




2024年12月17日,NVIDIA CEO黄仁勋在毫无预告下,在Youtube发布一个影片:只见他趣味地从厨房的烤炉端出一个「蛋糕」, 说道这是一台全新的AI主机“Jetson Orin Nano Super Developer Kit”,效能提升1.7倍,具有Cuda、cuDNN神经网络且透过全新的架构可以处理机器人以及大型语言模型。
这台号称全新的Jetson Orin Nano “Super” 具有以下规格:
- 6 Core ARM Cortex78AR
- 1024 CUDA
- 32 Tensor
- 8GB 128-bit LPDDR5
这时候我感到一点奇怪,因为这个规格跟我目前手上的Jetson Orin Nano “without Super” 不是完全一样的吗?
这个问题立即就有人在NVIDIA的官方论坛中询问,“Is that mean there is no hardware difference? It’s just a BSP/software performance improvement?”
官方的回覆是,“Yes, the existing Jetson Nano Orin Developer Kit can be upgraded to Jetson Orin Nano Super Developer Kit with this software update.”
而前几天,官方的FAQ已经加入这个问题的标准解答

资料来源:NVIDIA官方网站
也就是说,这台所谓的全新的Jetson Orin Nano “Super”,与旧版的Orin完全无硬件上的差异,而所谓的效能提升1.7倍就是透过软件升级来达成的,如果你手上有一台旧版Orin,只要安装新的软件,就可以穿上「红内裤」变成Super的超人模式,不需要再为了这号称的1.7倍效能购买新设备,而原本Nano这个产品线的所有机器都会以Super型态出厂,不会再有纯Nano规格的产品。
