



成本杀手!LLaMA-Factory 助阵 Qwen3-VL:低预算下的高效医疗影像全揭秘
还在为医疗影像大模型的“高算力、高显存”门槛头疼吗?
2025年10月,Qwen3-VL-30B-A3B-Instruct 的开源,带来了革命性的解决方案。它独创的 A3B(Adaptive 3B Activation)动态稀疏机制,可以在保持顶级性能的同时,仅激活 30 亿参数,直接将显存占用降低 60%!
今天,我们将深度解析一个完整的实战项目:如何利用LLaMA-Factory 框架,高效微调 Qwen3-VL,让模型能够在有限的医学影像数据上,更好地理解图像内容、描述可见结构,并生成符合医学语境的分析文字。
这套 “小数据 + 稀疏激活 + LoRA” 的高效优化路径,是为所有受限于算力、但希望快速验证领域效果的开发者量身定制!
项目背景:破解医疗AI“高算力”痛点
医疗影像(CT、MR、X-Ray)场景对模型的细粒度理解和兼容性要求极高。Qwen3-VL 的架构设计,精准命中了这些需求。
核心优势——专为医疗场景:
- A3B 动态稀疏激活: 在推理时,模型仅激活约 10% 的总参数量(约 3B)。这解决了 30B 级别大模型在单卡/低算力环境中的部署难题。
- 跨模态深度对齐: 采用视觉-语言联合对比学习框架,在视觉编码器与语言模型之间建立细粒度映射,支持分辨率动态切换。
- 医疗原生支持: 模型原生支持DICOM 格式解析,无需额外处理即可兼容主流医学影像。在 MedTrinity-25M 零样本评测中,对颅内出血、骨折等病灶的准确率已达到 78.3% 的高基准。
本次实战,我们正是基于Qwen3-VL 的这些特性,精选了 MedTrinity-25M 的 16k parquet子集,依托 LLaMA-Factory 框架,探索在有限资源下实现极致性能适配。
效果验证:微调后的诊断能力怎么样?
可以在项目复现中的“快速体验demo” 中进行快速体验,参考步骤进行操作,即可立即观察到基线模型和微调后模型的区别。
通过对比基线模型和微调后的模型,验证在典型高频医疗场景中的诊断精度。以一张CT 影像为例:
基线模型效果

微调后模型效果

| 模型 | 定位能力 | 诊断风格 | 文本特点 |
|---|---|---|---|
| 基线模型效果 | 能精确定位到额–顶骨交界处的异常区域 | 倾向直接下结论 | 直接给出“右侧额顶骨区域颅骨骨折”等单一诊断,风格果断,但在复杂病例中可能略显武断。 |
| 微调模型效果 | 同样能识别绿色框内的异常区域 | 更偏“提示 + 鉴别诊断” | 给出了异常相关结构,描述为“局部密度异常,可考虑出血、水肿、挫伤等”,风格更保守,更接近临床放射科的谨慎表达。 |
从结果可以看到,基线模型虽然能比较准确地抓住病变位置,但在病变性质上更倾向于直接给出单一诊断;
微调后的模型则更像临床中的放射科报告,会先提示“这里不对劲”,同时给出一系列可能的解释,把“判断空间”交给医生。
这种从“武断”到“谨慎”的变化,其实就是我们希望通过微调带来的:更贴近真实临床语境的 AI。
实战揭秘:医疗影像诊断模型的高效微调流程
项目利用LLaMA-Factory 强大的轻量化微调能力,在Lab4AI上完成了 “数据清洗 → LoRA 微调 → 推理验证”的流程。
如果你也想亲手体验一次“大模型 × 医疗影像”的微调流程,可以在项目复现中的项目详细流程实践中进行,步骤如下。
Step1 数据集准备
