




引言
先如今所有的技术栈中,只要一谈关于高可用、高并发处理相关的实现,必然会牵扯到集群这个话题,也就是部署多台服务器共同对外提供服务,从而做到提升系统吞吐量,优化系统的整体性能以及稳定性等目的。
当多台机器上部署相同服务节点时,客户端的发送请求访问就会出现一个必须要解决的问题:客户端的请求到底该交由哪台服务器处理?这点则由负载均衡策略来决定,也就是说:请求具体会被分发到哪台服务器,是调度算法来决定的。
负载均衡这个概念,几乎在所有支持高可用的技术栈中都存在,例如微服务、分库分表、各大中间件(
MQ、Redis、MyCat、Nginx、ES)等,也包括云计算、云调度、大数据中也是炙手可热的词汇。
负载均衡策略主要分为静态与动态两大类:
- 静态调度算法:指配置后只会依据配置好的策略进行请求分发的算法。
- 动态调度算法:指配置后会根据线上情况(网络/CPU负载/磁盘IO等)来分发请求。
但负载均衡算法数量并不少,本篇主要对于一些常用且高效的负载策略进行剖析。
一、基本的负载算法
如果聊到最基本的负载均衡算法,那么相信大家多少都有了解,例如:轮询、随机、权重等这类算法。特点就在于实现简单,先来快速过一遍基本的算法实现。
1.1、轮询算法
轮询算法是最为简单、也最为常见的算法,也是大多数集群情况下的默认调度算法,这种算法会按照配置的服务器列表,按照顺序依次分发请求,所有服务器都分发一遍后,又会回到第一台服务器循环该步骤,Java代码实现如下:
// 服务类:主要用于保存配置的所有节点
public class Servers {
// 模拟配置的集群节点
public static List<String> SERVERS = Arrays.asList(
"44.120.110.001:8080",
"44.120.110.002:8081",
"44.120.110.003:8082",
"44.120.110.004:8083",
"44.120.110.005:8084"
);
}
// 轮询策略类:实现基本的轮询算法
public class RoundRobin{
// 用于记录当前请求的序列号
private static AtomicInteger requestIndex = new AtomicInteger(0);
// 从集群节点中选取一个节点处理请求
public static String getServer(){
// 用请求序列号取余集群节点数量,求得本次处理请求的节点下标
int index = requestIndex.get() % Servers.SERVERS.size();
// 从服务器列表中获取具体的节点IP地址信息
String server = Servers.SERVERS.get(index);
// 自增一次请求序列号,方便下个请求计算
requestIndex.incrementAndGet();
// 返回获取到的服务器IP地址
return server;
}
}
// 测试类:测试轮询算法
public class Test{
public static void main(String[] args){
// 使用for循环简单模拟10个客户端请求
for (int i = 1; i <= 10; i++){
System.out.println("第"+ i + "个请求:" + RoundRobin.getServer());
}
}
}
/******输出结果*******/
第1个请求:44.120.110.001:8080
第2个请求:44.120.110.002:8081
第3个请求:44.120.110.003:8082
第4个请求:44.120.110.004:8083
第5个请求:44.120.110.005:8084
第6个请求:44.120.110.001:8080
第7个请求:44.120.110.002:8081
第8个请求:44.120.110.003:8082
第9个请求:44.120.110.004:8083
第10个请求:44.120.110.005:8084
上述案例中,整个算法的实现尤为简单,就是通过一个原子计数器记录当前请求的序列号,然后直接通过%集群中的服务器节点总数,最终得到一个具体的下标值,再通过这个下标值,从服务器IP列表中获取一个具体的IP地址。
轮询算法的优势:
- ①算法实现简单,请求分发效率够高。
- ②能够将所有请求均摊到集群中的每个节点上。
- ③易于后期弹性伸缩,业务增长时可以拓展节点,业务萎靡时可以缩减节点。
轮询算法的劣势:
- ①对于不同配置的服务器无法合理照顾,无法将高配置的服务器性能发挥出来。
- ②由于请求分发时,是基于请求序列号来实现的,所以无法保证同一客户端的请求都是由同一节点处理的,因此需要通过
session记录状态时,无法确保其一致性。
轮询算法的应用场景:
- ①集群中所有节点硬件配置都相同的情况。
- ②只读不写,无需保持状态的情景。
1.2、随机算法
随机算法的实现也非常简单,也就是当客户端请求到来时,每次都会从已配置的服务器列表中随机抽取一个节点处理,实现如下:
// 随机策略类:随机抽取集群中的一个节点处理请求
public class Random {
// 随机数产生器,用于产生随机因子
static java.util.Random random = new java.util.Random();
public static String getServer(){