这样说来,黄仁勋自称这台为All brand New,事实上并非是全新的架构,只是旧瓶装新酒,那么你肯定会控告这个广告华而不实对吧,错错错,这次NVIDIA的Jetson Orin Nano “Super”效能提升了,但定价却从$499降到$249,对消费者来说这才是真正的实惠。
Orin Nano Super的优势
那么一个旧硬件框架是如何透过软件提升到1.7倍效能?另外一个问题则是,8G小机器加上了最佳化软件就能飞天钻地吗?
在这篇文章我们先回答第一个问题,Super Mode到底是从哪里压榨出来的?
答案可能是:加压超频。
我们观察两个不同Jetpack套件,前版本5.1与Super版本6.1,可以发现,早期的电源模式最高15W,而在Super版比15W还多了MAXN选项,根据官方数据MAXN代表大约25W,那么我们选择MAXN模式后,会有什么改变呢?
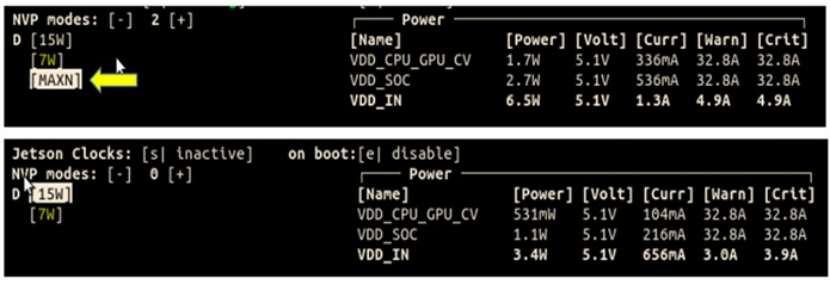
下图则是将电源模式调整为MAXN模式后,比较其运作数据可以发现CPU运作频率可高达1.7GHz(原本1.5 GHz),存储器从2.1 GHz提升到3.2 GHz。
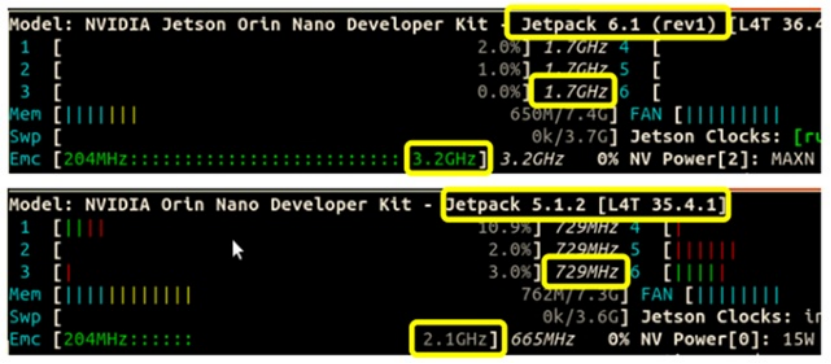
依照官方数据,与AI运算相关的主要装置GPU,其频率更从原本的635 MHz提升到1020 MHz,这也就是主要的Super模式的由来。经由这几个方向的压榨,我们可以看到装置在AI效能有显著的提升,包括整数及浮点数的神经网络运算大约都能提升70%以上效能。
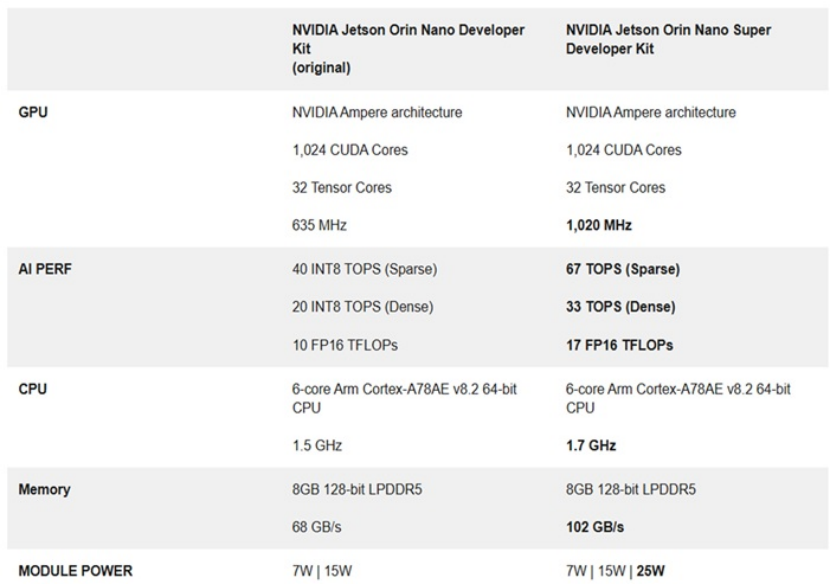
效能比较表(来源:NVIDIA)
如果你手上拥有的不是Nano这个规格的,是不是就没办法穿上红内裤变成Super模式呢?嘿嘿,见鬼了,Orin NX也有Super模式,效能一样提升近50%,但NX没有降价,目前依旧为原价,另外Orin中最高等级的AGX似乎还没有红内裤的消息,有赖后续更新。
