境,执行下面命令后会发现路径上有 (env) 字样的标识
source env/Scripts/activate
# 查看 (env) 环境下使用的 Python 和 pip 工具版本
ls env/Scripts/
# *** 安装 requests ***
pip install requests
# 退出虚拟环境,退出后路径上的 (env) 字样的标识消失
cd env/Scripts/
deactivate
# 导出环境所需要的模块的清单
pip freeze >> requirements.txt
# 上传 GitHub 时,将下面项忽略上传
echo env/ >> .gitignore
echo InterfaceTesting.iml >> .gitignore
echo __pycache__/ >> .gitignore
# 将代码传至 GitHub
# 本地仓初始化
git init
# 创建本地仓与 GitHub 仓的远程链接
git remote add github 你的github仓的地址
# 将代码添加到暂存区
git add .
# 将代码提交到
git commit -m "init environment"
# 将代码上传到GitHub仓中
git push github master
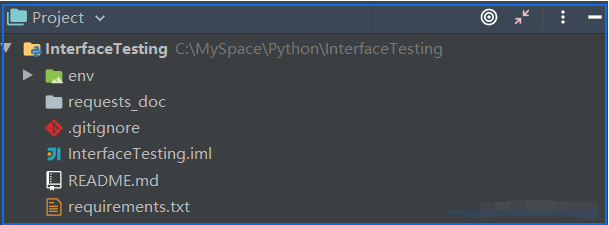
初始化环境的项目结构示例如下:
2. 接口基础知识
2.1 接口分类
接口一般来说有两种,一种是程序内部的接口,一种是系统对外的接口。
-
(1) webservice接口:走soap协议通过http传输,请求报文和返回报文都是xml格式的,我们在测试的时候都要通过工具才能进行调用,测试。 -
(2) http api 接口:走http协议,通过路径来区分调用的方法,请求报文都是key-value形式的,返回报文一般都是json串,有get和post等方法。
2.2 接口请求类型
根据接口的请求方法,常用的几种接口请求方式:
-
(1) GET:从指定资源获取数据 -
(2) POST:向指定的资源请求被处理的数据(例如用户登录) -
(3) PUT:上传指定的URL,一般是修改,可以理解为数据库中的 update -
(4) DELETE:删除指定资源
二、Requests 快速上手
1. requests基础
所有的数据测试目标以一个开源的接口模拟网站【HTTPBIN】为测试对象。
1.1 发送请求
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : requests_send_request.py
@Time : 2019/9/2 11:54
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
import requests
# 1.requests请求方式
# (1) GET请求方式
httpbin_get = requests.get('http://httpbin.org/get', data={'key': 'value'})
print('httpbin_get: ', httpbin_get.text)
# (2) POST请求方式
httpbin_post = requests.post('https://httpbin.org/post', data={'key': 'value'})
print('httpbin_post: ', httpbin_post.text)
# (3) PUT请求方式
httpbin_put = requests.put('https://httpbin.org/put', data={'key': 'value'})
print('httpbin_put: ', httpbin_put.text)
# (4) DELETE请求方式
httpbin_delete = requests.delete('https://httpbin.org/delete', data={'key': 'value'})
print('httpbin_delete', httpbin_delete)
# (5) PATCH亲求方式
httpbin_patch = requests.patch('https://httpbin.org/patch', data={'key': 'value'})
print('httpbin_patch', httpbin_patch)
1.2 参数传递
常用的参数传递形式有四种:【GitHub示例】
(1)字典形式的参数:payload = {'key1': 'value1', 'key2': 'value2'}
(2) 元组形式的参数:payload = (('key1', 'value1'), ('key2', 'value2'))
(3) 字符串形式的参数:payload = {'string1', 'value1'}
(4) 多部份编码的文件:files = {
# 显示设置文件名、文件类型和请求头
'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})
}
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : requests_transfer_parameter.py
@Time : 2019/9/2 12:39
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : 参数传递:字典、元组、字符串、文件
"""
import requests
# 2. 参数传递
# (1) 传参参数为字典形式: 数据字典会在发送请求时会自动编码为表单形式
def transfer_dict_parameter():
payload = {
'key1': 'value1',
'key2': 'value2'
}
transfer_dict_parameter_result = requests.post('https://httpbin.org/post', params=payload)
print("transfer_dict_parameter_url: ", transfer_dict_parameter_result.url)
print("transfer_dict_parameter_text: ", transfer_dict_parameter_result.text)
transfer_dict_parameter()
# (2) 传参参数为元组形式: 应用于在表单中多个元素使用同一 key 的时候
def transfer_tuple_parameter():
payload = (
('key1', 'value1'),
('key1', 'value2')
)
transfer_tuple_parameter_result = requests.post('https://httpbin.org/post', params=payload)
print('transfer_tuple_parameter_url: ', transfer_tuple_parameter_result.url)
print('transfer_tuple_parameter_text: ', transfer_tuple_parameter_result.text)
transfer_tuple_parameter()
# (3) 传参参数形式是字符串形式
def transfer_string_parameter():
payload = {
'string1': 'value'
}
transfer_string_parameter_result = requests.post('https://httpbin.org/post', params=payload)
print('transfer_string_parameter_url: ', transfer_string_parameter_result.url)
print('transfer_string_parameter_text: ', transfer_string_parameter_result.text)
transfer_string_parameter()
# (4) 传参参数形式:一个多部分编码(Multipart-Encoded)的文件
def transfer_multipart_encoded_file():
interface_url = 'https://httpbin.org/post'
files = {
# 显示设置文件名、文件类型和请求头
'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})
}
transfer_multipart_encoded_file_result = requests.post(url=interface_url, files=files)
print('transfer_multipart_encoded_file_result_url: ', transfer_multipart_encoded_file_result.url)
print('transfer_multipart_encoded_file_result_url: ', transfer_multipart_encoded_file_result.text)
transfer_multipart_encoded_file()
1.3 接口响应
给接口传递参数,请求接口后,接口会给我们我们响应返回,接口在返回的时候,会给我们返回一个状态码来标识当前接口的状态。
(1)状态码
【GitHub示例】

#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : response_code.py
@Time : 2019/9/2 15:41
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
import requests
# 1. 返回接口状态码:200
def response_200_code():
interface_200_url = 'https://httpbin.org/status/200'
response_get = requests.get(interface_200_url)
response_get_code = response_get.status_code
print('response_get_code: ', response_get_code)
response_200_code()
# 2.返回接口状态码:400
def response_400_code():
interface_400_url = 'https://httpbin.org/status/400'
response_get = requests.get(interface_400_url)
response_get_code = response_get.status_code
print('response_get_code: ', response_get_code)
response_400_code()
(2)响应头
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : response_content.py
@Time : 2019/9/2 15:41
