



告别手敲 tabular:Table2LaTeX-RL 高保真表格生成复现
最近电子科技大学联合同济大学、之江实验室的研究人员开发了Table2LaTeX-RL,这是一个使用多模态语言模型和双奖励强化学习框架将表格图像转换为高保真LaTeX代码的系统。这种方法在复杂表上表现出卓越的性能,实现了0.6145的CW-SSIM和0.9218的TEDS-Structure,同时保持了0.9917LaTeX编译率。
论文名称:Table2LaTeX-RL: High-Fidelity LaTeX Code Generation from Table Images via Reinforced Multimodal Language Models
作者团队:电子科大团队
Table2LaTeX-RL的论文、代码、模型、数据均已开源,欢迎大家体验!

01 论文概述
详细论文解读请查看往期文章NeurlPS2025| 告别手动制表:电子科大+之江实验室提出Table2LaTeX-RL创新性高保真表格生成方法
简介
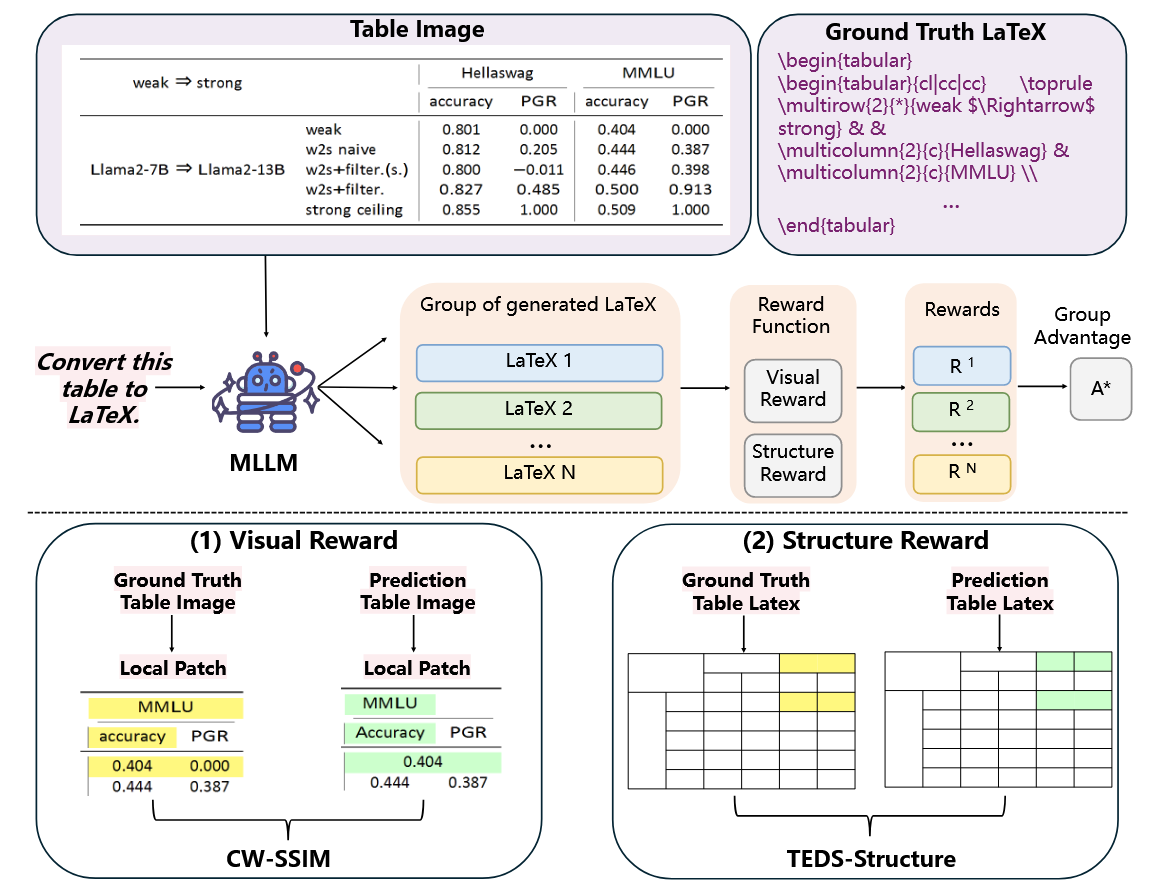
