#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
docx 模板渲染器(离线内存渲染)
- 读取 Excel → 字典
- 解压 docx → 对 word/*.xml 执行占位符替换(支持全角括号、零宽、数学粗体字母归一化)
- 回打包为新 docx
说明:此方法不调用 COM,不在原文档上就地修改,最大化保持格式与对象结构。
"""
import os
import re
import io
import zipfile
import xml.etree.ElementTree as ET
import openpyxl
from openpyxl.utils import range_boundaries
import unicodedata
from xml.sax.saxutils import escape
ZERO_WIDTH = "\u200b\u200c\u200d\u2060\ufeff"
def normalize_math_letters(text: str) -> str:
"""将常见数学粗体/变体字母映射为 ASCII,以便占位符匹配。
目前覆盖 U+1D400..U+1D419 (𝐀-𝐙) 与 U+1D41A..U+1D433 (𝐚-𝐳)。
如需扩展,可补充更多数学字母区段。
"""
if not text:
return text
result_chars = []
for ch in text:
code = ord(ch)
# Bold A-Z
if 0x1D400 <= code <= 0x1D419:
result_chars.append(chr(ord('A') + (code - 0x1D400)))
continue
# Bold a-z
if 0x1D41A <= code <= 0x1D433:
result_chars.append(chr(ord('a') + (code - 0x1D41A)))
continue
result_chars.append(ch)
return ''.join(result_chars)
def normalize_text_for_match(text: str) -> str:
if not text:
return text
# 全角花括号转半角
text = text.replace('{', '{').replace('}', '}')
# 去零宽
for ch in ZERO_WIDTH:
text = text.replace(ch, '')
# 数学粗体等 → ASCII
text = normalize_math_letters(text)
return text
def load_excel_placeholders(excel_path: str):
print(f"📊 读取 Excel: {excel_path}")
book = openpyxl.load_workbook(excel_path, data_only=True)
mapping = {}
for sheet_name in book.sheetnames:
sheet = book[sheet_name]
for row in range(1, sheet.max_row + 1):
for col in range(1, sheet.max_column + 1):
cell = sheet.cell(row=row, column=col)
if cell.value is None:
continue
cell_addr = f"{openpyxl.utils.get_column_letter(col)}{row}"
ph = f"{{{{{sheet_name}!{cell_addr}}}}}"
mapping[ph] = str(cell.value)
print(f"✅ Excel 数据装载完毕: {len(mapping)} 个键")
return mapping, book
def render_xml(xml_text: str, placeholder_to_value: dict) -> str:
"""在 XML 字符串中替换占位符。
策略:用正则抓取 {{...}},对花括号内做归一化后在映射表里查值,命中则替换整个 {{...}}。
备注:对于被标签拆断的占位符(极少数情况),此方法无法命中,后续如需可引入更细粒度的 XML 解析处理。
"""
if not xml_text:
return xml_text
# 为了匹配带全角/零宽/数学粗体的占位符,先对比时做归一化
# 但替换时仍用原始匹配片段的起止范围,保证不破坏其它 XML
placeholder_pattern = re.compile(r"\{\{[\s\S]*?\}\}")
def _repl(m: re.Match) -> str:
raw = m.group(0)
key_norm = normalize_text_for_match(raw)
# 归一化后的键若直接命中,替换
value = placeholder_to_value.get(key_norm)
if value is None:
# 有些键原本就是半角,尝试不归一化
value = placeholder_to_value.get(raw)
if value is None:
return raw
return escape(value)
# 构造一个“归一化过的键 → 值”的映射,提升命中率
normalized_map = {normalize_text_for_match(k): v for k, v in placeholder_to_value.items()}
# 将函数闭包携带的映射替换为归一化后的
return placeholder_pattern.sub(lambda m: _repl_with_map(m, normalized_map), xml_text)