项目使用的是MedTrinity-25M 医学图文大数据集。原始数据可以到官网获取
本次Lab4AI 实践从其中选择了一个约16,163 张图像的 parquet 子集,并放置在:/workspace/user-data/codelab/Qwen3-VL-30B/dataset/data_sft
Step2 数据预处理
LLaMA-Factory 的多模态数据格式主要支持 ShareGPT 格式 与 Alpaca 格式。Lab4AI 已预先完成了格式转换,如需复现,可根据提供的脚本自行修改:
- 输出路径
- 验证集比例(ratio)
并且可以修改code/data目录下的dataset_info.json文件,增加自定义数据集。将训练集和验证集代码段添加到dataset_info.json文件中的末尾。
如果只是跟着本项目操作,可直接跳过。
Step3 基线模型
在微调前,我们使用未改动的基线模型(原始 Qwen3-VL-30B-A3B-Instruct)进行一次图像描述测试。
我们从验证集随机抽取 1 张 CT 进行测试。基线模型给出了如下描述:
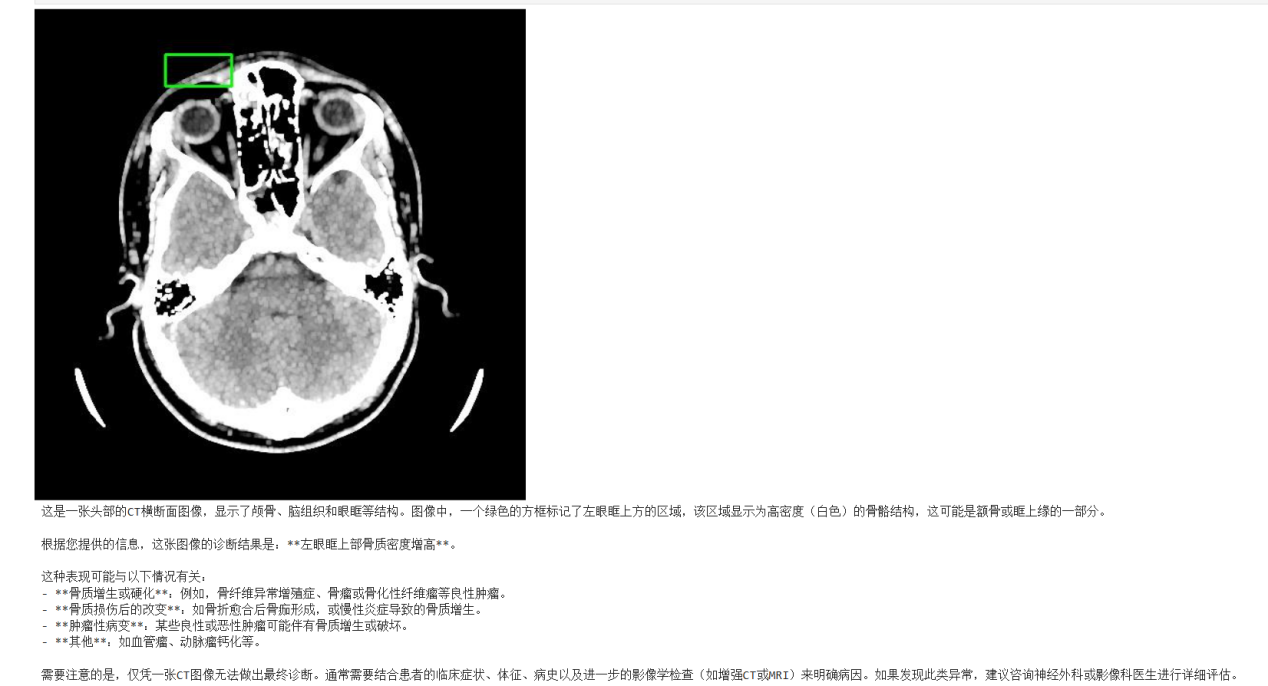
可以看出,基线模型能够识别“位置”,但诊断结果只是骨质密度增高,且描述内容不够详细。
Step4 lora微调
准备好lora微调权重文件
将adapter_name_or_path路径替换成以上Lora微调权重保存的路径。再次启动模型,若效果不佳,更改参数继续微调。
--deepspeed ds_z2_config.json----》ds_z2_config.json--per_device_train_batch_size 32-----》4
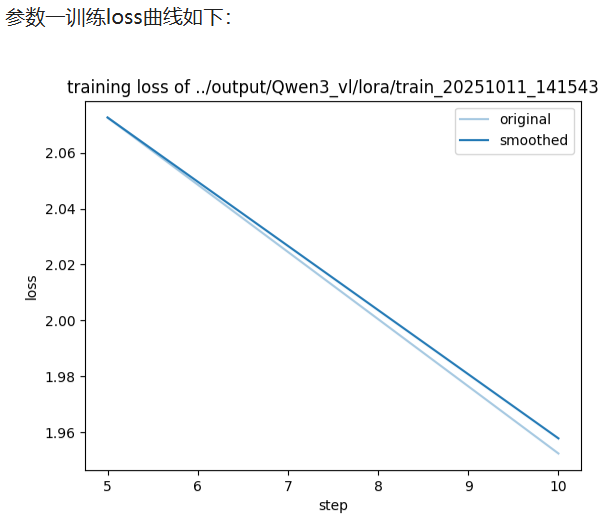
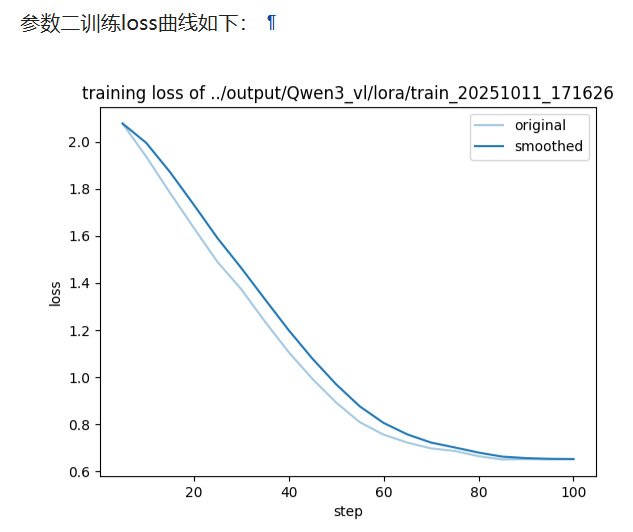
由loss对比图可知,同硬件 / 同数据 ,Z3 训练速度更快但微调 loss 明显上涨,Z2 速度略降却能把 loss 压得更低
Z3 训练速度↑ 主要来自「小块通讯 + 微批次自动放大」的带宽优势;
Z3 微调 loss↑ 本质是「参数延迟 + 梯度噪声」导致收敛点变差;
若显存够用,追求指标优先选Z2;显存爆炸才上 Z3,并同步 放大 global batch / 拉长 warmup / 降低 lr 去补回落点。
针对Qwen3-VL 的稀疏架构和医疗细粒度特征,我们总结了以下参数调优建议,以保证最高效能:
| 超参 | 推荐配置/建议 | 效果说明 |
|---|---|---|
| Epoch & 早停 | - 16k 数据:3 epoch 出现性能拐点;4 epoch 起容易过拟合- 5k 小数据:建议 6–8 epoch ,强烈建议开启 EarlyStopping(patience=1)- lr scheduler:使用 cosine decay + 3% warmup(默认即可) | - 有效防止在小样本集上的过拟合- linear 衰减在图文任务上无显著优势 |
| Rank & Alpha | - Rank:建议 ≥ 64(16→64 提升显著,128 以上收益趋于饱和)- Alpha:设置为 alpha = rank / 2(如 rank=64 → alpha=32) | - 高 rank 能捕捉医学影像的细粒度结构特征- Alpha 与 rank 成比例更稳定,避免训练震荡 |
