



 本文介绍了使用Hive进行月小费统计和关键路径转化率分析。通过级联求和计算每个用户每月小费总额,并探讨了如何计算转化率,包括每步转化人数和漏出率。同时,提到了数据导出和工作流调度在Hadoop环境中的应用。
本文介绍了使用Hive进行月小费统计和关键路径转化率分析。通过级联求和计算每个用户每月小费总额,并探讨了如何计算转化率,包括每步转化人数和漏出率。同时,提到了数据导出和工作流调度在Hadoop环境中的应用。
文章目录
hive级联求和
每月小费统计
数据如下
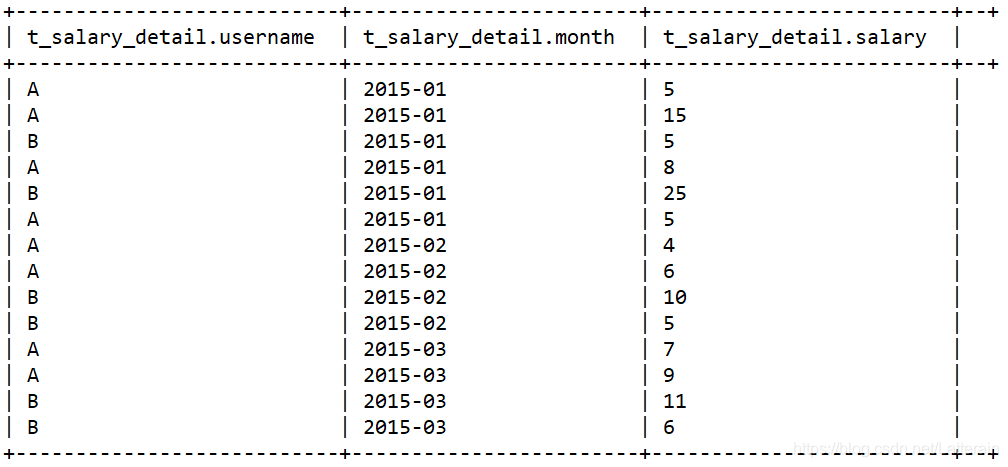
需求:统计每个用户每个月总共获得多少小费
select username,month,sum(salary) from t_salary_detail group by username,month;
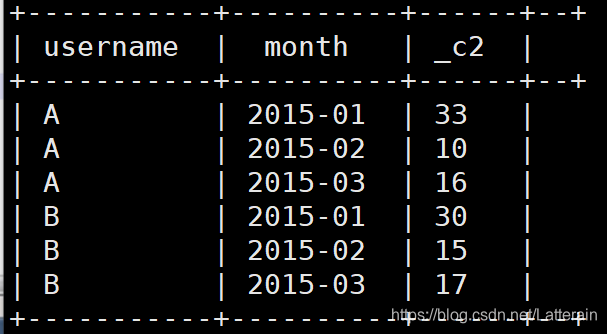
需求:统计每个用户累计小费
累计求和使用inner join自己连接自己实现。
设置后关联的表的月份小于等于前面的表
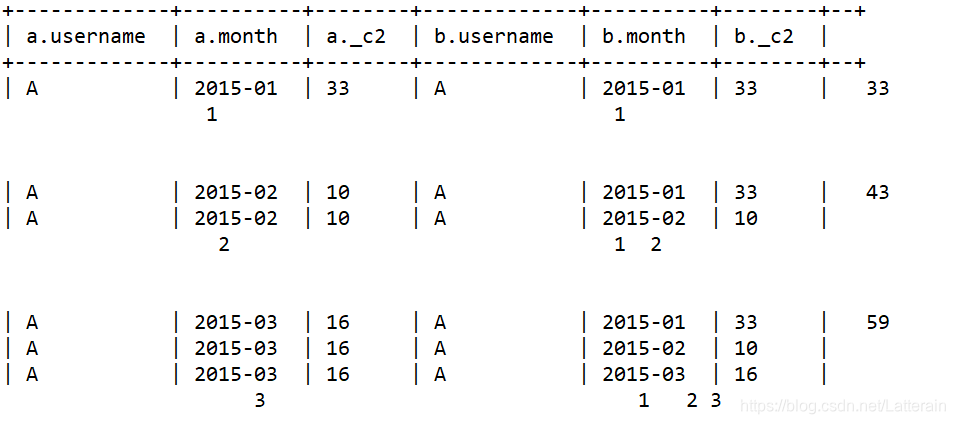
select
A.username,A.month,max(A.salSum),sum(B.salSum) as accumulate
from
(select t.month,t.username,sum(salary) as salSum from t_salary_detail t group by t.username,t.month) A
inner join
(select t.month,t.username,sum(salary) as salSum from t_salary_detail t group by t.username,t.month) B
on A.username = B.username
where B.month <= A.month
group by A.username,A.month
order by A.username,A.month;
关键路径转化率分析
求两个指标:
- 每一步相对于第一步的转化率
- 每一步相对于上一步的转化率
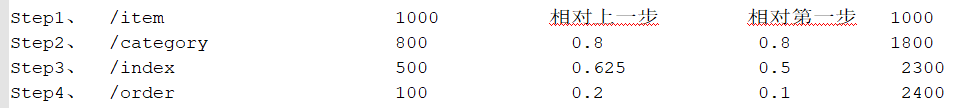
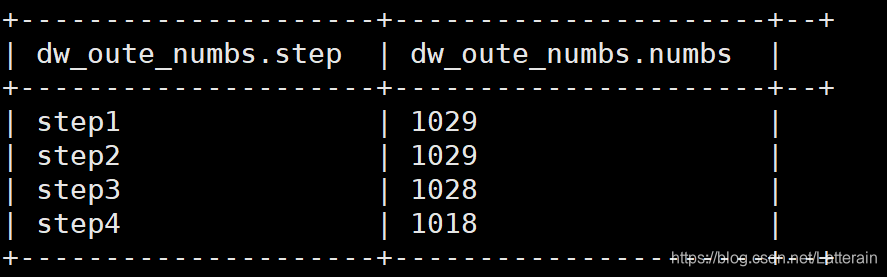
需求:查询每一个步骤的总访问人数
create table dw_oute_numbs as
select 'step1' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920'
and request like '/item%'
union all
select 'step2' as step,count(distinct remote_addr) as numbs from ods_click_pageviews
where datestr='20130920'
and request like '/category%'
union all
select 'step3' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920'
and request like '/order%'
union all
select 'step4' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20130920'
and request like '/index%';
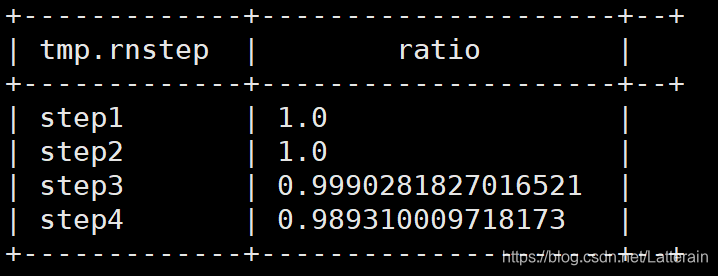
需求:查询每一步骤相对于路径起点人数的比例
采用级联求和
方法:
不带任何条件inner join,产生笛卡儿积。
观察结果后发现可以过滤只取第一步的所有数据。
每一步的人数/第一步的人数==每一步相对起点人数比例
笛卡儿积后的结果