def _repl_with_map(m: re.Match, normalized_map: dict) -> str:
raw = m.group(0)
key_norm = normalize_text_for_match(raw)
value = normalized_map.get(key_norm)
if value is None:
return raw
return escape(value)
def render_docx(template_docx: str, output_docx: str, data_map: dict, workbook):
# 需要处理的 XML 部件
targets = [
'word/document.xml',
# 页眉/页脚/脚注/批注等
# 将在遍历时用 startswith('word/header') 等方式捕获
]
# 预构建归一化映射
normalized_map = {normalize_text_for_match(k): v for k, v in data_map.items()}
with zipfile.ZipFile(template_docx, 'r') as zin:
with zipfile.ZipFile(output_docx, 'w', compression=zipfile.ZIP_DEFLATED) as zout:
for item in zin.infolist():
data = zin.read(item.filename)
if item.filename.endswith('.xml') and (
item.filename == 'word/document.xml' or
item.filename.startswith('word/header') or
item.filename.startswith('word/footer') or
item.filename in ('word/footnotes.xml', 'word/endnotes.xml', 'word/comments.xml', 'word/commentsExtended.xml')
):
try:
xml_text = data.decode('utf-8')
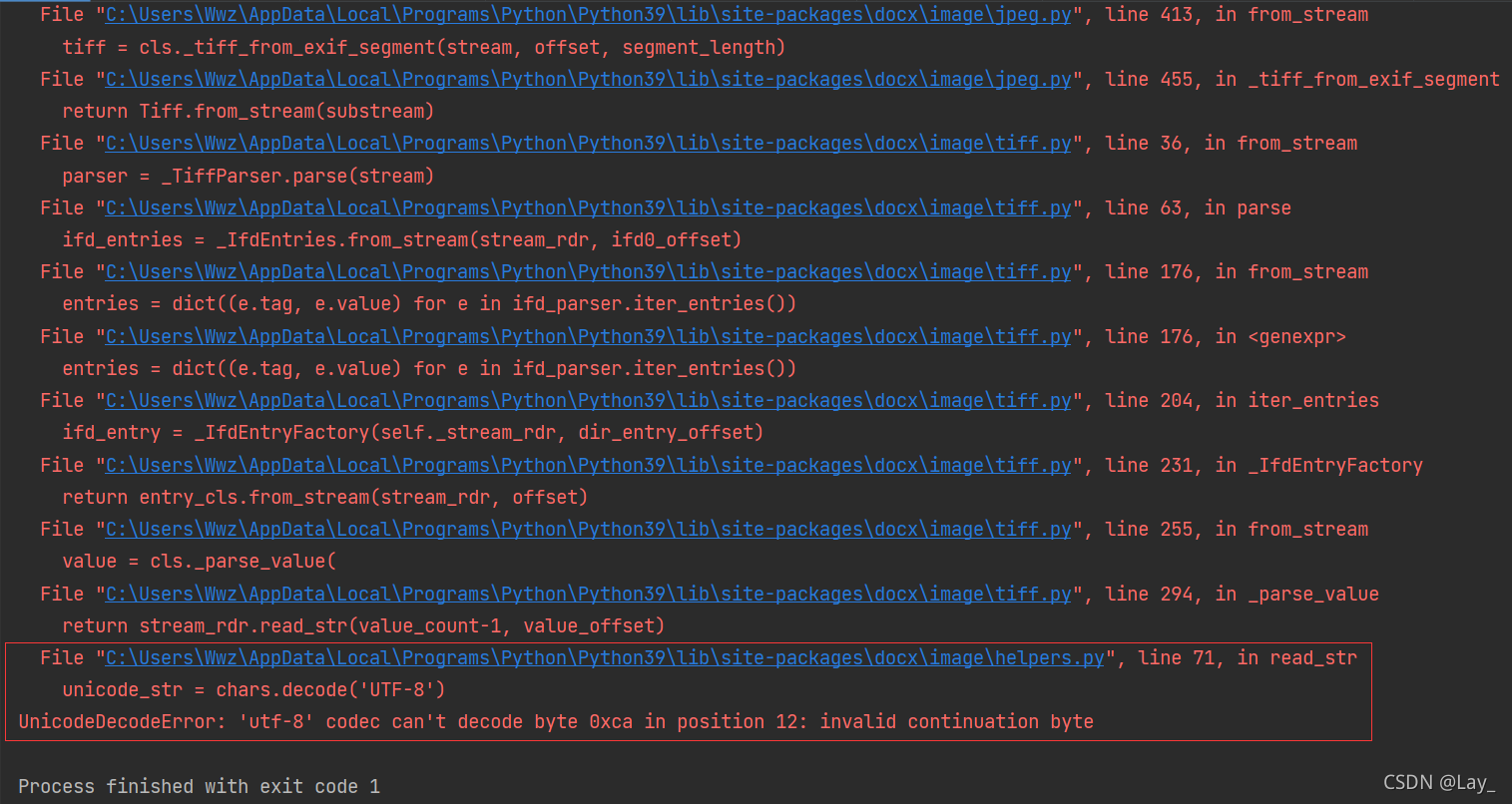
except UnicodeDecodeError:
# 尝试用 utf-8-sig 或 fallback
try:
xml_text = data.decode('utf-8-sig')
except Exception:
xml_text = data.decode('latin-1')
# 第一阶段:纯串级替换(覆盖未被拆分的占位符)
rendered = render_xml(xml_text, normalized_map)
# 第二阶段:结构化替换(跨 run/跨 m:t 的占位符)
try:
rendered = render_structured_xml(rendered, normalized_map, workbook)
except Exception:
pass
zout.writestr(item, rendered.encode('utf-8'))
else:
zout.writestr(item, data)
def render_structured_xml(xml_text: str, normalized_map: dict, workbook) -> str:
"""结构化替换:解析 XML,把分散在多个 w:t/m:t 的占位符也替换掉。
策略:
- 对每个段落 w:p、数学块 m:oMath/m:oMathPara,收集其下所有文本节点(w:t 与 m:t)
- 将这些文本拼接为 original 字符串,同时记录每个字符对应的(节点索引, 在节点内偏移)
- 构建 normalized 字符串及其到 original 的索引映射
- 在 normalized 字符串里用正则找 {{...}},命中后用映射到 original 范围,回写到节点文本中
仅修改文本内容,不增删节点结构,尽量保持版式。
"""
ns = {
'w': 'http://schemas.openxmlformats.org/wordprocessingml/2006/main',
'm': 'http://schemas.openxmlformats.org/officeDocument/2006/math',
}
def all_text_nodes(container: ET.Element):
for t in container.findall('.//w:t', ns):
yield t
for t in container.findall('.//m:t', ns):
yield t
def build_strings(nodes):
orig_chars = []
char_to_node = [] # 每个原始字符映射到(节点索引, 节内偏移)
for idx, n in enumerate(nodes):
s = n.text or ''
for off, ch in enumerate(s):
orig_chars.append(ch)
char_to_node.append((idx, off))
original = ''.join(orig_chars)
# 生成 normalized 及反向映射
norm_chars = []
norm_to_orig = []
for i, ch in enumerate(original):
ch_norm = normalize_math_letters(ch)
# 全角括号/零宽归一
if ch == '{':
ch_norm = '{'
elif ch == '}':
ch_norm = '}'
if ch in ZERO_WIDTH:
continue # 跳过,不映射
