




 本文深入分析Spark Structured Streaming的StreamExecution,特别是MicroBatchExecution的初始化和流处理逻辑。从StreamingQueryManager启动流,到StreamExecution的runActivatedStream()方法在MicroBatchExecution中的实现,探讨了offsets、commits目录的内容,以及如何恢复流处理进度。
本文深入分析Spark Structured Streaming的StreamExecution,特别是MicroBatchExecution的初始化和流处理逻辑。从StreamingQueryManager启动流,到StreamExecution的runActivatedStream()方法在MicroBatchExecution中的实现,探讨了offsets、commits目录的内容,以及如何恢复流处理进度。
一、StreamingQueryManager创建流并启动
接一篇文章创建流的Source、Sink
在创建Sink后,会调用sessionState.streamingQueryManager.startQuery()创建并启动流,
对应的StreamQueryManager启动流程图为:

startQuery()、createQuery()主要代码:
class StreamingQueryManager private[sql] (sparkSession: SparkSession) extends Logging {
private[sql] def startQuery(
userSpecifiedName: Option[String],
userSpecifiedCheckpointLocation: Option[String],
df: DataFrame,
extraOptions: Map[String, String],
sink: BaseStreamingSink,
outputMode: OutputMode,
useTempCheckpointLocation: Boolean = false,
recoverFromCheckpointLocation: Boolean = true,
trigger: Trigger = ProcessingTime(0),
triggerClock: Clock = new SystemClock()): StreamingQuery = {
val query = createQuery(
userSpecifiedName,
userSpecifiedCheckpointLocation,
df,
extraOptions,
sink,
outputMode,
useTempCheckpointLocation,
recoverFromCheckpointLocation,
trigger,
triggerClock)
activeQueries.put(query.id, query)
}
try {
query.streamingQuery.start()
} catch {
case e: Throwable =>
activeQueriesLock.synchronized {
activeQueries -= query.id
}
throw e
}
query
}
private def createQuery(
userSpecifiedName: Option[String],
userSpecifiedCheckpointLocation: Option[String],
df: DataFrame,
extraOptions: Map[String, String],
sink: BaseStreamingSink,
outputMode: OutputMode,
useTempCheckpointLocation: Boolean,
recoverFromCheckpointLocation: Boolean,
trigger: Trigger,
triggerClock: Clock): StreamingQueryWrapper = {
var streamExecutionCls = extraOptions.getOrElse("stream.execution.class", "")
var deleteCheckpointOnStop = false
val checkpointLocation = userSpecifiedCheckpointLocation.map { userSpecified =>
new Path(userSpecified).toUri.toString
}.orElse {
xxxx
}
}
val analyzedPlan = df.queryExecution.analyzed
df.queryExecution.assertAnalyzed()
if (sparkSession.sessionState.conf.isUnsupportedOperationCheckEnabled) {
UnsupportedOperationChecker.checkForStreaming(analyzedPlan, outputMode)
}
if (sparkSession.sessionState.conf.adaptiveExecutionEnabled) {
logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} " +
"is not supported in streaming DataFrames/Datasets and will be disabled.")
}
var streamingQueryWrapper: StreamingQueryWrapper = null
if (streamExecutionCls.length > 0) {
val cls = Utils.classForName(streamExecutionCls)
val constructor = cls.getConstructor(
classOf[SparkSession],
classOf[String],
classOf[String],
classOf[LogicalPlan],
classOf[BaseStreamingSink],
classOf[Trigger],
classOf[Clock],
classOf[OutputMode],
classOf[Map[String, String]],
classOf[Boolean])
val streamExecution = constructor.newInstance(
sparkSession,
userSpecifiedName.orNull,
checkpointLocation,
analyzedPlan,
sink,
trigger,
triggerClock,
outputMode,
extraOptions,
new java.lang.Boolean(deleteCheckpointOnStop)).asInstanceOf[StreamExecution]
streamingQueryWrapper = new StreamingQueryWrapper(streamExecution)
} else {
streamingQueryWrapper = (sink, trigger) match {
case (v2Sink: StreamWriteSupport, trigger: ContinuousTrigger) =>
UnsupportedOperationChecker.checkForContinuous(analyzedPlan, outputMode)
new StreamingQueryWrapper(new ContinuousExecution(
sparkSession,
userSpecifiedName.orNull,
checkpointLocation,
analyzedPlan,
v2Sink,
trigger,
triggerClock,
outputMode,
extraOptions,
deleteCheckpointOnStop))
case _ =>
new StreamingQueryWrapper(new MicroBatchExecution(
sparkSession,
userSpecifiedName.orNull,
checkpointLocation,
analyzedPlan,
sink,
trigger,
triggerClock,
outputMode,
extraOptions,
deleteCheckpointOnStop))
}
}
streamingQueryWrapper
}
}二、StreamExecution的初始化
1、 StreamExecution源码分析
StreamQueryManager.startQuery()最后一步描述的query.streamingQuery.start()即真正创建StreamExecution的流处理线程:
abstract class StreamExecution(xxxxx)
extends StreamingQuery with ProgressReporter with Logging {
def start(): Unit = {
logInfo(s"Starting $prettyIdString. Use $resolvedCheckpointRoot to store the query checkpoint.")
