




1.集合初始化器
集合初始化器允许采用和数组声明类似的方式,在集合实例化期间用一组初始成员构造该集合。
List<string> strList = new List<string>()
{
"Apple", "Orange", "Pear"
};
如果不使用集合初始化器,就只能实例化集合后,调用ICollection<T>的Add()方法一个一个添加成员。事实上,使用集合初始化器时,编译器会自动生成Add语句,从而不需要开发者显式编码。也因如此,要想使用集合初始化器,就需要满足以下条件的其中一个:
(1)集合类型应该实现ICollection<T>接口,从而确保集合包含Add()方法。
(2)集合类型也可以只实现IEnumerable<T>接口而不实现ICollection<T>接口,但要将一个或多个Add()方法定义成接口扩展方法或集合类型的实例方法。
2.集合接口
下图展示了集合类实现接口的层次结构:
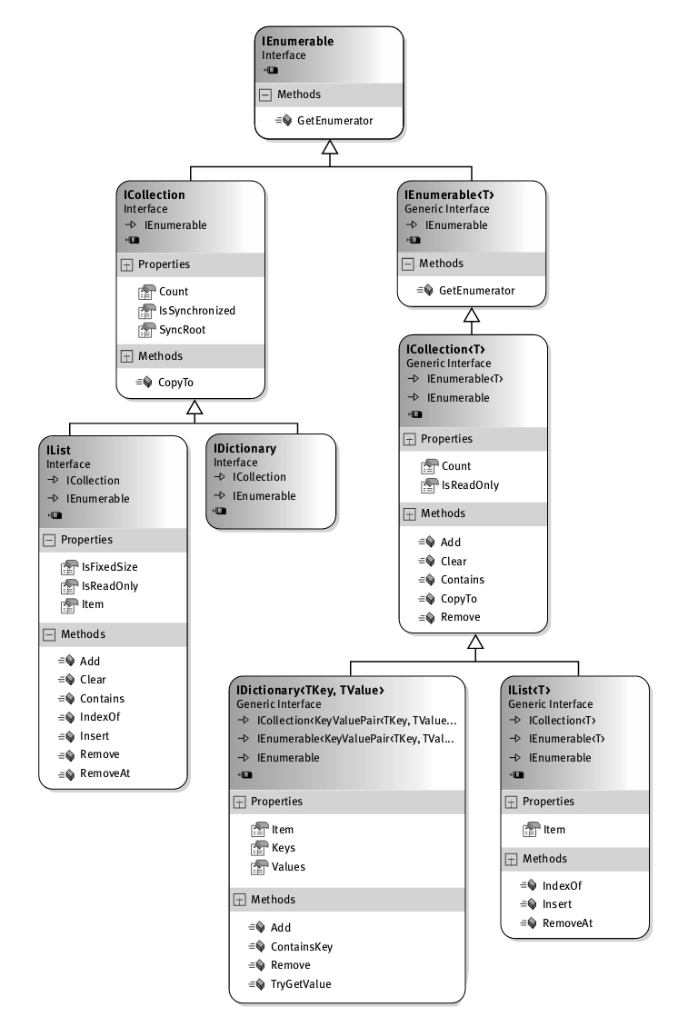
IList<T>和IDictionary<TKey,TValue>接口
这两个接口决定了集合类型是侧重于通过位置索引来获取值,还是侧重于通过”键“来获取值。实现这两个接口的类必须提供索引器。对于IList<T>,索引器的操作数是要获取的元素的位置。对于IDictionary<TKey,TValue>,索引器的操作数是和值关联的键。
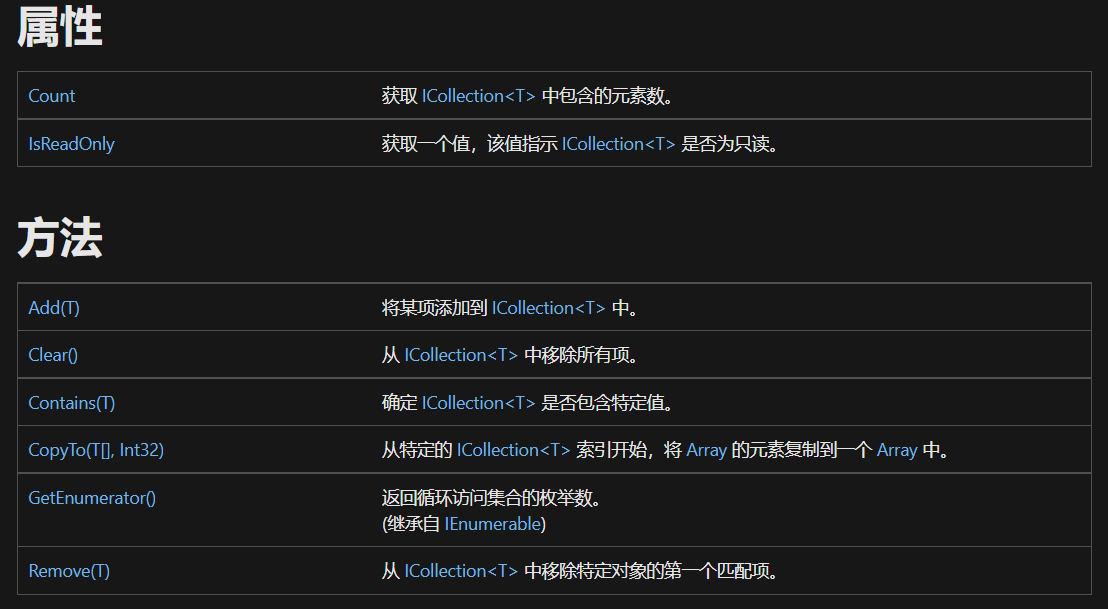
ICollection<T>接口
上面的两个接口都实现了ICollection<T>接口。它包含如下成员:
IEnumerable<T>接口
.NET集合本质上是一个类,且至少实现了IEnumerable接口,因为这个接口提供了遍历集合所必须的方法。
当我们对一个数组使用foreach遍历时,C#编译器会将其转换成一个等价的for循环,类似于下面这样:
// 转换前
int[] arr = new[] { 1,2,3,4 };
foreach (int i in arr)
{
Console.WriteLine(i);
}
// 转换后
int[] tempArr;
int[] arr = new[] {1, 2, 3, 4};
tempArr = arr;
for (int counter = 0; counter < tempArr.Length; counter++)
{
int item = tempArr[counter];
Console.WriteLine(item);
}
由此可见,foreach语句需要Length属性和数组索引操作符的支持。这对于数组来说没问题,但并不是所有集合都像数组那样长度已知,另外也存在很多不支持按索引检索的集合类型,如Stack<T>、Queue<T>等。像这样的集合遍历就需要用到迭代器模式,即只要确定第一个和下一个元素,就不需要事先知道元素的总数,也就不需要按索引获取元素。
