




 本文介绍如何使用Spark通过JDBC连接MySQL数据库读取数据,并利用Jieba进行中文分词处理。详细展示了代码实现过程,包括创建SparkSession、配置数据库连接参数、加载数据到DataFrame以及应用Jieba分词。
本文介绍如何使用Spark通过JDBC连接MySQL数据库读取数据,并利用Jieba进行中文分词处理。详细展示了代码实现过程,包括创建SparkSession、配置数据库连接参数、加载数据到DataFrame以及应用Jieba分词。
从数据库里读取记录
我们要创建一个DataFrame来存储从数据库里读取的表。
首先要创建Spark的入口–SparkSession对象。
需要引入的包:
import org.apache.spark.sql.SparkSession
在main函数里:
val spark = SparkSession.builder().getOrCreate()//创建一个SparkSession对象
然后使用spark.read.format(“jdbc”)通过从mysql数据库读取的数据(读取的是某个表,DataFrame也是一个类似于数据库表的结构的数据结构):
val jdbcDF = spark.read.format("jdbc")
.option("url","xxx")//为隐私就不写了
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable","isbn_info")
.option("user","rec")
.option("password","cuclabcxg")
.load()
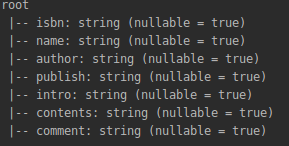
可以查看一下该表的模式:
jdbcDF.printSchema()
Jieba进行中文分词
IDEA中首先在Maven pom.xml中添加jieba所需依赖:
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
在程序里导入jieba包:
import com.huaban.analysis.jieba.JiebaSegmenter
import com.huaban.analysis.jieba.JiebaSegmenter.SegMode
在main里,取出mysql表中数据,转成String格式,然后再使用jieba分词。
val comment:String = jdbcDF.first()(6).toString()
var jieba:String = new JiebaSegmenter().sentenceProcess(comment).toString()
上面代代码就是取出comment字段为String格式,然后使用jieba的sentenceProcess方法进行分词。
全部代码及结果
import org.apache.spark.sql.SparkSession
import com.huaban.analysis.jieba.JiebaSegmenter
import com.huaban.analysis.jieba.JiebaSegmenter.SegMode
object wordCut {
def main(args: Array[String]): Unit = {
//spark的入口
val spark = SparkSession.builder().getOrCreate()//创建一个SparkSession对象
//访问数据库,得到dataframe存储表数据
val jdbcDF = spark.read.format("jdbc")
.option("url","jdbc:mysql://picpic.55555.io:24691/recTest")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable","isbn_info")
.option("user","rec")
.option("password","cuclabcxg")
.load()
//取出评论
val comment:String = jdbcDF.first()(6).toString()
var jieba:String = new JiebaSegmenter().sentenceProcess(comment).toString()
print(jieba)
}
}

Jieba分词函数的探究
JiebaSegmenter对象下有两个方法:process(),sentenceProcess()。


从IDEA上给出的函数参数可以看出,process()需要两个参数(要进行分词的String类型的文本(段落),切分模式mode(INDEX或SEARCH));sentenceProcess()只需要一个参数(要进行分词的String类型的文本(句子))。
我上面使用的是sentenceProcess,结果是对的。那么使用前者输出结果会是什么样的呢?有什么作用呢?下面就来测试一下:
val str:String = "我来到北京清华大学。"
var jieba0:String = new JiebaSegmenter().sentenceProcess(str).toString()
println(jieba0)
var jieba2:String = new JiebaSegmenter().process(str,SegMode.INDEX).toString()
println(jieba2)
var jieba3 = new JiebaSegmenter().process(str,SegMode.SEARCH).toString()
println(jieba3)

在此可以发现:使用process()结果是列表套列表,里面的每个小列表中元素依次是
[分好的词, 分好的词的第一个字符在文本字符数组的索引, 分好的词的最后一个字符在文本字符数组的索引的下一个索引]
INDEX:精准的切开,用于对用户查询词分词;
SEARCH:长词再切分,提高召回率。
(对这两个模式的解释翻遍全网,这个还算靠谱)
分词的执行逻辑
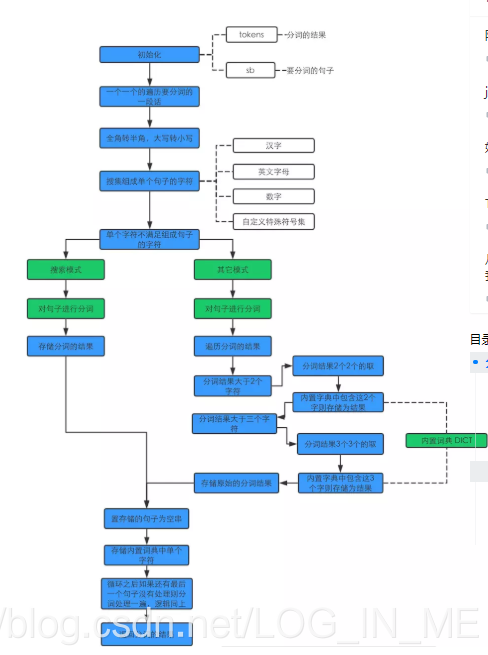
可以看到核心在于:
1、内部包含一个字典
2、分词逻辑
3、不同模式的切分粒度

















 1620
1620





 到【灌水乐园】发言
到【灌水乐园】发言







