




 本文详细介绍了正则表达式的基本语法和在Python中的使用,包括元字符、匹配模式、Python的re模块功能,如re.compile、re.match、re.search、re.split、re.findall、re.finditer和re.sub的用法,并通过示例代码演示了它们的实际操作。
本文详细介绍了正则表达式的基本语法和在Python中的使用,包括元字符、匹配模式、Python的re模块功能,如re.compile、re.match、re.search、re.split、re.findall、re.finditer和re.sub的用法,并通过示例代码演示了它们的实际操作。
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。本篇博客是基于:《Python爬虫开发与项目实战》一书的学习笔记。
基本语法与使用
如果想要匹配一个单词he,则使用“he”就可以匹配成功,同时因为正则忽略了大小写,所以“He”,“HE”和“hE”都会被匹配出来。然而,“here”、“header”等以“he”开头的词也会匹配出来。这时候为了保证准确性和唯一性,则需要使用正则表达式。
下面是正则表达式的常用元字符:
| 元字符 | 含义 |
|---|---|
| . | 除换行符外的任意字符 |
| \b | 匹配单词的开始或结束 |
| \d | 匹配数字 |
| \w | 匹配字母、数字、下划线或汉字 |
| \s | 匹配任意空白符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
则上面的“he”要进行匹配的话就要写成“\bhe\b”。现在网上已经有很多在线测试工具了,例如在线正则表达式测试。大家可以充分利用这些工具。
如果要查找“.”或者“*”这种具有特定功能的字符就会出错,所以要和平时我们编程写的一样,通过“\”这个来进行。比如www.baidu.com就要写成www.baidu.com。
如果要重复匹配某些特定的字符,则不可能一直重复写上面的元字符。这时候需要先将指定数量的代码写出来:
| 限定符 | 含义 |
|---|---|
| * | 重复0次或更多次 |
| + | 重复1次或更多次 |
| ? | 重复0次或1次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
例如“^\d{5,12}$”匹配5到12个数字的字符串,一般用于QQ号的匹配。但是也有很复杂的匹配,例如匹配IP地址,可以参考文章:详解一个自己原创的正则匹配IP的表达式。
如果想要查找某一类字符之外的字符,可以采用反义的方法。
| 代码 | 含义 |
|---|---|
| \B | 匹配不是单词的开始或结束的位置 |
| \D | 匹配非数字的字符 |
| \W | 匹配除字母、数字、下划线或汉字的字符 |
| \S | 匹配任意非空白符的字符 |
| [^ab] | 匹配除了a、b以外的字符 |
| [^(123|abc)] | 匹配除了1、2、3或者a、b、c以外的字符 |
在正则表达式中,有两种模式,通常是贪婪模式,即尽可能多地匹配字符。如“a\w+b”,如果有一串字符“a12345b7904”,那么贪婪模式下,会全部匹配,而不是只匹配“a12345b”。如果只想匹配出“a12345b”,那么就要用懒惰模式。将上面的表达式改为“a\w+?b”。使用“?”启动懒惰模式。
Python下的正则
Python通过re模块对正则表达式提供支持。一般步骤是先将正则表达式的字符串形式编译为pattern形式,然后使用pattern实例处理文本并获得匹配结果,最后使用match实例获得信息进行其他操作。
- re.compile
首先是利用re中的compile函数将一个正则表达式转化为pattern匹配对象。
import re
pattern = re.compile(r'\babc\b')- flag
flag是一个参数,在后面会看到它被用在各个函数中。flag是匹配模式的标志,取值可以用“|”使多个模式同时生效。
re.I忽略大小写;
…… - re.match
这个函数是从输入参数string开始,尝试匹配pattern,如果遇到无法匹配的字符或者达到string的末尾,则立即返回None,反之获得匹配结果。
import re
string1 = "2347892abc"
string2 = "abc805sljr"
string3 = "abc"
pattern = re.compile(r'\babc\b')
result1 = re.match(pattern,string1)
if result1:
print(result1.group())
else:
print("match error!")
result2 = re.match(pattern,string2)
if result2:
print(result2.group())
else:
print("match error again!")
result3 = re.match(pattern,string3)
if result3:
print(result3.group())
else:
print("match error again!")代码运行结果如下:

在pattern 中设置的是仅和'abc' 这三个字符相匹配,string1 中开头是一串数字,立马返回None;string2 是还掺杂着别的字符,所以也不匹配;而string3 中仅有'abc' 即匹配成功,利用group() 函数将值提取出来。如果将pattern = re.compile(r'\babc\b') 改成pattern = re.compile(r'abc') 则能与string2 匹配。
- re.search
与re.match类似,但是re.match是从字符串的头开始匹配,而re.search是查找整个字符串。将上面的代码稍作修改:
import re
string1 = "237894897345abc"
string2 = "abc792359234"
string3 = "abc"
pattern = re.compile(r'abc')
result1 = re.search(pattern,string1)
if result1:
print(result1.group())
else:
print("match error!")
result2 = re.search(pattern,string2)
if result2:
print(result2.group())
else:
print("match error again!")
result3 = re.search(pattern,string3)
if result3:
print(result3.group())
else:
print("match error again!")输出结果为:
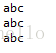
- re.split
按照pattern对字符串进行分割。
import re
string1 = "237894897345abc792345792"
pattern = re.compile(r'abc')
result1 = re.split(pattern,string1)
print(result1)运行结果如下:
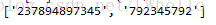
- re.findall
搜索所有的string, 以列表的形式返回。
import re
string1 = "237894897345abc792345792abchfskfhrehavdshdkfabc"
pattern = re.compile(r'abc')
result1 = re.findall(pattern,string1)
print(result1)运行结果如下:
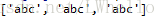
- re.finditer
搜索整个string,以迭代器的形式返回。
string1 = "237894897345abc792345792abchfskfhrehavdshdkfabc"
pattern = re.compile(r'abc')
result1 = re.finditer(pattern,string1)
print(result1)
这样会看到下面的结果:
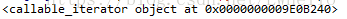
因为迭代器要一个个打印,所以写成下面形式:
for result in result1:
print(result.group())- re.sub
替换string中匹配的字符串并返回替换后的字符串。
import re
string1 = "237894897345abc792345792abchfskfhrehavdshdkfabc"
pattern = re.compile(r'abc')
result1 = re.sub(pattern,'lili',string1)
print(result1)打印的结果如下:
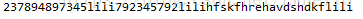

















 3810
3810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