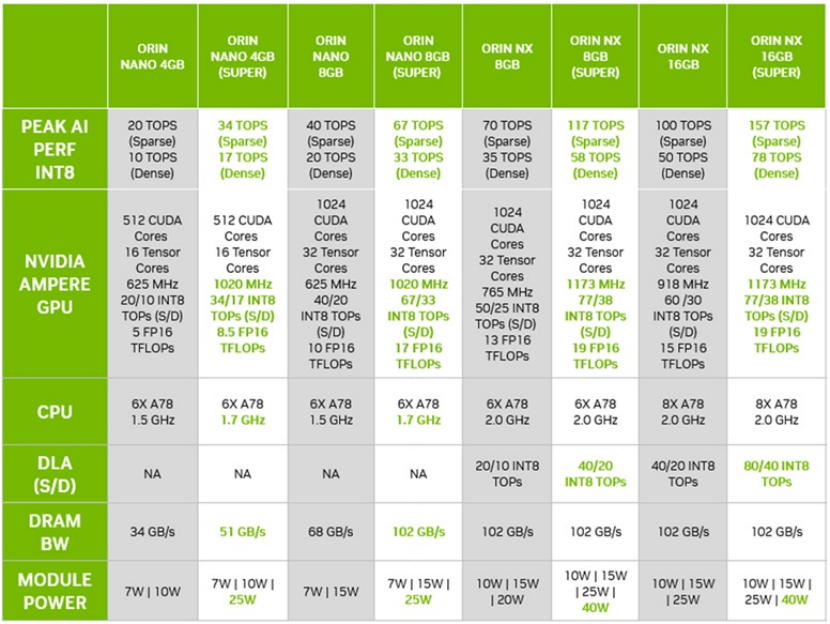
图片来源:NVIDIA
Nano实体开箱
接着笔者要拿出杀手锏了:世界知名的工业计算机制造商研华科技(Advantech)提供一台Jetson Orin Nano(EPC-R7300IF-ALA1NN)给笔者测试,这台Nano出场就已经改成Super模式了,不仅如此,现在因应各领域的AI流行趋势,目前正在全面特价中,现在就来开箱。

开箱后可以看到与一般开发板不同的地方,研华科技专业的工业计算机工艺让这台装置穿上厚厚的盔甲,抵抗工业生产环境的各种职业灾害。
拆掉上方的散热片,非常厚实,光是这个散热片就重达780g,可以说是用料实在,也可以发现整机不需要散热风扇,避免了风扇故障带来的风险。

前方面板则增加了SIM卡插槽及USB OTG,后续可以让装置直接升级到5G LTE网络基地台上网,对于部份没有Wi-Fi的厂区,可以说是非常好的方案。

后方面板则有双网络卡、HDMI、双USB3.0、及一个工业电源插头。

内部设计也可以见到研华科技的用心,都已经预留WiFi模块、5G LTE模块、SSD模块接口,让你扩充方便,适合所有的应用场域。

系统状态表开机后可以看到,本系统出厂都已经改成Super模式,下图为系统状态表,也可以看到MAXN选项已经出现。
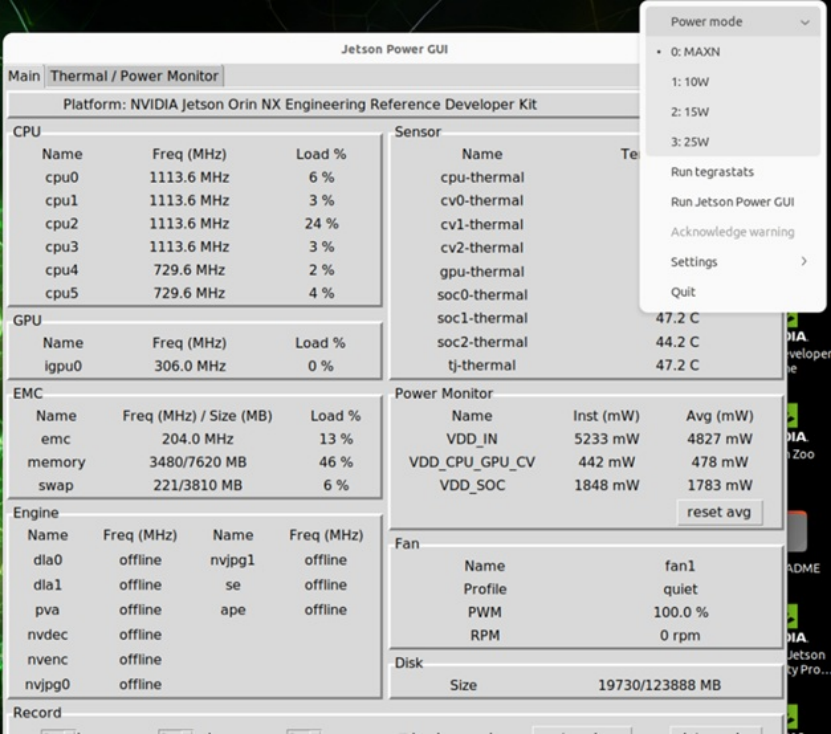
实测 Jetson Orin “Super” 效能提升
前面谈到Jetson Orin系列产品可以透过Super模式(MAXN)来大幅提升效能,我们就来测试看看效能到底提升了多少?本次实测将以目前最流行的LLM大型语言模型 -Llama-3.2,而效能比较的部分则分成Super模式、25W、15W进行全面的测试,由于笔者手上已经没有传统版Jetson Orin,因此就以15W模式做为传统板的基准进行分析。
