



 本文深入解析正则表达式的基础与高级用法,包括元字符、工具应用场景和示例。同时,详细介绍了sed和awk这两种强大的文本处理工具,涵盖其格式、返回值、常见命令和实战案例,帮助读者掌握高效文本处理技巧。
本文深入解析正则表达式的基础与高级用法,包括元字符、工具应用场景和示例。同时,详细介绍了sed和awk这两种强大的文本处理工具,涵盖其格式、返回值、常见命令和实战案例,帮助读者掌握高效文本处理技巧。
正则表达式
名词解释
正则表达式(regular expression, RE)是一种字符模式,
用于在查找过程中匹配指定的字符。
在大多数程序里,正则表达式都被置于两个正斜杠之间;
例如/l[oO]ve/就是由正斜杠界定的正则表达式,
它将匹配被查找的行中任何位置出现的相同模式。
在正则表达式中,元字符是最重要的概念。
工具
被vim、sed、awk、grep调用
场景
mysql、oracle、php、python ,Apache,Nginx... 需要正则
示例
需求
匹配数字的脚本:用户输入创建账号的数量
语法
[[ ^[0-9]+$ ]]
示范
read -p "输入数字才退出: " num
while :
do
if [[ ! $num =~ ^[0-9]+$ ]];then
echo "error enter!"
read -p "输入数字才退出:" num
else
echo "thank you"
exit 1
fi
done


元字符
定义
元字符是这样一类字符,它们表达的是不同于字面本身的含义
分类
基本正则表达式元字符
^
行首定位符
❌[root@localhost ~]# grep “root” /etc/passwd
root: x :0:0:root:/root:/bin/bash
operator: x :11:0:operator:/root:/sbin/nologin
[root@localhost ~]# grep “^root” /etc/passwd
为什么什么少一行?
root: x :0:0:root:/root:/bin/bash
[^]
匹配不在指定组内的字符
[^a-z0-9]ove //////取反
❌[root@localhost~]# cat 1.txt
love
1ove
|ove
[root@localhost~]# grep [0-9a-Z]ove 1.txt
love
1ove
[root@localhost ~]# grep [^0-9a-Z]ove 1.txt
|ove
$
行尾定位符
❌[root@mycat ~]# grep “gin$” passwd
mail: x :8:12:mail:/var/spool/mail:/sbin/nologin
.
匹配任意单个字符
❌[root@localhost ~]# grep abc 1.txt
abc
[root@localhost ~]# grep adc 1.txt
adc
[root@localhost ~]# grep a.c 1.txt
abc
adc
*
匹配前导符0到多次
❌[root@localhost ~]# cat 1.txt
a
ab
abc
abcd
abcde
abcdef
ggg
hhh
iii
[root@localhost ~]# grep “abc*” 1.txt
ab
abc
abcd
abcde
abcdef
[root@localhost ~]# grep “abcd*” 1.txt
abc
abcd
abcde
abcdef
.*
任意多个字符
❌[root@localhost ~]# grep ".* " 1.txt
a
ab
abc
abcd
abcde
abcdef
ggg
hhh
iii
为什么*.不好使?
[ ]
匹配指定范围内的一个字符
❌[lL]ove
搜索love不论大小写
[ - ]
匹配指定范围内的一个字符,连续的范围
❌[a-z0-9]ove //////[a-Z]=[a-zA-Z]
\
用来转义元字符 ('' "" \),脱意符
❌[root@localhost ~]# grep “l.” 1.txt
love
l.ve
[root@localhost ~]# grep “l.” 1.txt
l.ve
\<
词首定位符
❌[root@localhost ~]# grep “love” 1.txt
love
iloveyou
[root@localhost ~]# grep “\ <love” 1.txt
love
\ >
词尾定位符
love>
()
\(..\)
匹配稍后使用的字符的标签
❌:% s/172.16.130.1/172.16.130.5/
:% s/(172.16.130.)1/\15/
:% s/(172.)(16.)(130.)1/\1\2\35/
:3,9 s/(.*)/#\1/ 加注释
x\{m\}
字符x重复出现m次
❌[root@localhost ~]# grep o 1.txt
love
loove
looove
[root@localhost ~]# grep “o{3}” 1.txt
looove
x\{m,\}
字符x重复出现m次以上
o\{5,\}
❌
x\{m,n\}
字符x重复出现m到n次
o\{5,10\}
[root@localhost ~]# egrep “o{4,5}” 1.txt
oooo
ooooo
ioooo
ooooi
iooooi
[root@localhost ~]# egrep “o{5,5}” 1.txt
ooooo
扩展正则表达式元字符
egrep
+
匹配1~n个前导字符
[root@localhost ~]# cat 1.txt
lve
love
loove
[root@localhost ~]# egrep lo+ve 1.txt
love
loove
?