IEnumerable<T>接口的设计目的就是允许使用迭代器遍历集合元素,而不需要索引模式。IEnumerable<T>接口中只有一个方法GetEnumerator(),它的作用是返回一个IEnumerator<T>对象,这个对象才是真正的迭代器。IEnumerator<T>从IEnumerator派生而来,后者包含了三个成员:只读属性Current,MoveNext()方法和Reset()方法。Current用来返回当前元素。MoveNext()从当前元素移动到下一个元素,同时检测是否已遍历完集合中的每个元素。利用这两个成员,就可以实现对集合的遍历。
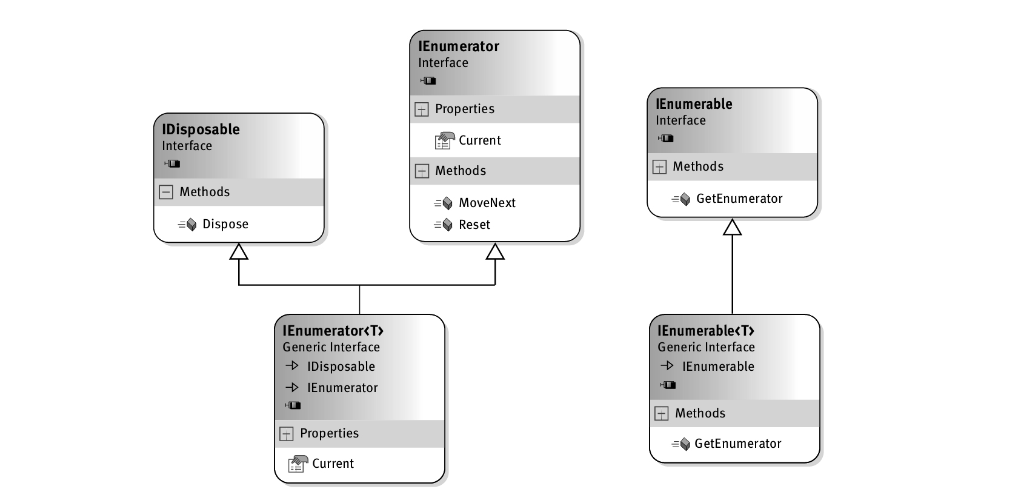
为什么集合类不直接支持IEnumerator<T>和IEnumerator接口,而是支持IEnumerable<T>接口呢?为了理解这个问题,可以设想一个场景:如果有两个循环交错遍历同一个集合会发生什么问题?显然,Current并不能同时指示两个不同的元素,而MoveNext()也无法正确定位到下一个元素,这就造成了交错循环间的相互干扰。为了解决这个问题,集合类不直接支持IEnumerator<T>和IEnumerator,而是通过IEnumerable<T>的GetEnumerator()方法返回一个支持IEnumerator<T>的对象,通过这个第三方的对象,维护循环遍历的状态。这个对象就像是游标,在同一时间,可以存在多个游标,且游标之间互不干扰。
当退出循环或在循环过程中抛出了异常,就需要对状态进行清理。事实上IEnumerator<T>接口也支持了IDisposable接口。当循环结束后就会调用该接口中的Dispose()方法,来清理循环状态。
(扩展:事实上C#编译器不要求一定要实现IEnumerable<T>接口才能对一个数据类型进行遍历。编译器只需要能查找到返回「包含Current属性和MoveNext()方法的一个类型」的GetEnumerator()方法即可)
3.集合类
C#共有5种主要的集合类,分别是List<T>、Dictionary<TKey, TValue>、Stack<T>、Queue<T>和LinkedList<T>,它们的区别在于数据的插入、存储和获取方式。这里只介绍前两种比较有代表性的集合类。
列表集合List<T>
(1)添加
List<T>的性质与数组类似,区别在于随着元素增多,这种类会自动扩展。
List<T>内部用于存储数据的是一个数组,当我们调用该类的无参构造方法时,会将该数组的指针指向一个事先准备好的长度为0的数组
//...
