




单向循环链表的原理及应用
思考一个问题:对于单向链表而言,想要遍历链表,则必须从链表的首结点开始进行遍历,请问有没有更简单的方案实现链表中的数据的增删改查?
回答:是有的,可以使用单向循环的链表进行设计,单向循环的链表的使用规则和普通的单向链表没有较大的区别,需要注意:单向循环链表的尾结点的指针域中必须指向链表的首结点的地址,带头结点的单向循环链表更加容易进行管理。
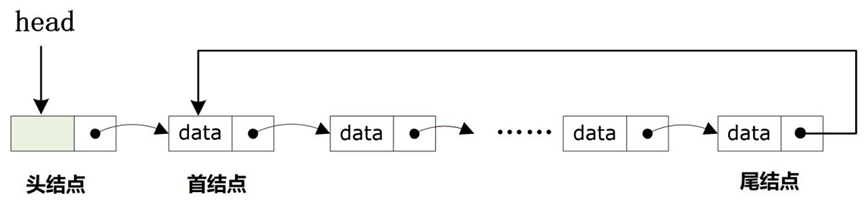
上图所示的就是一个典型的单向循环链表的结构,可以发现单向循环链表的结构属于环形结构,链表中的最后一个结点的指针域中存储的是链表的第一个结点的地址。
为了管理单向循环链表,需要构造头结点的数据类型以及构造有效结点的数据类型,如下:
typedef int DataType_t;
//构造单向循环链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct CircularLinkedList
{
DataType_t data; //结点的数据域
struct LinkedList *next; //结点的指针域
}CircLList_t;
(1) 创建一个空单向循环链表,空链表应该有一个头结点,对链表进行初始化
CircLList_t * CircLList_Create(void)
{
//1.创建一个头结点并对头结点申请内存
CircLList_t *Head = (CircLList_t *)calloc(1,sizeof(CircLList_t));
if (NULL == Head)
{
perror("Calloc memory for Head is Failed");
exit(-1);
}
//2.对头结点进行初始化,头结点是不存储数据域,指针域指向自身,体现“循环”思想
Head->next = Head;
//3.把头结点的地址返回即可
return Head;
}
(2) 创建新结点,为新结点申请堆内存并对新结点的数据域和指针域进行初始化,操作如下:
CircLList_t * CircLList_NewNode(DataType_t data)
{
//1.创建一个新结点并对新结点申请内存
CircLList_t *New = (CircLList_t *)calloc(1,sizeof(CircLList_t));
