



H100 真的被封印了吗?我用 vLLM+FP8 把吞吐拉爆了
为什么要做这次极限压测?
在原生 BF16 精度下,大模型对显存带宽(Memory Bandwidth)和容量的需求呈指数级增长。
高并发场景下,KV Cache 的显存爆炸往往导致 Batch Size 无法提升,显卡算力尚未跑满,显存却已耗尽。
这种“存算失衡”使得单位 Token 的生成成本居高不下,推理延迟(Latency)在高负载下显著恶化。
为了缓解显存压力,业界广泛采用了 INT4/INT8 等量化方案(如 GPTQ、AWQ)。
然而,传统的整数量化在追求极致压缩时,往往伴随着精度损失(Accuracy Drop)的风险,且在某些特定算子上并未能完全释放 Tensor Core 的计算潜力。
如何在保持模型聪明程度的同时,榨干硬件的每一滴性能,是生产环境部署的核心痛点。
为此,我们开展了本项目,项目深度整合了 NVIDIA H100 GPU 的硬件特性与 vLLM 推理框架的先进优化(如 PagedAttention 及 FP8 量化支持),针对 Llama-3-8B 等主流大模型,在极限压测场景下,系统性评估了 FP8 在吞吐量、显存效率及并发能力上的表现。
通过这次极限压测,得到了以下三点关键发现:
1. 吞吐量性能跃升
验证了 FP8 带来的算力红利。在极限压测下,FP8 模式相比 BF16 基线实现了 60.3% (约 1.6 倍) 的 Token 生成吞吐量提升(从 7,437 tok/s 提升至 11,921 tok/s),充分释放了 H100 Transformer Engine 的潜能。
2. 显存效率与并发革命
证明了 FP8 KV Cache 的“并发神技”。通过将 KV Cache 压缩为 FP8 格式,在单卡 80GB 显存限制下,成功将峰值并发承载能力(Peak Concurrent Requests)从 170 提升至 1,033,实现了 5 倍以上的容量增长,彻底消除了常规负载下的 OOM 风险。
3. 定义生产环境基准
确立了 H100 的单卡性能基线。通过全链路压测,量化了 H100 在 Llama-3-8B 模型下的“服务红线”:建议单卡承载 60 QPS 的持续随机负载,在此负载下可保持首字延迟(TTFT)在 120ms 以内的极佳体验,为企业集群规划提供了精确的量化参考。