科学论文中的复杂表格一直是自动化处理中的硬骨头:多级表头、跨行跨列单元格、嵌套结构和数学公式都极其依赖精细的版面控制。Table2LaTeX-RL 正是针对这一瓶颈提出的新方案——作者构建了大规模表格图像–LaTeX数据集,并基于多模态大模型设计出首个视觉–结构双重奖励强化学习框架 VSGRPO,让模型不仅能输出语法正确的 LaTeX 代码,更能在最终排版效果上高度贴近原始表格,尤其在复杂表格场景下显著超越现有系统。
核心创新
本研究提出了一个基于强化多模态大语言模型的高保真表格生成框架——Table2LaTeX-RL,旨在实现表格图像到 LaTeX 代码的精确映射。本文的主要创新点包括:
- 大规模数据构建:构建了首个超过 120 万对表格图像–LaTeX 源代码的高质量训练数据集,依据结构复杂度划分为简单、中等与复杂三级,为模型提供了全面的结构学习基础。
- 双重奖励强化学习策略(VSGRPO):在 Group Relative Policy Optimization(GRPO)框架下,引入结构层奖励(TEDS-Structure)与视觉层奖励(CW-SSIM)的联合优化机制,有效提升了模型对复杂表格的生成稳定性与结构保真度。
- 混合评估体系:提出结合结构相似度与视觉相似度的综合评估协议,克服了传统指标仅依赖文本层面对视觉一致性缺乏刻画的问题,更准确地反映生成结果的质量。
研究成果
实验结果表明,所提出方法在表格图像到 LaTeX 代码生成任务上取得了当前最优性能(State-of-the-Art)。其中,基于 Qwen2.5-VL-3B 的模型在复杂表格上的 CW-SSIM 指标提升 0.09,TEDS-Structure 首次突破 0.92,在结构准确性与视觉一致性方面均显著优于现有模型(如 Mathpix、Nougat、GPT-4o 等)。此外,本文工作首次系统验证了强化学习在视觉-结构协同优化中的有效性,为高保真文档重建提供了新的研究范式与方法论参考。相关代码与数据集已开源,为表格理解与文档智能化研究奠定了重要基础。
02 Lab4AI一键复现流程
本次复现基于 Lab4AI 平台现有的 Table2LaTeX-RL 项目完成的,整体流程可以概括为:选项目 → 进入环境 → 按官方脚本运行训练与评估。
Step 1:进入 Lab4AI 复现项目
打开Lab4AI 官网,在导航栏选择 「论文复现」。