if (NULL == New)
{
perror("Calloc memory for NewNode is Failed");
return NULL;
}
//2.对新结点的数据域和指针域进行初始化
New->data = data;
New->next = NULL;
return New;
}
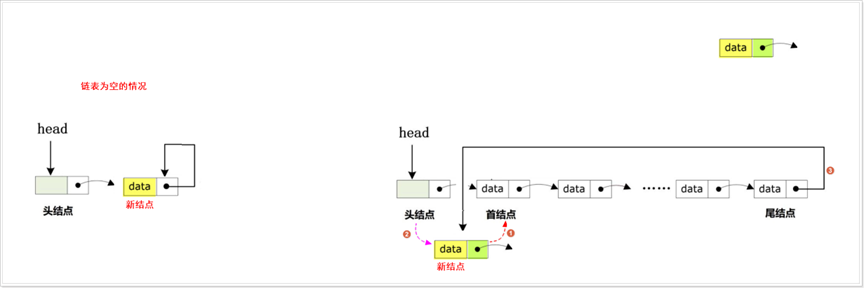
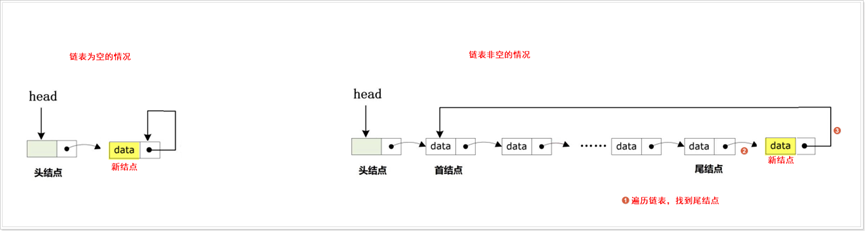
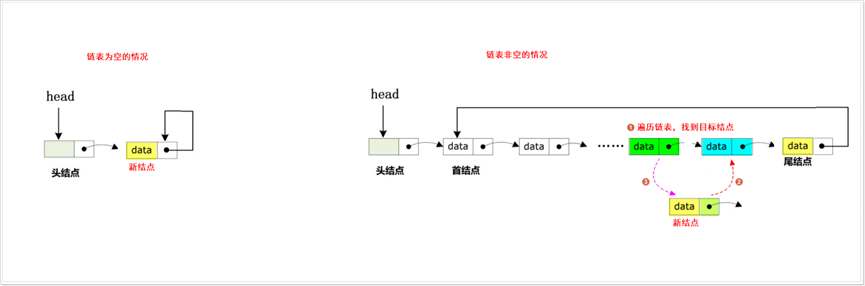
(3) 根据情况把新结点插入到链表中,此时可以分为尾部插入、头部插入、指定位置插入:
头插
尾插
指定位置插入
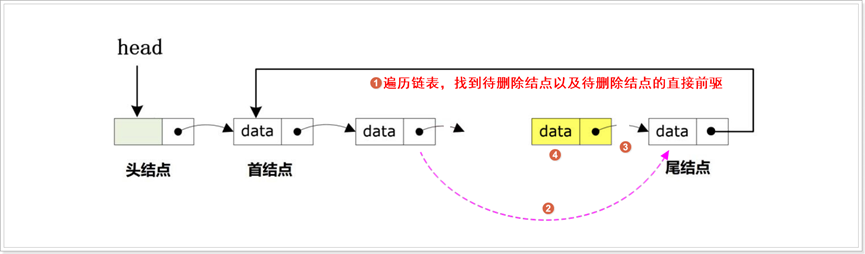
(4) 根据情况可以从链表中删除某结点,此时可以分为尾部删除、头部删除、指定元素删除:
头删
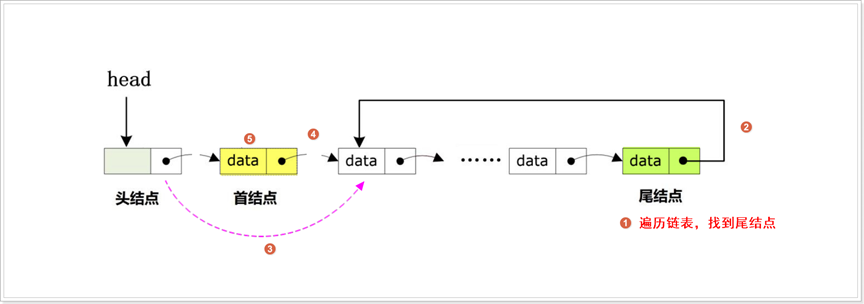
尾删
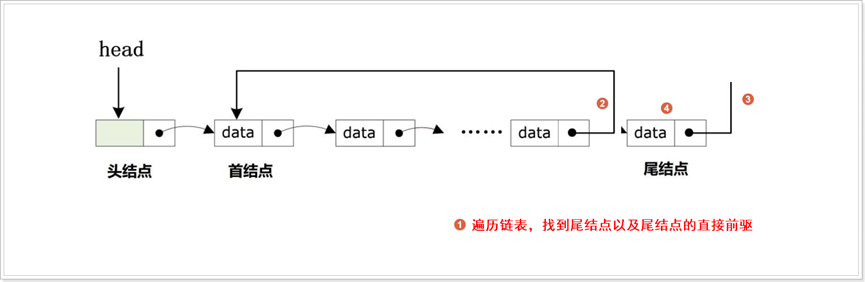
指定位置删除
双向链表的原理及应用
如果想要提高单向链表或者单向循环链表的访问速度,则可以在链表中的结点中再添加一个指针域,让新添加的指针域指向当前结点的直接前驱的地址,
也就意味着一个结点中有两个指针域(prev + next),也被称为双向链表(Double Linked List)。
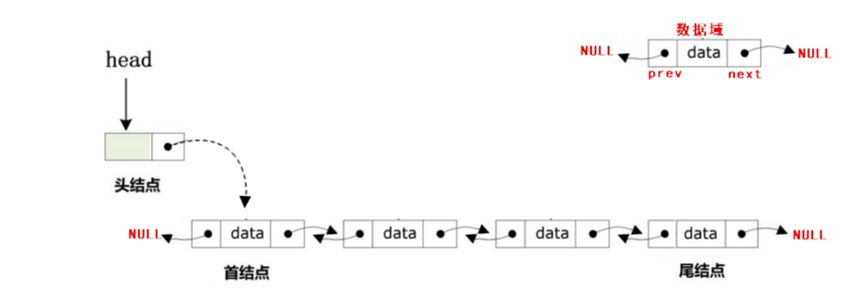
由于带头结点更加方便用户进行数据访问,所以创建一条带头结点的双向不循环的链表
typedef int DataType_t;
//构造双向链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct DoubleLinkedList
{
DataType_t data; //结点的数据域
struct DoubleLinkedList *prev; //直接前驱的指针域
struct DoubleLinkedList *next; //直接后继的指针域
}DoubleLList_t;
(1) 创建一个空链表,由于是使用头结点,所以就需要申请头结点的堆内存并初始化即可!
