




 本文探讨在云服务器上,如何有效回收未被用户关联的文件。通过对比单次查询所有和分批次查询加临时文件存储两种策略,解决大数据量下内存消耗过大的问题。
本文探讨在云服务器上,如何有效回收未被用户关联的文件。通过对比单次查询所有和分批次查询加临时文件存储两种策略,解决大数据量下内存消耗过大的问题。
运行环境 CentOS7 1G内存 40G硬盘(某某云服务器,学生价9.5一个月)
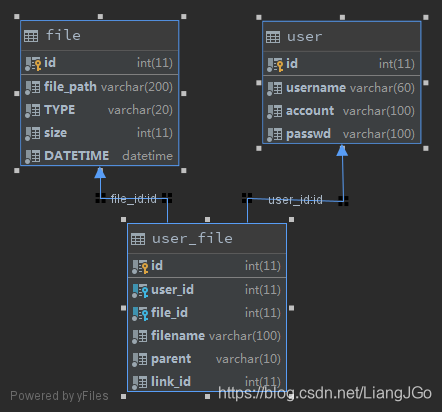
数据表结构
硬盘中文件存放方式是:
以月为单位创建目录,同一个月的文件放在同一个目录中。
文件名格式为:时间戳+原始文件名
如:E:\development\upload\20196\1561637254739img.jpeg
数据库的file表存有文件的真实路径,user_file表则是用户表user与file表多对多的一个关联表,user_file表中的 link_id 字段是一个与 file 表关联的外键,当用户删除自己保存的文件时只是删除user_file表的记录,并不会直接删除file表中的记录,因为file可能还有其他用户关联。
当全部用户都没有关联该file记录时,该file记录就应该被删除,对应的文件也就应该被删除。
由于文件文件量比较大,数据库记录信息也比较多,所以需要在一个特定的时间去回收,使用spring的task组件,设置一个定时执行任务,设置在每天的凌晨3点进行文件回收
方式1,单次查询所有:
回收步骤:
- 查询出全部user_file的 link_id(封装成Long对象), 存放在一个List中, 命名为 linkIdList
- 查询出全部 file 记录(每条记录封装成一个pojo的一个WPFile对象),也存放在一个List中, 命名为wpFileList。
- 比较两个List,取出wpFileList中 id 属性值不在linkIdList中的对象,将该对象的 filePath 属性存放在List中,命名为pathList,这个pathList中的路径则是没有用户关联的,路径对应的文件应该被删除。这些对象对应于file表中的记录也应该被删除。
回收结束
这样子虽然能成功的回收文件,但是在小数据量时没有问题,在数据量大时就会出现内存消耗过大的问题。在一百万条数据时,wpFileList集合需要 163 m 内存, linkIdList需要 27m内存,当三百万条数据服务器就吃不消了,方法不可行。
方式2,分批次查询+临时文件存储:
既然一次过把所有文件都存入List中会造成内存消耗过大问题,那么能不能分批次进行查询,每一次只查询一部分(我暂时一次查100000条),这样wpFileList集合只需要 16 m左右的内存,linkIdList则只需要 2.7m左右内存,这样即使是数据库中有一千万或上亿条数据,也没关系,只要查询次数增加即可,不会出现瞬间内存爆炸的风险。
步骤:
- 不断循环查询,每次查询十万条,直到数据查询完毕。每次查询的结果只取一部分有用的数据存入临时文件中。两个文件的查询方式类似。这样就得到了两个临时文件wpfile.txt 和 userfile.txt。wpfile.txt 存放了file的id和文件路径,userfile.txt存放了link_id.
- 比较wpfile.txt 的id 和userfile.txt 的link_id , 如果在userfile.txt文件中没有wpfile.txt 的id对应值,表示wpfile.txt文件中的这一行数据应该被删除了(没有人关联他),记录在deletefile.txt临时文件中
- 读取deletefile.txt每一行数据,一行(格式为:“id path”)中id 代表一条要数据库中file表中要删除的行,path代表硬盘中要删除文件的路径。删除即可
github地址为:https://github.com/liangjiegao/java-

















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