在搜索框中输入 “Table2LaTeX-RL”,找到对应的论文复现项目。
点击项目详情页中的 「立即体验」,进入在线复现环境。
由于该项目使用多模态大模型并涉及强化学习阶段,模型体量和计算量都比较大,在资源选择中请配置8卡GPU,以保证训练与评估过程能顺利跑完。
Step 2:进行训练
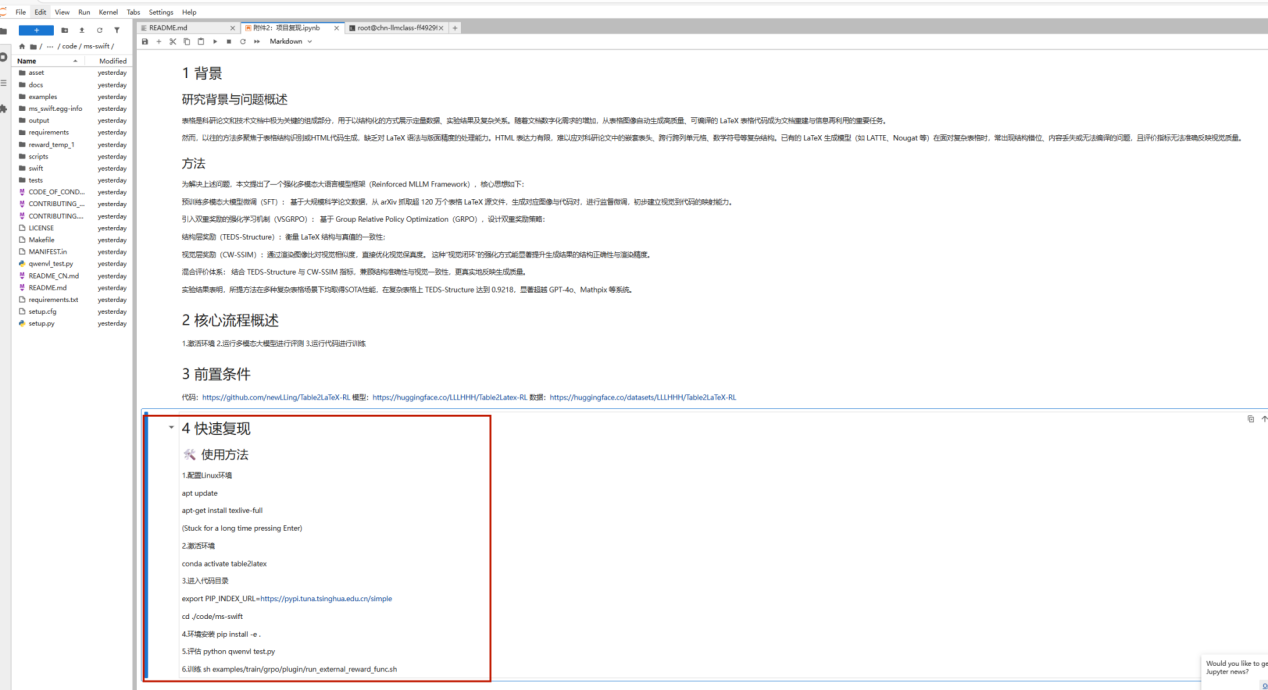
进入环境后,核心目录位于:/workspace/codelab/Table2LaTeX-RL/,其中:
code/:项目代码(ms-swift 为主工程目录)
dataset/:表格图像与 LaTeX 标注数据
model/:预训练多模态大模型
进入代码目录:cd /workspace/codelab/Table2LaTeX-RL/code,在该目录下可以看到平台准备好的复现文档,按照文档完成环境配置和依赖安装。准备完成后,进入主工程目录启动训练:cd ms-swift 按文档中的官方脚本启动训练。
Step 3:进行评估,获得输出结果
训练结束后,按照文档中的评估脚本进行验证,即可得到结果。
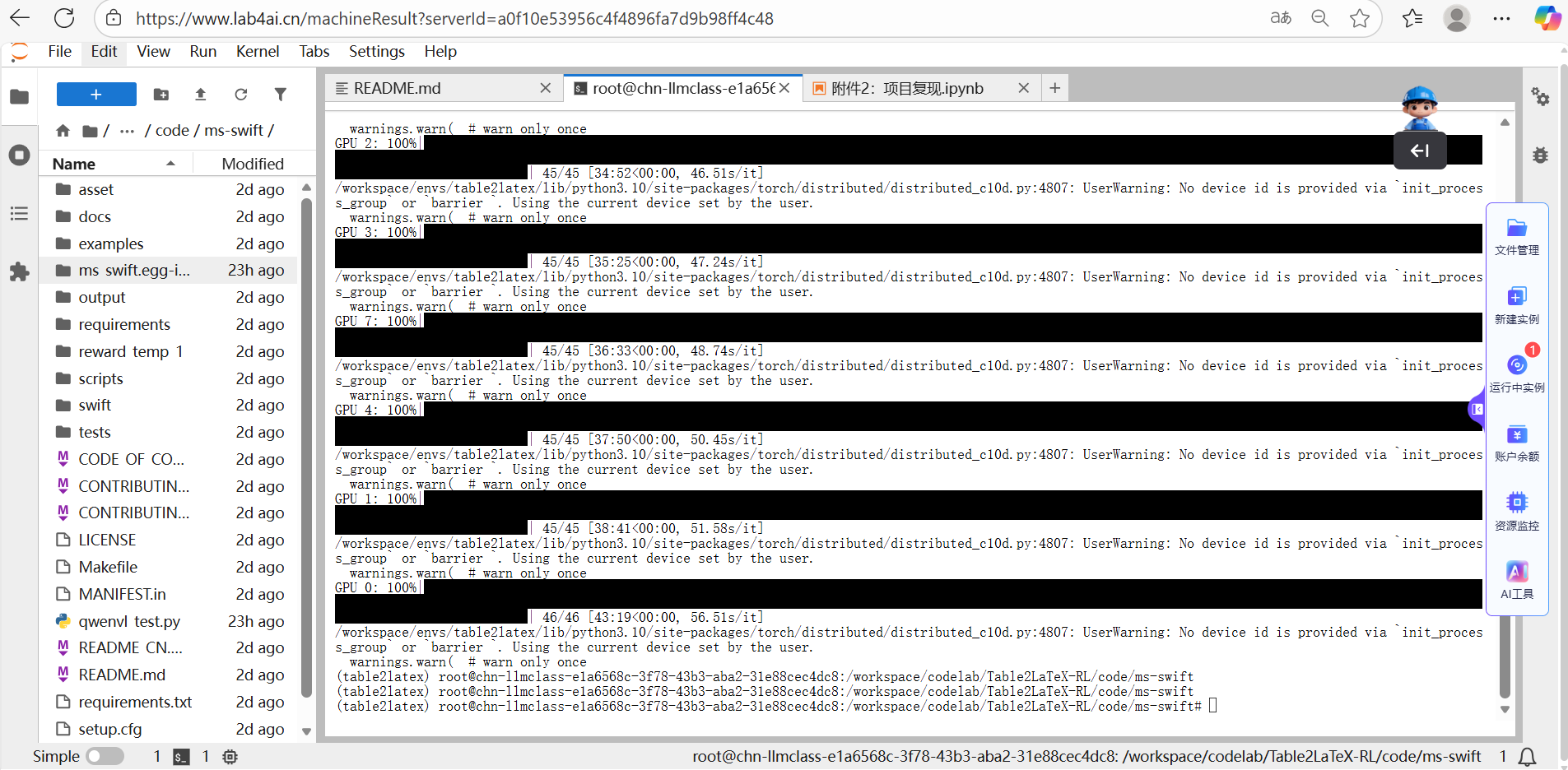