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
import requests
# 1. 返回接口状态码:
# (1). 返回接口状态码:200
def response_200_code():
interface_200_url = 'https://httpbin.org/status/200'
response_get = requests.get(interface_200_url)
response_get_code = response_get.status_code
print('response_get_code: ', response_get_code)
response_200_code()
# (2).返回接口状态码:400
def response_400_code():
interface_400_url = 'https://httpbin.org/status/400'
response_get = requests.get(interface_400_url)
response_get_code = response_get.status_code
print('response_get_code: ', response_get_code)
response_400_code()
# (3) 重定向接口返回状态码:301
def response_301_code():
interface_url = 'https://butian.360.cn'
response_get = requests.get(interface_url)
response_get_code = response_get.status_code
print('response_get_code: ', response_get_code)
response_301_code()
# ------------------------------------------------------
# 2. 响应内容
  响应内容的请求头、查看文本、编码方式、二进制响应、原始响应。
def response_contents():
url = 'https://httpbin.org/get'
response_get = requests.get(url=url)
# 响应头
print('response_get_headers', response_get.headers)
# 响应文本
print('response_get_text: ', response_get.text)
# 文本编码方式
print('response_get_encoding: ', response_get.encoding)
# 二进制响应内容
print('response_get_content: ', response_get.content)
# 原始响应内容
origin_content = response_get.raw
origin_content_read = origin_content.read(10)
print('origin_content: ', origin_content)
print('origin_content_read: ', origin_content_read)
response_contents()
1.4 接口其他处理
【GitHub示例】
(1) 操作cookies
import requests
import time
url = 'https://httpbin.org/get'
def operator_cookies():
r = requests.get(url)
print('r.cookies: ', r.cookies)
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
r2 = requests.get(url=url, cookies=jar)
print('r2.text', r2.text)
operator_cookies()
(2) 请求历史
import requests
url = 'https://httpbin.org/get'
def request_history():
r = requests.get(url=url)
print('r.history: ', r.history)
request_history()
(3) 超时请求
requests 在经过 timeout 参数设定的秒数时间之后停止等待响应。
import requests
import time
def timeout():
print(time.time())
url = 'https://httpbin.org/get'
print(time.time())
r = requests.get(url, timeout=5)
print(time.time())
timeout()
(4) 错误与异常
常见的错误异常有:
-
· 遇到网络问题(如:DNS 查询失败、拒绝连接等时),requests 会抛出一个 ConnectionError 异常。 -
· 如果 HTTP 请求返回了不成功的状态码, Response.raise_for_status() 会抛出一个 HTTPError异常。 -
· 若请求超时,则超出一个 Timeout 异常。 -
· 若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects 异常。 -
· 所有 Requests 显式抛出的异常都继承自 requests.exceptions.RequestsException。
2. requests 高级应用
2.1 会话对象
2.2 请求与响应对象
2.3 准备的请求
2.4 SSL证书验证
2.5 客户端证书
三、接口测试实战
1. 百度翻译接口测试
理论千千万万,实战才是真理。百度翻译提供了一套成熟的翻译接口(不是恰饭😂),我们就用此接口对前面理论进行实战。【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : baidu_translate.py
@Time : 2019/9/2 20:05
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
import requests
import random
import hashlib
import urllib
import json
class BaiduTranslate(object):
def __init__(self, word):
# 你要翻译的元素
self.q = word
self.fromLang = 'en'
self.toLang = 'zh'
self.baidu_translate = 'https://api.fanyi.baidu.com'
self.translate_api_url = '/api/trans/vip/translate'
# 百度开发者配置信息
self.appid = 'XXXXXXXX'
self.secretKey = 'XXXXXXXX'
# 开发配置
self.salt = random.randint(32768, 65536)
self.sign = self.appid + self.q + str(self.salt) + self.secretKey
m1 = hashlib.md5()
m1.update(self.sign.encode('utf-8'))
self.sign = m1.hexdigest()
self.my_url = self.translate_api_url + '?appid=' + self.appid + '&q=' + urllib.request.quote(self.q) + '&from=' + self.fromLang + '&to=' + self.toLang + '&salt=' + str(self.salt) + '&sign=' + self.sign
def en_translate_zh(self):
re = requests.request('post', self.baidu_translate + self.translate_api_url)
print('\n\t re.text', re.text)
re_json = json.loads(re.text)
print('\n\t re_json', re_json)
if __name__ == "__main__":
bt = BaiduTranslate('test')
bt.en_translate_zh()
2. urllib请求接口
有了requests库请求接口了,为什么要再用urllib来请求接口呢?因为urllib是python的基础库,不需要下载安装,在对环境要求甚高的环境下,在不破坏原来的环境下,依然可以让自动化代码依然运行。【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : urllib_request.py
@Time : 2019/9/2 20:49
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
from urllib import request
from urllib import parse
def urllib_request():
base_url = 'http://www.tuling123.com/openapi/api'
payload = {
'key1': 'Your',
'key2': '你好'
}
ur = request.Request(url=base_url)
ur_response = request.urlopen(ur)
print('\n ur_response: \n\t', ur_response)
print('\n ur_response_getcode: \n\t ', ur_response.getcode)
print('\n ur_response_headers: \n\t ', ur_response.headers)
data = parse.urlencode(payload).encode('utf-8')
url_payload = request.Request(url=base_url, data=data)
url_payload_response = request.urlopen(url_payload)
print('\n url_payload_response: \n\t', url_payload_response)
print('\n url_payload_response_getcode: \n\t ', url_payload_response.getcode)
print('\n url_payload_response_headers: \n\t ', url_payload_response.headers)
print('\n url_payload_response_msg: \n\t ', url_payload_response.msg)
print('\n url_payload_response_read: \n\t ', url_payload_response.read)
urllib_request()