DoubleLList_t * DoubleLList_Create(void)
{
//1.创建一个头结点并对头结点申请内存
DoubleLList_t *Head = (DoubleLList_t *)calloc(1,sizeof(DoubleLList_t));
if (NULL == Head)
{
perror("Calloc memory for Head is Failed");
exit(-1);
}
//2.对头结点进行初始化,头结点是不存储数据域,指针域指向NULL
Head->prev = NULL;
Head->next = NULL;
//3.把头结点的地址返回即可
return Head;
}
(2) 创建新结点,为新结点申请堆内存并对新结点的数据域和指针域进行初始化,操作如下:
DoubleLList_t * DoubleLList_NewNode(DataType_t data)
{
//1.创建一个新结点并对新结点申请内存
DoubleLList_t *New = (DoubleLList_t *)calloc(1,sizeof(DoubleLList_t));
if (NULL == New)
{
perror("Calloc memory for NewNode is Failed");
return NULL;
}
//2.对新结点的数据域和指针域(2个)进行初始化
New->data = data;
New->prev = NULL;
New->next = NULL;
return New;
}
(3) 根据情况可以从链表中插入新结点,此时可以分为尾部插入、头部插入、指定位置插入:
头插
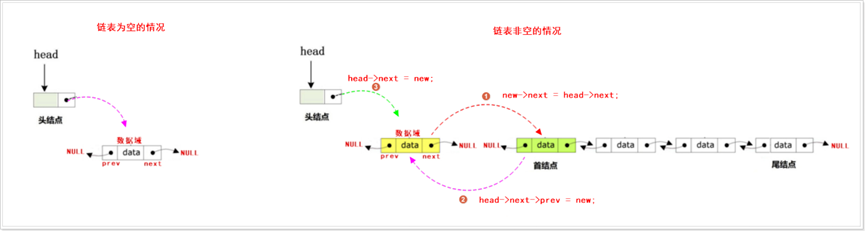
尾插
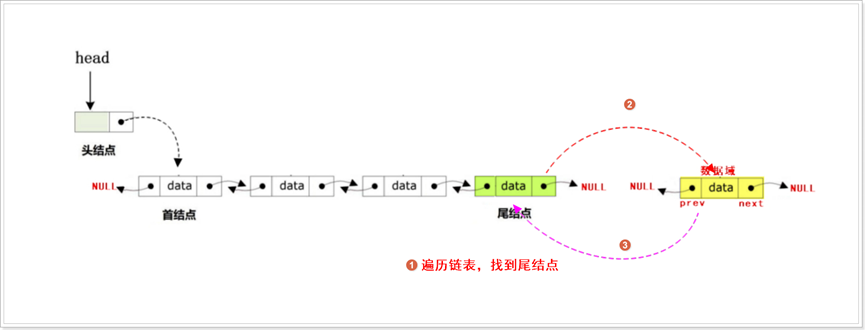
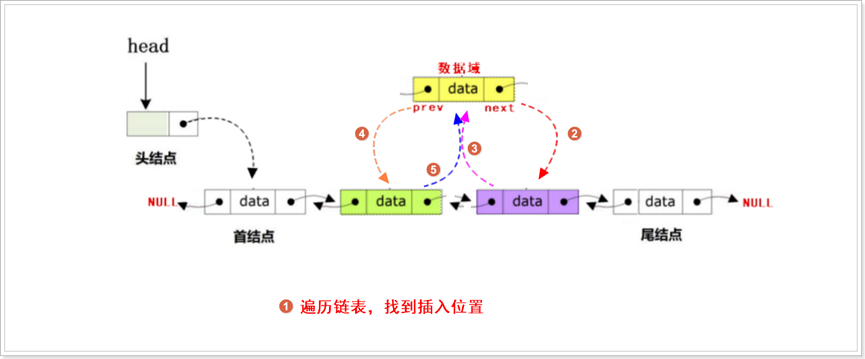
指定位置插入
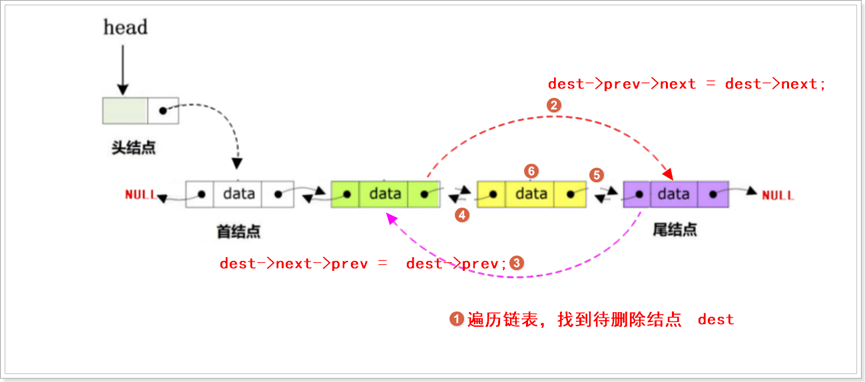
(4) 根据情况可以从链表中删除某结点,此时可以分为尾部删除、头部删除、指定结点删除:
头删
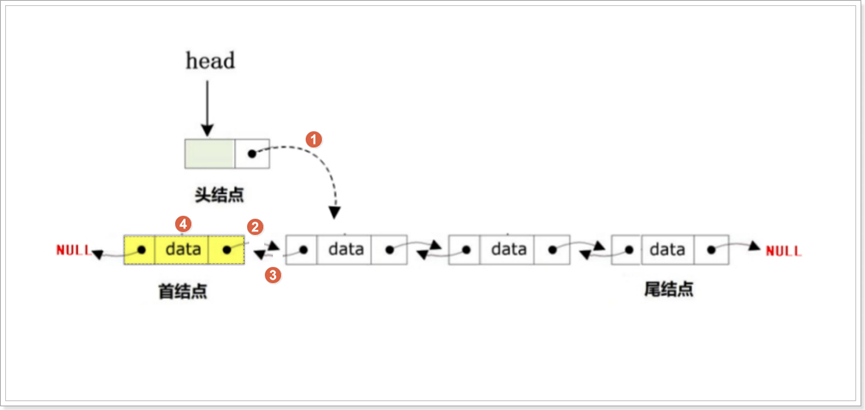
尾删
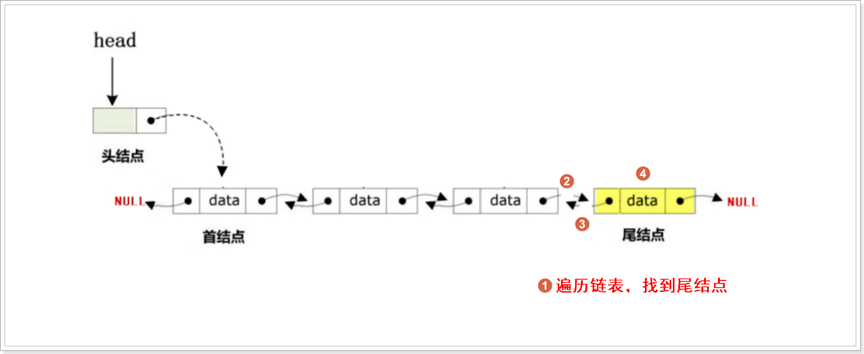
指定位置删除
双向循环链表的原理及应用
双向循环链表与双向链表的区别:指的是双向循环链表的首结点中的prev指针成员指向链表的尾结点,并且双向循环链表的尾结点里的next指针成员指向链表的首结点,所以双向循环链表也属于环形结构。