select tmp.rnstep,tmp.rnnumbs/tmp.rrnumbs as ratio
from(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where tmp.rrstep='step1';
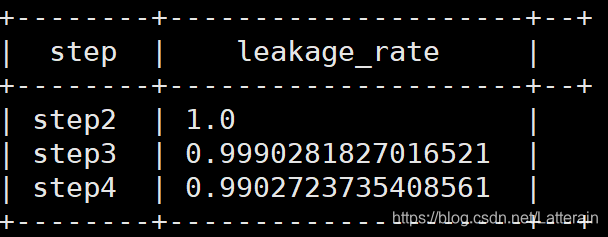
需求:查询每一步骤相对于上一步骤的漏出率
从上一步产生的笛卡儿积结果观察,通过字段截取step,转为int格式后,添加过滤,表1等于表2减1。
这里可以用cast
cast为hive的内置函数,主要用于类型的转换
例:
select cast(1 as float);
select cast(‘2018-06-22’ as date);
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as leakage_rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
from dw_oute_numbs rn
inner join
dw_oute_numbs rr
) tmp
where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1;
数据导出
sqoop
/export/servers/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect jdbc:mysql://192.168.163.26:3306/weblog --username root --password admin --m 1 --export-dir /user/hive/warehouse/weblog.db/dw_pvs_everyday --table dw_pvs_everyday --input-fields-terminated-by '\001'
/export/servers/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect jdbc:mysql://192.168.163.26:3306/weblog --username root --password admin --m 1 --export-dir /user/hive/warehouse/weblog.db/dw_pvs_everyhour_oneday/datestr=20130918 --table dw_pvs_everyhour_oneday --input-fields-terminated-by '\001'
/export/servers/sqoop-1.4.6-cdh5.14.0/bin/sqoop export --connect jdbc:mysql://192.168.163.26:3306/weblog --username root --password admin --m 1 --export-dir /user/hive/warehouse/weblog.db/dw_pvs_referer_everyhour/datestr=20130918 --table dw_pvs_referer_everyhour --input-fields-terminated-by '\001'
工作流调度
将综合案例123中实现的模块串起来,定时的执行。
- flume数据的采集:flume一直在采集,不需要定时的执行
- 表模型三个mr的程序
第一个:mr清洗数据
第二个:pageView表模型
第三个:visit表模型 - hive建表加载数据
每天产生的数据,都要定时的加载到hive的对应的分区表里面去 - 数据的分析的hql语句
自己开发的hql语句写到脚本里面定时的执行 - 数据的导出
sqoop数据的导出也需要定时执行

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