匹配0~1个前导字符
lo?ve :?前面的o 有还是没有,都行!
[root@localhost ~]# egrep lo?ve tom.sh
love
lve
a|b
匹配a或b
[root@localhost ~]# egrep “o|v” 1.txt
lve
1ove
loove
looove
loeve
love
Love
iloveyou
l.ve
o
oo
ooo
oooo
ooooo
ioooo
ooooi
iooooi
()
组字符
[root@localhost ~]# egrep “loveable|rs” 1.txt
rs
loveable
lovers
[root@localhost ~]# egrep “love(able|rs)” 1.txt
loveable
lovers
示例1
grep love 1.txt
找love
/^love/
以love开头
/love$/
以love结尾
/l.ve/
l开始,一个任意字符,ve结尾
/lo*ve/
l开始,零个或多个o,ve结尾
/[Ll]ove/
大L 或者小L 开头的 ove
/love[a-z]/
love最后一个小写字母
/love[^a-zA-Z0-9]/
love最后一个(不是字母或者数字),而是符号
[root@localhost ~]# egrep "love[^a-zA-Z0-9]" 1.txt
love,
love?
grep
目的
过滤,查找文档中的内容
分类
grep
略
egrep
扩展支持正则
\w 所有字母与数字,称为字符[a-zA-Z0-9]
'l[a-zA-Z0-9]*ve' === 'l\w*ve'
\W 所有字母与数字之外的字符,称为非字符
'love[^a-zA-Z0-9]+' === 'love\W+'
\b 词边界
'\<love\>' === '\blove\b'
fgrep
就不支持正则
[root@localhost ~]# fgrep . 1.txt
l.ve
返回值
0 是找到了
表示成功;
1 是没有
表示在所提供的文件无法找到匹配的pattern
2 找到地儿不对
示范
# grep 'root' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
# echo $?
0
# grep 'root1' /etc/passwd #用户root1并不存在
# echo $?
1
grep 'root' /etc/passwd1 #这里的/etc/passwd1文件并不存在
#grep: /etc/passwd1: No such file or directory
#echo $?
2
参数
grep -q 静默
结果不显示在屏幕上,可通过返回值了解
grep -v 去反
grep -R 可以查目录下面的文件
默认只能查找文件
grep -o 只找到这个关键字就可以
[root@localhost ~]# grep “a” 1.txt
5.a
5.aaa
a
ab
ldfadasfsdave
[root@localhost ~]# grep -o “a” 1.txt
a
a
a
a
a
grep -B2前两行
grep -A2后两行
grep -C2上下两行
egrep -l 只要文件名
[root@localhost ~]# egrep -l ‘root’ /etc/passwd
/etc/passwd
egrep -n 带行号
[root@localhost ~]# egrep -n ‘xulei’ /etc/passwd
43:xulei: x :1000:1000::/home/xulei:/bin/bash
示例
# egrep 'NW' datafile
在datafile文件中,找NW
# egrep 'NW' d*
找NW,文件只要是d开头就可以
# egrep '^n' datafile
以n开头的
# egrep '4$' datafile
4结尾
# egrep TB Savage datafile
找TB,在savage里找,在datafile里找
# egrep 'TB Savage' datafile
找TB Savage
# egrep '5\..' datafile
找五点后面是一个任意字符
# egrep '\.5' datafile
找点五
# egrep '\<north\>' datafile
就找这个词