queryExecutionThread.setDaemon(true)
queryExecutionThread.start()
startLatch.await() // Wait until thread started and QueryStart event has been posted
}
}实际是执行queryExecutionThread的run()方法:
val queryExecutionThread: QueryExecutionThread =
new QueryExecutionThread(s"stream execution thread for $prettyIdString") {
override def run(): Unit = {
// To fix call site like "run at <unknown>:0", we bridge the call site from the caller
// thread to this micro batch thread
sparkSession.sparkContext.setCallSite(callSite)
runStream()
}
}runStream()分为环境的初始化、启动和执行过程中的异常处理try{…}catch{…}结构、其核心方法是runActivatedStream(sparkSessionForStream),具体的实现在MicroBatchExecution(批量处理)、ContinuousExecution(连续处理)这个两个子类中均有各自具体的实现。
runStream()流程:
· 创建metics
· postEvent(id, runId, name)向listenBus发送启动事件Event
· 设置其它conf变量
· runActivatedStream(sparkSessionForStream)执行MicroBatchExecution或ContinousExecution的runActivatedStream(),持续查询流
· 使用try{…}catch{…}获取启动和运行过程异常
2、 StreamExecution的子类实现:override runActivatedStream()
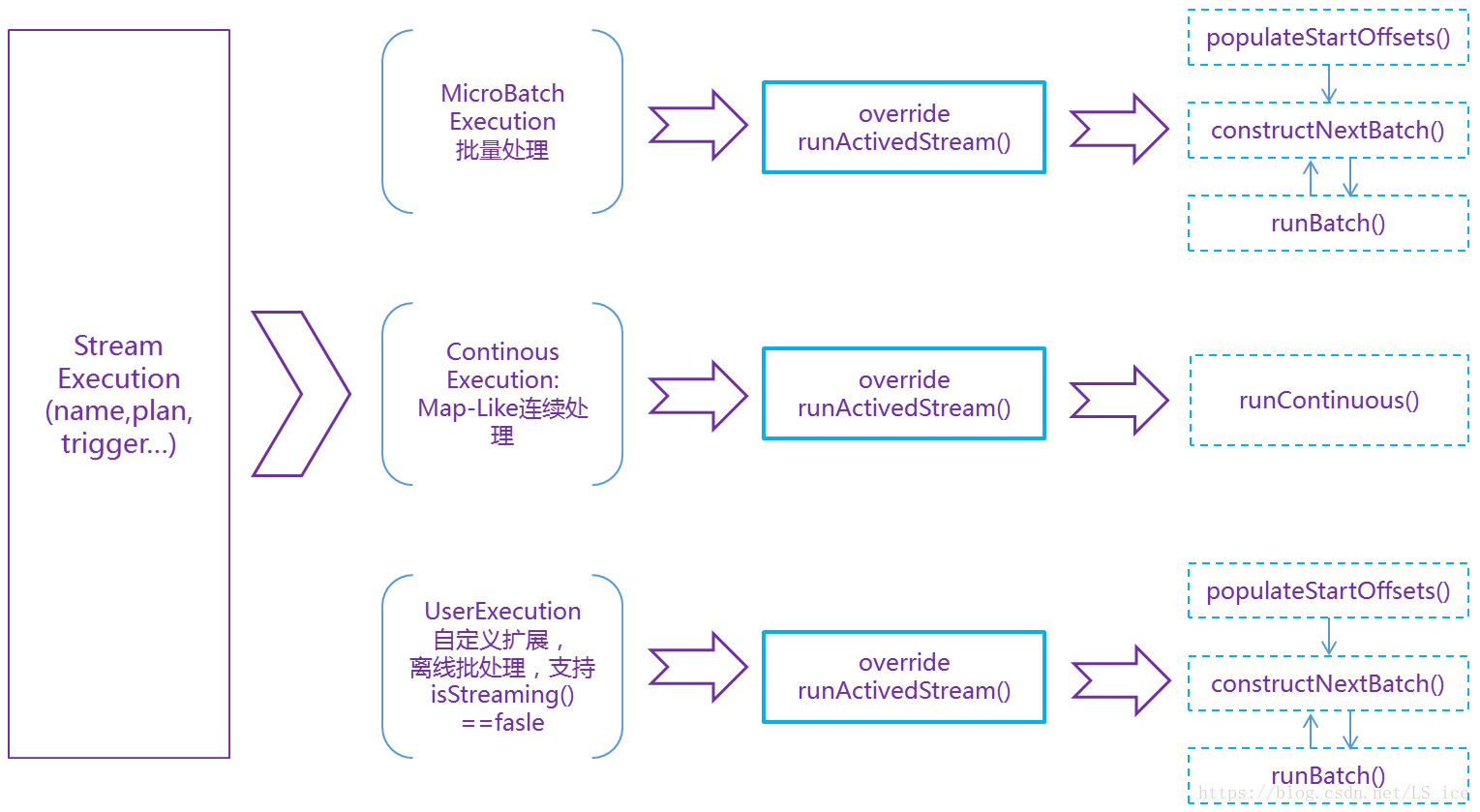
StreamExecution的子类:
I、MicroBatchExecution:我们现有项目中主要使用MicroBatchExecution处理流
II、 CountinousExecution:连续处理,目前spark只支持Map-Like的操作,使用场景较少
III、UserExecution,扩展实现,删除了watermark的相关计算,同时dataframe的属性修改为isStreaming==fasle,以支持离线数据持续处理
其它一些Execution内部相关的修改:
I、 实现MemorySinkExtend、DistributeSink(缓存数据到BlockManager) ·
II、配置SparkPlanGraphWrapper的存储机制解决内存泄露问题等
三、MicroBatchExecution批量流处理分析
1、MicroBatchExecution的成员变量
- 构造函数:
class MicroBatchExecution(
//spark上下文