internal T[] _items;
private static readonly T[] s_emptyArray = new T[0];
public List()
{
_items = s_emptyArray;
}
//...
当向集合中添加元素时,会判断当前数组是否已满,如果处于满的状态,就会进行扩容操作。
//...
public void Add(T item)
{
_version++;
T[] array = _items;
int size = _size;
if ((uint)size < (uint)array.Length)
{
_size = size + 1;
array[size] = item;
}
else
{
// 如果超长就扩容
AddWithResize(item);
}
}
private void AddWithResize(T item)
{
Debug.Assert(_size == _items.Length);
int size = _size;
// 调用扩容方法
Grow(size + 1);
_size = size + 1;
_items[size] = item;
}
private void Grow(int capacity)
{
Debug.Assert(_items.Length < capacity);
// 如果当前数组长度为0,则新的长度取默认长度(4),否则就直接翻倍
int newcapacity = _items.Length == 0 ? DefaultCapacity : 2 * _items.Length;
// 如果新的长度超过了数组的最大长度(2147483591),则赋值为数组最大长度
if ((uint)newcapacity > Array.MaxLength) newcapacity = Array.MaxLength;
// 如果新的长度还是小于要求的长度,则直接赋值成要求的长度
if (newcapacity < capacity) newcapacity = capacity;
Capacity = newcapacity;
}
//...
(2)排序
当我们需要对List<T>中的元素进行排序,可以调用其中的Sort()方法。它要求元素类型实现了IComparable<T>接口或通过参数传入一个IComparer<T>作为实参:
// 实现IComparable<T>版本
class Student:IComparable<Student>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public int CompareTo(Student? other)
{
if (other is null)
{
return 1;
}
return Age - other.Age;
}
public override string ToString()
{
return $"{FirstName}{LastName} {Age}岁";
}
}
public static void ListPracticeMain()
{
List<Student> stuList = new List<Student>()
{
new Student() {FirstName = "张", LastName = "小明", Age = 16},
new Student() {FirstName = "李", LastName = "小红", Age = 15},
new Student() {FirstName = "刘", LastName = "小鹏", Age = 19}
};
stuList.Sort();
Console.WriteLine(stuList[0]);
Console.WriteLine(stuList[1]);
Console.WriteLine(stuList[2]);
}
// 输出结果
// 李小红 15岁
// 张小明 16岁
// 刘小鹏 19岁
// 传入IComparer<T>参数版本
class NameComparison:IComparer<Student>
{
public int Compare(Student? x, Student? y)
{
if (ReferenceEquals(x, y)) return 0;
if (x is null) return 1;
if (y is null) return -1;
int result = String.Compare(x.LastName, y.LastName, StringComparison.Ordinal);
if (result == 0)
result = String.Compare(x.FirstName, y.FirstName, StringComparison.Ordinal);
return result;
}
}
public static void ListPracticeMain()
{
List<Student> stuList = new List<Student>()
{
new Student() {FirstName = "张", LastName = "小明", Age = 16},
new Student() {FirstName = "李", LastName = "小红", Age = 15},
new Student() {FirstName = "刘", LastName = "小鹏", Age = 19}
};
stuList.Sort(new NameComparison());
Console.WriteLine(stuList[0]);
