




 文章介绍了WGAN-GP的背景,作为解决原始GAN和WGAN训练不稳定的改进方案。WGAN-GP通过梯度惩罚而非权重约束来稳定训练,适用于多种GAN架构,包括图像和语言模型。文章提供了代码实现和数据集下载链接,展示了在解决梯度消失和爆炸问题上的优势。
文章介绍了WGAN-GP的背景,作为解决原始GAN和WGAN训练不稳定的改进方案。WGAN-GP通过梯度惩罚而非权重约束来稳定训练,适用于多种GAN架构,包括图像和语言模型。文章提供了代码实现和数据集下载链接,展示了在解决梯度消失和爆炸问题上的优势。
目录
3.权重限制的困难(Difficulties with weight constraints)
提示:本文不会对WGAN-GP其中的公式进行推导,主要是讲解WGAN-GP算法的实现。
1.WGAN-GP产生背景
自从生成对抗网络(Generative Adversarial Networks 简称GAN)被提出来之后,各种各样在原始GAN的基础上提出了很多的创新的GAN,但是原始的GAN网络训练不稳定,并且对超参数非常的敏感,还会导致模式崩塌的现象。因此,DCGAN对原始的GAN进行了改进,提出了一些新的方法和技巧来让GAN训练更加的稳定,但是这些技巧不是从最根本的方法去解决问题,所以WGAN诞生了。
WGAN(Wasserstein GAN)提出了一种新的方法,可以说是从本质的方向上去解决GAN训练不稳定的问题,并且WGAN在这方面取得了很大的进展,但是有时仍然产生只有较差的样本或者无法收敛。该问题主要是由于在WGAN中使用权重裁剪时,对于critic模型来说,可能会导致不可预料的行为,因此提出了WGAN-GP,继续对其进行改进。
WGAN-GP提出了一种剪辑的替代方案权重:惩罚critic相对于其输入的梯度数。WGAN-GP所提出的方法比标准WGAN执行得更好,并且能够在几乎没有超参数调整的情况下稳定地训练各种GAN架构,包括101层ResNets和具有连续生成器的语言模型,包括在CIFAR-10和LSUN卧室上实现了高质量的生成器。
提示:在论文的附录中给出很多关于WGAN-GP和其他GAN进行对比的效果,更加说明了WGAN-GP在训练过程中更加的稳定,效果更好。




2.WGAN-GP的主要成就
-
在玩具数据集上,我们展示了critic的权重削减是如何导致不可预料的行为的。
-
提出了梯度惩罚(WGAN-GP),它不会遇到同样的问题,并且效果更加的稳定。
-
展示了各种GAN架构的稳定训练和性能改进超权重剪裁、高质量图像生成和字符级GAN语言没有任何离散采样的模型。
3.权重限制的困难(Difficulties with weight constraints)
- WGAN中的权重裁剪会导致优化困难,即使优化成功,最终的critic也可能具有无法控制的价值表面。
- 实验使用了特定形式的权重约束(每个权重大小的硬剪裁),并且也尝试了其他权重约束(L2范数剪裁、权重归一化)以及软约束(L1和L2权重衰减),发现它们表现出类似的问题。
-
在某种程度上,这些问题可以通过critic中的批处理规范化来缓解。然而,即使使用批量标(Batch Normalization)准化,我们也观察到WGAN的critic往往无法达成一致
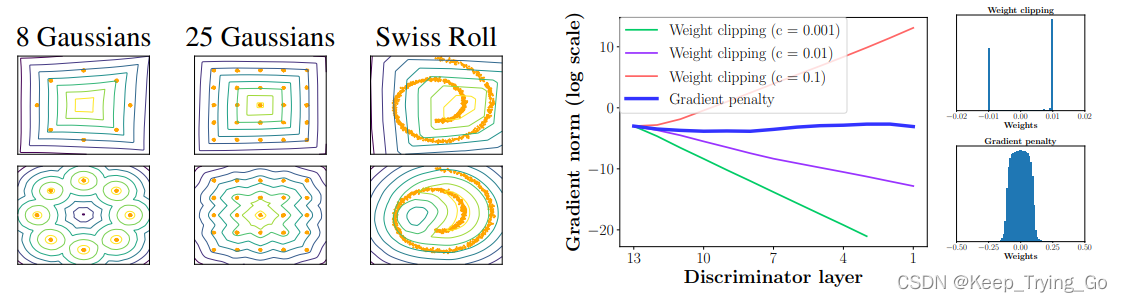
左图:使用(顶部)权重剪裁和(底部)梯度惩罚,训练WGAN的critic值曲面在玩具数据集上进行运算。经过权重裁剪训练的critic无法捕捉到数据分布的更高时刻。生成器固定在真实数据处加上高斯噪声处。
右图:在Swiss Roll数据集上训练期间,深度WGAN critic的梯度范数在使用权重剪裁时爆炸或消失,但在使用梯度惩罚。权重剪裁(顶部)将权重推向两个值(剪裁范围的极端),这与渐变惩罚(底部)不同。可以看到使用权重裁剪(weight clipping[-c,c])时,对去那种的初始化出现了两个极端。然而使用梯度惩罚的话,权重在整个的区间都是呈现一种连续的。
(1)WGAN-GP算法流程