sparkSession: SparkSession,
/**dataStreamWriter.queryName(name)设置的内容,可以用来标识流的名称
* MemorySink会将这个名称关联为一个table,用来查询其持有的数据*/
name: String,
/**dataStreamWriter.option("checkPointLocation", "hdfs://xxxx")设置的路径
*用于存储流计算source、offset、commit、state等WAL计算进度和版本信息*/
checkpointRoot: String,
//resolved逻辑执行计划,类似于DAG,在流计算执行过程中
//source节点会被替换为具体的dataframe数据,后面会详细分析
analyzedPlan: LogicalPlan,
sink: BaseStreamingSink, //流的输出端,只能有一个
trigger: Trigger, //流的执行周期
triggerClock: Clock, //获取系统时间,重写waitTillTime()方法,按Trigger设定的时间,实现sleep()逻辑
//dataStreamWriter.outputMode(mode)设置的输出模式,有Update、Append、Complete三种类型
outputMode: OutputMode,
/**用户通过dataStreamWriter.option(key, value)设置的所有参数,一般会被具体的Sink用到,
*例如KafkaSink的server地址,topic名,以及FileStreamSink的写文件目录*/
extraOptions: Map[String, String],
deleteCheckpointOnStop: Boolean)
extends StreamExecution(
sparkSession, name, checkpointRoot, analyzedPlan, sink,
trigger, triggerClock, outputMode, deleteCheckpointOnStop){}- logicalPlan:根据analyzedPlan创建logicalPlan,其中一个重要的动作是创建source,并存放在StreamingExecutionRelation中,端到端流一般是一个source,流与流进行join则有两个source,源码及注释:
override lazy val logicalPlan: LogicalPlan = {
var nextSourceId = 0L
//StreamingRelation与StreamingExecutionRelation的map映射
val toExecutionRelationMap = MutableMap[StreamingRelation, StreamingExecutionRelation]()
val v2ToExecutionRelationMap = MutableMap[StreamingRelationV2, StreamingExecutionRelation]()
/**对analyzedPlan进行transform操作,即遍历每个child节点,
*如果节点为StreamingRelation、StreamingRelationV2类型(在DataSteamReader.load()方法中创建,