四、搭建测试接口平台
自搭建的接口平台使用Django框架进行开发,基于当前接口的需求(接口的增、删、改、查)功能,搭建一个满足需要的接口测试平台。
1. 环境搭建
1.1 项目创建
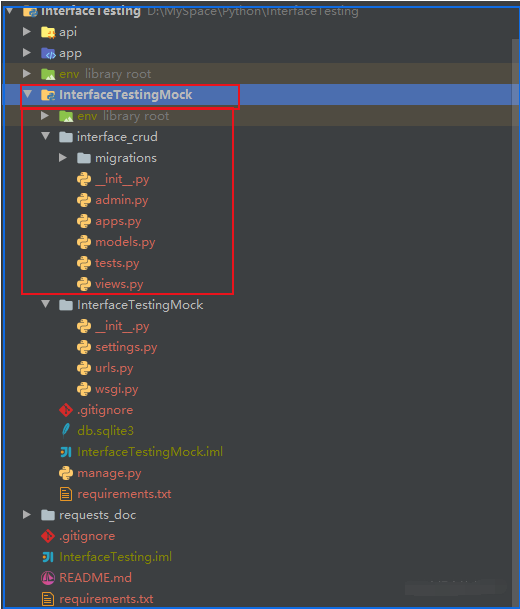
【GitHub示例】
# 下载 django 框架库
pip install django
# 创建 django 工程
django-admin startproject InterfaceTestingMock
# 创建 api_crud app
cd InterfaceTestingMock
python manage.py startapp interface_crud
# 创建 api_mock 工程的虚拟运行环境
viutualenv env
# 激活虚拟环境
source env/Scripts/activate
# 退出虚拟环境
deactivate
# 导出虚拟环境 env 所需要的库
pip freeze >> requirements.txt
1.2 接口开发配置
(1) 创建表结构
python manage.py migrat
(2) 编写模型层代码,以下语句相当于创建了两张表:User,Article
# interface_crud.models.py
from django.db import models
# Create your models here.
class User(models.Model):
id = models.AutoField(primary_key=True)
user_name = models.CharField(max_length=50)
user_password = models.CharField(max_length=100)
# active inactive
status = models.CharField(max_length=10)
class Article(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=50)
content = models.TextField()
# delete alive
status = models.CharField(max_length=10)
(3) 新增表,执行下面语句让 django 知道表发生了变化
python manage.py makemigrations interface_crud
(4) 再次创建表
python manage.py migrate
(5) 生成创建超级管理员账号
-
# 依次数据用户名、邮箱地址、密码、重复密码、确认(y) -
python manage.py createsuperuser
(6) 配置接口请求地址
# InterfaceTestingMock.urls.py
from django.contrib import admin
from django.urls import path
from interface_crud.views import add_article, modify_article
urlpatterns = [
path('admin/', admin.site.urls),
path('articles/', add_article),
path('articles<int: art_id>', modify_article)
]
2. 接口开发
&emsp:&emsp:就目前常用的接口参数传参形式分别有:表单类接口传参,多用于提供给前端页面(后续学习跟进总结);另一种常用的就是 json 传参形式的,这种传参形式能够满足开发处业务逻辑更为复杂的接口,本次接口开发就采用该形式。【GitHub示例】—【GitHub示例】
备注:2.1-2.6是根据【** [秦无殇的博客](https://www.cnblogs.com/webDepOfQWS/p/10693152.html)**】学习整理而来,谢谢这位老哥❀
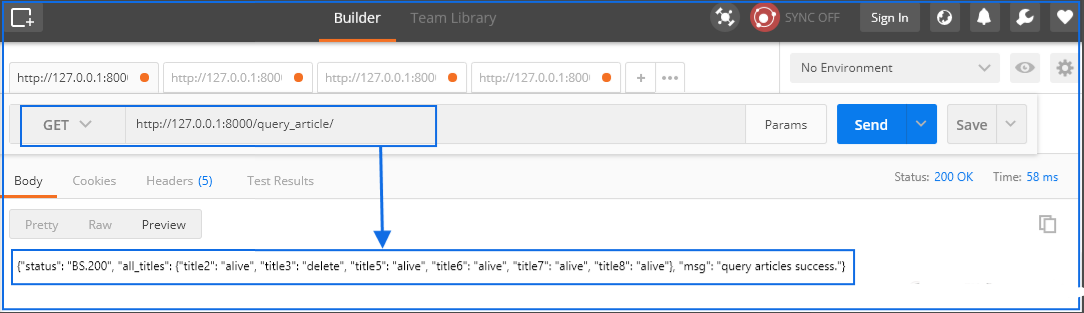
2.1 查询文章接口
from interface_crud.models import Article
from django.http import JsonResponse, HttpResponse
import json
# Create your views here.
# 查询文章
def query_article(request):
if request.method == 'GET':
articles = {}
query_articles = Article.objects.all()
print('query_articles: ', query_articles)
for title in query_articles:
articles[title.title] = title.status
return JsonResponse({"status": "BS.200", "all_titles": articles, "msg": "query articles success."})
print("request.body", request.body)
else:
return HttpResponse("方法错误")
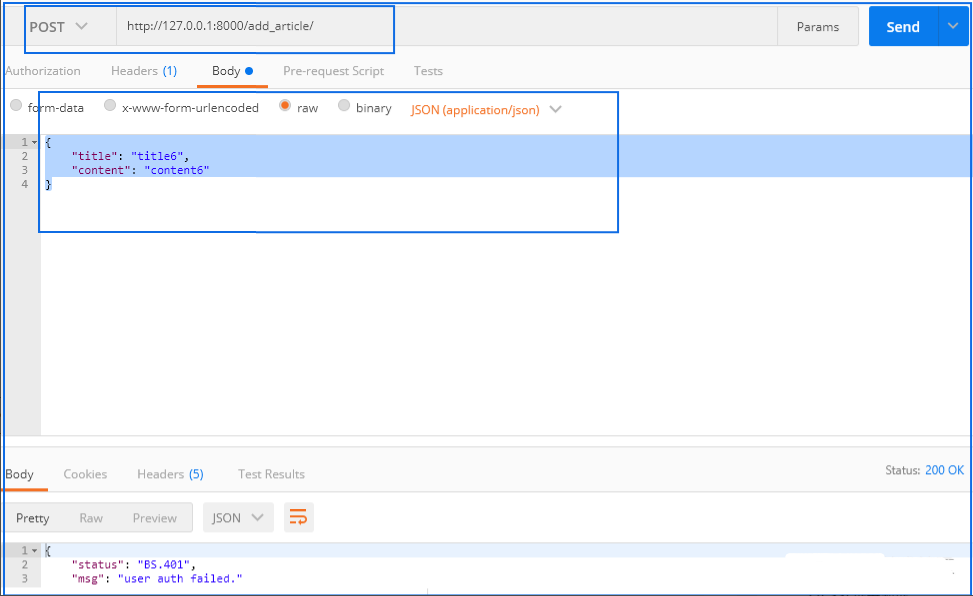
2.2 增加文章接口
# 增加文章
def add_article(request):
auth_res = user_auth(request)
if auth_res == "auth_fail":
return JsonResponse({"status": "BS.401", "msg": "user auth failed."})
else:
if request.method == "POST":
# b''
print('request.body: ', request.body)
print('request.body: ', type(request.body))
req_dict = json.loads(request.body)
print('req_json: ', req_dict)
print('req_json: ', type(req_dict))
key_flag = req_dict.get('title') and req_dict.get('content') and len(req_dict) == 2
print('key_flag: ', key_flag)
# 判断请求体是否正确
if key_flag:
title = req_dict['title']
content = req_dict['content']
# title返回的是一个list
title_exist = Article.objects.filter(title=title)
# 判断是否存在同名的title
if len(title_exist) != 0:
return JsonResponse({"status": "BS.400", "msg": "title already exist, fail to publish."})
"""
插入数据
"""
add_art = Article(title=title, content=content, status='alive')
add_art.save()
return HttpResponse(add_art)
return JsonResponse({"status": "BS.200", "msg": "add article success."})
else:
return JsonResponse({"status": "BS.400", "message": "please check param."})
else:
return HttpResponse("方法错误,你应该使用POST请求方式")
2.3 修改文章接口
# 更新文章
def modify_article(request, article_id):
auth_res = user_auth(request)
if auth_res == "auth_fail":
return JsonResponse({"status": "BS.401", "msg": "user auth failed."})
else:
if request.method == 'POST':
modify_req = json.loads(request.body)
try:
article = Article.objects.get(id=article_id)
print("article", article)
key_flag = modify_req.get('title') and modify_req.get('content') and len(modify_req) == 2
if key_flag:
title = modify_req['title']
content = modify_req['content']
title_exist = Article.objects.filter(title=title)
if len(title_exist) > 1:
return JsonResponse({"status": "BS.400", "msg": "title already exist."})
# 更新文章
old_article = Article.objects.get(id=article_id)
old_article.title = title
old_article.content = content
old_article.save()
return JsonResponse({"status": "BS.200", "msg": "modify article sucess."})
except Article.DoesNotExist:
return JsonResponse({"status": "BS.300", "msg": "article is not exists,fail to modify."})
else:
return HttpResponse("方法错误,你应该使用POST请求方式")
2.4 删除文章接口
# 删除文章
def delete_article(request, article_id):
auth_res = user_auth(request)
if auth_res == "auth_fail":
return JsonResponse({"status": "BS.401", "msg": "user auth failed."})
else:
if request.method == 'DELETE':
try:
article = Article.objects.get(id=article_id)
article_id = article.id
article.delete()
return JsonResponse({"status": "BS.200", "msg": "delete article success."})
except Article.DoesNotExist:
return JsonResponse({"status": "BS.300", "msg": "article is not exists,fail to delete."})
else:
return HttpResponse("方法错误,你应该使用DELETE请求方式")
2.5 token认证
# 用户认证
# 四个简单的接口已经可以运行了,但是在发请求之前没有进行鉴权,毫无安全性可言。下面来实现简单的认证机制。需要用到内建模块hashlib,hashlib提供了常见的摘要算法,如MD5,SHA1等。
def user_auth(request):
token = request.META.get("HTTP_X_TOKEN", b'')
print("token: ", token)
if token:
# 暂时写上 auth 接口返回的数据
if token == '0a6db4e59c7fff2b2b94a297e2e5632e':
return "auth_success"
else:
return "auth_fail"
else:
return "auth_fail"
2.6 接口测试
在接口开发是不断开发不断测试是一个非常好的习惯。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : interface_crud_tests.py