Console.WriteLine(stuList[1]);
Console.WriteLine(stuList[2]);
}
// 输出结果
// 张小明 16岁
// 李小红 15岁
// 刘小鹏 19岁
无论是上面哪种实现方法,都必须能生成一个全序,即CompareTo的实现必须为任何可能的数据项排列组合提供一致的排序结果。例如如果任何一个实参是null就返回0的话,就可能出现「两个非null元素等于null但不互等」的情况。
(3)删除
当调用删除方法删除集合中的某个元素时,底层会调用Array.Copy(),将删除的元素后续的值全都向前挪一位。因此,当通过循环遍历集合时删除元素,会造成指针指向预期之外的元素位置。如果必须要在循环中删除元素,那么一定要从尾部开始遍历。
字典集合Dictionary<TKey, TValue>
Dictionary<TKey, TValue>中最重要的字段是int[]? _buckets、Entry[]? _entries和IEqualityComparer<TKey>? _comparer。_buckets中的一个元素保存的是指向_entries中某个Entry实例的地址。Entry的结构如下:
private struct Entry
{
public uint hashCode;
public int next;
public TKey key; // Key of entry
public TValue value; // Value of entry
}
可以看到,它实际上是一个链表,next指向的是下一个实例在数组中存储的位置。
(1)添加
当我们向字典中添加元素时,C#会获取Key的哈希值,并将其映射到_buckets中的对应位置。然后在_entries中创建一个新的实例,并在_buckets中存储新实例的下标。由于_buckets的长度有限,因此会存在哈希碰撞的问题。当发生碰撞时,就将新的Entry采用头插法,插入到原Entry的前面。
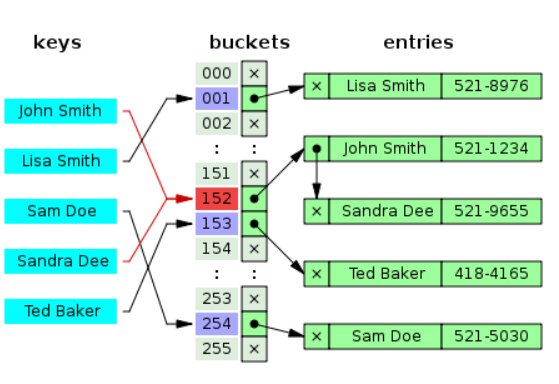
当_entries数组装满时,就需要对其进行扩容操作。实时上,对_entries和_buckets的扩容操作是同时进行的。在进行扩容时,会对当前的数组长度×2,然后找到比得到的值大的最近的一个素数,将其作为新数组的长度。扩容完成后,由于_buckets的长度改变,所以要对所有元素的哈希值重新进行取模运算,然后更新到_buckets上,同时重新设置_entries中元素的next字段。
(2)查找与删除
在字典中无论是查询还是删除,都需要根据Key值找到对应的Value。C#首先会计算出Key的哈希值,通过哈希值找到对应的_buckets上的元素,然后就得到了对应的Entry的位置。但是如果发生了哈希碰撞,得到的Entry就是个链表,链表上的Entry的hashCode都是相同的。那么如何才能找出要查询的Key呢?答案是通过IEqualityComparer<T>类型的比较器判断。如果在实例化Dictionary时没有指定比较器,C#就会使用默认的比较器,即值类型检查两者是否包含了相同的数据,引用类型检查是否引用了同一个对象。我们当然也可以通过实现IEqualityComparer<T>接口来自定义一个比较器,代码如下:
public static void DictionaryPracticeMain()
{
Dictionary<Student, string> dic = new Dictionary<Student, string>(new StudentEquality())
{
[new Student() {Age = 10, Name = "Jack"}] = "Jack",
[new Student() {Age = 10, Name = "Rose"}] = "Rose",
[new Student() {Age = 11, Name = "Jack"}] = "Jack"
};
// 输出 Rose
Console.WriteLine(dic[new Student(){Age = 10,Name = "Jack"}]);
}
class Student
{
public int Age { get; set; }
public string Name { get; set; }
}
class StudentEquality : IEqualityComparer<Student>
{
public bool Equals(Student? x, Student? y)
{
if (x is null || y is null) return false;
return x.Age == y.Age;
}
public int GetHashCode(Student obj)
{
if (obj is null) return 0;
return obj.Age.GetHashCode();
}
}
上面代码中,我们传入的比较器只根据Age来判断两个实例是否相等,而哈希值也是根据Age获取,因此先插入的“Jack”与后插入的“Rose”实际上是相同的Key,因而前者被覆盖了。在自定义字典相等性时,尤其需要注意的是:如果Equals()为两个对象返回了true,那么GetHashCode()也必须为同样的对象返回相同的值。 这也是实现IEqualityComparer<T>接口需要同时实现Equals()和GetHashCode()的原因。
参考文献:
[1]马克·米凯利斯.C#8.0本质论[M].机械工业出版社.

















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









