



 本文详细介绍了Hadoop MapReduce中的MapTask和ReduceTask的工作流程,包括MapTask的切片、数据读取、排序与合并,以及ReduceTask的复制、合并和排序阶段。此外,还探讨了MapReduce的shuffle过程和Snappy压缩。针对数据JOIN操作,文章对比了Reduce端和Map端的join算法,讨论了各自的优缺点和适用场景。
本文详细介绍了Hadoop MapReduce中的MapTask和ReduceTask的工作流程,包括MapTask的切片、数据读取、排序与合并,以及ReduceTask的复制、合并和排序阶段。此外,还探讨了MapReduce的shuffle过程和Snappy压缩。针对数据JOIN操作,文章对比了Reduce端和Map端的join算法,讨论了各自的优缺点和适用场景。
mapreduce
MapTask
maptask的并行度: 是指代有多少个maptask的任务
FileInputFormat 里面有一个方法: getSplits
这个方法返回的就是我们一个文件,有多少个切片,一个切片对应我们一个maptask的任务

获取文件的切片的几个参数控制:
mapred.min.split.size 没有配置的话默认值是1
mapred.max.split.size 没有配置的话默认值是 Long.MAX_VALUE
如果没有配置上面这两个参数,我们文件的切片大小就是128M,与我们的block块相等。
- 1Kb的一个文件 一个block块 一个切片 1个maptaks
- 300M的一个文件 三个block块 三个切片 3个maptask
一般maptask的个数就是与我们block块的大小有关系

步骤:
- 首先,读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,有多少个split就对应启动多少个MapTask。split与block的对应关系默认是一对一。
- 将输入文件切分为splits之后,由RecordReader对象(默认LineRecordReader)进行读取,以\n作为分隔符,读取一行数据,返回<key,value>。Key表示每行首字符偏移值,value表示这一行文本内容。
- 读取split返回<key,value>,进入用户自己继承的Mapper类中,执行用户重写的map函数。RecordReader读取一行这里调用一次。
- map逻辑完之后,将map的每条结果通过context.write进行collect数据收集。在collect中,会先对其进行分区处理,默认使用HashPartitioner。
- 将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
- 当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
- 合并溢写文件:每次溢写会在磁盘上生成一个临时文件(写之前判断是否有combiner),如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量。
环形缓冲区的大小
涉及到我们maptask的调优的过程,如果内存充足**,可以将换型缓冲区的大小稍微调大,避免我们大量的小文件需要合并**
mapTask基础设置配置
设置一:设置环型缓冲区的内存值大小(默认设置如下)
mapreduce.task.io.sort.mb 100
设置二:设置溢写百分比(默认设置如下)
mapreduce.map.sort.spill.percent 0.80
设置三:设置溢写数据目录(默认设置)
mapreduce.cluster.local.dir ${hadoop.tmp.dir}/mapred/local
设置四:设置一次最多合并多少个溢写文件(默认设置如下)
mapreduce.task.io.sort.factor 10
ReduceTask
reducetask的个数:job.setNumReduceTasks(5)
Reduce大致分为copy、sort、reduce三个阶段:
- Copy阶段,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件。
- Merge阶段。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。merge有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件。
- 合并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
- 对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
MapReduce shuffle过程

