



seq2seq
1. 概述
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列。它涉及两个过程:Encoder 中将一个可变长度的信号序列变为固定长度的向量表达。Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。通常encoder及decoder均采用RNN结构如LSTM或GRU等。
可用于机器翻译、文本生成、语言模型、语音识别等领域。
2. RNN
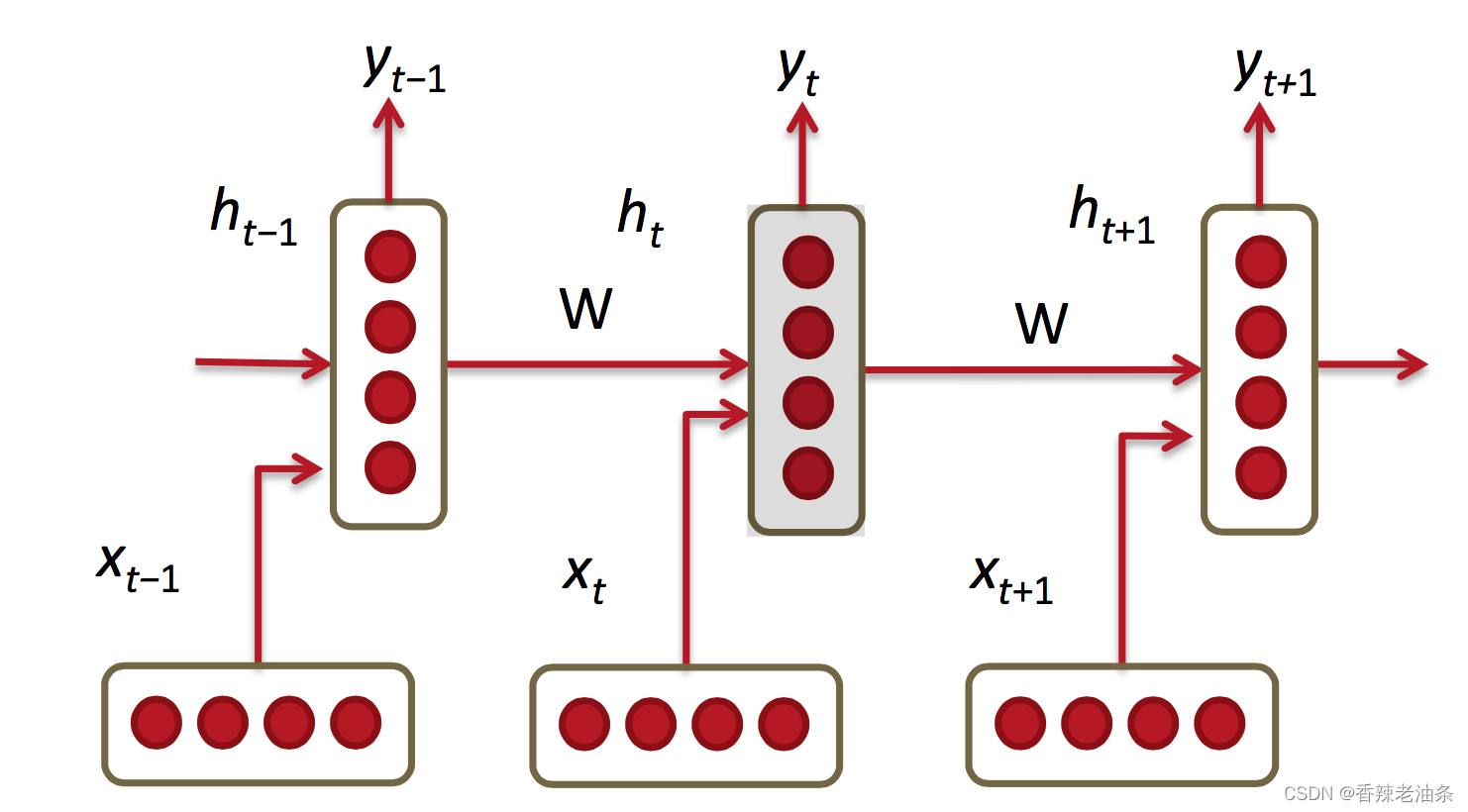
RNN 基本的模型如上图所示,每个神经元接受的输入包括:前一个神经元的隐藏层状态 h(用于记忆) 和当前的输入 x (当前信息)。神经元得到输入之后,会计算出新的隐藏状态 h 和输出 y,然后再传递到下一个神经元。因为隐藏状态 h 的存在,使得 RNN 具有一定的记忆功能。
针对不同任务,RNN有多种结构。
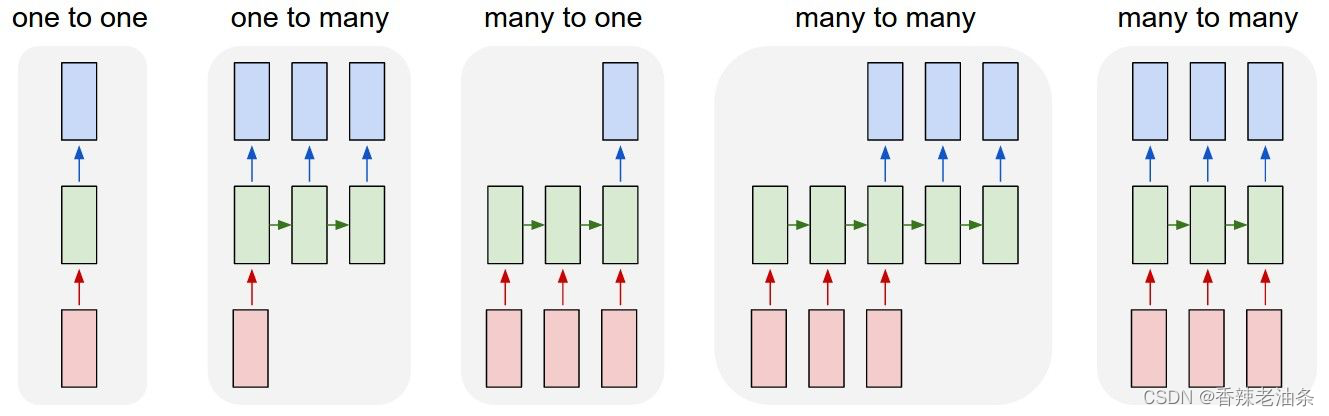
RNN不仅能够处理序列输入,也能够得到序列输出,这里的序列指的是向量的序列。
3. Seq2Seq 模型
RNN 的输入和输出个数都有一定的限制,实际中很多任务的序列的长度是不固定的,例如机器翻译中,源语言、目标语言的句子长度不一样;对话系统中,问句和答案的句子长度不一样。