for j, c2 in enumerate(ch_norm):
norm_chars.append(c2)
norm_to_orig.append(i)
normalized = ''.join(norm_chars)
return original, normalized, char_to_node, norm_to_orig
def apply_replacement(nodes, char_to_node, start_orig, end_orig, value):
# 定位起止 (节点索引, 偏移)
if start_orig >= len(char_to_node) or end_orig == 0:
return
s_node, s_off = char_to_node[start_orig]
e_node, e_off = char_to_node[end_orig - 1]
# 左右残留
left = (nodes[s_node].text or '')[:s_off]
right = (nodes[e_node].text or '')[e_off + 1:]
# 置入 value
nodes[s_node].text = left + value
# 清空中间节点
for k in range(s_node + 1, e_node):
nodes[k].text = ''
# 处理右端节点
if e_node != s_node:
nodes[e_node].text = right
# 解析 XML
root = ET.fromstring(xml_text)
# 构建 parent 映射,便于节点替换
parent_map = {}
for p in root.iter():
for ch in list(p):
parent_map[ch] = p
# 处理的容器:段落与数学块
containers = []
containers.extend(root.findall('.//w:p', ns))
containers.extend(root.findall('.//m:oMath', ns))
containers.extend(root.findall('.//m:oMathPara', ns))
ph_regex = re.compile(r'\{\{[\s\S]*?\}\}')
table_regex = re.compile(r"\{\{表格::([^!]+)!([A-Za-z]+\d+):([A-Za-z]+\d+)\}\}")
def fetch_range(sheet_name: str, start: str, end: str):
try:
ws = workbook[sheet_name]
except KeyError:
return None
min_col, min_row, max_col, max_row = range_boundaries(f"{start}:{end}")
rows = []
for r in range(min_row, max_row + 1):
row_vals = []
for c in range(min_col, max_col + 1):
v = ws.cell(row=r, column=c).value
row_vals.append('' if v is None else str(v))
rows.append(row_vals)
return rows
def build_tbl(rows):
tbl = ET.Element(f"{{{ns['w']}}}tbl")
tblPr = ET.SubElement(tbl, f"{{{ns['w']}}}tblPr")
# 自动适应 & 边框
ET.SubElement(tblPr, f"{{{ns['w']}}}tblLayout", {f"{{{ns['w']}}}type": "autofit"})
borders = ET.SubElement(tblPr, f"{{{ns['w']}}}tblBorders")
for tag in ("top", "left", "bottom", "right", "insideH", "insideV"):
ET.SubElement(borders, f"{{{ns['w']}}}{tag}", {
f"{{{ns['w']}}}val": "single",
f"{{{ns['w']}}}sz": "4",
f"{{{ns['w']}}}color": "auto",
})
tr_elems = []
for row in rows:
tr = ET.SubElement(tbl, f"{{{ns['w']}}}tr")
tr_elems.append(tr)
for cell in row:
tc = ET.SubElement(tr, f"{{{ns['w']}}}tc")
tcPr = ET.SubElement(tc, f"{{{ns['w']}}}tcPr")
p = ET.SubElement(tc, f"{{{ns['w']}}}p")
r = ET.SubElement(p, f"{{{ns['w']}}}r")
t = ET.SubElement(r, f"{{{ns['w']}}}t")
t.text = cell
# 尝试将第一列的“逐字符竖排”合并为纵向合并
try:
first_col_vals = [ (rows[i][0] if rows[i] else '') for i in range(len(rows)) ]
non_empty = [v for v in first_col_vals if v]
if non_empty and all(len(v) <= 2 for v in non_empty) and sum(len(v) for v in non_empty) >= 3:
header_text = ''.join(v for v in first_col_vals).strip()
