



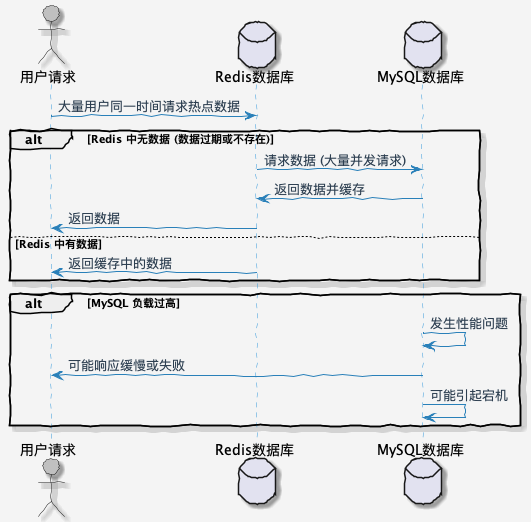
什么是缓存击穿?
缓存击穿指在高并发的系统中,**一个热点数据缓存过期或者在缓存中不存在**,导致大量并发请求直接访问数据库,从而给数据库造成巨大压力,甚至可能引起宕机。具体来说,当某个热点数据在缓存中过期时,如果此时有大量并发请求同时访问这个数据,由于缓存中不存在,所有请求都会直接访问数据库,导致数据库负载急剧增加。
缓存击穿解决方案
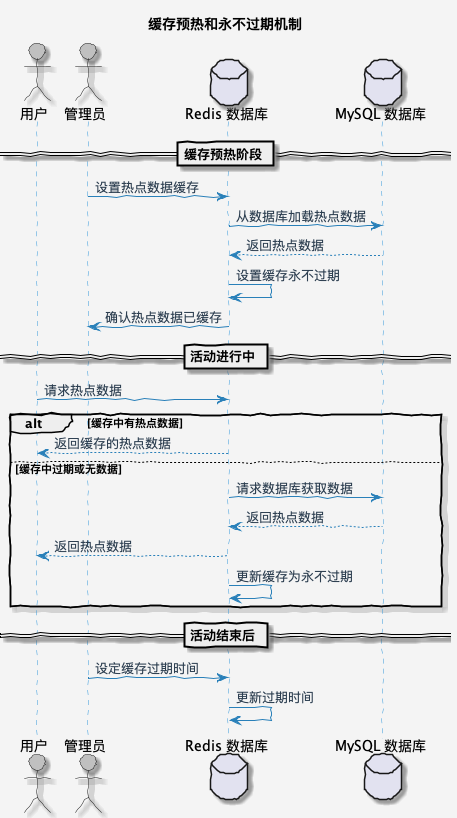
1. 预热和缓存永不过期
一般来说,我们会通过预热和缓存永不过期的机制让缓存不击穿,这样即使再大的流量也可以通过缓存去抗。- 缓存预热:热点数据预加载,指的是在活动或者大促开始前,针对已知的热点数据从数据库加载到缓存中,这样可以避免海量请求第一次访问热点数据需要从数据库读取的流程。
- 永不过期:热点数据永不过期,指的就是可以预知的热点数据,在活动开始前,设置过期时间为 -1。这样的话,就不会有缓存击穿的风险。
上面两个一般都是搭配一起使用的。等对应热点缓存的活动结束后,这些数据访问量就比较低了,可以通过后台任务的方案对指定缓存设置过期时间,这样可以有效降低 Redis 存储压力。
2. 分布式锁之双重判定锁
分布式锁的解决方案就是保证**只有一个请求可以访问数据库,其它请求等待结果**。这样可以避免大量的请求同时访问数据库。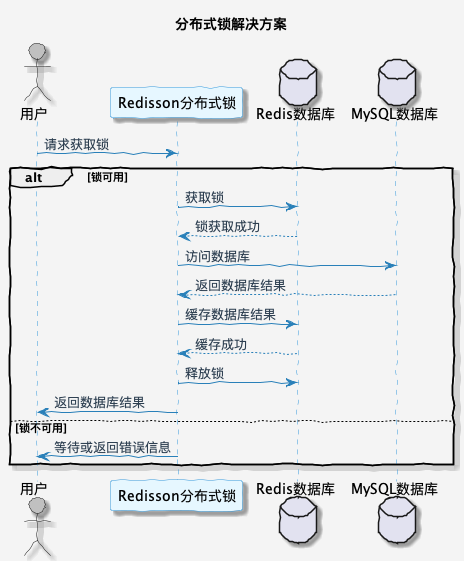
但是这种的话有一个弊端,那就是获取分布式锁的请求,都会执行一遍查询数据库,并更新到缓存。理论上只有第一个加载数据库记录请求是有效的。
针对这个问题,可以通过双重判定锁的形式,在获取到分布式锁之后,再次查询一次缓存是否存在。如果缓存中存在数据,就直接返回;如果不存在,才继续执行查询数据库的操作。这样就可以避免大量请求访问数据库。
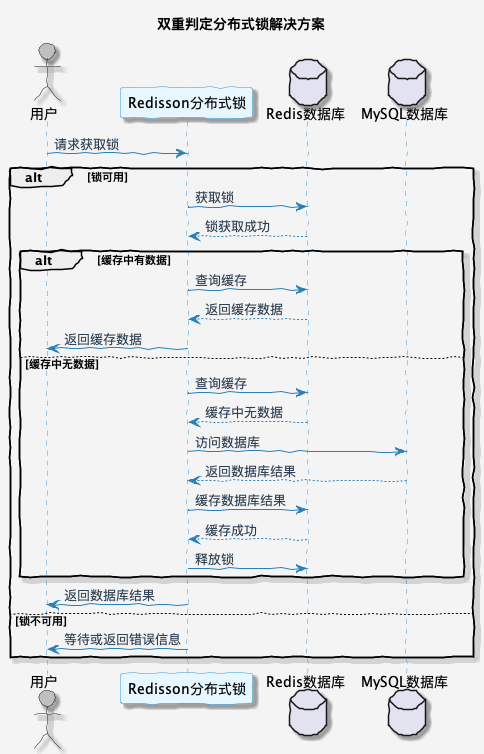