为什么要用 vLLM?
vLLM 是一个用于 LLM 推理和服务的快速易用库,vLLM 具有以下优势:
✔️ 最先进的服务吞吐量
✔️ 通过 PagedAttention 有效管理注意力键值内存
✔️ 对传入请求进行连续批处理
✔️ 使用 CUDA/HIP 图进行快速模型执行
✔️ 量化:GPTQ、AWQ、INT4、INT8 和 FP8
✔️ 优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成。
✔️ 推测解码
✔️ 分块预填充

对于本项目而言, vLLM 凭借其标志性的 PagedAttention 技术,已经解决了显存碎片化问题。
而在最新的迭代中,vLLM 针对 H100 进行了深度适配,支持了 FP8 权重量化与 KV Cache FP8 压缩。
这种软硬件的深度结合,使得 vLLM 能够突破传统 CUDA Kernel 的瓶颈,实现真正的 Continuous Batching 性能飞跃。
核心技术解析
H100 × vLLM × FP8 为什么能跑出质变?答案就在下面。
1. vLLM 的关键:先把 KV Cache 的显存问题解决掉
传统推理框架会导致 KV Cache 随着生成长度动态增长,系统不得不预留最大可能的显存空间(MaxLength)。
而这容易造成显存碎片和浪费,显存先触顶后并发就会迅速崩盘。
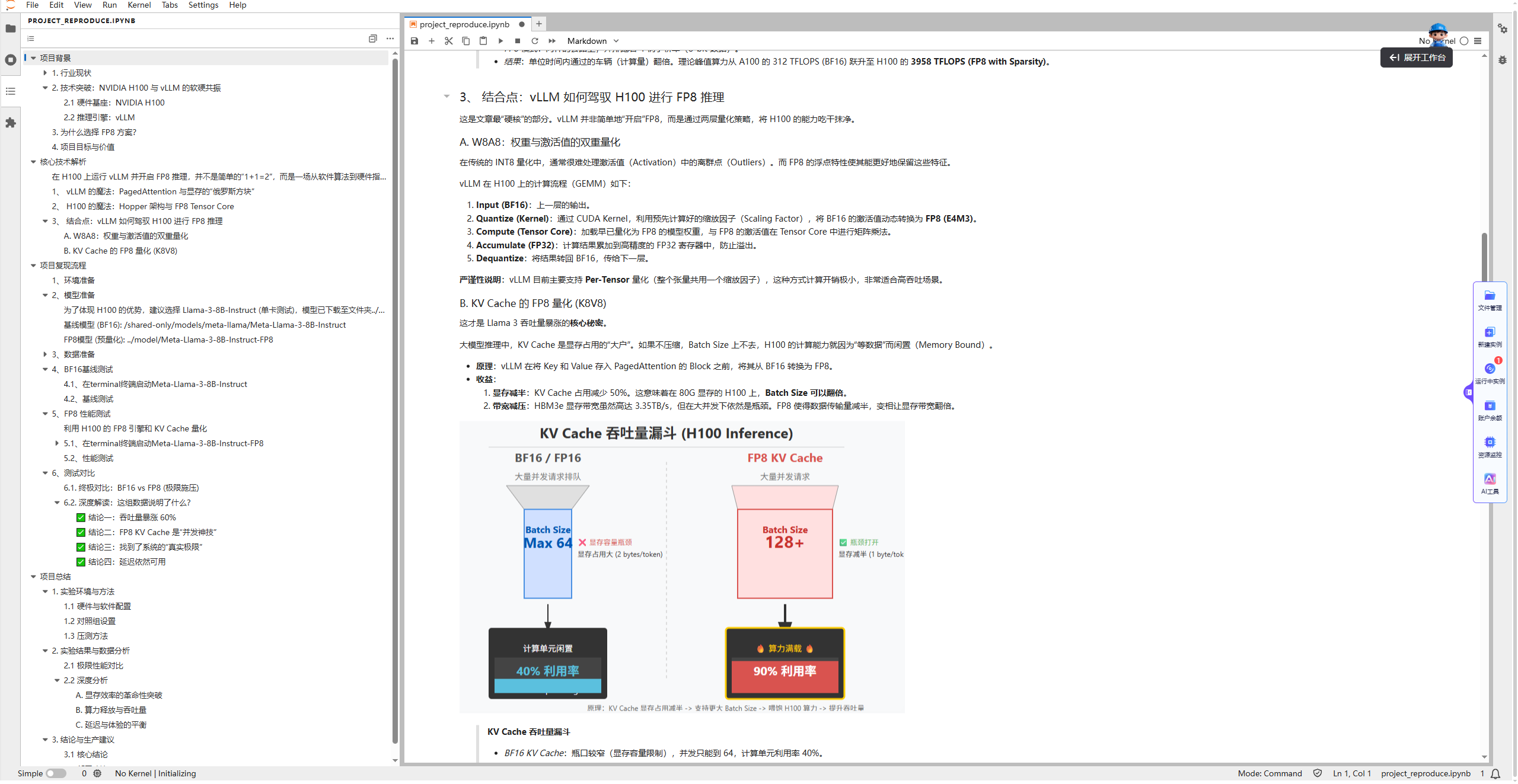
vLLM 的 PagedAttention 用虚拟内存和分页思想管理 KV Cache:把每个请求的 KV 拆成固定大小的 KV Blocks,并通过 Block Table 记录“逻辑连续的 token 块”到“物理显存块”的映射关系,使 KV Cache 可以按需分配、物理不连续存放,从而显著降低碎片化与无效占用,为高并发场景腾出显存空间。
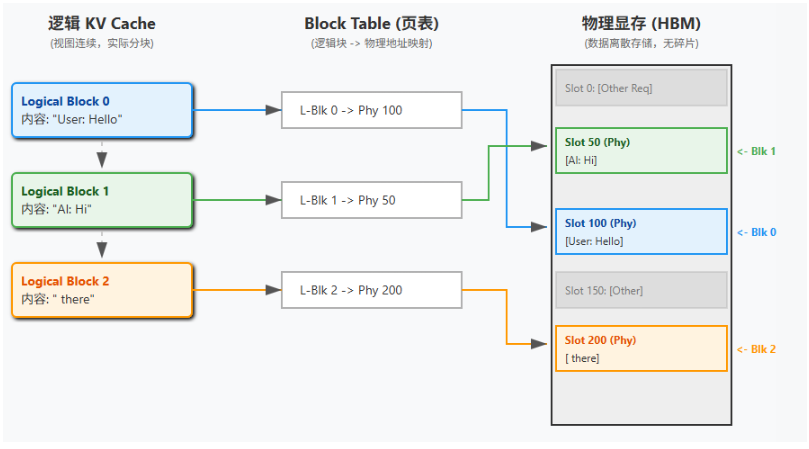
这种机制将显存浪费率降到了 <4%。在 H100 这种高带宽显卡上,显存容量往往比算力先触顶。PagedAttention 节省出的显存,意味着可以插入更多的并发请求(Larger Batch Size),从而直接提升吞吐量。
