



 本文深入解析MongoDB中的聚合管道功能,涵盖基本概念、常用管道操作符及其实例,如$match、$project、$group等,帮助读者掌握复杂查询和数据统计技巧。
本文深入解析MongoDB中的聚合管道功能,涵盖基本概念、常用管道操作符及其实例,如$match、$project、$group等,帮助读者掌握复杂查询和数据统计技巧。
aggregate
一般查询可以通过find()方法,但如果是比较复杂的查询或者数据统计的话,find可能就无能为力了,这时也许你需要的是aggregate
什么是聚合管道?
aggregation pipeline,直译为聚合管道,它可以对数据文档进行变换和组合- 聚合管道是基于
数据流概念,数据进入管道经过一个或多个stage,每个stage对数据进行操作(筛选,投射,分组,排序,限制或跳过)后输出最终结果
db.collection.aggregate()方法
- 聚合管道查询使用的方法
- 参数是数组,
每个数组元素就是一个stage,stage中运用操作符对数据进行处理后再交由下一个stage,直到没有下个stage,就输出最终的结果,而数据的处理则是通过使用操作符
管道操作符
mongoDB中有许多操作符,在aggregate中每个stage可以使用的操作符叫做管道操作符
分类
- 阶段操作符(Stage Operators)
- 阶段操作符是使用于db.collection.aggregate()方法里面,数组参数中的第一层
- 表达式操作符(Expression Operators)
- 表达式操作符主要用于在管道中构建表达式时使用,使用类似于函数那样需要参数,主要用于$project操作符中,用于构建表达式
- 累加器(Accumulators)
- 当在group中使用时,累加器是针对每个分组使用的
- 当在project中使用时,累加器则是针对每个字面量起作用
以下列举比较常用的管道操作符:
| 操作符 | 含义 |
|---|---|
| $project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
| $match | 匹配操作符,用于对文档集合进行筛选 |
| $group | 分组操作符,用于对文档集合进行分组 |
| $unwind | 拆分操作符,用于将数组中的每一个值拆分为单独的文档 |
| $sort | 排序操作符,用于根据一个或多个字段对文档进行排序 |
| $limit | 限制操作符,用于限制返回文档的数量 |
| $skip | 跳过操作符,用于跳过指定数量的文档 |
| $lookup | 连接操作符,用于连接同一个数据库中另一个集合,并获取指定的文档,类似于populate |
阶段操作符详解

-
$match 匹配操作符
用于对文档集合进行筛选{ $match: { <query> } }- 查询name为“111”的书
- 查询书的owner为“eee”的书

-
$project 投射操作符
用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段{ $project: { <specification(s)> } }specification的规则:
规则 描述 _id: 0 or false 不返回_id(默认返回) <字段名>: 1 or true 选择需要返回什么字段 <字段名>: 表达式 使用表达式,可以用于重命名字段,或对其值进行操作,或新增字段 <字段名>: 0 or false 选择需要不返回什么字段,注意:当使用这种用法时,就不要用上面的方法 -
book集合投射name
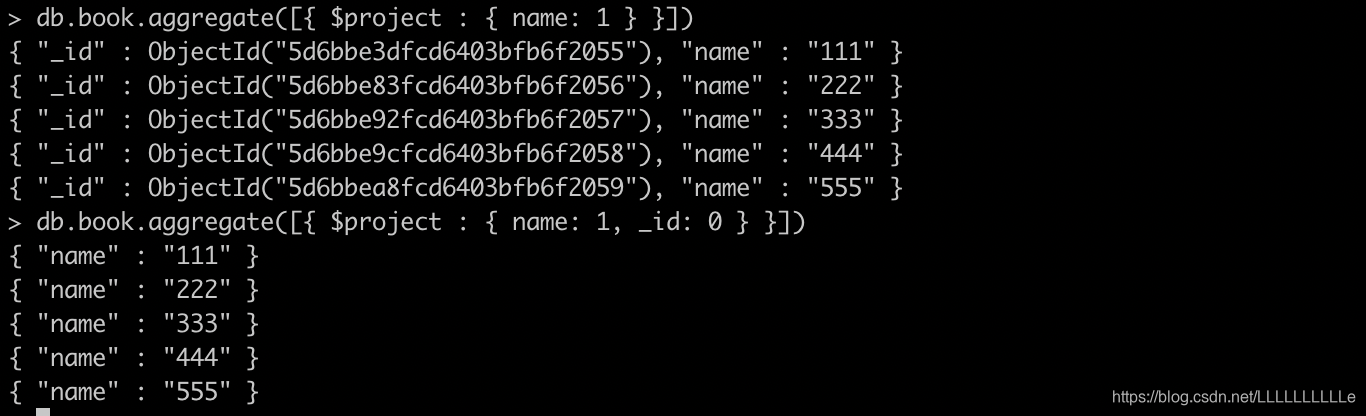
-
将book集合的name重命名为bookname

-
返回新字段bookowner,并使用表达式让它的值为owner的大写

-
-
$sort 排序操作符
用于根据一个或多个字段对文档进行排序
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } } -
$limit 限制操作符
用于限制返回文档的数量
{ $limit: <positive integer> }- 返回3本book

- 返回3本book
-
$skip 跳过操作符
用于跳过指定数量的文档
{ $skip: <positive integer> }- 跳过2本book
- 跳过2本book
-
$group 分组操作符
用于对文档集合进行分组
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }注:_id是必须的,用作分组的依据条件- 将people按sex分组
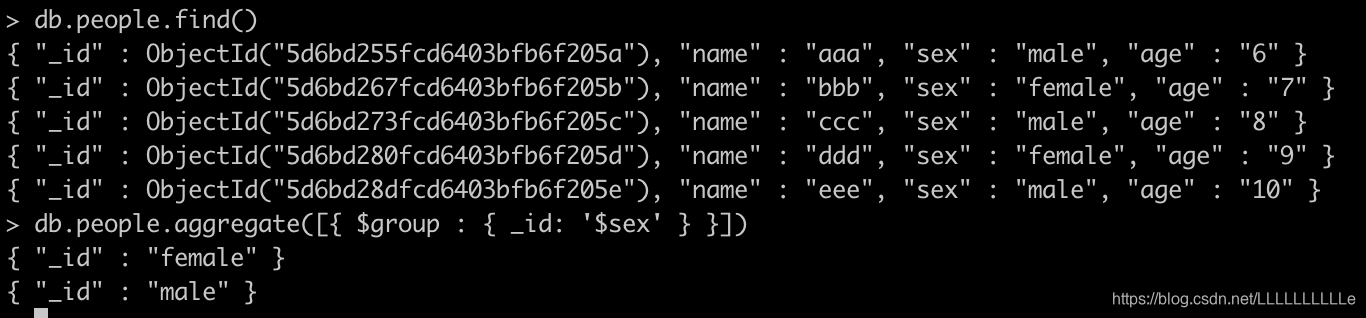
- 将people按sex分组

















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