本次使用Llama来测试边缘设备的效能,主要是因为Llama 3.2提供了轻量级的1B和3B版本,专为低功耗设备与移动应用最佳化,适合在边缘运算环境中进行推论测试。这些模型支援长达 128K 的上下文,使其能够处理较长的指令与数据,同时保持高效的推论速度。
此外,Llama的架构经过最佳化,可以在各种嵌入式系统或其他低功耗硬件上运作,让我们能够评估设备在实际应用中的运算能力、存储器占用与能耗表现。因此,透过 Llama 来测试边缘设备,不仅能检验其 AI 运算能力,也能验证Jetson Orin在资源受限环境下的稳定性与效能极限。
一、安装测试环境
首先我们安装Ollama。Ollama 是一个开源软件平台,允许使用者在本地计算机上运作LLM,无需依赖云端服务。提供强大功能的同时保持易用性,支持运作、管理和自订各种开源语言模型,包括 Llama 2、Mistral 和 CodeLlama。
我们将使用 Ollama 来运作 LLaMA 3.2 大型语言模型集合,作为基础聊天机器人。安装指令如下:
curl -fsSL https://ollama.com/install.sh | sh
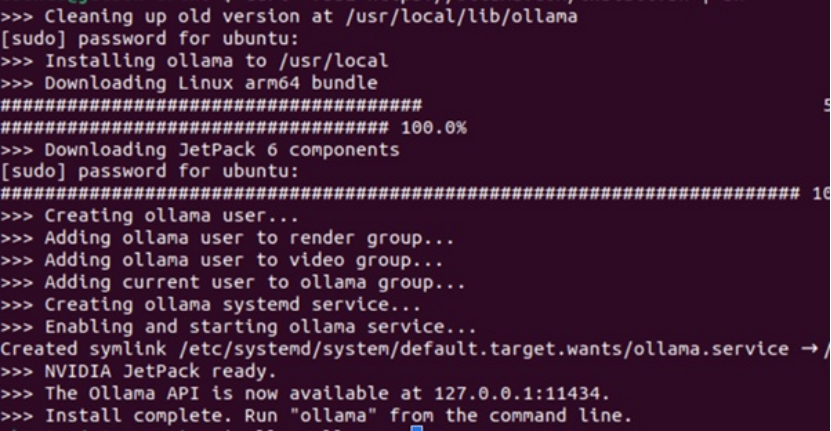
从上面的安装过程可以发现,Ollama安装时会先检测环境,并下载对应的版本,例如在安装过程中发现是JetPack 6就下载其对应的元件。
安装完毕后,就可以再指定要执行的模型,本次我们要执行的是llama3.2,执行指令如下:
ollama rum llama3.2
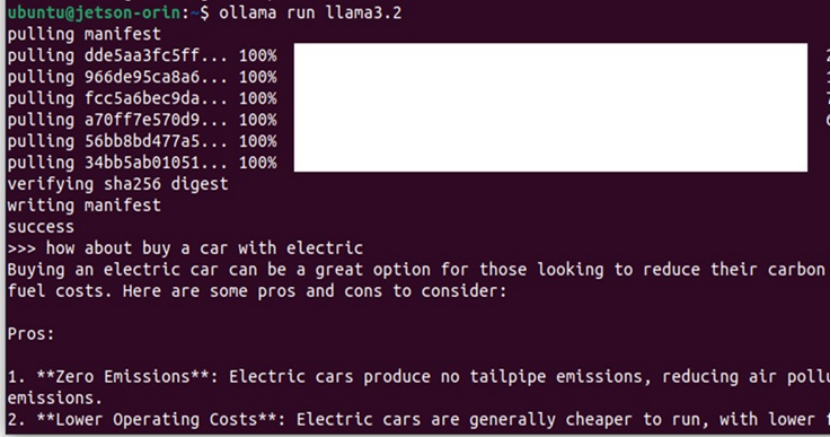
安装过程及执行过程
待执行完毕后,看到>>>的提示符号就可以开始对话了,我询问了一个问题是有关购买电动车的问题,后续就可以等候AI来尽情发挥了。
当环境安装完毕,就进入大家期待的环节,到底皮衣男黄仁勋口中的1.7倍效能的红包是真的还是假的呢?让我们实际动手测试看看。