@Time : 2019/9/4 14:22
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
import requests
import unittest
class TestInterfaceCrud(unittest.TestCase):
@unittest.skip("跳过 test_query_article 测试")
def test_query_article(self):
payload = {}
res = requests.get('http://127.0.0.1:8000/query_article/', params=payload)
print("test_query_article: ", res.text)
@unittest.skip("跳过 test_add_article 测试")
def test_add_article(self):
payload = {
"title": "title5",
"content": "content5",
}
Headers = {
# "Authorization": '通用的token,但是该接口使用的是X-Token',
"Content-Type": "application/json; charset=utf-8",
"Accept": "application/json",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3730.400 QQBrowser/10.5.3805.400",
"X-Token": "0a6db4e59c7fff2b2b94a297e2e5632e"
}
res = requests.post('http://127.0.0.1:8000/add_article/', headers=Headers, json=payload)
print(res.request)
print(res.text)
@unittest.skip("跳过 test_modify_article 测试")
def test_modify_article(self):
payload = {
"title": "title1",
"content": "content1",
}
Headers = {
# "Authorization": '通用的token,但是该接口使用的是X-Token',
"Content-Type": "application/json; charset=utf-8",
"Accept": "application/json",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3730.400 QQBrowser/10.5.3805.400",
"X-Token": "0a6db4e59c7fff2b2b94a297e2e5632e"
}
res = requests.post('http://127.0.0.1:8000/modify_article/1', headers=Headers, json=payload)
print(res.request)
print(res.text)
# @unittest.skip("跳过 test_delete_article 测试")
def test_delete_article(self):
payload = {
"title": "title2",
"content": "content2",
}
Headers = {
# "Authorization": '通用的token,但是该接口使用的是X-Token',
"Content-Type": "application/json; charset=utf-8",
"Accept": "application/json",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3730.400 QQBrowser/10.5.3805.400",
"X-Token": "0a6db4e59c7fff2b2b94a297e2e5632e"
}
res = requests.delete('http://127.0.0.1:8000/delete_article/2', headers=Headers, json=payload)
print(res.request)
print(res.text)
@unittest.skip("跳过 test_test_api 测试")
def test_test_api(self):
payload = {
'title': 'title1',
'content': 'content1',
'status': 'alive'
}
res = requests.post('http://127.0.0.1:8000/test_api/')
print(res.text)
if __name__ == '__main__':
unittest.main()
五、接口自动化
1. 数据处理
1.1 Excel中数据
获取 excel 的第几 sheet 页,行数,列数,单元格值,数据写入 excel操作。【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : operate_excel.py
@Time : 2019/9/5 10:07
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : 对 Excel 的读写操作
"""
import xlrd
from xlutils.copy import copy
class OperateExcel(object):
def __init__(self, file_name=None, sheet_id=None):
"""
:param file_name: excel文件的具体路径名称
:param sheet_id: 要操作的第几 sheet 页
"""
if file_name:
self.file_name = file_name
else:
self.file_name = '../data/util_data/operate_excel.xls'
if sheet_id:
self.sheet_id = sheet_id
else:
self.sheet_id = 0
self.sheet_table = self.get_sheet()
# 获取 sheet 页操作对象
def get_sheet(self):
data = xlrd.open_workbook(self.file_name)
sheet_table = data.sheets()[self.sheet_id]
return sheet_table
# 获取该 sheet 页的行数和列数,拿到的是一个元组
def get_sheet_nrows_ncols(self):
return self.sheet_table.nrows, self.sheet_table.ncols
# 获取该 sheet 页的行数
def get_sheet_nrows(self):
return self.sheet_table.nrows
# 获取该 sheet 页的列数
def get_sheet_ncols(self):
return self.sheet_table.ncols
# 获取具体单元格的数据
def get_sheet_cell(self, row, col):
"""
:param row: 单元格的行值
:param col: 单元格的列值
:return: cell_data
"""
cell_data = self.sheet_table.cell_value(row, col)
return cell_data
# 写入数据到 excel 中
def write_to_excel(self, row, col, value):
# 同样的先打开 excel 操作句柄
data = xlrd.open_workbook(self.file_name)
copy_data = copy(data)
# 选择写入的 sheet 页
copy_data_sheet = copy_data.get_sheet(0)
# 写入数据
copy_data_sheet.write(row, col, value)
# 保存数据
copy_data.save(self.file_name)
if __name__ == "__main__":
oe = OperateExcel()
print("获取 excel 表的行数和列表,返回元组形式:", oe.get_sheet_nrows_ncols())
print("获取 excel 表的行数:", oe.get_sheet_nrows())
print("获取 excel 表的列数:", oe.get_sheet_ncols())
print("获取单元格(1, 1)的值:", oe.get_sheet_cell(1, 1))
print("获取单元格(1, 2)的值:", oe.get_sheet_cell(1, 2))
print("获取单元格(2, 2)的值:", oe.get_sheet_cell(2, 2))
oe.write_to_excel(17, 7, '写入的数据')
1.2 JSON中数据
【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : operate_json.py
@Time : 2019/9/5 12:24
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : 操作 JSON 文件中的数据
"""
import json
class OperateJson(object):
def __init__(self, file_name=None):
if file_name:
self.file_name = file_name
else:
self.file_name = '../data/util_data/operate_json.json'
self.data = self.get_json()
# 读取 json 文件
def get_json(self):
with open(self.file_name, encoding='utf-8') as fp:
data = json.load(fp)
return data
# 根据关键词读取数据
def get_key_data(self, key):
return self.data[key]
if __name__ == '__main__':
oj = OperateJson()
print('login: ', oj.get_key_data("login"))
print('login.username: ', oj.get_key_data("login")["username"])
print('login.password: ', oj.get_key_data("login")["username"])
print('logout: ', oj.get_key_data("logout"))
print('logout.code: ', oj.get_key_data("logout")["code"])
print('logout.info: ', oj.get_key_data("logout")["info"])
{
"login": {
"username": "kevin",
"password": "121345"
},
"logout": {
"code": 200,
"info": "logout"
}
}
1.3 数据库中的数据
数据库用的常用的MySQL。【GitHub示例】
远程连接数据库可能会连接出错的解决方法:GRANT ALL PRIVILEGES ON . TO ‘root’@‘%’ IDENTIFIED BY ‘你的密码’ WITH GRANT OPTION;
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : operate_mysql.py
@Time : 2019/9/5 16:10
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : 操作 数据库 中的数据
"""
import pymysql
import json
class OperateMysql(object):
