






📫 作者简介:「六月暴雪飞梨花」,专注于研究Java,就职于科技型公司后端工程师
🏆 近期荣誉:华为云云享专家、阿里云专家博主、腾讯云优秀创作者、腾讯云TDP-KOL、ACDU成员、墨天轮技术专家博主
🔥 三连支持:欢迎 ❤️关注、👍点赞、👉收藏三连,支持一下博主~
文章目录
引言
分割文件场景很常见,尤其是在日志解析或者查阅日志信息时。在我们日常的工作中,传输文件很常见,在进行文件传输的过程中,因为网络传输速率和文件内容大小的限制,经常会遇到文件传输失败的情况。针对文件传输失败的情况。大文件由于其传输时间长,一旦传输失败,重新传输费时且不一定能保证再次传输成功。针对这种情况,可以考虑将文件分割成小文件的方式进行传输,减少因传输失败或传输大小限制导致的问题。本文就是讲述如何拆分文件后再进行传输,可提升在工作中的效率。
split使用场景
● 分割文本,在有些语言中可分割字符串、分割文本、分割视频等
● 分割日志文件,协助运维同事排查日志报错等
● 分割后备份文件,用于增量存储数据等
● 处理大型数据集文件等
MacOS上的Split工具与Linux上大同小异,主要有一些参数不一样,但是总体来看都还是一致的。
前期准备
为了更准确的学习和实践,方便后续使用,操作前最好准备一台Linux的操作系统以及可以使用的一个终端。
操作系统:CentOS 7.7,GNU/Linux
内核版本:Red Hat 4.8.5-36
[root@localhost ~]# uname -a
Linux xxx.xxx 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.7.1908 (Core)
[root@localhost ~]#
语法帮助
其实,在所有的Linux为内核的机器上面,都可以使用 --help 来查询帮助,以帮助我们快速了解命令的用途和用法,例如split --help。而在Linux中的帮助命令更清晰,更能让我们快速了解split命令的用法。
[root@localhost ~]$ split --help
用法:split [选项]... [输入 [前缀]]
Output fixed-size pieces of INPUT to PREFIXaa, PREFIXab, ...; default
size is 1000 lines, and default PREFIX is 'x'. With no INPUT, or when INPUT
is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-a, --suffix-length=N generate suffixes of length N (default 2)
--additional-suffix=SUFFIX append an additional SUFFIX to file names
-b, --bytes=SIZE put SIZE bytes per output file
-C, --line-bytes=SIZE put at most SIZE bytes of lines per output file
-d, --numeric-suffixes[=FROM] use numeric suffixes instead of alphabetic;
FROM changes the start value (default 0)
-e, --elide-empty-files do not generate empty output files with '-n'
--filter=COMMAND write to shell COMMAND; file name is $FILE
-l, --lines=NUMBER put NUMBER lines per output file
-n, --number=CHUNKS generate CHUNKS output files; see explanation below
-u, --unbuffered immediately copy input to output with '-n r/...'
--verbose 在每个输出文件打开前输出文件特征
--help 显示此帮助信息并退出
--version 显示版本信息并退出
SIZE is an integer and optional unit (example: 10M is 10*1024*1024). Units
are K, M, G, T, P, E, Z, Y (powers of 1024) or KB, MB, ... (powers of 1000).