2. H100 的魔法: Hopper + Transformer Engine 的 FP8 原生支持
H100 的第四代 Tensor Core/Transformer Engine 支持 FP8 精度。
用更小的数据格式在相同带宽与寄存器宽度下,H100 可以一次性搬运和计算 2 倍的数据量。
FP8 常见两种格式:E4M3(精度更高、动态范围较小)与 E5M2(动态范围更大、精度更低),由硬件/软件在不同场景选择使用。
第一种,E4M3。这类格式的精度较高,动态范围较小。推理(Inference)通常使用此格式,因为权重的分布相对集中。
第二种,E5M2。这类格式的动态范围大,精度低(类似 IEEE 754 标准)。通常用于训练中的梯度计算。
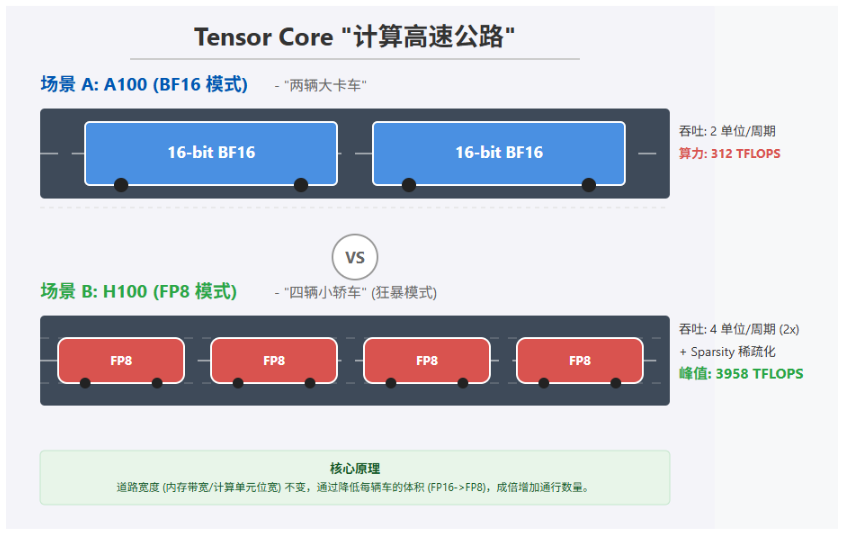
我们用这个高速公路图片来做一个比喻,对比 A100 和 H100 显卡的 Tensor Core(张量核心)计算效率差异。
BF16 模式就像是一条高速公路(Tensor Core)上并排跑着 2 辆大卡车(16-bit 数据)。
FP8 模式更像是同样的公路上并排跑着 4 辆小轿车(8-bit 数据)。
在内存带宽、算力单元等硬件条件不变的情况下,通过采用更窄的浮点精度(从 BF16 降到 FP8)+ 稀疏化技术,让数据能更密集地 “运输”,从而大幅提升 Tensor Core 的计算效率。
3. 真正的组合拳:vLLM 用“两层 FP8”同时拉吞吐、抬并发
很多人以为“开 FP8”就是结束了,但 vLLM 更关键的是两层策略:
(1) W8A8:权重与激活值的双重量化
运行时将激活从 BF16 动态量化到 FP8,与 FP8 权重在 Tensor Core 做 GEMM,并用更高精度累加,兼顾吞吐与数值稳定性。
严谨性说明: vLLM 目前主要支持 Per-Tensor 量化(整个张量共用一个缩放因子),这种方式计算开销极小,非常适合高吞吐场景。
(2) KV Cache 的 FP8 量化
在写入 PagedAttention 的 KV block 前,将 K/V 从 BF16 转为 FP8,直接降低 KV Cache 显存与带宽压力,这才是并发上限能被显著抬高的关键。