二、开始测试
如前所述,我们将测试三个版本的功耗来模拟Super模式及传统模式,再来比较差异,虽然是非正规测试,我们还是保持公平性,1. 首先更换模式必须重新开机避免AI答题Cache的问题,2. 所有模式都会询问五个问题,问题有简单有复杂,并求其平均值,避免单一问题造成偏移问题。
本次测试的问题列表:
- hello world
- Who are you
- How about electric car
- What is CSS
- How about nuclear power plant
如需要Ollama提供其执行效能时,仅须在执行后方加入 –verbose即可,因此指令为:
ollama rum llama3.2 --verbose
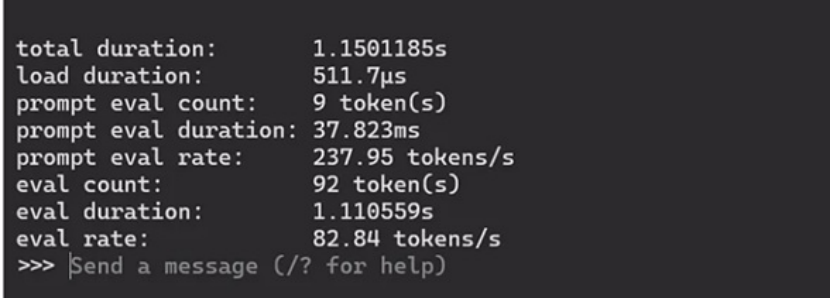
此后每个回答结束后,都会补上这次的执行效能。我们从中挑选四个重要的指标进行评估:
- Total duration 总时长:用以代表AI思考及回覆的总时间
- load duration载入时间:模型载入的时间
- prompt eval rate提示评估速度:理解问题时的速度,以Token/s来计算
- eval rate推理速度:生成答案时的速度,以Token/s来计算
以下为测试的结果列表(五题平均值)
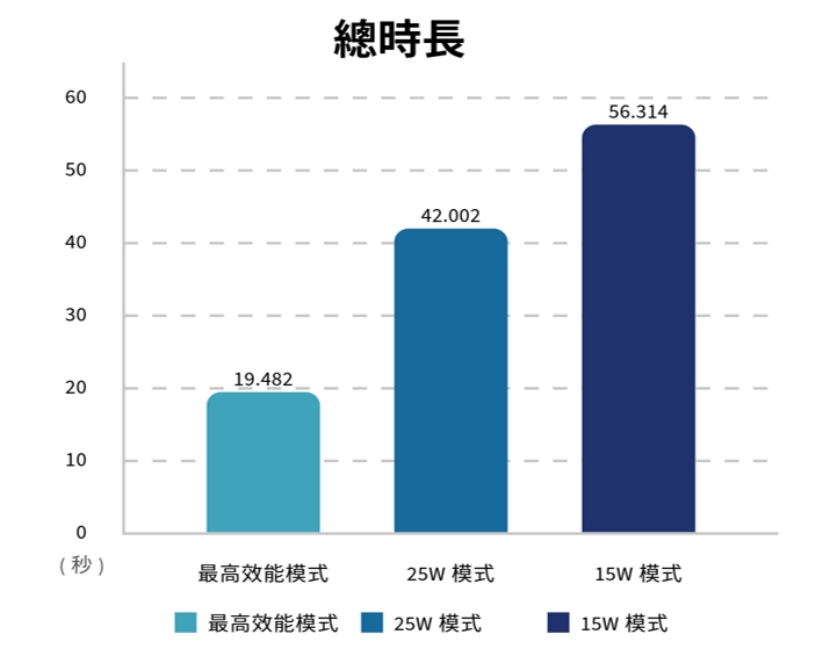
指标1:总时长
15W时,五个问题平均需要56秒,而25W仅需要42秒,最高效能则需要不到20秒钟,换算效能提升比例分别为25W:25.41%、MAXN:65.41%。本项目大致符合1.7倍的红包利多。
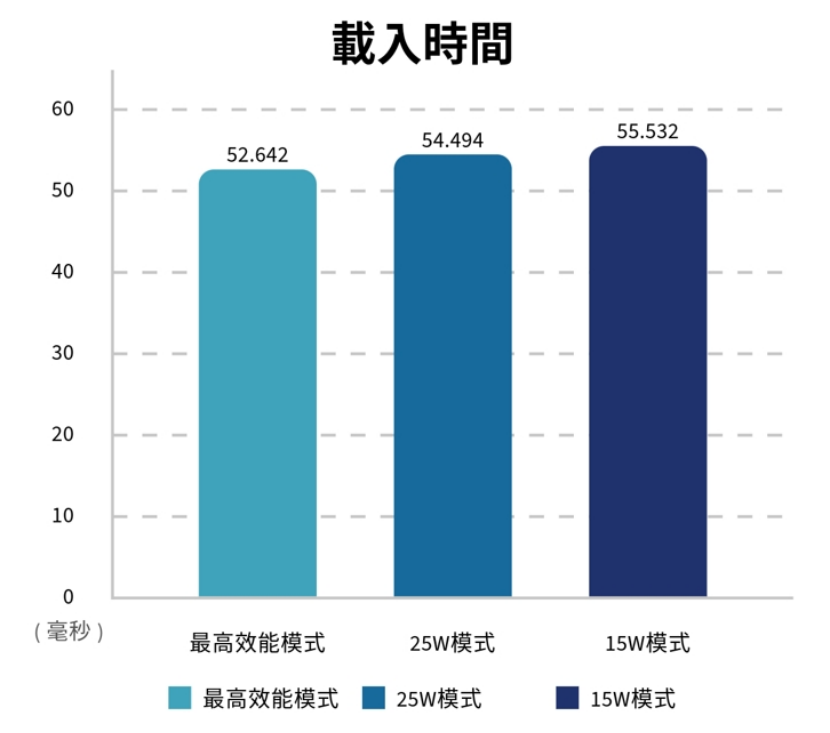
指标2:载入时间
本部份时间差异非常小,但依然可以看到MAXN与25W的效能都高过15W的传统模式。