CHUNKS may be:
N split into N files based on size of input
K/N output Kth of N to stdout
l/N split into N files without splitting lines
l/K/N output Kth of N to stdout without splitting lines
r/N like 'l' but use round robin distribution
r/K/N likewise but only output Kth of N to stdout
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
请向<http://translationproject.org/team/zh_CN.html> 报告split 的翻译错误
要获取完整文档,请运行:info coreutils 'split invocation'
[root@localhost ~]$
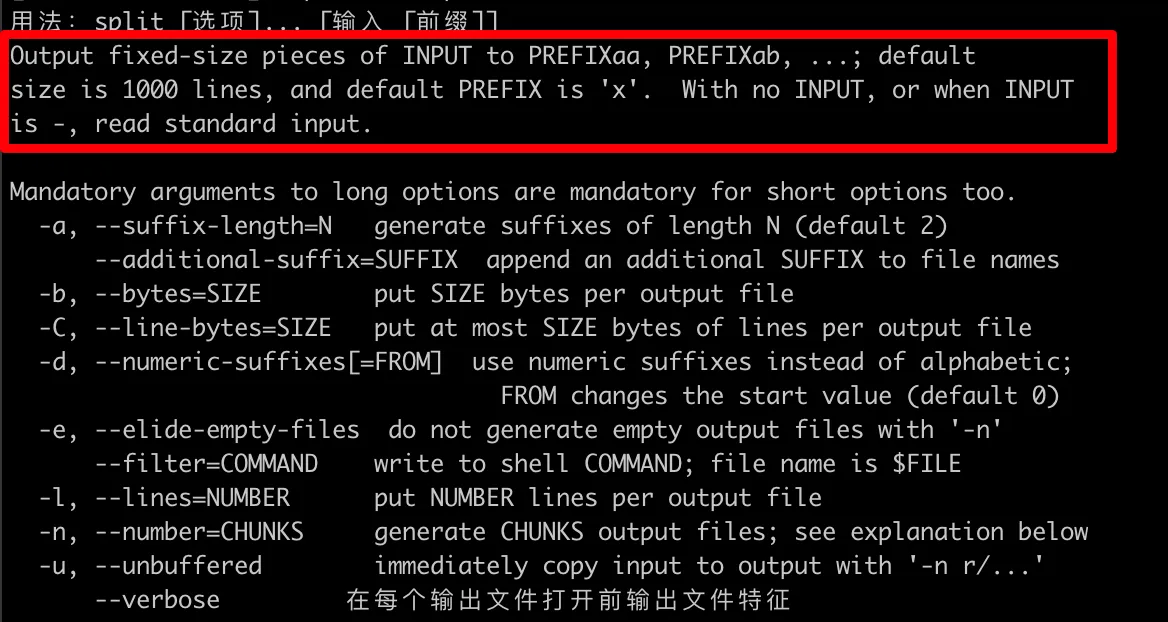
在Linux中的帮住文档中,一个很有意思的事情就是帮助文档里面这句话(上图我圈出来了),翻译下就是
将INPUT输出为固定大小的块,分别存储到PREFIXaa、PREFIXab……目录中;默认情况下大小为1000行,默认前缀为’x’。如果没有输入,或者当有输入为“-”时,则读取标准输入。
可以看出来Linux中的说明性文档很人性化,都会告知具体的默认信息和具体情况,下面的一些帮助信息或者枚举类的信息,也是很明了,一看就让人明白这种;反观MacOS中就没有那么乐观了。
当然,如果想要了解的更深,例如版本信息,则可以执行 --version 来查询更多的信息,丰富我们的知识。从下面的查询可以得出 当前机器的 split 版本为 8.22,使用 GPLv3+ 许可,更多信息则需要参考 http://gnu.org/licenses/gpl.html 等等。
[root@localhost ~]# split --version
split (GNU coreutils) 8.22
Copyright (C) 2013 Free Software Foundation, Inc.
许可证:GPLv3+:GNU 通用公共许可证第3 版或更新版本<http://gnu.org/licenses/gpl.html>。
本软件是自由软件:您可以自由修改和重新发布它。
在法律范围内没有其他保证。
由Torbjörn Granlund 和Richard M. Stallman 编写。
[root@localhost ~]#
测试文件信息
测试文件:log.log
测试文件大小:9.1MB
测试文件行数:232376L
具体查询信息如下:
[root@localhost test]# du -hs *
9.1M log.log
[root@localhost test]#
[root@localhost test]# wc -l log.log
232376 log.log
[root@localhost test]#
1 默认分割
按照Linux中的默认规则,执行命令,可以很直观的看到,默认情况下,split命令会按照行来分割文件,而且每个文件的大小为1000L,分割后输出的文件以 x 为前缀,后续按照两位英文字母依次排列为aa,ab,……,zz结束。此时可以分割文件的最大的个数为笛卡尔乘积,也就是 23^2=529 。当然了,如果量还需要更大的话,则可以按照3位英文字母排列,aaa,aab,aac,……,直到zzz结束。具体的分割规则和计算方式,这里不再赘述,可以参考上面macOS中所写。
[root@localhost test]# split log.log
[root@localhost test]#
[root@localhost test]# ls
log.log xai xar xba xbj xbs xcb xck xct xdc xdl xdu xed xem xev xfe xfn xfw xgf xgo xgx xhg xhp xhy xih xiq
xaa xaj xas xbb xbk xbt xcc xcl xcu xdd xdm xdv xee xen xew xff xfo xfx xgg xgp xgy xhh xhq xhz xii xir
xab xak xat xbc xbl xbu xcd xcm xcv xde xdn xdw xef xeo xex xfg xfp xfy xgh xgq xgz xhi xhr xia xij xis
xac xal xau xbd xbm xbv xce xcn xcw xdf xdo xdx xeg xep xey xfh xfq xfz xgi xgr xha xhj xhs xib xik xit
xad xam xav xbe xbn xbw xcf xco xcx xdg xdp xdy xeh xeq xez xfi xfr xga xgj xgs xhb xhk xht xic xil xiu
xae xan xaw xbf xbo xbx xcg xcp xcy xdh xdq xdz xei xer xfa xfj xfs xgb xgk xgt xhc xhl xhu xid xim xiv
xaf xao xax xbg xbp xby xch xcq xcz xdi xdr xea xej xes xfb xfk xft xgc xgl xgu xhd xhm xhv xie xin xiw
xag xap xay xbh xbq xbz xci xcr xda xdj xds xeb xek xet xfc xfl xfu xgd xgm xgv xhe xhn xhw xif xio xix
