






抽象的:
介绍
问答系统(QA)用于回答以自然语言编写的问题。当这些问题侧重于视觉信息时,该过程称为视觉问答系统(VQA)。针对非医学图像的 VQA 称为一般 VQA,而针对医学图像的 VQA 称为医学 VQA。本文主要关注医学图像和相关的 VQA 问题。VQA 是一项多学科任务,涉及自然语言处理(NLP)、计算机视觉(CV)以及知识表示和推理(KR)。图 1中的 VQA 图表询问图像中是否含有眼底渗出物,从图像(CV)和文本(NLP)中提取特征,并解释它们之间的关系(KR)以通过分类器回答问题。
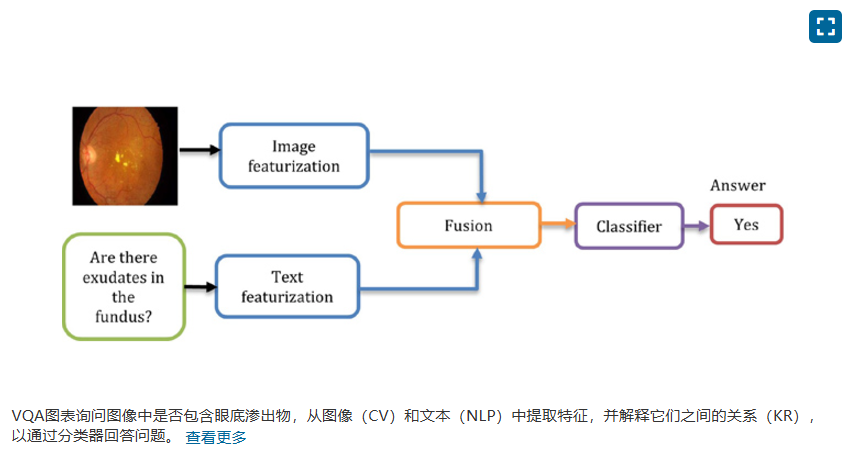
最近,鉴于深度学习的重要性以及迁移学习在构建视觉和 NLP 模型中的应用,VQA 已成为人工智能 (AI) 研究人员面临的挑战。VQA 有助于实现视觉对话 AI 梦想,使计算机能够像人类一样高效地理解、分析和回答有关视觉场景的问题[1] 。在 VQA [2]中,提供回答选择的解释至关重要。尽管 QA 模型取得了重大进展,但 VQA 模型仍然表现不佳[3]、[4]。造成这种表现不佳的主要原因如下:
-
人类解决问题的方法与 VQA 模型中的方法不同。例如,虽然人类可以轻松识别图像中的老年人,但对于模型来说,这可能更难。
-
现有的 VQA 模型缺乏进行高级推理的能力[4]。例如,根据特定属性(例如大小、形状和纹理)对肿瘤进行分类的问题需要的不仅仅是物体检测。当询问大于 5 毫米的肿瘤时,模型必须检测图像中的所有肿瘤以及所有现有肿瘤的大小,进行比较并回答问题。
-
许多研究没有关注文本所表达的思想和图像内容之间的深层关系[5]。许多研究没有表明结果是基于正确的推理还是巧合的答案[4]。
该领域的一个空白是需要一个大型、丰富的数据集,其中包含图像、简单和复杂的问答对及其相关性,并且没有针对特定主题的偏见数据。因此,过去三年中生成了大量信息[6]。 Vu 等人[7]生成了三个包含复杂问题的医学数据集。
除了医学 VQA 差距中的复杂问题之外,该领域还存在一些局限性。尽管 ImageCLEF-Med 每年都会提供最新数据,研究人员也会增强现有数据或生成新数据,但这些信息仍然存在局限性,不足以开发出在现实世界中使用的稳健实用的模型[8]。例如,数据大小存在限制,需要很大才能处理各种问题和答案。缺乏有关图像或患者病史信息的数据限制了现实世界的医疗 VQA 代理系统[8]。尽管 Kovaleva 等人[9]提出了患者病史数据,但他们仅根据一句话就提取了病史。此外,数据不平衡或有偏差是另外两个数据缺陷。数据简单,没有复杂的问题,导致简单的模型无法回答复杂问题。此外,自动数据生成方法会产生稳健的数据问题[10]。所有这些数据都足以影响 VQA 模型的性能。研究人员提出了不同的解决方案和多模型来超越这些界限并提高整体性能,但整体性能仍然很低。
医学图像(例如 CT、MRI、乳房 X 光检查和超声波)在采集和传输过程中会受到影响。这些噪声图像需要一个能够突破这种噪声限制的稳健模型[11]。尽管 Nguyen 等人[12]和 Zhan 等人[13]等研究人员提出了一些模型来解决这个问题并显著提高性能,但性能水平仍然很低。除了医学 VQA 中的这些问题之外,经常使用的预训练模型(例如 VGGNet 和 ResNet)具有固定的输入图像大小,这会影响模型的性能并使疾病特征不可见[14]。在这种情况下,找到一种有效的增强方法可能会有所帮助。
医疗 VQA 模型可以在医疗 VQA 代理系统中发挥作用,帮助患者理解他们的 X 射线、CT 或 MRI 图像。医疗 VQA 还可以帮助医学领域的学生。准确的模型可以帮助医生和射线专家通过询问有关图像中模糊物体的问题来获取更多信息。
医疗 VQA 是一个新的、尚未得到充分探索的 AI 领域。研究人员设计了各种多模型 VQA 来提高性能。这些多模型需要进一步研究以检测其优缺点并克服局限性。需要对最新模型进行深入分析,以选择一种能够显着提高性能的新型模型结构。除 Lin 等人 [24] 外,已有多项调查关注一般领域的 VQA [1]、[15]、[16]、[17]、 [ 18 ] 、 [ 19]、[20]、[21]、[22]、[23],而 Lin 等人[24]被归类为医疗 VQA 中的第一项调查。表 1包含相关调查。