Seq2Seq 是一种重要的 RNN 模型,也称为 Encoder-Decoder 模型,可以理解为一种 N×M的模型。该框架由这篇论文提出:Sutskever et al.(2014) Sequence to Sequence Learning with Neural Networks
模型包含两个部分:Encoder 用于编码序列的信息,将任意长度的序列信息编码到一个向量 c 里。而 Decoder 是解码器,解码器得到上下文信息向量 c 之后可以将信息解码,并输出为序列。Seq2Seq 模型结构有很多种,结构差异主要存在于Decoder部分。下面是几种比较常见的:
第一种:
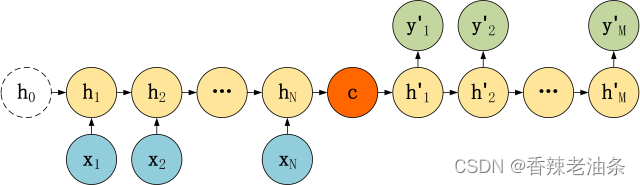
第二种:
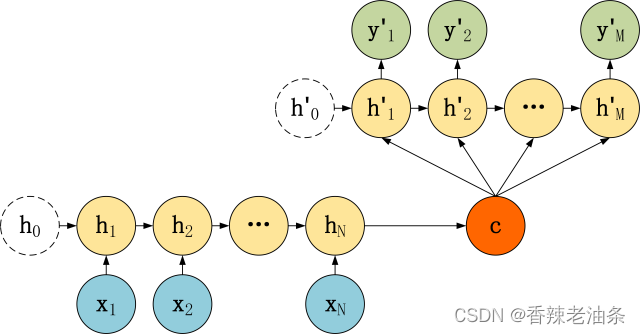
第三种:
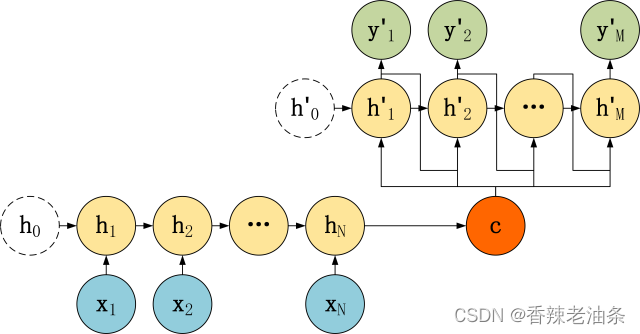
3.1 编码器 Encoder
Encoder 的 RNN 接受输入 x,最终输出一个编码所有信息的上下文向量 c,中间的神经元没有输出。Decoder 主要传入的是上下文向量 c,然后解码出需要的信息。上下文向量C的不一定就是最后一个隐藏层的输出。
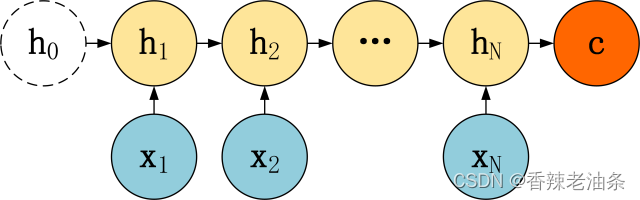
上下文向量C:
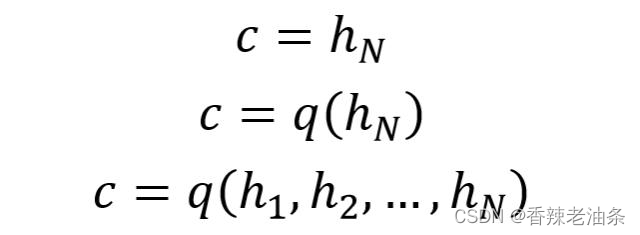
从公式可以看到,c可以直接使用最后一个神经元的隐藏状态 hN 表示;也可以在最后一个神经元的隐藏状态上进行某种变换 hN 而得到,q 函数表示某种变换;也可以使用所有神经元的隐藏状态 h1, h2, …, hN 计算得到。