*前面文章有分析,一般常用的为StreamingRelation),则替换为统一的StreamingExecutionRelation
*StreamingExecutionRelation的作用是将每个批次的增量数据newData: Map[BaseStreamingSource, LogicalPlan],
*按source替换为新的newBatchesPlan,并执行查询*/
val _logicalPlan = analyzedPlan.transform {
case streamingRelation@StreamingRelation(dataSource, _, output) =>
toExecutionRelationMap.getOrElseUpdate(streamingRelation, {
// Materialize source to avoid creating it in every batch
val metadataPath = s"$resolvedCheckpointRoot/sources/$nextSourceId"
//调用DataSource提供的方法,创建Source,实现了StreamSourceProvider接口的自定义Provider也是在这里调用
val source = dataSource.createSource(metadataPath)
nextSourceId += 1
StreamingExecutionRelation(source, output)(sparkSession)
})
case s@StreamingRelationV2(source: MicroBatchReadSupport, _, options, output, _) =>
v2ToExecutionRelationMap.getOrElseUpdate(s, {
// Materialize source to avoid creating it in every batch
val metadataPath = s"$resolvedCheckpointRoot/sources/$nextSourceId"
val reader = source.createMicroBatchReader(
Optional.empty(), // user specified schema
metadataPath,
new DataSourceOptions(options.asJava))
nextSourceId += 1
StreamingExecutionRelation(reader, output)(sparkSession)
})
case s@StreamingRelationV2(_, sourceName, _, output, v1Relation) =>
v2ToExecutionRelationMap.getOrElseUpdate(s, {
// Materialize source to avoid creating it in every batch
val metadataPath = s"$resolvedCheckpointRoot/sources/$nextSourceId"
if (v1Relation.isEmpty) {
throw new UnsupportedOperationException(