def __init__(self):
# 数据库初始化连接
self.connect_interface_testing = pymysql.connect(
"XXX.XXX.XXX.XXX",
"XXX",
"XXXXXXXX",
"InterfaceTesting",
cursorclass=pymysql.cursors.DictCursor
)
# 创建游标操作数据库
self.cursor_interface_testing = self.connect_interface_testing.cursor()
def select_data(self, sql):
# 执行 sql 语句
self.cursor_interface_testing.execute(sql)
# 获取查询到的第一条数据
first_data = self.cursor_interface_testing.fetchone()
# 将返回结果转换成 str 数据格式
first_data = json.dumps(first_data)
return first_data
if __name__ == "__main__":
om = OperateMysql()
res = om.select_data(
"""
SELECT * FROM test_table;
"""
)
print(res)
2. 邮件告警
通常我们做接口自动化测试的时候,自动化用例执行结束后,我们需要首先需要看自动化用例是不是执行结束了,另外它的执行结果是什么。我们不可能一直紧盯着脚本执行,所以当自动化执行结束后,我们需要发送邮件来进行提醒并把自动化的执行情况邮件通知。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : email_config.py
@Time : 2019/9/5 18:58
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : 发送邮件配置
"""
import smtplib
from email.mime.text import MIMEText
class EmailConfig(object):
global send_user
global mail_host
global password
send_user = '发送者邮箱@163.com'
mail_host = 'smtp.163.com'
password = '邮箱服务器密码'
def send_config(self, user_lists, subject, content):
user = "发件人昵称" + "<" + send_user + ">"
message = MIMEText(content, _subtype="plain", _charset="utf-8")
message['Subject'] = subject
message['From'] = user
message['To'] = ";".join(user_lists)
server = smtplib.SMTP()
server.connect(mail_host)
server.login(send_user, password)
server.sendmail(user, user_lists, message.as_string())
server.close()
def send_mail(self, pass_cases, fail_cases, not_execute_cases):
pass_num = float(len(pass_cases))
fail_num = float(len(fail_cases))
not_execute_num = float(len(not_execute_cases))
execute_num = float(pass_num + fail_num)
total_cases = float(pass_num + fail_num + not_execute_num)
pass_ratio = "%.2f%%" % (pass_num / total_cases * 100)
fail_ratio = "%.2f%%" % (fail_num / total_cases * 100)
user_lists = ['crisimple@foxmail.com']
subject = "【邮件配置测试】"
content = "一共 %f 个用例, 执行了 %f 个用例,未执行 %f 个用例;成功 %f 个,通过率为 %s;失败 %f 个,失败率为 %s" % (total_cases, execute_num, not_execute_num, pass_num, pass_ratio, fail_num, fail_ratio)
self.send_config(user_lists, subject, content)
if __name__ == "__main__":
ec = EmailConfig()
ec.send_mail([1, 3, 5], [2, 4, 6], [1, 2, 3])
3. 封装测试
3.1 多种请求方式兼容
通过第四模块的接口开发,我们知道接口的请求方式有多种,在接口测试时我们不可能针对不同请求方式的接口不断的改变它的请求方法形式和参数,所以可以将多种不同请求方式统一整合,只改变请求方法(GET、POST、DELETE、UPDATE)来切换不同的请求形式。【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : intergrate_request.py
@Time : 2019/9/6 7:56
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : 多种请求方法集成
"""
import requests
import json
class IntergrateRequest():
# 请求 request方法
def get_req(self, url, data=None, headers=None):
if headers is not None:
res = requests.get(url, data, headers).json()
else:
res = requests.get(url, data).json()
return res
# post 请求方式
def post_req(self, url, data=None, headers=None):
if headers is not None:
res = requests.post(url, data, headers).json()
else:
res = requests.post(url, data).json()
return res
# delete 请求方式
def delete_req(self, url, data=None, headers=None):
if headers is not None:
res = requests.delete(url, data, headers).json()
else:
res = requests.delete(url, data).json()
return res
def main_req(self, method, url, data=None, headers=None):
if method == "get":
res = self.get_req(url, data, headers)
elif method == 'post':
res = self.post_req(url, data, headers)
elif method == 'delete':
res = self.delete_req(url, data, headers)
else:
res = "你的请求方式暂未开放,请耐心等待"
return json.dumps(res, ensure_ascii=False, indent=4, sort_keys=True)
if __name__ == "__main__":
ir = IntergrateRequest()
method = 'get'
url = 'http://127.0.0.1:8000/query_article/'
data = None
headers = None
print(ir.main_req(method, url, data, headers))
3.2 自动化封装
前面已经把相当一部分的准备工作做好了,接下来就该进行对各个模块进行封装。
(1) 获取试用例关键字段
等一下详细说明:【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : testcases_keyword.py
@Time : 2019/9/6 16:21
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
class TestcasesKeyword(object):
CASE_ID = '0'
CASE_NAME = '1'
IS_EXECUTE = '2'
INTERFACE_URL = '3'
METHOD = '4'
HEADER = '5'
PAYLOAD = '6'
EXPECTED_RESULT = '7'
ACTUAL_RESULT = '8'
# 获取自动化用例 ID
def get_case_id():
return TestcasesKeyword.CASE_ID
def get_case_name():
return TestcasesKeyword.CASE_NAME
def get_is_execute():
return TestcasesKeyword.IS_EXECUTE
def get_interface_url():
return TestcasesKeyword.INTERFACE_URL
def get_method():
return TestcasesKeyword.METHOD
def get_header():
return TestcasesKeyword.HEADER
def get_payload():
return TestcasesKeyword.PAYLOAD
def get_expected_result():
return TestcasesKeyword.EXPECTED_RESULT
def get_actual_result():
return TestcasesKeyword.ACTUAL_RESULT
if __name__ == "__main__":
print(get_case_id())
(2) 业务场景封装
写代码的作用就是为业务场景服务,是的前面各个模块只是我们的技术栈的积累。这里开始我们算是真正进入业务层面逻辑的设计。比如对于接口自动化这块的测试,拿到自动化用例,我们怎么处理这些用例呢?如果自动化用例是存放在 Excel 中的话,我们首选要拿到每条测试用例各个关键的字段值,根据这些关键字的特定含义看是否执行,是否给接口传header,或是将用例的最后执行结果写回到 execel 中去。是的没错,通过这样的描述我们就是在对自动化用例做业务层面的具体封装。【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : get_excel_testcases.py
@Time : 2019/9/6 18:14
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
from util.operate_excel import OperateExcel
from basic import testcases_keyword
class GetExcelTestcases(object):
def __init__(self):
self.oe = OperateExcel()
# 获取测试用例条数,也就是 Excel 中的行数
def get_cases_num(self):
return self.oe.get_sheet_nrows()
# 判断是否携带 headers
def is_header(self, row):
col = int(testcases_keyword.get_header())
header = self.oe.get_sheet_cell(row, col)
if header is not None:
return header
else:
print("你的 header 呢?")