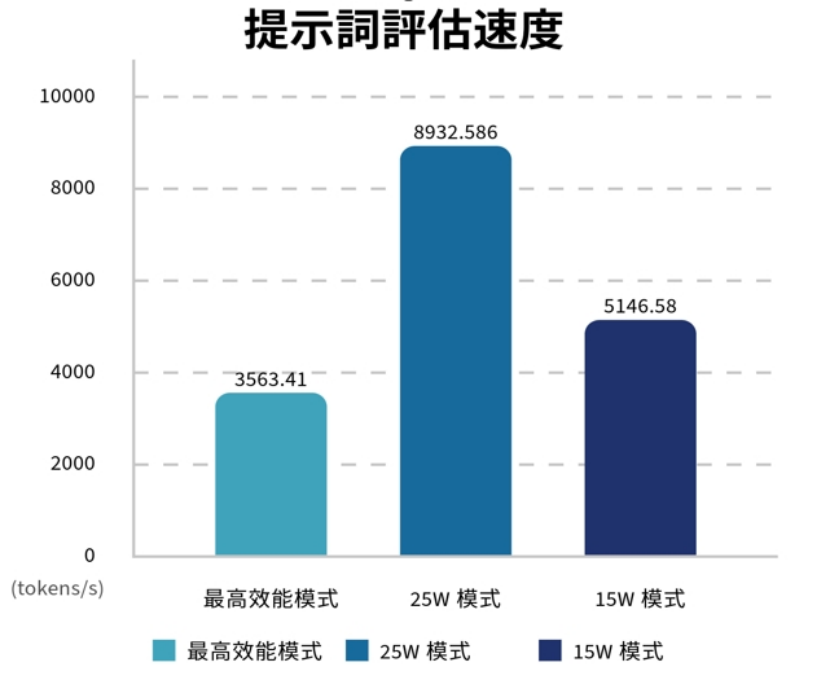
指标3:提示评估速度
本部份可以看到一个奇怪现象,虽然25W的效能高过15W的传统模式,但MAXN却大幅落后,这可能是因为样本数太少,或者其他问题导致,另外提示评估问题一般都不复杂,Token也不会使用太多,重要性不如指标4推理速度。
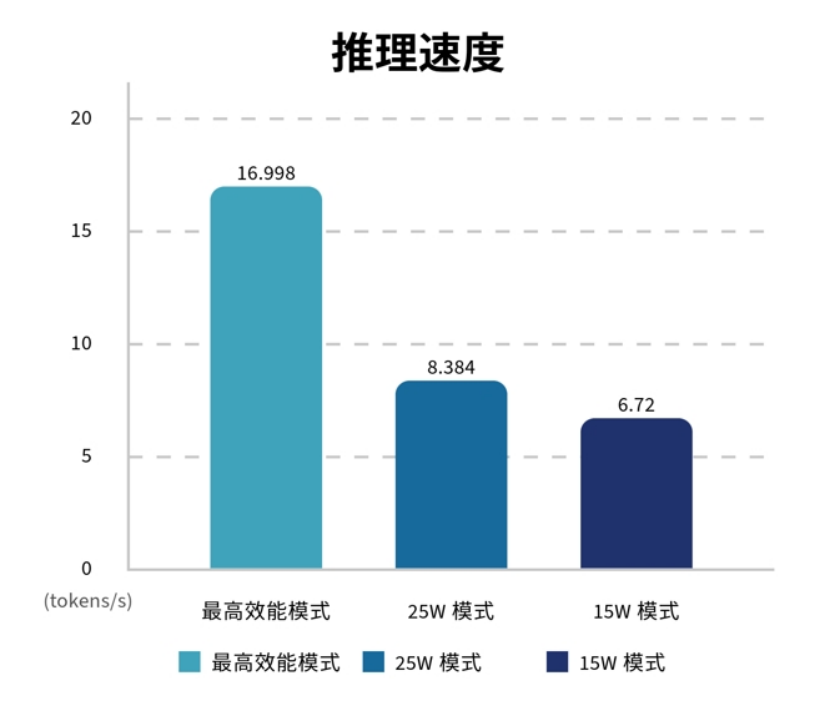
指标4:推理速度
推理速度可以说是LLM系统最重要的评估指标,因为「最伤脑筋思考」就属这部份了,而在本部份MAXN可以说大幅领先,25W则高过15W不多,换算效能提升比例的话,分别是25W:24.7%,MAXN:152.98%,这也算接近1.7倍效能提升。
效能测试小结
Jetson Orin 的Super模式(MAXN)确实带来了显著的效能提升,本文透过实测Llama 3.2语言模型,在15W、25W及MAXN三种模式下进行比较,分析AI推论的效能差异。
测试环境使用Ollama 作为 LLM 运行平台,Llama 3.2 具有轻量级设计,适合边缘运算环境。测试方法为五个固定问题,并记录四项关键指标:总时长、载入时间、提示评估速度及推理速度。结果显示,在MAXN模式下,总时长相较于15W模式缩短65.41%,推理速度提升152.98%,基本符合NVIDIA CEO 黄仁勋所称的1.7 倍效能提升。
虽然载入时间变化不大,且提示评估速度在 MAXN 模式下反而下降,可能是样本数或其他因素影响,但整体而言,Super 模式对LLM的推论效能提升显著,适合需要高效AI推论的边缘运算应用。
Jetson Orin在VLM的测试与应用
本篇文章的最后一部份我们来测试VLM的运用。
VLM(Vision Language Models,视觉语言模型)是结合影像和语言理解的AI模型,它的目标是让模型像人类一样,不仅能「看」到影像,还能理解影像的内容,并将其转化为语言描述。与传统的物件辨识模型(如YOLO、Faster R-CNN等)不同,这些模型专注于检测图像中的特定物体,进行物体定位和分类,而VLM则进行的是一种整体的图像理解。