# egrep '\<[a-r].*n\>' datafile
a或r开头,中间任意,n结尾
# egrep '^n\w*\W' datafile
n开头,多个字母,结尾一个非字母
# egrep '\bnorth\b' datafile
就找north
# egrep 'NW|EA' datafile
NW或者EA
# egrep '3+' datafile
1个或多个3
# egrep '2\.?[0-9]' datafile
2开头,0个或1个点,一个数字
# egrep '(no)+' datafile
一个或多个no
# egrep 'S(h|u)' datafile
sh或su
# egrep 'Sh|u' datafile
sh或者u
sed
前言
Stream EDitor:流编辑
sed 是一种在线的、非交互式的编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。
接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输 出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;
文本文件->“模式空间”(pattern space)->屏幕
逐行处理
内容未变
编辑文件
格式
1 sed 选项 命令 文件
sed [options] 'command' file(s)
2 sed 选项 –f 脚本 文件
sed [options] -f scriptfile file(s)
返回值
都是0,对错不管。
只有当命令存在语法错误时,sed的退出状态才是非0
sed和正则表达式
与grep一样,sed在文件中查找模式时也可以使用正则表达式(RE)和各种元字符。
正则表达式是括在斜杠间的模式,用于查找和替换,以下是sed支持的元字符。
使用基本元字符集 ^, $, ., *, [], [^], \< \>,\(\),\{\}
使用扩展元字符集 ?, +, |, ( )
使用扩展元字符的方式:
\+ 转义
sed -r 加-r
汇总示例
删除命令: d
#sed -r ‘/root/d’ passwd
删除带root的行
#sed -r ‘3d’ passwd
#sed -r ‘3{d}’ passwd
删除第三行
#sed -r ‘3{d;}’ passwd
{存放sed的多个命令} 3{h;d},h暂存空间
#sed -r ‘3,$d’ passwd
删除3到最后一行之间的内容
#sed -r ‘$d’ passwd
删除最后一行内容
替换命令: s
sed -r ‘s/root/aofa/’ passwd
sed -r ‘s/^root/aofa/’ passwd
sed -r ‘s/root/aofa/g’ passwd



sed -r ‘s/[0-9][0-9]$/&.5/’ passwd
查找双数 结尾的词组
&:替换成 双数.5
&有查询结果的含义。

#sed -r ‘s/(mail)/E\1/g’ passwd
()括号组合字符,\1调用括号
[root@localhost ~]# sed -r ‘s/(mail)/E\1/g’ passwd
Email: x :8:12:Email:/var/spool/Email:/sbin/nologin9
sed -r ‘s#(mail)#E\1#g’ passwd
分隔符可以换成井号
读文件命令:r
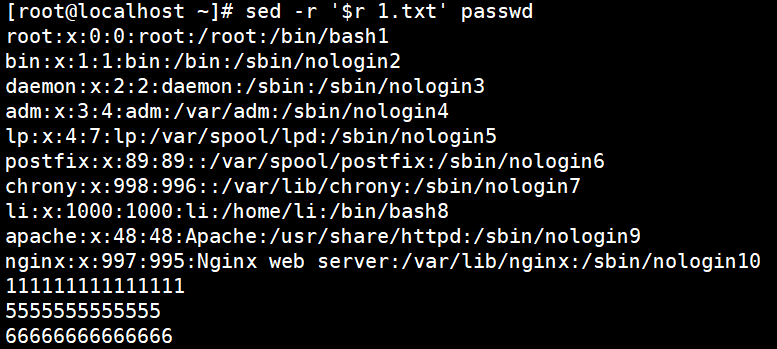
sed -r ‘$r 1.txt’ passwd
在passwd后面追读1.txt的内容
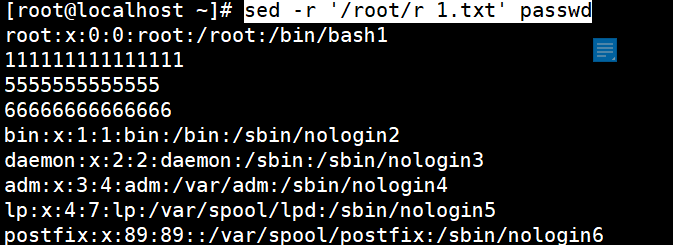
sed -r ‘/root/r 1.txt’ passwd
正则搜寻root
在root后面读取新文件
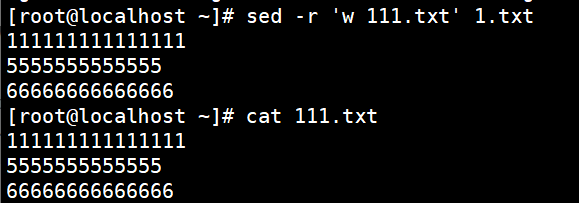
写文件命令:w(另存为)
sed -r ‘w 111.txt’ 1.txt
把1.txt全部内容 写入111.txt
追加命令: a(之后)
# sed -r 'a123' passwd
每行后面,都加上123行
# sed -r '2a123' passwd
2行后面,加上123行
插入命令: i(之前)