xah xaq xaz xbi xbr xca xcj xcs xdb xdk xdt xec xel xeu xfd xfm xfv xge xgn xgw xhf xho xhx xig xip xiy
[root@localhost test]#
[root@localhost test]# wc -l x*
1000 xaa
1000 xab
1000 xac
1000 xad
1000 xae
1000 xaf
……此处省略多行
1000 xiw
1000 xix
376 xiy
232376 总用量
[root@localhost test]#
2 按输出行数量分割
这个我们在MacOS中有做过实践,当时使用的行数是 1000L。此处分割 log.log ,3500L作为一个输出文件,输出文件的前缀为linux_log_,再做一次实践。
[root@localhost test]# split -l 3500 log.log linux_log_
[root@localhost test]#
[root@localhost test]# ls linux_log*
linux_log_aa linux_log_ah linux_log_ao linux_log_av linux_log_bc linux_log_bj linux_log_bq linux_log_bx linux_log_ce linux_log_cl
linux_log_ab linux_log_ai linux_log_ap linux_log_aw linux_log_bd linux_log_bk linux_log_br linux_log_by linux_log_cf linux_log_cm
linux_log_ac linux_log_aj linux_log_aq linux_log_ax linux_log_be linux_log_bl linux_log_bs linux_log_bz linux_log_cg linux_log_cn
linux_log_ad linux_log_ak linux_log_ar linux_log_ay linux_log_bf linux_log_bm linux_log_bt linux_log_ca linux_log_ch linux_log_co
linux_log_ae linux_log_al linux_log_as linux_log_az linux_log_bg linux_log_bn linux_log_bu linux_log_cb linux_log_ci
linux_log_af linux_log_am linux_log_at linux_log_ba linux_log_bh linux_log_bo linux_log_bv linux_log_cc linux_log_cj
linux_log_ag linux_log_an linux_log_au linux_log_bb linux_log_bi linux_log_bp linux_log_bw linux_log_cd linux_log_ck
[root@localhost test]# wc -l linux_log*
3500 linux_log_aa
3500 linux_log_ab
3500 linux_log_ac
3500 linux_log_ad
3500 linux_log_ae
此处省略多行……
3500 linux_log_ck
3500 linux_log_cl
3500 linux_log_cm
3500 linux_log_cn
1376 linux_log_co
232376 总用量
[root@localhost test]#
3 按输出文件大小分割
在MacOS中,我记得我写了是按照字节数量分割文件。我个人感觉按照输出文件大小分割更合适一些,这个主要是理解的偏差,这种方式我自己也更好理解。这里按照2M一个输出文件,输出文件的后缀为linux_b_。
[root@localhost test]# split -b 2M log.log linux_b_
[root@localhost test]#
[root@localhost test]# ls linux_b_*
linux_b_aa linux_b_ab linux_b_ac linux_b_ad linux_b_ae
[root@localhost test]#
[root@localhost test]# du -hs linux_b_*
2.0M linux_b_aa
2.0M linux_b_ab
2.0M linux_b_ac
2.0M linux_b_ad
1.1M linux_b_ae
[root@localhost test]#
[root@localhost test]# wc -l linux_b*
51110 linux_b_aa
51112 linux_b_ab
51112 linux_b_ac
51110 linux_b_ad
27932 linux_b_ae
232376 总用量
[root@localhost test]#
4 按照输出文件个数分割
使用-n来确定输出文件的数量,这个参数在MacOS中也是一致。例如将log.log分成 6 个目标文件输出。为了更好的说明分割的效果,我这里将分割后的输出的文件大小以及文件内的行数都打印出来。
[root@localhost test]# split log.log linux_file_count_ -n 6
[root@localhost test]#
[root@localhost test]# ls linux_file_count_*
linux_file_count_aa linux_file_count_ab linux_file_count_ac linux_file_count_ad linux_file_count_ae linux_file_count_af