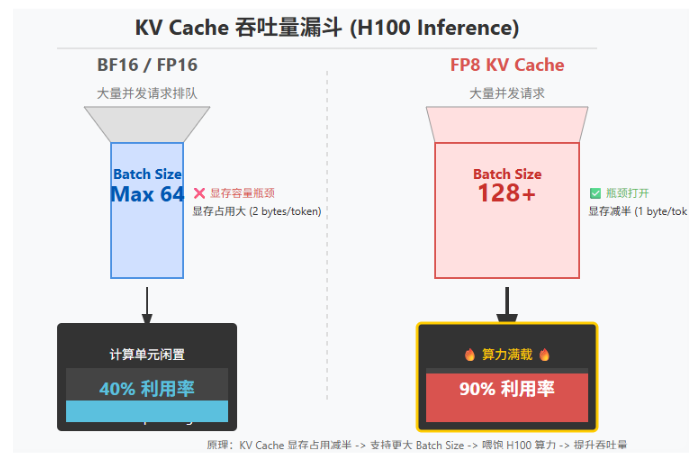
FP8 KV Cache:瓶口变宽(容量减半),并发达到 128+,计算单元利用率飙升至 90%,触发 H100 的“狂暴模式”。
总结: vLLM 的 PagedAttention/continuous batching 解决“容器与调度”,H100 的 FP8 Tensor Core 解决“计算引擎”,而 FP8 KV Cache 则是解除显存瓶颈、放大并发能力的关键开关。
一键体验 vLLM + FP8 推理
Step1 进入项目
在 Lab4AI 平台中搜索或点击对应项目解锁 H100 封印,点击立即体验,只需 1 卡即可体验。
Step2 激活环境
打开 project_reproduce.ipynb,在项目复现流程”部分运行部分代码并切换到已配置好的环境内核(按 Notebook 提示完成即可)。
Step3 BF16 基线测试
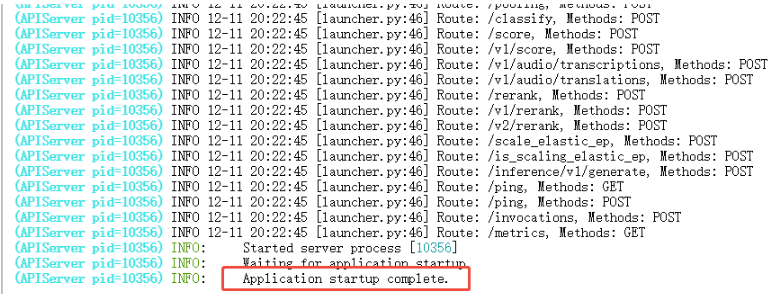
模型与数据集已准备好。先在终端启动 Meta-Llama-3-8B-Instruct(BF16) 服务;当日志出现 “Application startup complete.” 即表示服务启动完成。
随后回到 Notebook 执行压测代码:工具会按设定的到达速率持续发请求,并统计该压力下的**吞吐、并发、TTFT(首字延迟)与 TPOT(单 token 时间)**等指标。
Step4 FP8 性能测试
在终端启动 Meta-Llama-3-8B-Instruct-FP8 服务。注意:部署 FP8 模型前请先释放 BF16 测试占用的显存(例如停止 BF16 服务/重启服务进程)。启动完成后,同样在 Notebook 运行对应的压测代码,得到 FP8 的指标结果。
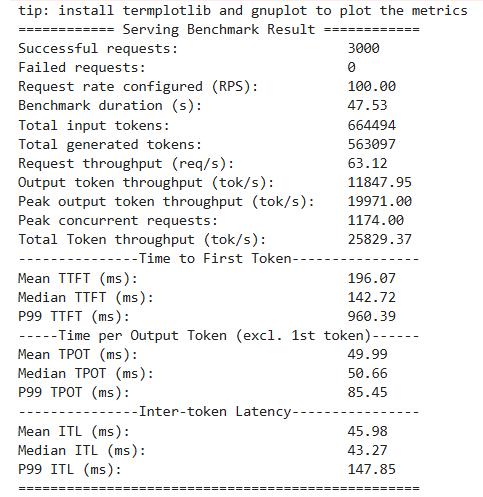
Step5 终极对比
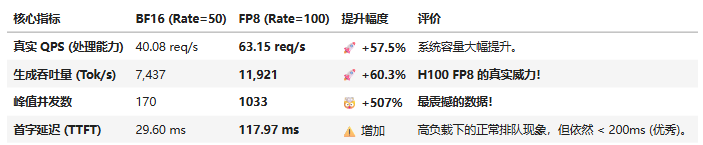
我们将之前的 BF16 最好成绩(Rate=50)与现在的 FP8 最好成绩(Rate=100)进行对比,可以得到四条结论。