| Target Modules | 建议选择 all-linear | - 比仅 q_proj / v_proj 平均提升 ~1.2 个点- 显存开销增加 ❤️%,性价比最高 |
| Dropout | - 数据 ≤ 10k:dropout = 0.05- 数据 ≥ 50k:可设为 0 | - 小数据更容易过拟合,适当 dropout 明显提升泛化能力- 大数据不需要 dropout,关闭可提升收敛速度 |
项目结论
本项目依托Lab4AI平台,基于LLaMA-Factory成功对Qwen3-VL-30B-A3B-Instruct进行了完整的微调流程,并在自定义医学影像-文本数据集上验证了稀疏激活架构的有效性。
实验结果显示,模型在颅内出血、骨折等典型影像识别与描述任务上,性能显著优于基线模型,达到了快速领域适配的目标。这充分证明了 “小数据 + 稀疏激活 + LoRA” 在医疗多模态场景的巨大潜力。
然而,受限于当前资源,仍有以下明确优化方向:
- 数据规模扩充: 目前仅使用了MedTrinity-25M 数据集约 16k 样本的子集。扩大至 25M 全量数据将显著提升模型对稀有病灶的覆盖率和描述多样性。
- 多语言能力增强: 当前训练集为纯英文。引入中英平行语料或将数据翻译为中文,可有效提升模型在中文医疗语境下的理解与表达。
- 任务维度扩展: 本次仅使用多模态图文对进行训练。补充Chinese-medical-dialogue 等纯文本对话语料,将极大增强模型在多轮问诊和报告解读等任务中的表现。
未来,通过持续扩大数据规模、丰富多语言支持及扩展任务模态,将进一步释放Qwen3-VL-30B-A3B-Instruct 的完整性能,使其成为更贴近临床实际需求的多模态医疗助手。
创作者招募中!Lab4AI x LLaMA-Factory 邀你共创实战资源
想解锁大模型微调实战,却愁无算力、缺平台?现在机会来了!
Lab4AI 联合 LLaMA-Factory 启动创作者招募,诚邀 AI 开发者、学生及技术爱好者提交微调实战案例,通过审核即享算力补贴与官方证书等,共创AI实践新生态。
大模型实验室Lab4AI实现算力与实践场景无缝衔接,具备充足的H卡算力,支持模型复现、训练、推理全流程使用,且具备灵活弹性、按需计费、低价高效的特点,解决用户缺高端算力、算力成本高的核心痛点。
Lab4AI不止让你能“跑通”,更让你能“跑远”:
1.开发者:高性能算力深度绑定
大模型实验室Lab4AI实现算力与实践场景无缝衔接,支持模型复现、训练、推理全流程使用,且具备灵活弹性、按需计费、低价高效的特点,解决用户缺高端算力、算力成本高的核心痛点。
2.科研党:从“看论文”到“发论文”的全流程支持
集成Arxiv每日速递,提供论文翻译与分析工具,并凭借一键论文复现功能,快速验证CVPR、ICCV、NeurIPS、ICML、ECCV、AAAI、IJCAI、ICLR、IJCV、TPAMI、JMLR、TIP等顶刊顶会的算法,帮助您解决数据集下载慢、依赖冲突、GPU 不足等环境配置难题,将环境配置时间节省80%以上。
3.学习者:AI课程支撑您边练边学
提供多样化AI在线课程,含LLaMAFactory官方合作课程等课程,聚焦大模型定制化核心技术,实现理论学习与代码实操同步推进。


















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