return None
# 判断该条用例是否执行
def get_is_run(self, row):
flag = None
col = int(testcases_keyword.get_is_execute())
is_run = self.oe.get_sheet_cell(row, col)
if is_run is not None:
flag = True
else:
flag = False
return flag
# 获取不同接口的请求方式
def get_method(self, row):
col = int(testcases_keyword.get_method())
method = self.oe.get_sheet_cell(row, col)
return method
# 获取要测试的接口链接
def get_url(self, row):
col = int(testcases_keyword.get_interface_url())
url = self.oe.get_sheet_cell(row, col)
return url
# 获取接口参数
def get_payload(self, row):
col = int(testcases_keyword.get_payload())
payload = self.oe.get_sheet_cell(row, col)
if payload is None:
return None
return payload
# 获取预期结果
def get_expected_result(self, row):
col = int(testcases_keyword.get_expected_result())
expected_result = self.oe.get_sheet_cell(row, col)
if expected_result is None:
return None
return expected_result
# 写入实际结果
def write_actual_result(self, row, value):
col = int(testcases_keyword.get_actual_result())
self.oe.write_to_excel(row, col, value)
if __name__ == "__main__":
gety = GetExcelTestcases()
print(gety.get_cases_num())
print(gety.is_header(1))
3. 执行自动化用例
接下来就是执行测试用例了。【GitHub示例】
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : run_excel_testcases.py
@Time : 2019/9/7 13:05
@Author : Crisimple
@Github : https://crisimple.github.io/
@Contact : Crisimple@foxmail.com
@License : (C)Copyright 2017-2019, Micro-Circle
@Desc : None
"""
from basic.get_excel_testcases import GetExcelTestcases
from basic.intergrate_request import IntergrateRequest
from util.email_config import EmailConfig
