




逆向思路:
1. 访问目标链接https://x.com/kirawontmiss/status/1930784893128016280
2. 打开F12,找到html下main.xxx.js的链接文件的url
![]()
3. 访问main.xxx.js,找到TweetDetails组的数据,拿到queryid后面要用到

4. 访问https://x.com/api/graphql/{queryid}/TweetDetail?+一组参数(别看后面一大串的,只需要改个别参数即可,大多数使用固定值即可)(如果要使用爬虫那就只有这一个url的请求需要做js逆向,上面的那几个不需要)

5. 全局搜索mp4之类的值,找到如下链接,随自己喜欢来访问下载视频
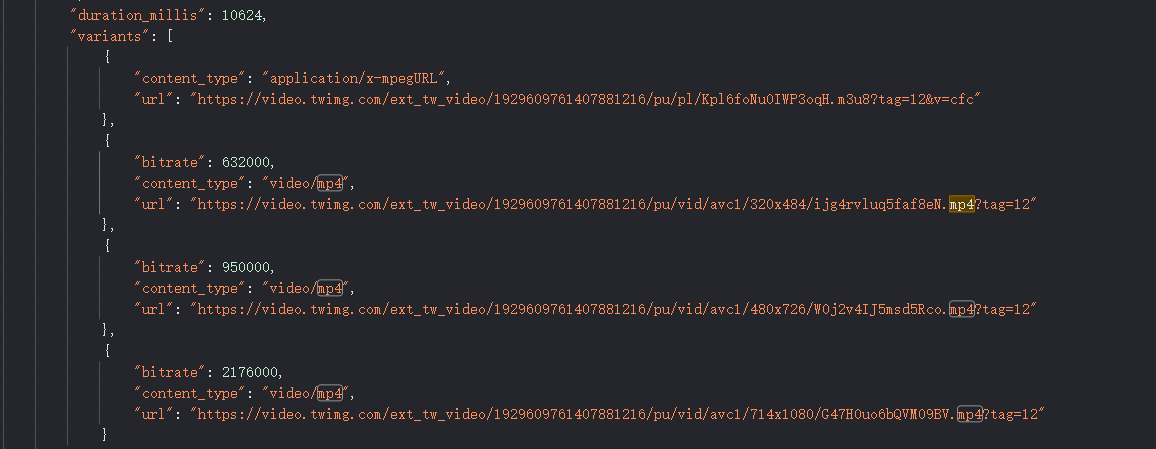

















 2063
2063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