例如,VLM不像传统物件侦测模型依赖图像中的物体外观来进行比对和分类,而是直接将整张图像视为一个整体,并尝试理解图像中的场景、结构和各种关联。它通过语言模型与视觉模型的结合,能够从图像中提取出更高层次的抽象信息,并生成对应的描述或推理。
举个例子,人类在看一张照片时,会先对整体的场景进行理解,然后再分析图像中的物体间的相互关系,例如:
- 场景识别:这是理解图像的大致环境,可能是街道、公园、餐厅等。
- 结构分析:理解图像中不同元素的关系。例如,两个人在交谈、一只狗在草地上跑等。
- 语境推理:模型不仅知道图像中的物体是什么,还能推测它们可能的动作或语境。
VLM的应用范围非常广泛,包括但不限于:
- 图像描述生成:根据图像生成自然语言的描述。
- 视觉问答:根据图片和问题回答具体问题。
- 图像-文本匹配:将图像与文本进行匹配或检索。
这些模型透过大量的资料训练,让模型学会将视觉和语言讯息结合起来,达到类似人类的视觉理解能力。
总结
本次测试验证了 VLM在 Jetson Nano Super上的运作潜力,并展现其在影像语意理解方面的强大能力。无论是人体辨识、交通流量分析,还是工地安全监测,VLM都能直接透过影像场景理解进行判断,而无需依赖传统的数据标记或特征提取方式。Jetson Nano Super作为低功耗 AI 边缘运算装置,在这些应用场景下表现稳定,能够有效处理实时影像分析需求,提升系统的灵活性与效率。由此可见,VLM 在Jetson Nano Super上的应用,未来可广泛用于智慧监控、行为分析与安全管理,值得进一步优化与开发。



















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









