




 本文介绍了如何针对百度百科进行爬虫操作,以获取疾病信息,特别是处理百度百科中链接的特殊编码问题。首先,讲述了百度百科搜索页面链接的特点,如慢性咽炎的例子,原始链接需要将疾病名称转为16进制并用%分隔。然后,阐述了转码新建链接的方法,以及如何根据疾病名称爬取相关详细信息,以补充99健康网中缺失的数据。
本文介绍了如何针对百度百科进行爬虫操作,以获取疾病信息,特别是处理百度百科中链接的特殊编码问题。首先,讲述了百度百科搜索页面链接的特点,如慢性咽炎的例子,原始链接需要将疾病名称转为16进制并用%分隔。然后,阐述了转码新建链接的方法,以及如何根据疾病名称爬取相关详细信息,以补充99健康网中缺失的数据。
前期爬取的99健康网中的信息,疾病特征信息有较大的缺失,因此在百度百科中,爬取相关信息,之所以单列出来,主要在于百度百科中网页链接中的关键字编码与其他字段不同,需要重新转换。
99健康网信息爬取过程请移步:https://blog.youkuaiyun.com/LIVEAD/article/details/99682492
本文主要内容包括:
- 百度百科搜索界面及链接特点
- 转码新建链接
- 根据疾病名称爬取所需信息
- 根据原表缺失情况,爬取补充信息
1.百度百科搜索界面及链接特点(例:慢性咽炎)

界面显示的链接为:https://baike.baidu.com/item/慢性咽炎
request网页是未报错,但在read网页源代码时报错:
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 10-16: ordinal not in range(128)
查看网页链接
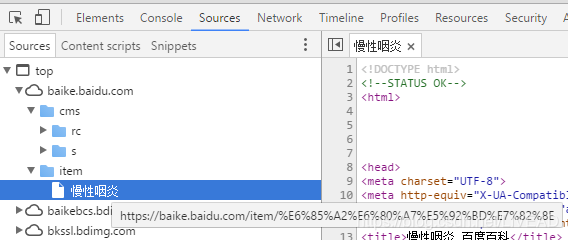
发现网页真实链为:https://baike.baidu.com/item/%E6%85%A2%E6%80%A7%E5%92%BD%E7%82%8E
其中’%E6%85%A2%E6%80%A7%E5%92%BD%E7%82%8E’ 是’慢性咽炎’ 16进制编码,同时以%隔开
因此网页爬取时,网页链接应为https://baike.baidu.com/item/关键字的16进制编码(以%隔开)
2.转码新建网页链接
import binascii
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