1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等。
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
Snappy压缩
Main类增加 configuration 配置,修改后如下:
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//开启map阶段数据压缩
configuration.set("mapreduce.map.output.compress","true");
configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
//开启reduce阶段数据压缩
configuration.set("mapreduce.output.fileoutputformat.compress","true");
configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
//int run = ToolRunner.run(new Configuration(), new FlowNumSortMain(), args);
int run = ToolRunner.run(configuration, new FlowNumSortMain(), args);
System.exit(run);
}
join算法
Reduce端join
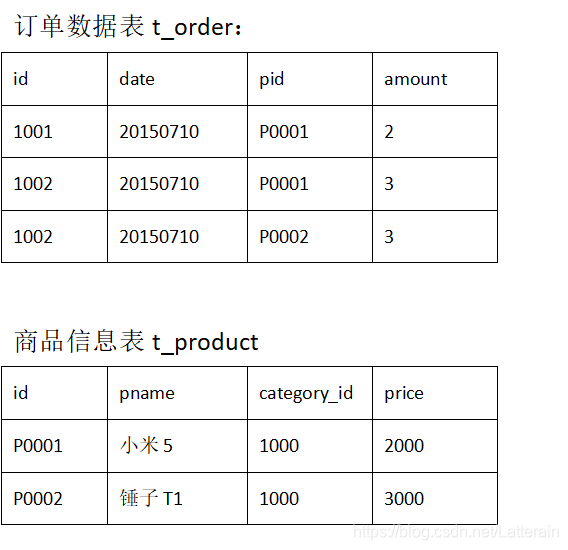
用mapreduce程序来实现一下SQL查询运算:
select a.id,a.date,b.name,b.category_id,b.price
from t_order a join t_product b
on a.pid = b.id
要求:
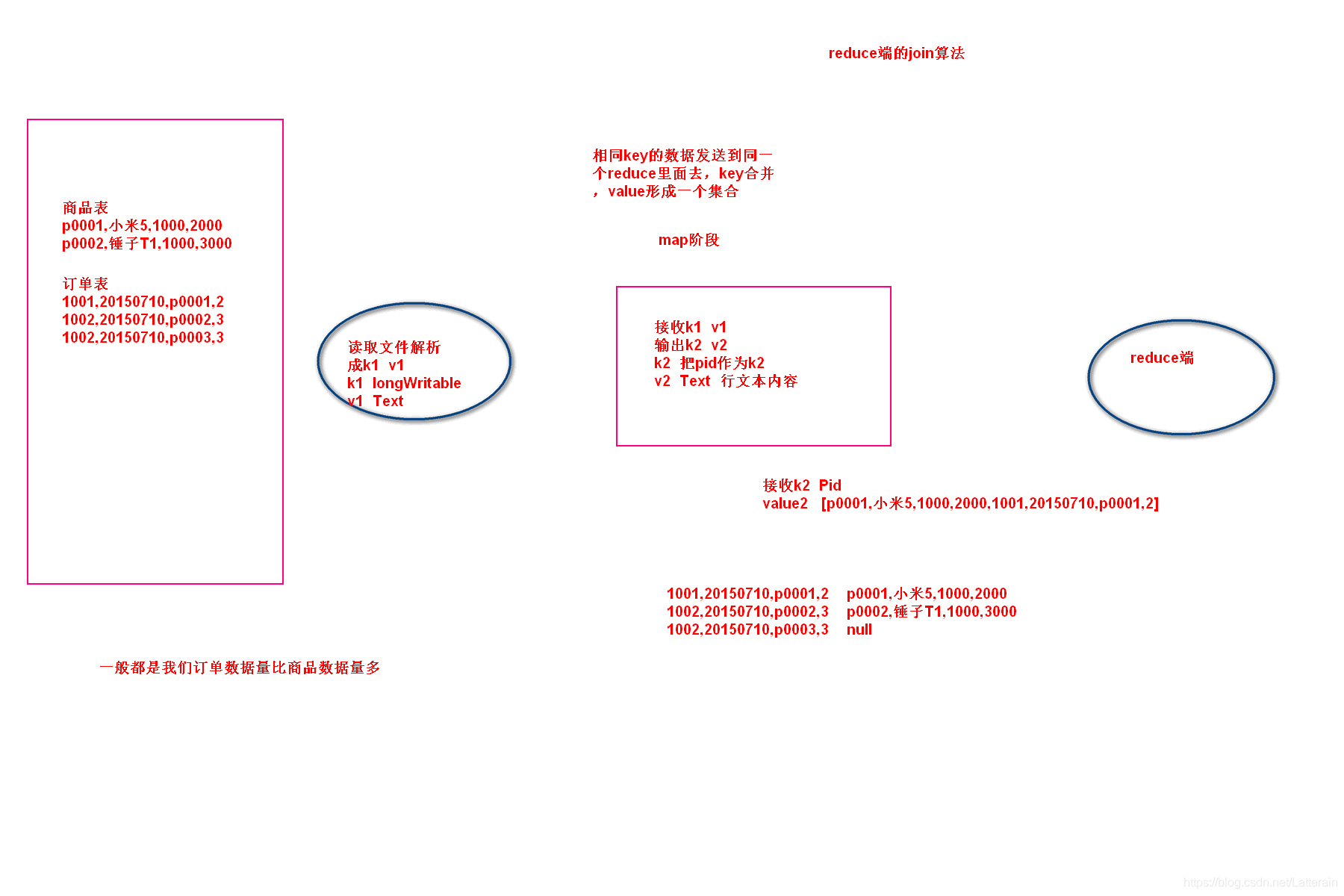
最后数据出来是这样的格式
1001,20150710,p0001,2 p0001,小米5,1000,2000
1002,20150710,p0002,3 p0002,锤子T1,1000,3000
1002,20150710,p0003,3 null
关键点:
将相同的producetId发送到同一个reduce里面去,形成一个集合
以productId作为我们key2
Map端join

reduce端join算法弊端:
reduce设置太少,数据处理太慢
reduce设置太多,集群资源浪费严重
将cache文件放入集群:
cd /export/
hdfs dfs -mkdir -p /cachefile
上传pdts.txt文件
hdfs dfs -put pdts.txt /cachefile
cache file:
p0001,xiaomi,1000,2
p0002,appale,1000,3
p0003,samsung,1000,4
Input: order.txt
1001,20150710,p0001,2
1002,20150710,p0002,3
1002,20150710,p0003,3
Mapper
package cn.nina.mr.demo6;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
//在程序主类运行方法里加了缓存文件,这里可以获取缓存文件
Map<String,String> map = null;
//重写setup方法获取缓存文件,将缓存文件内容存储到map当中去
@Override
protected void setup(Context context) throws IOException, InterruptedException {
map = new HashMap<String,String>();
//从context中获取configuration
Configuration configuration = context.getConfiguration();
//只有一个缓存文件,所以可以直接取第一个
URI[] cacheFiles = DistributedCache.getCacheFiles(configuration);
URI cacheFile = cacheFiles[0];
//获取文件系统
FileSystem fileSystem = FileSystem.get(cacheFile, configuration);
//获取文件输入流,如何将流转换成字符串
FSDataInputStream open = fileSystem.open(new Path(cacheFile));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(open));
String line = null;
while ((line = bufferedReader.readLine()) != null){
String[] lineArray = line.split(",");
map.put(lineArray[0],line);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
//获取到商品表数据
String product = map.get(split[2]);
//将商品表和订单表进行拼接
context.write(new Text(value.toString()+"\t"+product),NullWritable.get());
}
}
Main
package cn.nina.mr.demo6;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import sun.net.TelnetInputStream;
import java.net.URI;
public class MapJoinMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Configuration conf = super.getConf();
//添加缓存文件
DistributedCache.addCacheFile(new URI("hdfs://node01:8020/cachefile/pdts.txt"),conf);
Job job = Job.getInstance(conf, "mapJoin");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\Yichun\\Desktop\\hadoop\\hadoop_04\\map端join\\map_join_iput"));
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\Yichun\\Desktop\\hadoop\\hadoop_04\\map端join\\map_join_oput"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new MapJoinMain(), args);
System.exit(run);
}
}

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