from util.operate_json import OperateJson
from util.compare_str import CompareStr
class RunExcelTestcases(object):
def __init__(self):
self.gtc = GetExcelTestcases()
self.ir = IntergrateRequest()
self.ec = EmailConfig()
self.oj = OperateJson()
self.cs = CompareStr()
# 执行测试用例
def run_testcases(self):
# 定义空列表,存放执行成功和失败的测试用例
pass_lists = []
fail_lists = []
no_execute_lists = []
# no_execute_case_name = []
# 获取总的用例条数
cases_num = self.gtc.get_cases_num()
# 遍历执行每一条测试用例
for case in range(1, cases_num):
# 用例是否执行
is_run = self.gtc.get_is_run(case)
# print("is_run: ", is_run)
# 接口的请求方式
method = self.gtc.get_method(case)
# 请求测试接口
url = self.gtc.get_url(case)
# 要请求的数据
data = self.gtc.get_payload(case)
# 取出 header
if case == 1:
header = None
else:
header = self.oj.get_json()
# 获取预期结果值 expected_result
expected_result = self.gtc.get_expected_result(case)
if is_run is True:
res = self.ir.main_req(method, url, data, header)
if self.cs.is_contain(expected_result, res):
self.gtc.write_actual_result(case, 'pass')
pass_lists.append(case)
else:
self.gtc.write_actual_result(case, res)
fail_lists.append(case)
else:
no_execute_lists.append(case)
print("没有执行的测试用例有, 按序号有:", no_execute_lists)
self.ec.send_mail(pass_lists, fail_lists, no_execute_lists)
if __name__ == "__main__":
rts = RunExcelTestcases()
rts.run_testcases()
4. 持续集成
为什么要使用持续继承环境呢?通过前面的开发测试整个流程,我们清晰的发现,不管是接口还是自动化程序执行,都需要人为来控制,这是个很低技术含量但是又是不得不做的一个事。引进持续继承,就是让它来做一些重复的事情。
4.1 Jenkins环境搭建
(1) 环境配置
# jenkins是基于 Java 环境的,所以首先安装Java SDK
sudo apt-get install openjdk-8-jdk
# 将 jenkins 存储库密钥添加到系统
wget -q -O - https://pkg.jenkins.io/debian/jenkins-ci.org.key | sudo apt-key add -