具体代码实现如下:
for batch_idx,(data,_) in enumerate(dataLoader):
data = data.to(device)
cur_batch_size = data.shape[0]
#Train: Critic : max[critic(real)] - E[critic(fake)]
loss_critic = 0
for _ in range(CRITIC_ITERATIONS):
noise = torch.randn(size = (cur_batch_size,Z_DIM,1,1),device=device)
fake_img = gen(noise)
#使用reshape主要是将最后的维度从[1,1,1,1]=>[1]
critic_real = critic(data).reshape(-1)
critic_fake = critic(fake_img).reshape(-1)
gp = gradient_penality(critic,data,fake_img,device=device)
loss_critic = -(torch.mean(critic_real)- torch.mean(critic_fake)) + LAMBDA_GP*gp
opt_critic.zero_grad()
loss_critic.backward(retain_graph=True)
opt_critic.step()
#将维度从[1,1,1,1]=>[1]
gen_fake = critic(fake_img).reshape(-1)
#max E[critic(gen_fake)] <-> min -E[critic(gen_fake)]
loss_gen = -torch.mean(gen_fake)
opt_gen.zero_grad()
loss_gen.backward()
opt_gen.step()
(2)梯度消失(梯度弥散)和梯度爆炸
由于权重约束和成本函数之间的相互作用,WGAN优化过程很困难,这导致梯度消失或梯度爆炸,而没有仔细调整剪裁阈值c。
如上图所示:在Swiss Roll toy数据集上训练WGAN,在[0.1,0.01,0.001]中改变剪裁阈值c,并绘制关于连续激活层的临界损失梯度的范数。生成器和critic都是12层神经网络(多层感知机 - ReLU MLPs),没有批处理规范化(Batch Normalization)。
由图可观察到,对于这些值中的每一个,随着在网络中不断进行训练,梯度要么呈指数增长,要么呈指数衰减。而WGAN-GP的方法产生了更稳定的梯度,既不会消失也不会爆炸,从而允许训练更复杂的网络。
(3)梯度惩罚(gradient penalty)
WGAN+GP:在WGAN的基础上加上梯度惩罚。公式的前一半是WGAN的critic的原始优化目标公式,后一半是梯度惩罚(GP)。
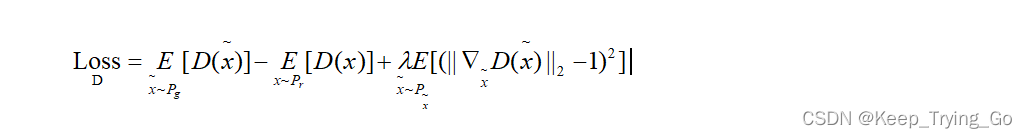
def gradient_penality(critic,real,fake,device='cpu'):
"""
:param critic: 判别器模型
:param real: 真实样本
:param fake: 生成的样本
:param device: 设备CUP or GPU
:return:
"""
BATCH_SIZE,C,H,W = real.shape
alpha = torch.randn(size=(BATCH_SIZE,1,1,1)).repeat(1,C,H,W).to(device)
interpolated_images=real*alpha + fake*(1-alpha)
#计算判别器输出
mixed_scores = critic(interpolated_images)
#求导
gradient = torch.autograd.grad(
inputs=interpolated_images,
outputs=mixed_scores,
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True
)[0]
gradient = gradient.view(gradient.shape[0],-1)
gradient_norm = gradient.norm(2,dim = 1)
gradient_penality = torch.mean((gradient_norm - 1)**2)
return gradient_penality理解为什么权重裁剪在WGAN critic中存在问题,建议读者去看原论文的附录证明。
4.WGAN-GP网络结构
5.数据集下载
链接:https://pan.baidu.com/s/1i_VU3aQpLkCx4Z5fhDVKHA
提取码:79y3
6.WGAN-GP代码实现
提示:代码放在了Github上,本文的代码是参考下面这位博主写的,但是自己其中只是做了一下修改,并且其中加了一个mainWindows界面代码,方便后面训练的模型进行图像风格的转换。
参考博主的代码:https://b23.tv/QUc0CNb

7.mainWindow窗口显示生成器生成的图片
提示:这里编写了一个显示生成器显示图片的程序(mainWindow.py),加载之前训练之后保存的生成器模型,之后可使用该模型进行随机生成图片,如下:
(1)运行mainWindow.py 初始界面如下
点击随机生成图片:

8.模型下载
链接:https://pan.baidu.com/s/1NyQzaxgX3B-pUAuwJWwCgQ
提取码:39p5


















 4498
4498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









