



GLM-4.6V开源:重新定义多模态AI的行动范式
12月8日,智谱AI正式开源GLM-4.6V系列多模态大模型,作为GLM系列在多模态方向上的重要迭代,GLM-4.6V在技术架构和应用场景上都实现了突破性进展。
技术架构全面升级
GLM-4.6V系列包含两款模型:GLM-4.6V(106B-A12B)、GLM-4.6V-Flash(9B)。模型将训练时上下文窗口提升到128k tokens,在视觉理解精度上达到同参数规模SOTA水平。 最引人注目的是,GLM-4.6V首次在模型架构中将Function Call(工具调用)能力原生融入视觉模型,打通从"视觉感知"到"可执行行动"的链路。这种"图像即参数,结果即上下文"的设计理念,使得模型能够直接处理多模态输入,无需中间转换,显著降低了工程复杂度。
革命性的多模态工具调用能力传统工具调用大多基于纯文本,在面对图像、视频等复杂内容时存在信息损失。GLM-4.6V构建了原生多模态工具调用能力:
- 输入多模态: 图像、截图、文档页面等可以直接作为工具参数
- 输出多模态: 模型能够对工具返回的图表、网页截图等进行再次视觉理解
- 闭环处理: 从感知到理解到执行的完整链路一体化完成
这种能力使得GLM-4.6V能够应对图文混排输出、商品识别与推荐、辅助型Agent等复杂视觉任务。
四大典型应用场景展现强大实力
场景一:智能图文混排与内容创作
GLM-4.6V在内容创作场景中表现卓越。无论是输入学术论文、研报还是简单主题,模型都能生成结构清晰、图文并茂的内容。它能够自动调用检索工具寻找配图,并进行视觉审核,确保内容质量。 在实际测试中,仅需提供一篇Arxiv论文,GLM-4.6V就能在几分钟内生成完整的公众号科普文章,包含精准的标题、专业的解读和恰当的图表插入。
提示词:用通俗易懂的话说明:这篇论文写了什么、研究现状、核心创新思路、以及这项成果除了学术价值之外,对现实世界和普通人意味着什么。

场景二:视觉驱动的电商导购
在电商场景下,GLM-4.6V可独立完成从"看图"到"生成导购清单"的完整链路。用户上传街拍图后,模型能自动识别购物意图,调用图像搜索工具,清洗多平台数据,最终生成包含价格、缩略图和购买链接的标准导购表格。
提示词:请帮我搜索与图中迪丽热巴的发箍类似的平价同款。

场景三:前端复刻与视觉交互开发
GLM-4.6V在前端开发领域展现出惊人能力。上传网页截图后,模型可实现像素级复刻,生成高质量的HTML/CSS代码。更支持多轮视觉交互调试,用户只需在截图上圈选并给出自然语言指令,模型就能自动修正代码。
提示词:复刻截图中的网页,页面中涉及的所有图片素材必须直接使用真实图片和视频。

场景四:长上下文文档与视频理解
GLM-4.6V 将视觉编码器与语言模型的上下文对齐能力提升至128k,模型拥有了“过目不忘”的长记忆力。在实际应用中,128k上下文约等于150页的复杂文档、200页PPT或一小时视频,能够在单次推理中处理多个长文档或长视频。
性能基准全面领先
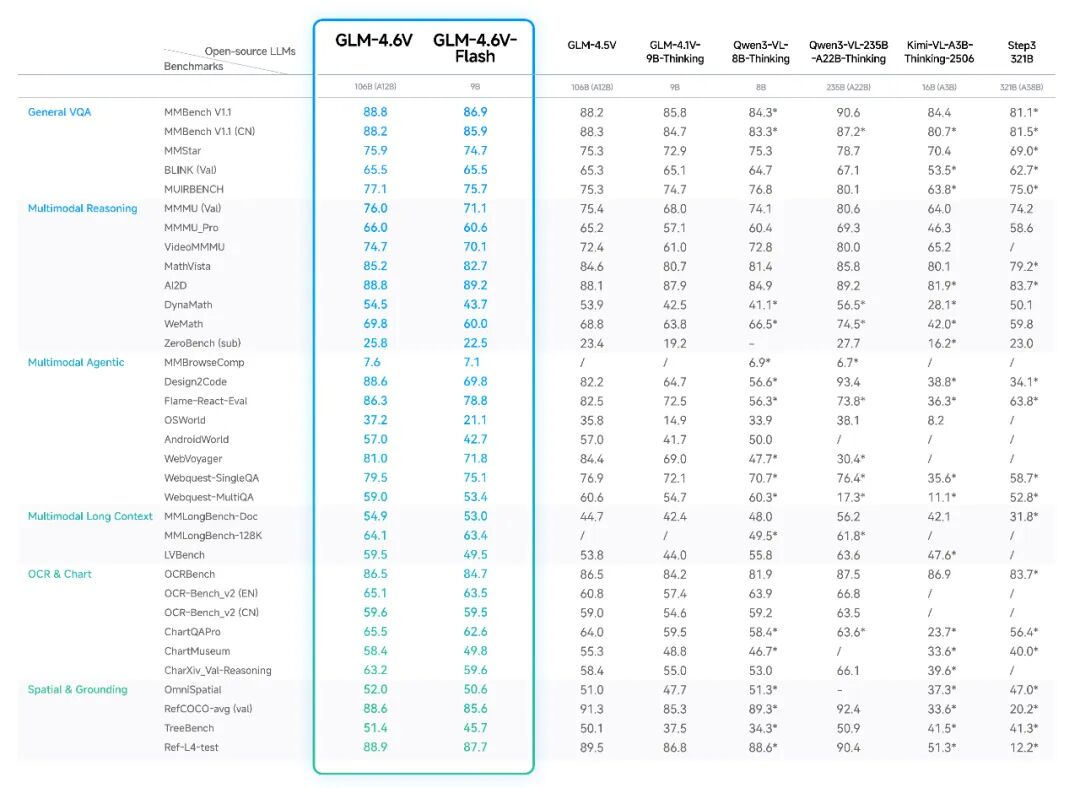
在MMBench、MathVista、OCRBench等30多个主流多模态评测基准中,GLM-4.6V均表现出色。9B版本的GLM-4.6V-Flash整体表现超过Qwen3-VL-8B,106B参数版本的性能比肩2倍参数量的Qwen3-VL-235B。
大模型实验室Lab4AI
GLM-4.6V的开源标志着多模态AI技术进入新的发展阶段。其"行动多模态"范式不仅提升了技术能力,更拓展了应用边界。从内容创作到商业分析,从编程辅助到视频理解,GLM-4.6V展现出了成为多模态AI时代基础平台的潜力。
大模型实验室作为专注于AI前沿技术的内容社区,将持续跟踪GLM-4.6V的最新进展,并分享更多实践案例和技术分析。欢迎各位开发者关注社区动态,共同探索这一创新技术的更多应用可能。
更多信息请关注公众号和官网。


















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









