




题目链接:437. 路径总和 III - 力扣(LeetCode)
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
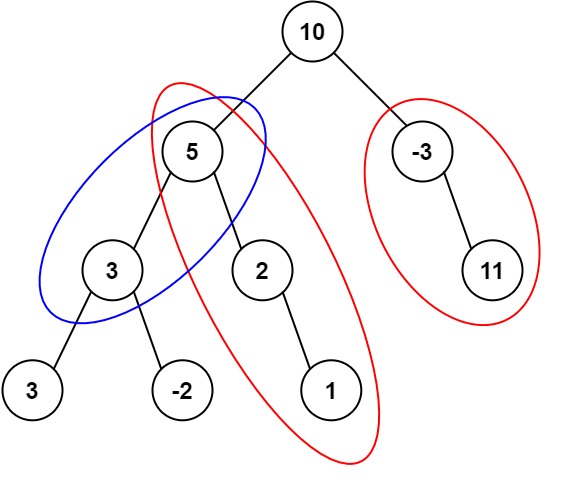
输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8 输出:3 解释:和等于 8 的路径有 3 条,如图所示。
示例 2:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 输出:3
提示:
-
二叉树的节点个数的范围是
[0,1000] -
-109 <= Node.val <= 109 -
-1000 <= targetSum <= 1000
每一条路径都可以视为一个数组,那么这题就变成了统计在某个数组中和为target的子序列的数量,这显然可以使用前缀和解决。
首先,要得到每一条路径所经过的节点值,就需要使用深度优先搜索。当我们搜索到节点node时,计算出其前缀和为curr,我们希望在根节点root到node之间,存在这么一个节点node1,使得node1到node的和为target,那么这就意味着node1的前缀和为curr-target.为了记录数量,我们使用哈希表。键为前缀和,值为出现次数。遍历到节点node时,看哈希表中是否存在curr-target这个键,如果存在,那么就记录curr-target这个路径和在这个路径的出现次数。再递归统计左右子树中出现目标值的次数,最后回溯,进入另一个分支即可。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
unordered_map<uint64_t,int>cnt;//键:前缀和;值:出现次数
int dfs(TreeNode*root,uint64_t curr,int target) {
if(!root) return 0;
int res=0;
curr+=root->val;
if(cnt.count(curr-target)) {
//如果存在curr-target这个键
res=cnt[curr-target];//那么res为在这条路径上的出现次数
}
cnt[curr]++;
res+=dfs(root->left,curr,target);
res+=dfs(root->right,curr,target);
cnt[curr]--;//回溯
return res;
}
int pathSum(TreeNode* root, int targetSum) {
cnt[0]=1;//对于根节点来说,它的前缀和为0,因此算一条路径
return dfs(root,0,targetSum);
}
};
















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