# 将Debian包存储库地址附加到服务器的sources.list
echo deb http://pkg.jenkins.io/debian-stable binary/ | sudo tee /etc/apt/sources.list.d/jenkins.list
# 更新存储库
sudo apt-get update
# 安装 Jenkins
sudo apt-get install jenkins
(2) Jenkins 的常用命令
# Jenkins 启动 | 查看状态 | 重启 | 停止
sudo service jenkins start|status|restart|stop
# jenkins启动后的访问地址:http:// ip_address_or_domain_name :8080
# 访问上面的地址会发现需要输入初始密码,查看获取初始密码
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
4.2 接口继承
(1) 新建模拟接口(InterfaceTestingMock)任务
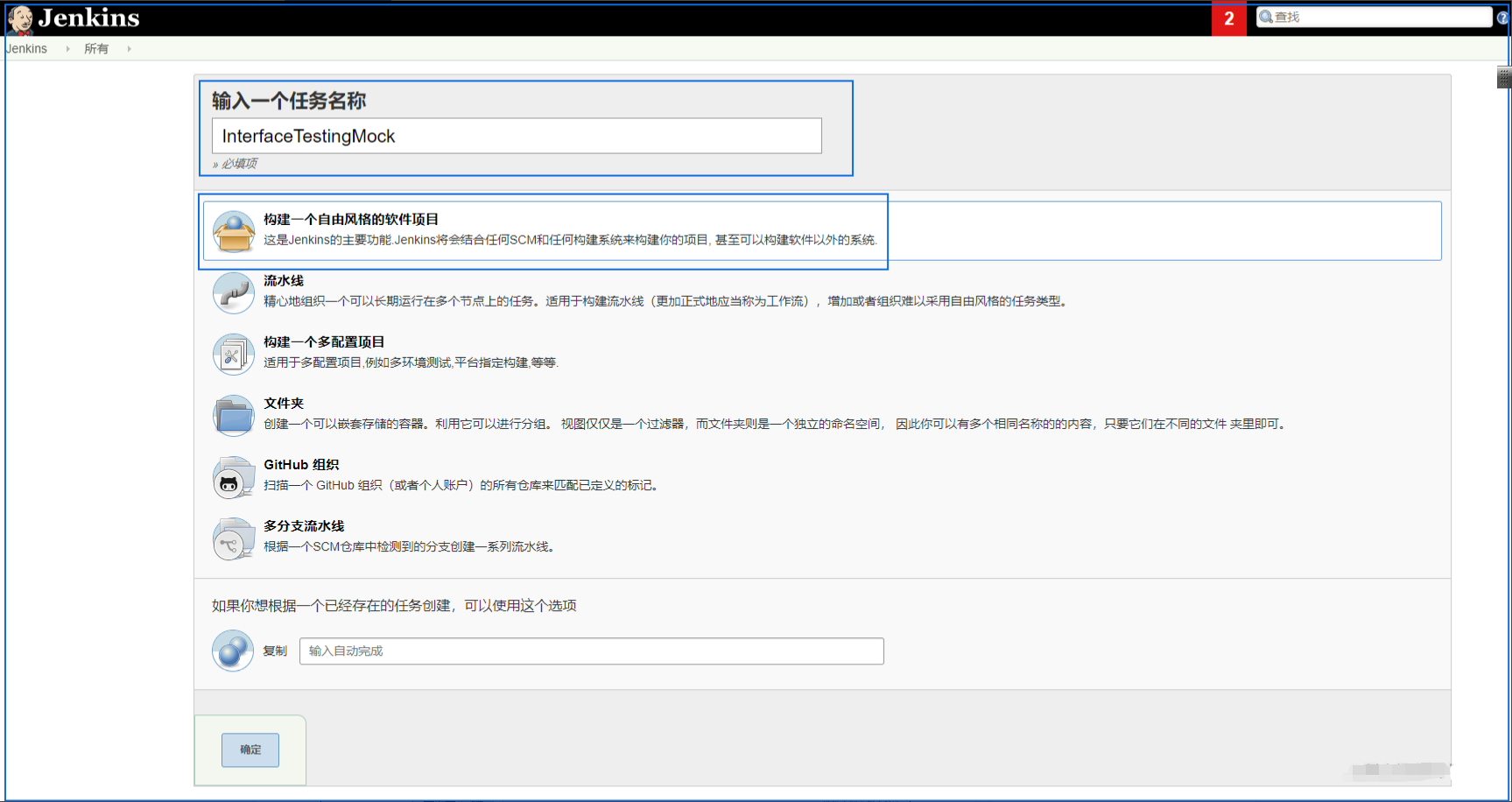
(2) 源码管理
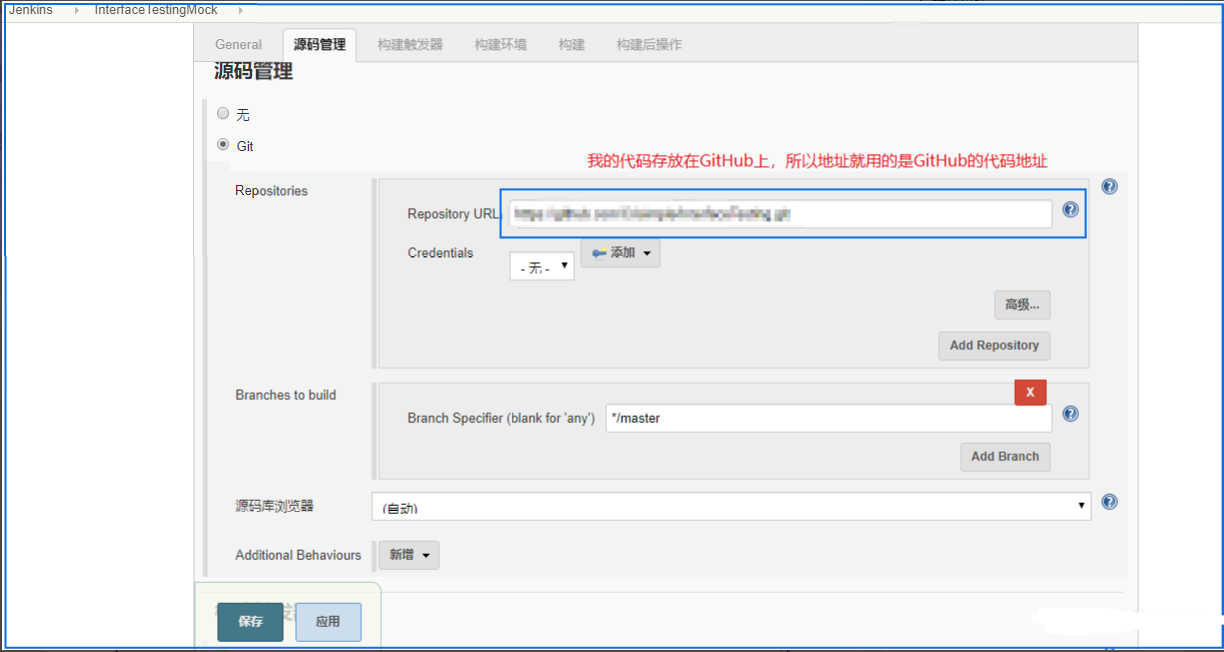
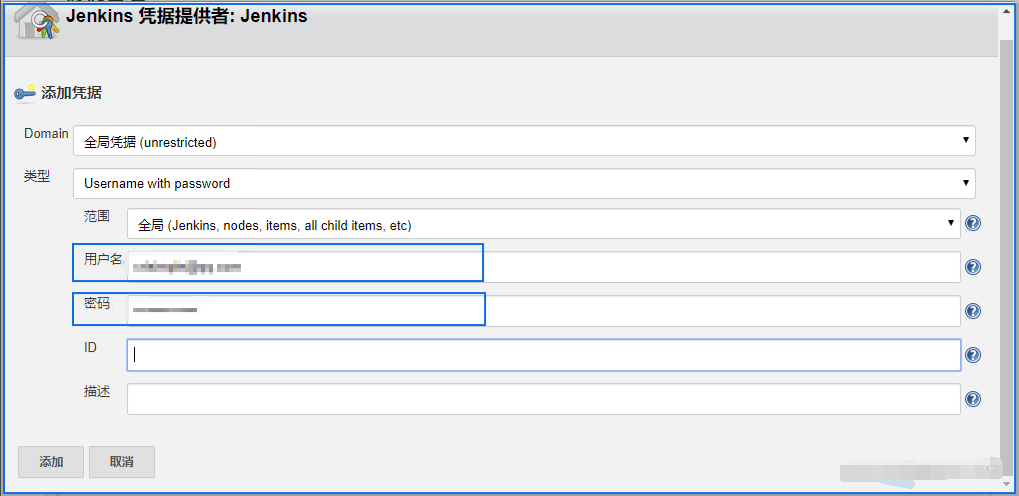
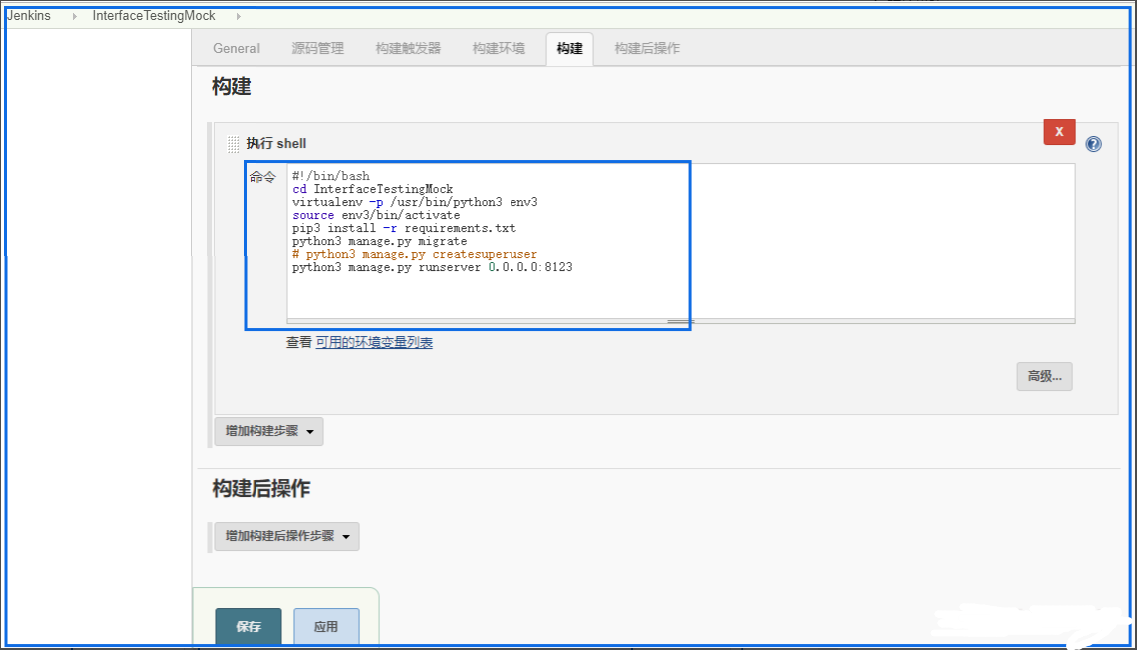
(3) 配置构建脚本
构建的是否,你可能会出现一些问题。我遇到就是无法创建超级用户,解决方案是:是权限的问题,我的解决方案是sudo python manage.py createsuperuser,执行创建超级用户前加sudo就可以了。如有问题可以留言
4.3 接口自动化集成
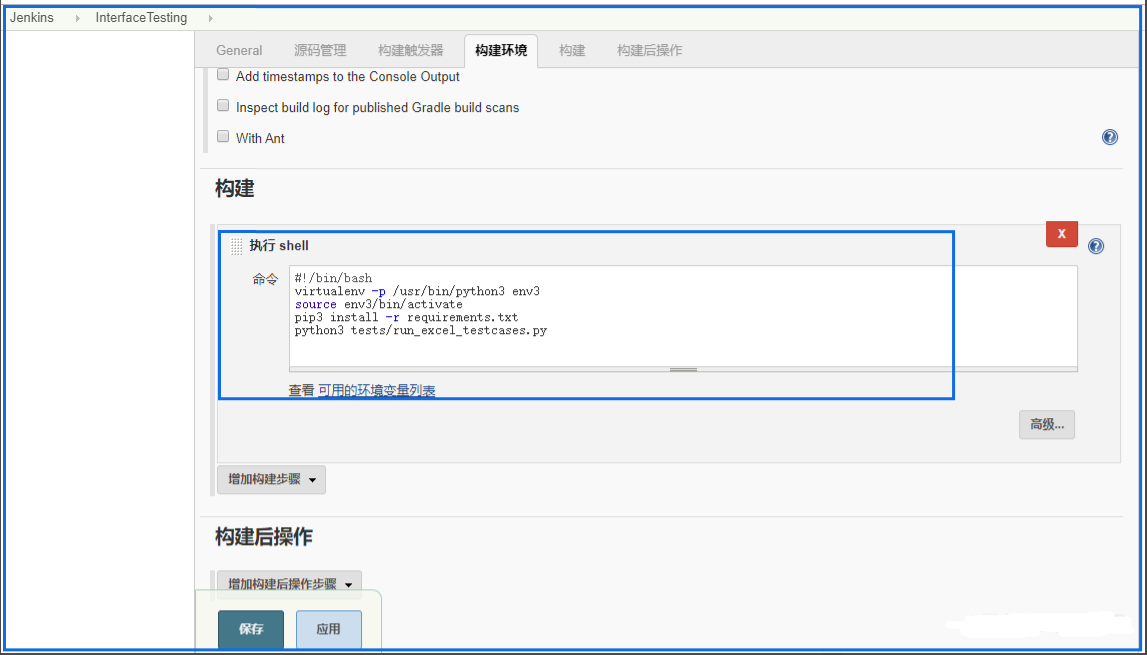
对于在命令行中执行程序时,通常会报错NoMoudle的错误的 解决方案。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维副业方向
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
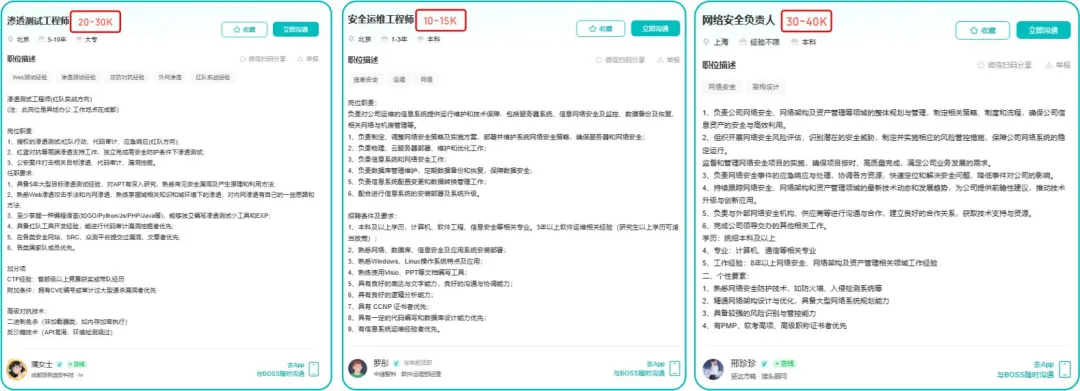
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
运维转行学习路线
(一)第一阶段:网络安全筑基
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
(二)第二阶段:漏洞挖掘与 SRC 漏扫实战
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
(三)第三阶段:渗透测试技能学习
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
(四)第四阶段:企业级安全攻防(含红蓝对抗)、应急响应
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
运维转行网络攻防知识库分享
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
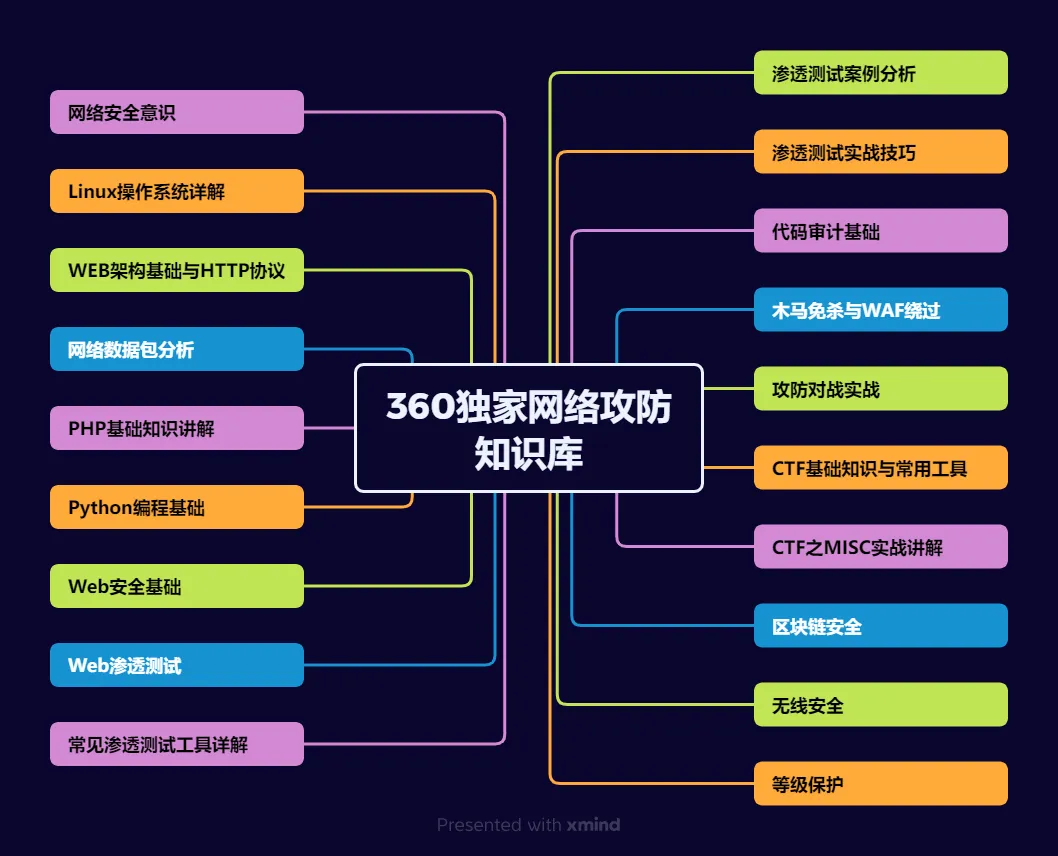
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