# 合理的标题字符集(英文字母/数字/括号/斜杠/单位等)
if re.fullmatch(r"[A-Za-z0-9_ /()·\-]+", header_text):
# vMerge across rows
# 在第一行第一列放完整文本,后续行设置 vMerge continue
for i, tr in enumerate(tr_elems):
tc = tr.find(f".//w:tc", ns)
if tc is None:
continue
tcPr = tc.find('w:tcPr', ns)
if tcPr is None:
tcPr = ET.SubElement(tc, f"{{{ns['w']}}}tcPr")
if i == 0:
ET.SubElement(tcPr, f"{{{ns['w']}}}vMerge", {f"{{{ns['w']}}}val": "restart"})
# 写入合并后的文本
p = tc.find('w:p', ns)
if p is None:
p = ET.SubElement(tc, f"{{{ns['w']}}}p")
# 清空原内容
for child in list(p):
p.remove(child)
r = ET.SubElement(p, f"{{{ns['w']}}}r")
t = ET.SubElement(r, f"{{{ns['w']}}}t")
t.text = header_text
else:
ET.SubElement(tcPr, f"{{{ns['w']}}}vMerge", {f"{{{ns['w']}}}val": "continue"})
# 清空内容
p = tc.find('w:p', ns)
if p is not None:
for child in list(p):
p.remove(child)
except Exception:
pass
return tbl
for c in containers:
nodes = list(all_text_nodes(c))
if not nodes:
continue
original, normalized, char_to_node, norm_to_orig = build_strings(nodes)
# 若整段文本就是一个“表格::sheet!A1:B2”占位符,则替换整个段落为 w:tbl
only = normalize_text_for_match(original).strip()
m_table = table_regex.fullmatch(only)
if m_table:
sheet, start, end = m_table.groups()
range_rows = fetch_range(sheet, start, end)
if range_rows:
parent = parent_map.get(c)
if parent is not None:
idx = list(parent).index(c)
parent.remove(c)
parent.insert(idx, build_tbl(range_rows))
continue
# 在 normalized 中寻找占位符
changes = []
for m in ph_regex.finditer(normalized):
ph_norm = m.group(0)
if ph_norm in normalized_map:
val = normalized_map[ph_norm]
else:
continue
# 映射到 original 范围
s_norm = m.start()
e_norm = m.end()
s_orig = norm_to_orig[s_norm]
e_orig = norm_to_orig[e_norm - 1] + 1
changes.append((s_orig, e_orig, val))
# 倒序应用避免索引漂移
for s_orig, e_orig, val in reversed(changes):
apply_replacement(nodes, char_to_node, s_orig, e_orig, val)
# 输出 XML
return ET.tostring(root, encoding='utf-8').decode('utf-8')
def main():
excel_path = r"C:\Users\seatone\Desktop\PythonStudy\20250822\66.xlsx"
template_docx = r"C:\Users\seatone\Desktop\PythonStudy\20250822\66.docx"
# 若目标文件被占用,改用时间戳避免占用冲突
import time
output_docx = rf"C:\Users\seatone\Desktop\PythonStudy\20250822\66_模板渲染版_{int(time.time())}.docx"
data_map, workbook = load_excel_placeholders(excel_path)
print("🚀 开始渲染模板为新文档…")
render_docx(template_docx, output_docx, data_map, workbook)
print(f"✅ 已生成: {output_docx}")
if __name__ == '__main__':
main()
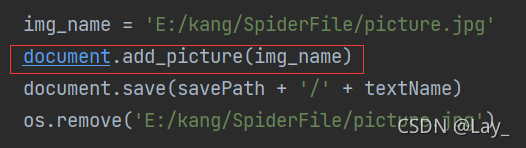
上述代码可以根据图片中的大小设大小吗?现在生册的excel表格太大了
最新发布





















 3876
3876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