[root@localhost test]#
[root@localhost test]# wc -l linux_file_count_*
38728 linux_file_count_aa
38728 linux_file_count_ab
38730 linux_file_count_ac
38732 linux_file_count_ad
38728 linux_file_count_ae
38730 linux_file_count_af
232376 总用量
[root@localhost test]# du -hs linux_file_count_*
1.6M linux_file_count_aa
1.6M linux_file_count_ab
1.6M linux_file_count_ac
1.6M linux_file_count_ad
1.6M linux_file_count_ae
1.6M linux_file_count_af
[root@localhost test]#
5 组合命令分割
如果希望每个文件在结尾处都是完整的,不至于一行数据被分割到两个文件中,那么此种应用场景正适合。下面我使用 -n 命令 和 l 结合使用,将文件 log.log 分割为 前缀为linux_3_的3个文件。
[root@localhost test]# split -n l/3 log.log linux_3_
[root@localhost test]#
[root@localhost test]# ls linux_3_*
linux_3_aa linux_3_ab linux_3_ac
[root@localhost test]#
[root@localhost test]# du -hs linux_3_*
3.1M linux_3_aa
3.1M linux_3_ab
3.1M linux_3_ac
[root@localhost test]# wc -l linux_3_*
77457 linux_3_aa
77461 linux_3_ab
77458 linux_3_ac
232376 总用量
[root@localhost test]#
[root@localhost test]# tail -20f linux_3_aa
2023-12-09 07:59:51,890 INFO ConnectionMetrics, totalCount = 0, detail = {long_connection=0, long_polling=0}
2023-12-09 07:59:54,890 INFO Connection check task start
2023-12-09 07:59:54,890 INFO Long connection metrics detail ,Total count =0, sdkCount=0,clusterCount=0
2023-12-09 07:59:54,891 INFO Connection check task end
2023-12-09 07:59:54,891 INFO ConnectionMetrics, totalCount = 0, detail = {long_connection=0, long_polling=0}
2023-12-09 07:59:57,891 INFO Connection check task start
2023-12-09 07:59:57,891 INFO ConnectionMetrics, totalCount = 0, detail = {long_connection=0, long_polling=0}
2023-12-09 07:59:57,891 INFO Long connect
6 更改输出文件后缀长度-a参数
在上面“默认分割”步骤有讲述到后缀的长度,这种情况就是文件比较大,分割后的输出文件数量比较多的情况。这个同macOS中命令参数一致,命令是 -a [长度],由于在MacOS中的帮助命令中有明确的指定,所以当时也没有在意,-a 命令默认情况下是2位数,也可以不写,当然也是可以指定的,例如 split -a 3 log.log ,输出的文件格式就是 xaaa,xaab,xaac,……,直到xzzz结束。
7 更改输出文件后缀类型-d参数
这个可以参考macOS中的“隐藏参数说明”。
8 忽略0大小的文件-e参数
拆分文件时,一些输出件的大小可能为零,也就是我们常说的空文件,在帮助文档中的全称是 elide-empty-files 。为防止零大小的输出文件,使用带有 -e 参数的拆分,以确保省略零大小的文件。
9 显示拆分时的文件特征verose参数
Linux中拆分命令不打印任何输出,如果想要跟踪拆分的工作原理可以使用参数 --verose 。
思考👀
(1)需要分割的文件如果不包含目标文件,则无法运行拆分命令。
(2)声明前缀是可选的。如果未指定前缀,则拆分默认使用x作为前缀,将创建的文件命名如下:xaa、xab、xac等。
总结
在我们日常的工作中,传输文件很常见,在进行文件传输的过程中,因为网络传输速率和文件内容大小的限制,经常会遇到文件传输失败的情况。针对文件传输失败的情况。大文件由于其传输时间长,一旦传输失败,重新传输费时且不一定能保证再次传输成功。针对这种情况,可以考虑将文件分割成小文件的方式进行传输,减少因传输失败或传输大小限制导致的问题。本文就是讲述如何拆分文件后再进行传输,可提升在工作中的效率。
欢迎关注博主 「六月暴雪飞梨花」 或加入【六月暴雪飞梨花社区】一起学习和分享Linux、C、C++、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