表 1显示了 2017 年至 2023 年 VQA 领域已发表的调查研究。尽管发表了许多调查研究,表明该领域非常活跃,但这些出版物大多属于一般领域,没有关于医学 VQA、其优缺点或医学领域开放挑战的部分,除了 Lin 等人[24]、Noor Mohammed 和 Srinivasan [26]以及 Lin 等人[27]。Lin 等人[24]和 Mohamed 和 Srinivasan [26]提出了一项医学领域的 VQA 调查研究。这些调查研究调查了为 2018、2019 年和 2020 年 ImageCLEF 挑战设计的方法以及 VQA-RAD 数据集上的两个额外模型。Lin 等人[24] 的研究还调查了除 VQA-Med 2021 之外的公共医学 VQA 数据集,而 Mohammed 和 Srinivasan [26]添加了 VQA-Med 2021 和糖尿病黄斑水肿 (DME) 数据集[28]。此外,他们还讨论了该领域的挑战和未来的研究。Lin 等人[24]和 Mohamed 和 Srinivasan [26]的调查基于 32 项研究的比较,需要进一步研究以涵盖和分析更多方法和数据集。最近的调查,Lin 等人[27],比之前的两次调查[24]、[26]更全面,其中涵盖了 44 项研究和 47 个模型。本调查研究是一项分析性综述,包含 60 项医学 VQA 研究。它比以前的研究更全面。它提出并比较了 75 多个医学 VQA 模型。对于数据集,现有的评论[24]、[26]、[27]分别调查了 8 个、5 个和 8 个数据集,而在本评论中,分析了 16 个数据集。此外,本评论研究将医学领域使用的技术与一般领域使用的技术进行了比较,Sharma 和 Jalal 在 2014-2020 年的研究[22]中调查了 80 个模型。在本评论中,对[22]中的这些研究进行了统计分析,以显示哪些技术主要用于一般领域,并检查这些技术是否影响医学领域的研究人员。
此外,优势、劣势、机会和威胁 (SWOT) 分析技术提供了对主题的清晰视图,可帮助研究人员了解已经完成的工作及其弱点。他们还有机会考虑有关他们可能面临的威胁的新研究。本研究利用 SWOT 全面分析了医学 VQA 数据集、技术、注意力以及视觉+语言预训练模型。分析研究贡献总结如下:
-
提出对现有医疗数据集进行调查,包括其特点、生成以及统计和 SWOT 分析。
-
本调查讨论了医学 VQA 中使用的视觉和文本特征化技术以及融合阶段。还对这些方法进行了统计和 SWOT 分析。
-
对基于 Sharma 和 Jalal [22]的一般 VQA 中的文本和视觉特征化方法进行统计分析,并与医学领域的方法进行比较,以检查一般 VQA 是否对研究人员产生影响。
-
我们提出了挑战并给出了建议,可能有助于研究人员在该领域开展新的研究。
本文的其余部分在第二和第三部分提出了审查假设和方法,然后在第四部分提出了 VQA 问题类型。在第五部分提出了医学基准数据集的调查,然后在第六部分提出了 VQA 评估指标。第七部分提出了医学 VQA 系统,并在随后的部分讨论了讨论和统计和 SWOT 分析。此外,在同一部分中提出了研究人员面临的挑战和建议。最后,我们在最后一节总结了审查。
审查假设
在对 med-VQA 领域的数据集和方法进行基于统计数据和 SWOT 分析的批判性评估时,可以考虑几个假设。这些假设可能包括:
-
代表性数据集:研究所选的数据集被认为是医学 VQA 更广泛领域的典型数据集,包括各种医学疾病、图像类型和问题类别。方法一致性:假设该领域内各种研究中使用的方法遵循一致的指导方针,以便进行有意义的比较和分析。
-
数据质量:假设所审查的研究中使用的数据准确、可靠且注释正确,则数据集的有效性和完整性得到保证。
-