原数据:包含输入表格的图像路径以及对话形式的指令与模型回复;
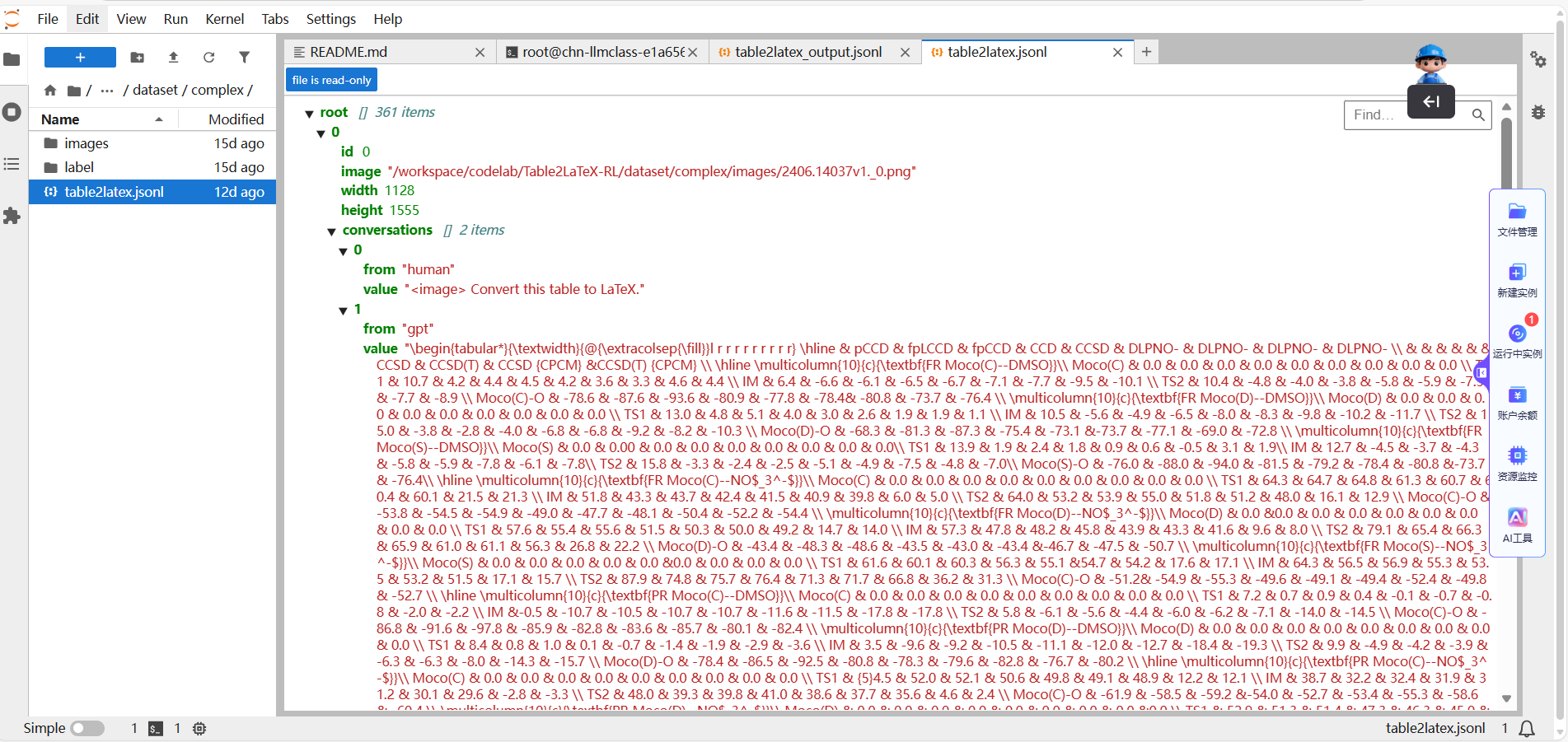
评估后:评估输出则在此基础上增加了 prediction 和 reference 两个字段——prediction:模型生成的 LaTeX 代码和reference:对应样本的人工标注 LaTeX 代码。
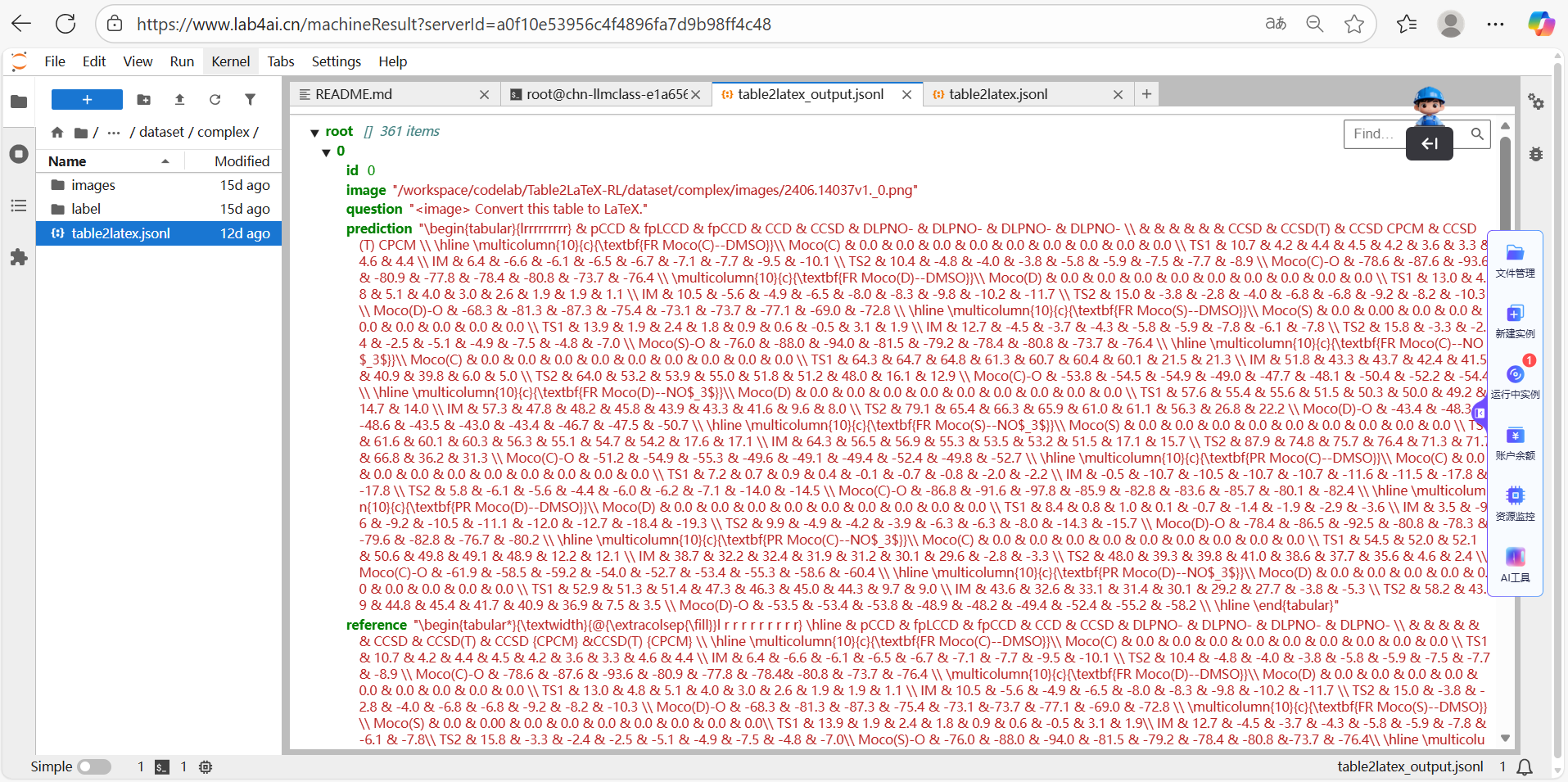
这意味着每条样本都会同时给出“模型输出 + 真值标注”这一对结果,二者一一对应。基于这份评估文件,就可以继续计算TEDS-Structure、CW-SSIM等指标,并挑选典型样例做可视化对比,来检查 Table2LaTeX-RL 在复杂表格上的还原效果。
03 Lab4AI还能做什么?
本次实验验证了 Table2LaTeX-RL 在实际科研与生产场景中的可用性。
依托多模态大模型与VSGRPO 强化学习框架,系统能够将复杂表格图片自动转换为高保真 LaTeX 代码,在多级表头、跨行跨列单元格、数学公式等高难度场景下,依然保持较高的结构还原度和编译成功率。
为学术排版、文档归档和自动化制表提供了可落地的技术方案。
Lab4AI不止让你能“跑通”,更让你能“跑远”:
1.开发者:高性能算力深度绑定
大模型实验室Lab4AI实现算力与实践场景无缝衔接,支持模型复现、训练、推理全流程使用,且具备灵活弹性、按需计费、低价高效的特点,解决用户缺高端算力、算力成本高的核心痛点。
2.科研党:从“看论文”到“发论文”的全流程支持
集成Arxiv每日速递,提供论文翻译与分析工具,并凭借一键论文复现功能,快速验证CVPR、ICCV、NeurIPS、ICML、ECCV、AAAI、IJCAI、ICLR、IJCV、TPAMI、JMLR、TIP等顶刊顶会的算法,帮助您解决数据集下载慢、依赖冲突、GPU 不足等环境配置难题,将环境配置时间节省80%以上。
3.学习者:AI课程支撑您边练边学
提供多样化AI在线课程,含LLaMAFactory官方合作课程等课程,聚焦大模型定制化核心技术,实现理论学习与代码实操同步推进。


















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