s"Data source $sourceName does not support microbatch processing.")
}
//使用v2Relation包装过的v1Relation,仍然调用DataSource提供的方法,创建Source
val source = v1Relation.get.dataSource.createSource(metadataPath)
nextSourceId += 1
StreamingExecutionRelation(source, output)(sparkSession)
})
}
//将逻辑执行计划中所有source存入Seq列表中
sources = _logicalPlan.collect { case s: StreamingExecutionRelation => s.source }
uniqueSources = sources.distinct
//返回transform后,带有StreamingExecutionRelation的执行计划
_logicalPlan
}- triggerExecutor:以设定的时间周期,执行流处理,具体实现类为ProcessingTimeExecutor
private val triggerExecutor = trigger match {
/**ProcessingTimeExecutor主要方法是execute(triggerHandler: () => Boolean)
*按设定的intervalMs执行triggerHandler方法,即runActiveStream()中的流处理*/
case t: ProcessingTime => ProcessingTimeExecutor(t, triggerClock)
case OneTimeTrigger => OneTimeExecutor()
case _ => throw new IllegalStateException(s"Unknown type of trigger: $trigger")
}2、runActivatedStream执行每批次流处理的整体逻辑
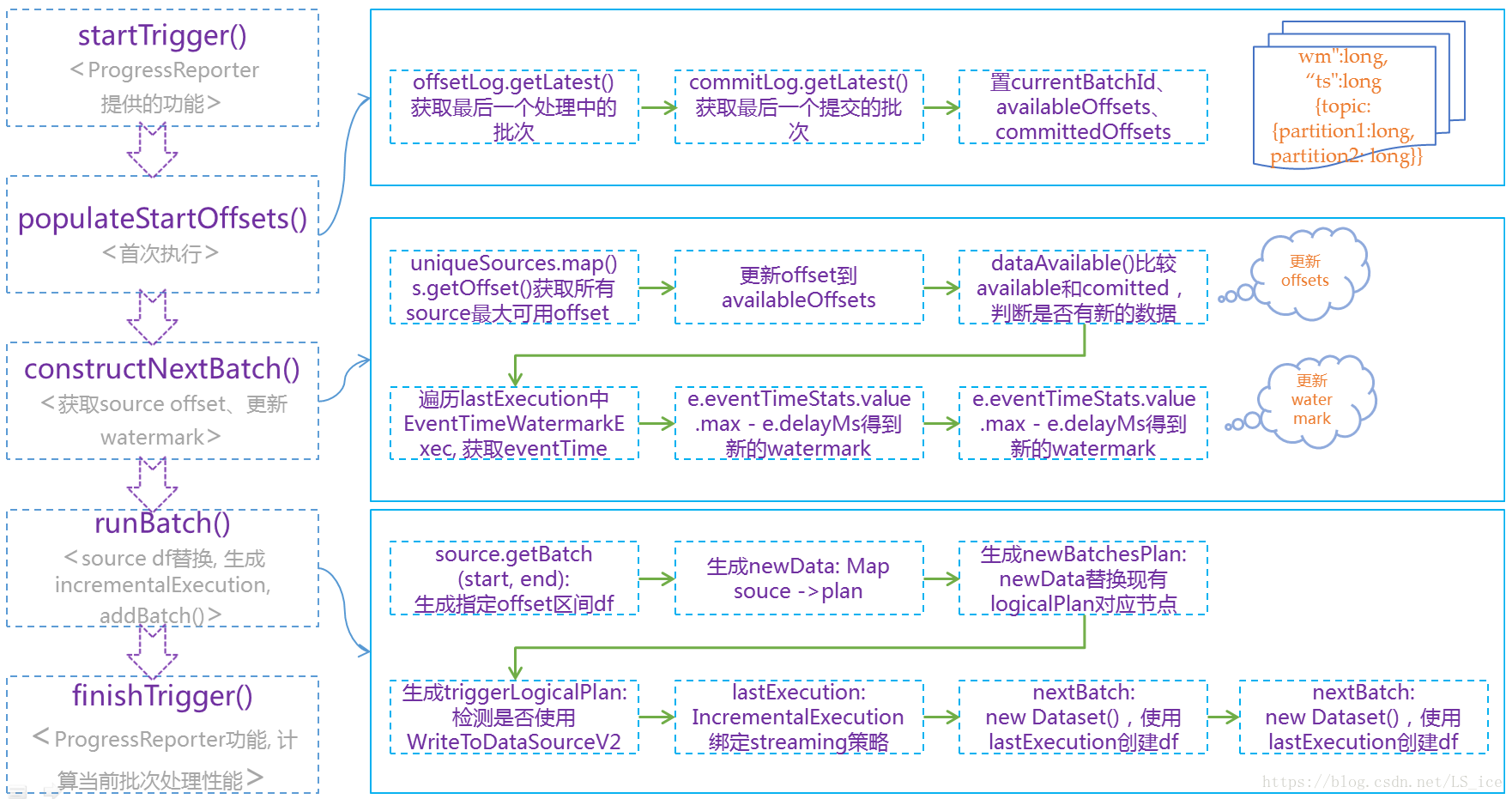
· startTrigger()和finishTrigger(): 是ProgressReporter提供的功能,用于统计流处理性能,ProgressReporter实现原理文章
· populateStartOffset():从配置的checkPoint目录读取offsets、commit子目录最大数字序号的文件内容,替换内存中watermark、availableOffsets、committedOffsets对象,比较提交的版本,决定是否恢复上次程序运行的流处理进度
· constructNextBatch():获取sources的最大offsets、 lastExecution.executedPlan.collect()方式获取上个批次的EventTimeWatermarkExec并更新watermark。offsetLog.purge()方法保存最近100个BatchID
class MicroBatchExecution(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1549
1549




 到【灌水乐园】发言
到【灌水乐园】发言