// 从已配置的服务器列表中,随机抽取一个节点处理请求
return Servers.SERVERS.get(random.nextInt(Servers.SERVERS.size()));
}
}
上述该算法的实现,非常明了,通过java.util包中自带的Random随机数产生器,从服务器列表中随机抽取一个节点处理请求,该算法的结果也不测试了,大家估计一眼就能看明白。
随机算法的优势:个人看来该算法单独使用的意义并不大,一般会配合下面要讲的权重策略协同使用。
随机算法的劣势:
- ①无法合理的将请求均摊到每台服务器节点。
- ②由于处理请求的目标服务器不明确,因此也无法满足需要记录状态的请求。
- ③能够在一定程度上发挥出高配置的机器性能,但充满不确定因素。
1.3、权重算法
权重算法是建立在其他基础算法之上推出的一种概念,权重算法并不能单独配置,因为权重算法无法做到请求分发的调度,所以一般权重会配合其他基础算法结合使用,如:轮询权重算法、随机权重算法等,这样可以让之前的两种基础调度算法更为“人性化”一些。
权重算法是指对于集群中的每个节点分配一个权重值,权重值越高,该节点被分发的请求数也会越多,反之同理。这样做的好处十分明显,也就是能够充分考虑机器的硬件配置,从而分配不同权重值,做到“能者多劳”。那如何实现呢,先来看看随机权重的实现:
public class Servers{
// 在之前是Servers类中再加入一个权重服务列表
public static Map<String, Integer> WEIGHT_SERVERS = new LinkedHashMap<>();
static {
// 配置集群的所有节点信息及权重值
WEIGHT_SERVERS.put("44.120.110.001:8080",17);
WEIGHT_SERVERS.put("44.120.110.002:8081",11);
WEIGHT_SERVERS.put("44.120.110.003:8082",30);
}
}
// 随机权重算法
public class Randomweight {
// 初始化随机数生产器
static java.util.Random random = new java.util.Random();
public static String getServer(){
// 计算总权重值
int weightTotal = 0;
for (Integer weight : Servers.WEIGHT_SERVERS.values()) {
weightTotal += weight;
}
// 从总权重的范围内随机生成一个索引
int index = random.nextInt(weightTotal);
System.out.println(index);
// 遍历整个权重集群的节点列表,选择节点处理请求
String targetServer = "";
for (String server : Servers.WEIGHT_SERVERS.keySet()) {
// 获取每个节点的权重值
Integer weight = Servers.WEIGHT_SERVERS.get(server);
// 如果权重值大于产生的随机数,则代表此次随机分配应该落入该节点
if (weight > index){
// 直接返回对应的节点去处理本次请求并终止循环
targetServer = server;
break;
}
// 如果当前节点的权重值小于随机索引,则用随机索引减去当前节点的权重值,
// 继续循环权重列表,与其他的权重值进行对比,
// 最终该请求总会落入到某个IP的权重值范围内
index = index - weight;
}
// 返回选中的目标节点
return targetServer;
}
public static void main(String[] args){
// 利用for循环模拟10个客户端请求测试
for (int i = 1; i <= 10; i++){
System.out.println("第"+ i + "个请求:" + getServer());
}
}
}
/********运行结果********/
第1个请求:44.120.110.003:8082
第2个请求:44.120.110.001:8080
第3个请求:44.120.110.003:8082
第4个请求:44.120.110.003:8082
第5个请求:44.120.110.003:8082
第6个请求:44.120.110.003:8082
第7个请求:44.120.110.003:8082
第8个请求:44.120.110.001:8080
第9个请求:44.120.110.001:8080
第10个请求:44.120.110.002:8081
上面这个算法对比之前的基本实现,可能略微有些复杂难懂,我们先上个图:
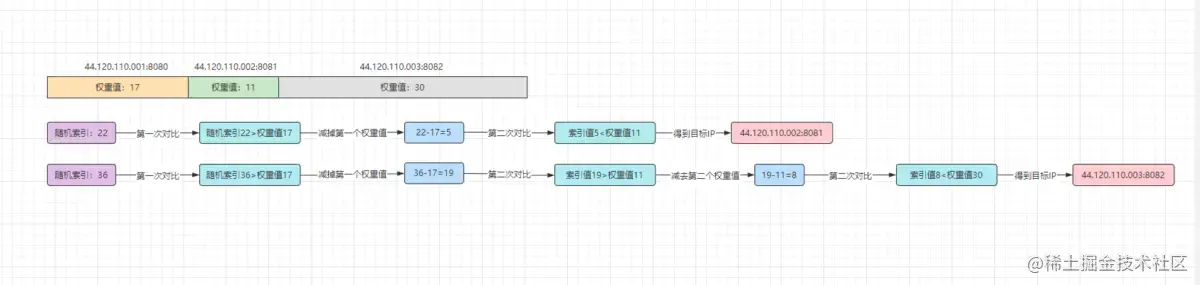
仔细观看上图后,逻辑应该会清晰很多,大体捋一下思路:
- 先求和所有的权重值,再随机生成一个总权重之内的索引。
- 遍历之前配置的服务器列表,用随机索引与每个节点的权重值进行判断。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2561
2561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