如果你关心的是部署成本,重点看结论二;如果你关心的是容量规划,重点看结论三:
深度解读:
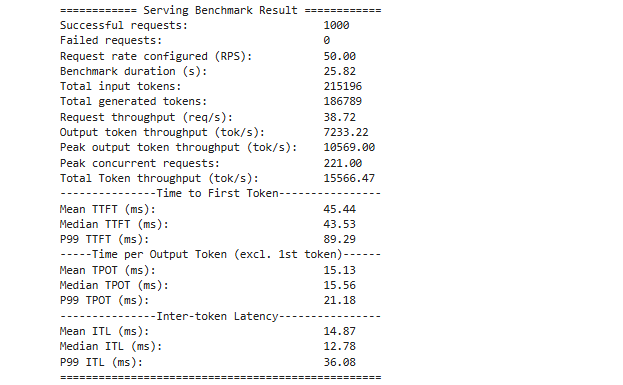
结论一:吞吐量提升约 60%
BF16 输出吞吐约 7.4k tok/s,切到 FP8 后提升到 ~11.9k tok/s,吞吐直接拉升一档,说明 H100 的 FP8 计算路径确实能把算力吃满。
结论二:FP8 KV Cache 让并发“起飞”
FP8 下 Peak concurrent requests 达到 1033,而 BF16 只有 170。核心原因是 --kv-cache-dtype fp8 显著降低 KV Cache 显存占用,从根本上抬高了单卡并发上限。
结论三:摸到了单卡的真实 QPS 上限
设定到达速率 100 RPS,实际完成吞吐稳定在 ~63.15 req/s。这基本就是 Llama-3-8B 在该数据分布下单张 H100 的可持续服务极限,再加压只会排队更长。
结论四:高并发下变慢,但仍可用
TPOT 上升到 38.75 ms/token,换算约 25 token/s。即便在千级并发的极限压力下,输出仍然是连续可读的,体验仍处在可用区间。
一句话总结: FP8 同时提升了产能(tok/s)与承载(并发),并给出了可用于上线的单卡容量边界。
项目结论与生产建议
本次评测表明,在 NVIDIA H100 上部署 Llama-3 等主流模型时,FP8 是更优的生产级选择。
在精度影响通常可控的前提下,可获得约 1.6× 的吞吐提升与约 5× 的并发承载提升,从而同时缓解“算力墙”和“显存瓶颈”,显著提高单卡服务能力与单位成本产出。
面向企业部署时,建议将 FP8 作为默认配置,在启动命令中固定启用--quantization fp8 --kv-cache-dtype fp8。
在选择模型时,优先选择预量化好的 FP8 模型,以避免在线量化开销与不确定性。
容量规划方面,可将单张 H100 在随机负载下约 60 QPS 视为可持续服务基准,在此基础上进行线性扩容并预留安全冗余。


















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