下面是这种场景下解决方案的一般步骤:
- 1.获取锁:在查询数据库前,首先尝试获取一个分布式锁。只有一个线程能够成功获取锁,其他线程需要等待;
- 2.查询数据库:如果双重判断确认数据确实不存在于缓存中,那么就执行查询数据库的操作,获取数据;
- 3.写入缓存:获取到数据后,将数据写入缓存,并设置一个合适的过期时间,以防止缓存永远不会被更新;
- 4.释放锁:最后,释放获取的锁,以便其他线程可以继续使用这个锁。
3. 高并发极端情况
很多同学认为到这里就结束了,但这恰恰只是开始,真正难得是接下来要讲的。我举个场景,有一万个请求同一时间访问触发了缓存击穿,如果用双重判定锁,逻辑是这样的:
- 1.第一个请求加锁、查询缓存是否存在、查询数据库、放入缓存、解锁,假设我们用了50毫秒;
- 2.第二个请求拿到锁查询缓存、解锁用了1毫秒;
- 3.那最后一个请求需要等待10049毫秒后才能返回,用户等待时间过长,极端情况下可能会触发应用的内存溢出。
3.1 尝试获取锁 tryLock
像上面这种场景,类似于秒杀的架构,我们要做的就是不让用户请求在服务端阻塞过长时间。那就可以使用尝试获取锁 `tryLock` API,它的语义是如果拿锁失败直接返回,而不是阻塞等待直到获取锁。通过这种方式我们可以快速失败,告诉用户网络异常请稍后再试,等用户再尝试刷新的时候,其实获取锁的线程已经把数据放到了缓存。
因为这种方案对用户操作体验不友好,所以也只是适用于部分场景。在实际开发中,需要灵活变更。
3.2 分布式锁分片
还有一种比较优雅的解决方案是通过分布式锁分片的形式,让并行的线程更多一些。因为同一时间有多个线程能同时操作,所以理论上,设置分片量的多少,也就是性能提升了近多少倍。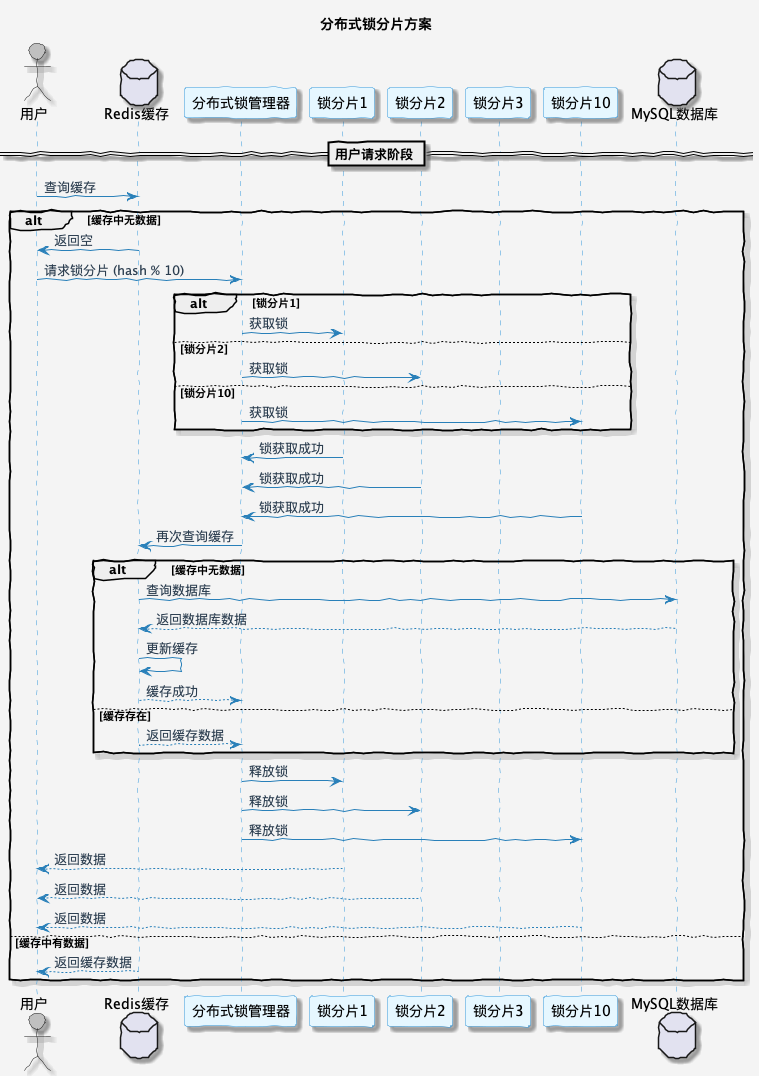

















 3663
3663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