# sed -r '2iaaaaaaaa' passwd
在第二行插入新行aaaaaaaaaa
[root@localhost ~]# sed -r '2iaaaaaaaa' passwd
root:x:0:0:root:/root:/bin/bash1
aaaaaaaa
bin:x:1:1:bin:/bin:/sbin/nologin2
......
替换整行命令: c
# sed -r '2caaaaaaaa' passwd
把第二行替换成aaaaaaaaa
[root@localhost ~]# sed -r '2caaaaaaaa' passwd
root:x:0:0:root:/root:/bin/bash1
aaaaaaaa
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
获取下一行命令:n
# sed -r '/root/{n;d}' passwd
n下一行的意思。
找root行,然后下一行,删除
[root@localhost ~]# sed -r '/root/{n;d}' passwd
root:x:0:0:root:/root:/bin/bash1
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
n:next下一行可以用多次。
[root@localhost ~]# sed -r '/root/{n;n;d}' passwd
root:x:0:0:root:/root:/bin/bash1
bin:x:1:1:bin:/bin:/sbin/nologin2
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
多重编辑 e
sed -r -e '1,3d' -e '4s/adm/admin/g' passwd
[root@localhost ~]# sed -r -e '1,3d' -e '4s/adm/admin/g'passwd
admin:x:3:4:admin:/var/admin:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
实战案例
删除配置文件中#号注释行
sed -r '/^#/d' /etc/vsftpd/vsftpd.conf
修改文件:
sed -ri '$a\chroot_local_user=YES' /etc/vsftpd/vsftpd.conf
在最后一行追加
sed -ri '/^SELINUX=/cSELINUX=disabled' /etc/selinux/config
换行c
给文件行添加注释:
sed -r '2,6s/^/#/' a.txt
找到2到6行,把开始换成#
sed -r '2,6s/(.*)/#\1/' a.txt
()内容可以被\1引用
sed -r '2,6s/.*/#&/' a.txt
&匹配前面查找的内容
sed中使用外部变量
sed -r "\$a$var1" /etc/hosts
第一行后追加变量$var1
awk
1.前言
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。
数据可以来自标准输入、一个或多个文件,或其它命令的输出。
它支持用户自定义函数和动态正则表达式等先进功能,
awk的处理文本和数据的方式是这样的,
它逐行扫描文件,从第一行到最后一行,
寻找匹配的特定模式的行,并在这些行上进行你想要的操作。
如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕),
awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,
分别是Alfred Aho、Peter Weinberger、 Kernighan。
2.工作原理
awk -F: ‘{print $1,$3}’ /etc/passwd
(1)awk使用一行作为输入,并将这一行赋给内部变量$0,每一行也可称为一个记录,以换行符结束
(2)然后,行被:(默认为空格或制表符)分解成字段(或域),每个字段存储在已编号的变量中,从$1开始,
最多达100个字段
(3)awk输出之后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔
