



 本书针对分布式系统架构演变、高并发处理、流量管制等关键问题,提供了详细的解决方案和技术实践。涵盖服务治理、缓存优化、数据库分库分表等多个方面。
本书针对分布式系统架构演变、高并发处理、流量管制等关键问题,提供了详细的解决方案和技术实践。涵盖服务治理、缓存优化、数据库分库分表等多个方面。
前言
生活本来沉闷无味 但跑起来就有风~
过去二十年来,编程语言得到飞速发展,作为软件的重中之重架构,它也在发生巨大的改变,本篇讲解了架构是如何演化而来、高并发系统常见痛点、如何治理分布式系统,系统瓶颈解决思路。祝您看完后,对架构理解更近一步,在面对瓶颈突破时也能拥有更多选择~
分布式系统架构演变
一般来说,系统由小变大的过程,几乎都要经历单机架构,集群架构,分布式架构。伴随着业务系统架构的还有关系型数据库存储架构的提升,分库分表,从本地缓存到分布式缓存。
任何一个网站诞生之初都不可能直接就拥有庞大的流量和海量数据,都是在不停的试错中演变自身架构,如果业务没有起色,一味的追求大型网站架构又有什么意义呢。
内容简介
本书并没有过多渲染系统架构的理论知识,而是切切实实站在开发一线角度, 为各位读者诠释了大型网站在架构演变过程中出现一系列技术难题时的解决方案。
本书首先从分布式服务案例开始介绍,重点为大家讲解了大规模服务化场景下企业应该如何实施服务治理;然后在大流量限流/消峰案例中,笔者为大家讲解了应该如何有效地对流量实施管制,避免大流量对系统产生较大冲击,确保核心业务的稳定运行;接着笔者为大家讲解了分布式配置管理服务;之后的几章,笔者不仅为大家讲解了秒杀、限时抢购场景下热点数据的读/写优化案例,还为大家讲解了数据库实施分库分表改造后所带来的一系列影响的解决方案。
目录
- 第1章分布式服务案例
- 第2章大流量限流/消峰案例.
- 第3章分布式配置管理服务 案例.
- 第4章大促场景下 热点数据的读/写优化案例
- 第5章数据库分库分表案例
第1章分布式服务案例
1.1 分布式系统的架构演变过程

本章笔者为大家详细介绍了互联网领城分布式系统的架构演变过程。在此大家需要注意,如果用户规模及业务需求的复杂度还没有到量,那么最好保持现有架构不变,毕竞构建一个高性能、高可用,易扩展、可伸缩的分布式系统绝非一件简单的事情,需要解决的技术难题太多。而且,如果业务没有起色,一味地追寻大型网站架构并无任何意义。当然,随着用户规模的线性增长,以及业务需求越来越复杂,从单机系统逐渐演变为分布式系统,以更好地支撑业务发展似乎是必经之路。
第2章大流重限流/消峰例
天猫、淘宝这种级别的大型互联网电商网站,主要的技术挑战来自于庞大的用户规模所带来的大流量和高并发,在“双11". “双12” 等大促场景下尤为明显。如果不对流量进行合理管制,肆意放任大流量冲击系统,那么将导致- - 系列的问题出现,比如一些可用的连接资源被耗尽、分布式缓存的容量被撑爆、数据库吞吐量降低,最终必然会导致系统产生雪崩效应。当然,应对大流量和高并发也没有大家想象得那么复杂和神秘,一般来说,大型互联网站通常采用的做法是通过扩容、动静分离、缓存、服务降级及限流五种常规手段来保护系统的稳定运行。
2.1分布式系统为什么需要进行流量管制


笔者从业务层面和技术层面两个维度为大家详细讲解了应该如何对流量实施管制,从而避免在大促场景下因峰值流量过大对系统造成较大冲击,引发系统出现雪崩现象。笔者先为大家讲解了目前市面上一些常见的限流算法,比如令牌桶算法.漏桶算法及计数器算法等,并演示了如何使用Nginx的限流功能来实现接人层限流,以及使用计数器算法在限时抢购场景下控制单机并发写流量。除了可以运用技术手段实施流量管制,也可以在业务上做调整,换一种思路或玩法,采用基于时间分片的消峰方案也可以有效对流量实施管制。最后,笔者为大家讲解了如何使用MQ进行异步调用、实现系统之间的解构,并为大家演示了阿里开源的消息中间件RocketMQ的具体部署和使用方式,还分享了笔者在实际工作中基于MQ实现流量消峰的一些典型案例。
第3章分布式配置管理服务案例
相信大家对配置信息都不会感到陌生,在实际的开发过程中,无论是访问数据库、分布式缓存系统、消息队列,还是通过Dubbo框架实现RPC调用,都需要提前配置好目标URL.账号/密码等信息,因此这类信息也被称为配置信息。在大部分情况下,我们都会选择将相关配置信息配置在配置文件中,当系统启动时,会从指定的目录下进行加载,通过获取配置文件中的配置信息项来完成环境的初始化工作。除此之外,我们在使用电脑进行办公、娱乐时,也会高频率地与配置信息打交道,比如,通过操作系统的控制面板来设置显示器的分辨率、鼠标的双击速度,以及区域和语言设置等,这些都属于配置信息,所以如果你告诉我你从未接触过配置信息,那么我一定会摇摇头对你说这不可能。
31:1将配置信息耦合在业务代码中


第4章大促场景下热点数据的读/写优化案例
本章笔者会结合实际的工作经验,为大家重点讲解大促场景下热点数据读/写技术难题的一-系列解决方案。
4.1缓存技术简介
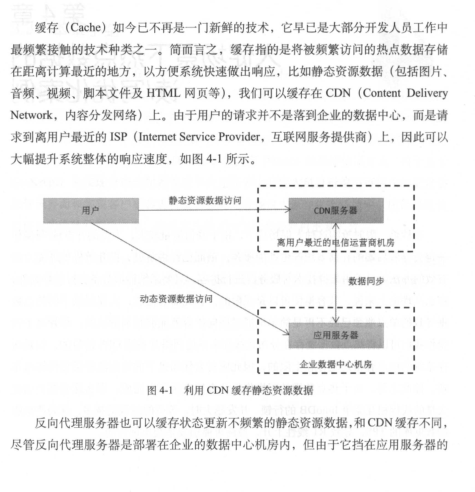

热点数据的读/写操作其实是秒杀,抢购场景下最核心的技术难题。本章以为什么需要在系统中使用缓存技术作为开篇,重点讲解了本地缓存Ehcache及分布式缓存Redis技术,并介绍了如何使用Jedis, Redisson 等客户端API与Redis进行交互。
第5章数据库分库分表案例
大型网站几乎时时刻刻都在接受着高并发和海量数据的洗礼,随着用户规模的线性上升,单库的性能瓶颈会逐渐暴露出来,由于数据库的检索效率越来越慢,导致生产环境中产生较多的慢速SQL。对于非结构化的数据,可以将其存储在NoSQL数据库中来提升性能,但是重要的业务数据,仍然要落盘在关系型数据库(如MySQL数据库)中。那么如何提升关系型数据库的并行处理能力和检索效率就成为了架构师需要思考和解决的棘手问题,并且单库如果宕机,业务系统也就随之瘫痪了。因此,在互联网场景下,架构师务必要确保后端存储系统具备高可用性和高性能,为了解决这些问题,目前互联网场景下常见的做法便是对数据库实施分库分表,即Sharding改造。
5.1关系型数据库的架构演变


本书适用于任何对分布式系统架构感兴趣的架构师、开发人员以及运维人员。相信阅读本书你将会有知其然和知其所以然的畅快感


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