3.2 解码器Decoder
相对于编码器而言,解码器的结构更多,论文的主要创新也是在Decoder,下面介绍三种。
第一种:
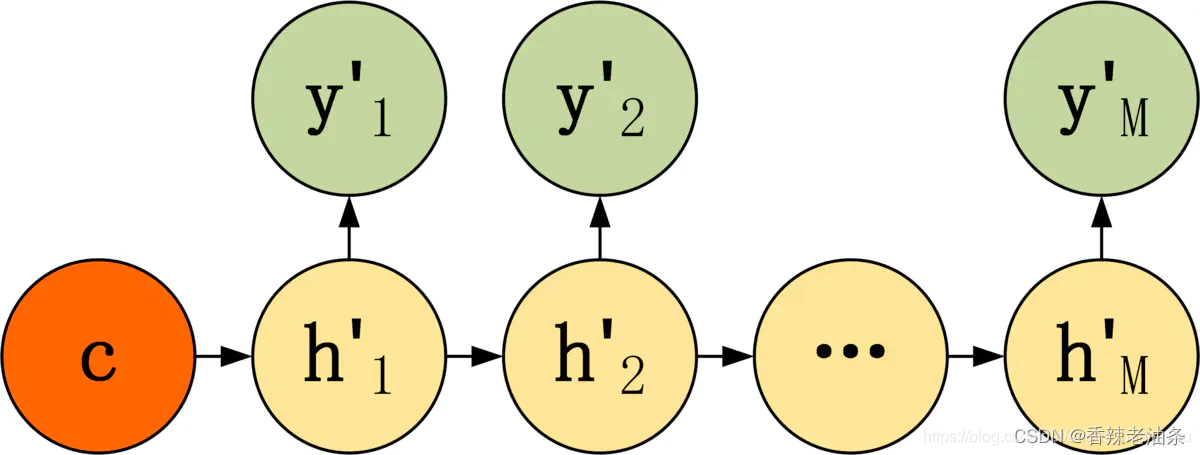
直接将Decoder得到的上下文向量作为RNN的初始隐藏状态输入到RNN结构中,后续单元不接受 c 的输入,计算公式如下:
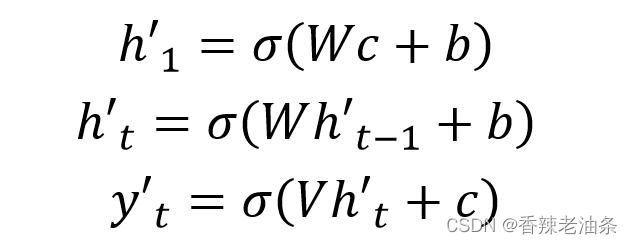
第二种:
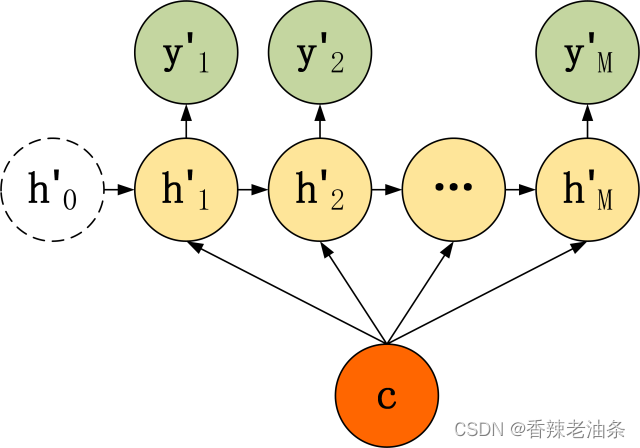
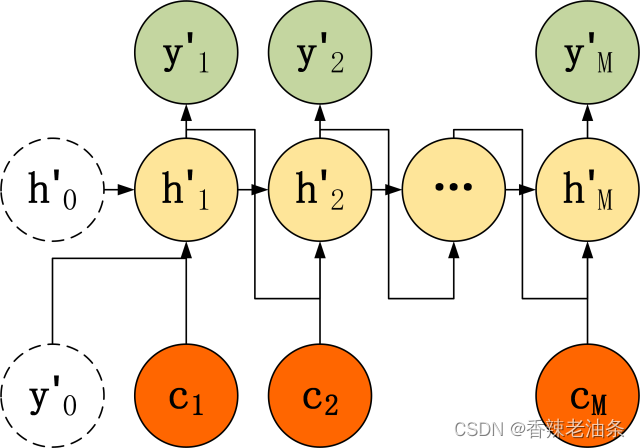
二种 Decoder 结构有了自己的初始隐藏层状态 h’0,不再把上下文向量 c当成是 RNN 的初始隐藏状态,而是当成 RNN 每一个神经元的输入。可以看到在 Decoder 的每一个神经元都拥有相同的输入 c,这种 Decoder 的隐藏层及输出计算公式:
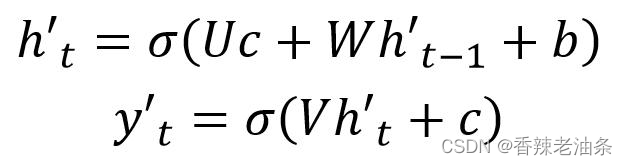
第三种:
第三种 Decoder 结构和第二种类似,但是在输入的部分多了上一个神经元的输出 y’。即每一个神经元的输入包括:上一个神经元的隐藏层向量 h’,上一个神经元的输出 y’,当前的输入 c(Encoder 编码的上下文向量)。对于第一个神经元的输入 y’0,通常是句子其实标志位的 embedding 向量。第三种 Decoder 的隐藏层及输出计算公式:
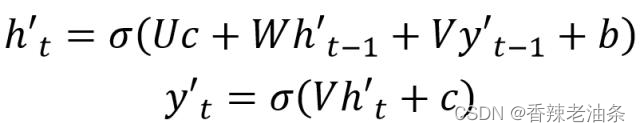
3.3 Attention模型
Encoder-Decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是上下文向量C无法完全表示整个序列的信息,二是先输入的内容携带的信息会被后输入的信息稀释掉。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码时准确率就要打一定折扣。
为了解决上述问题,在 Seq2Seq出现一年之后,Attention模型被提出了。该模型在产生输出的时候,会产生一个注意力范围来表示接下来输出的时候要重点关注输入序列的哪些部分,然后根据关注的区域来产生下一个输出,如此反复。
Attention 和人的一些行为特征有一定相似之处,人在看一段话的时候,通常只会重点注意具有信息量的词,而非全部词,即人会赋予每个词的注意力权重不同。attention 模型虽然增加了模型的训练难度,但提升了文本生成的效果。
Attention 需要保留 Encoder 每一个神经元的隐藏层向量 h,然后 Decoder 的第 t 个神经元要根据上一个神经元的隐藏层向量 h’t-1 计算出当前状态(指的的第t个)与 Encoder 每一个神经元的相关性 et。et 是一个 N 维的向量 (Encoder 神经元个数为 N),若 et 的第 i 维越大,则说明当前节点与 Encoder 第 i 个神经元的相关性越大。et 的计算方法有很多种,即相关性系数的计算函数 a 有很多种:
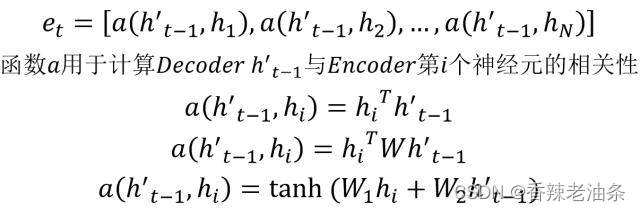
上面得到相关性向量 et 后,需要进行归一化,使用 softmax 归一化。然后用归一化后的系数融合 Encoder 的多个隐藏层向量得到 Decoder 当前神经元的上下文向量 ct:
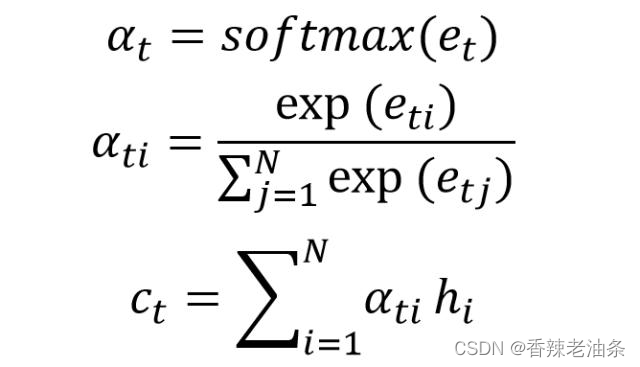
Seq-to-Seq模型从一开始在机器翻译领域被提出,到后来被广泛应用到NLP各个领域,原因就在于其对序列数据的完美使用,而且解决了以前RNN模型输出维度固定的难题,所以很快得到了推广。
4.主要参考:
- Seq2Seq 模型详解:
https://baijiahao.baidu.com/s?id=1650496167914890612&wfr=spider&for=pc - Attention机制详解:
https://zhuanlan.zhihu.com/p/47063917 - 机器翻译不可不知的Seq2Seq模型:
https://cloud.tencent.com/developer/article/1167621 - Seq2Seq中的Attention:
https://blog.youkuaiyun.com/qq_34372112/article/details/102810311


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