成字段并进行处理。该过程将持续到所有行处理完毕

3.语法
awk [options] ‘commands’ filenames (推荐)
==options:
例如:-F 定义输入字段分隔符,默认的分隔符是空格或制表符(tab)
==command(时空):
BEGIN{} {} END{}
BEGIN{}
begin发生在行处理前(注意大写)
{}
行处理时,读一行执行一次
END{}
行处理后
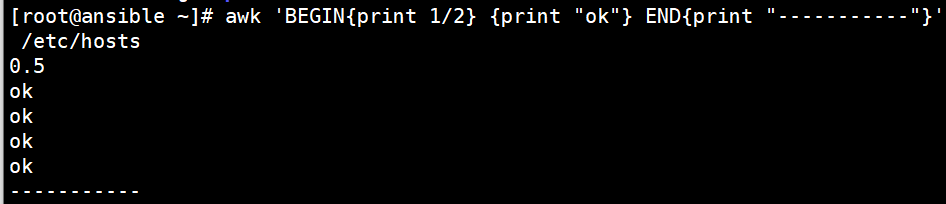
awk ‘BEGIN{print 1/2} {print “ok”} END{print “-----------”}’ /etc/hosts
内部变量
① FS
输入字段分隔符(默认空格)
# awk -F: '{print $1, $3}' /etc/passwd | head -1
root 0
或
# awk -F'[ :\t]' '{print $1,$2,$3}' /etc/passwd | head -1
root x 0
或
# awk 'BEGIN{FS=":"} {print $1,$3}' /etc/passwd | head -1
root 0
② OFS
输出字段分隔符
# awk -F: '{print $1,$2,$3,$4}' /etc/passwd | head -1
root x 0 0
# awk -F: 'BEGIN{FS=":";OFS="+++"}{print $1,$2,$3,$4}' /etc/passwd | head -1
root+++x+++0+++0
③ RS
输入记录(行)分隔符,默认换行符
# awk '{print $0}' a.txt
111 222 333 444 555:666:777
[root@localhost ~]# awk 'BEGIN{RS=" "}{print $0}' a.txt
111
222
333
444
555:666:777
请注意,在此时记录已经不是行的概念了。分隔符由”换行符“换成了”空格“
④ ORS
输出记录(行)分隔符,默认换行符
⑤ FNR ,NR
多文件汇总编号
多文件独立编号
# awk -F: '{print NR, $0}' /etc/centos-release /etc/hosts
1 CentOS Linux release 7.3.1611 (Core)
2 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
3 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# awk -F: '{print FNR, $0}' /etc/centos-release /etc/hosts
1 CentOS Linux release 7.3.1611 (Core)
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
⑥ NF
字段总数
[root@localhost ~]# awk -F: '{print NF, $0}' /etc/passwd
7 root:x:0:0:root:/root:/bin/bash
7 bin:x:1:1:bin:/bin:/sbin/nologin
7 daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@localhost ~]# awk -F: '{print NF, $NF}' /etc/passwd
7 /bin/bash
7 /sbin/nologin
7 /sbin/nologin
格式化输出
① print 函数
date |awk '{print "Month: " $2 "\nYear: " $1}'
Month: 11月
Year: 2017年
\n换行符
想输出文字,用引号
awk -F: '{print "username is: " $1 "\t uid is: " $3}' /etc/passwd | head -1
username is: root uid is: 0
awk -F: '{print "\tusername and uid: " $1,$3 "!"}' /etc/passwd | head -1
username and uid: root 0!