由于带头结点更加方便用户进行数据访问,所以本次创建一条带头结点的双向循环的链表。
typedef int DataType_t;
//构造双向链表的结点,链表中所有结点的数据类型应该是相同的
typedef struct DoubleLinkedList
{
DataType_t data; //结点的数据域
struct DoubleLinkedList *prev; //直接前驱的指针域
struct DoubleLinkedList *next; //直接后继的指针域
} DoubleLList_t;
(1) 创建一个空链表,由于是使用头结点,所以就需要申请头结点的堆内存并初始化即可
DoubleLList_t *DoubleLList_Create(void)
{
//1.创建一个头结点并对头结点申请内存
DoubleLList_t *Head = (DoubleLList_t *)calloc(1, sizeof(DoubleLList_t));
if (NULL == Head)
{
perror("Calloc memory for Head is Failed");
exit(-1);
}
//2.对头结点进行初始化,头结点是不存储有效数据,指针域指向自己形成循环
Head->prev = Head;
Head->next = Head;
//3.把头结点的地址返回即可
return Head;
}
(2) 创建新结点,为新结点申请堆内存并对新结点的数据域和指针域进行初始化,操作如下
DoubleLList_t *DoubleLList_NewNode(DataType_t data)
{
//1.创建一个新结点并对新结点申请内存
DoubleLList_t *New = (DoubleLList_t *)calloc(1, sizeof(DoubleLList_t));
if (NULL == New)
{
perror("Calloc memory for NewNode is Failed");
return NULL;
}
//2.对新结点的数据域和指针域(2个)进行初始化
New->data = data;
New->prev = NULL; //插入链表时会正确设置这些指针
New->next = NULL;
return New;
}
(3) 操作如上相同根据情况可以从链表中插入新结点(可分为尾部插入、头部插入、指定位置插入)以及从链表中删除某结点(可分为尾部删除、头部删除、指定结点删除)即可

















 3537
3537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