② printf 函数
语法
%s 字符类型
%d 数值类型
%f 浮点型,可以定义保留
占15字符
- 表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加\n
, 逗号,输出字段分隔符
awk -F: '{printf "%-10s %-10s %-15s\n", $1,$2,$3}' /etc/passwd | head
root x 0
bin x 1
daemon x 2
adm x 3
lp x 4
sync x 5
shutdown x 6
halt x 7
mail x 8
operator x 11
这是由于xmind的对齐导致的。
awk -F: '{printf "|%-15s| %-10s| %-15s|\n", $1,$2,$3}' /etc/passwd | head
|root | x | 0 |
|bin | x | 1 |
|daemon | x | 2 |
|adm | x | 3 |
|lp | x | 4 |
|sync | x | 5 |
|shutdown | x | 6 |
|halt | x | 7 |
|mail | x | 8 |
|operator | x | 11 |
模式(正则表达)和动作
概念
任何awk语句都由模式和动作组成。模式部分决定动作语句何时触发及触发事件。
如果省略模式部分,动作将时刻保持执行状态。每一行都会有动作。
模式可以是任何条件语句或复合语句或正则表达式。有模式的话,就是对模式对应的行进行动作。
模式:可以是条件测试,正则,复合语句
动作:可以是打印,计算等。
① 字符串比较
awk '/^root/' /etc/passwd
awk '$0 ~ /^root/' /etc/passwd
awk '$0!~/^root/' /etc/passwd
awk -F: '$1 ~ /^root/' /etc/passwd
② 数值比较
关系运算符
语法
运算符 含义 示例
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
awk -F: '$3 == 0' /etc/passwd
awk -F: '$3 == 1' /etc/passwd
awk -F: '$3 < 10' /etc/passwd
== 也可以用于字符串判断
awk -F: '$7 == "/bin/bash"' /etc/passwd
awk -F: '$1 == "alice"' /etc/passwd
算术 运算
语法
+ - * / %(模) ^(幂2^3)
awk -F: '$3 * 10 > 500' /etc/passwd
awk脚本编程
变量
awk调用变量
自定义内部变量 -v
awk -v user=root -F: '$1 == user' /etc/passwd
-v
定义变量
外部变量 “’”
单引号
# heihei=shutdown
# echo $heihei
shutdown
# awk -F: '$1 ~ "'"$heihei"'" ' passwd
shutdown:x:6:0shutdown:/sbin:/sbin:shutdown7
条件判断
if…else if…else
格式
{if(表达式1){语句;语句;…} else if (表达式2){语句;语句;…}else{语句;语句;…} }
if(){}else if (){}else{}
示例
需求:
管理员数量:管理员id为0
内置用户数量:用户id’小于1000
普通用户数量:用户id大于999
awk -F: '{if($3==0){i++} else if($3>999){k++}
else{j++}} END{print i; print k; print j}' /etc/passwd
awk -F: '{if($3==0){i++} else if($3>999)
{k++} else{j++}} END{print "管理员个数: "i;
print "普通用个数: "k; print "系统用户: "j}' /etc/passwd

循环
while
每行打印十次
awk ‘{i=1;whilw(i<=10){print $0;i++}}’ passwd
for
循环打印5个数字
awk ‘BEGIN{for(i=1;i<=5;i++){print i} }’
不适用BEGIN可以吗?
{},和END{}可以吗?可以需要有文件。
将每行打印10次
awk -F: '{ for(i=1;i<=10;i++) {print $0} }' /etc/passwd
打印每一行的每一列
awk -F: '{ for(i=1;i<=NF;i++) {print $i} }' passwd
说明:NF是最大列数,循环打印了每一列。
awk -F: '{ for(i=1;i<=NF;i++) {print $i} }' passwd
root
x
0
0
root
/root
/bin/bash
数组
定义数组
需求
将用户名定义为数组的值,打印第一个值
awk -F: '{username[++i]=$1} END{print username[1]}' /etc/passwd
root
数组遍历
按索引遍历
awk -F: '{username[x++]=$1} END{for(i in username) {print
i,username[i]} }' /etc/passwd
10 games
11 ftp
12 nobody
13 systemd-bus-proxy
14 systemd-network
15 dbus
16 polkitd
30 chrony
17 abrt
31 ntp
18 unbound
awk编程案例
统计/etc/passwd中各种类型shell的数量
awk -F: '{shells[$NF]++} END{ for(i in shells){print i,
shells[i]} }' /etc/passwd
提示
$NF 最后一列的字段内容
{}行处理
把统计的对象,作为索引。每次递增。
Print i 打印索引
Shells[i] 数组加索引,显示的就是值


















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