普遍性:假设从评估研究中使用的数据集分析和方法得出的结果和结论可以推广到更广泛的范围并应用于其他医学 VQA 场景。
-
SWOT 框架适用性:假设 SWOT 分析框架是评估数据集和 med-VQA 领域中使用的方法的优势和劣势的合适且有价值的工具。
-
统计分析的有效性:所呈现结果的有效性基于这样的假设:在所检查的研究中进行的统计分析已经得到充分的规划、执行和解释。
-
出版偏见:假设已经评估的研究是目前医学 VQA 领域中可用的相对完整和无偏见的文献样本,并且没有明显偏见地只发表重要或积极的发现。
审查方法
本评论旨在彻底研究和分析医学视觉问答 (med-VQA) 领域的现有基准、技术和模型。评论的方法可总结如下:
-
基于对基于 Sharma 和 Jalal [22]的 VQA 在一般领域的启发的研究贡献,该研究侧重于 2014 年至 2021 年期间发表的研究,并且由于 2018 年医学领域的视觉问答 (VQA) 领域出现,因此我们的调查包括了 2018 年至 2021 年期间发表的最相关研究。为了保持最新状态,我们还考虑了 2022 年和 2023 年发表的一些研究。此外,我们还包括了 2018 年至 2021 年期间进行的所有 imageCLEF 挑战赛的研究。但是,需要注意的是,这项调查不包括 imageCLEF 在 2022 年组织的 med-VQA 挑战赛的任何论文,因为那一年没有发生这样的事件。此外,由于 imageCLEF 2023 会议于 2023 年 9 月举行,因此在该会议上发表的任何论文都不会包括在本次调查中。
-
该评论涵盖并分析了自 2018 年以来 med-VQA 中使用的所有基准,并深入了解了它们的生成方法、大小、验证程序、问题类型、图像类型和局限性。
-
由于模型之间比较的一个标准是性能指标,并且它是 VQA 差距之一,因此讨论了这些指标。
-
该评论探讨了 VQA 组件和技术,以便研究人员在深入研究 med-VQA 模型之前对 VQA 有一个清晰的概述。
-
这些模型被分为几部分,并根据其方法进行了讨论。进行了统计和 SWOT 分析。统计分析侧重于文献中使用的每种方法的频率及其在不同数据集上的性能。此外,还针对每个数据集进行分析,考虑其使用频率和实现的最佳准确度。此外,通用领域的 VQA 比医学领域的 VQA 早三年就开始了。因此,进行了统计分析,以研究研究人员是否影响通用领域的研究人员。
-
SWOT 分析解决了几个关键问题:该领域存在哪些重要的研究方面可以带来重大进展?现有研究的局限性是什么?这些局限性为研究人员带来了哪些机会?最后,研究人员需要注意哪些方面?
-
最后,该评论讨论了医学 VQA 领域面临的挑战,并提出了指导未来研究的建议。
该方法确保对 med-VQA 基准、技术和模型进行全面、系统的分析,并为该领域的研究人员提供宝贵的见解。
医疗 VQA 数据集
许多 VQA 数据集已公开。这些数据集可根据图像类型分为四类:剪贴画、自然、合成和混合。图 2显示了前三种图像类型的示例。据我们所知,九个公开的医疗数据集中有五个。

A. VQA 数据集生成
基于图像用自然语言生成问题和答案对是一种新过程,称为视觉问题生成 (VQG) [29]。此任务背后的主要动机是提供大规模数据集以创建实用的 VQA 代理[30]、[31]。视觉问答对有三种方法:手动、自动(VQG)和半自动。图 3显示了数据集生成类型。手动 VQA 数据集生成基于专家创建问答对,例如 VQA-RAD [10]和 SLAKE [32]数据集。与此方法相关的一个难题是,由于缺乏可用的专家,这些数据集的规模相对较小。由于 VQA 需要大型数据集,因此这些数据集无法提供高效、实用的 VQA 代理。另一种类型的 VQA 数据集生成是半自动化的,基于问答对的自动生成并经过专家认证,例如 VQA-Med 2019。VQG 是指基于无需人工认证即可生成问答对的自动视觉问答对生成方法。RedVisDial [9]、Tools [7]、BACH [7]和 IDiRD [7]数据集是 VQG 的示例。VQG 数据集有两个主要问题:噪音和没有有意义的问答对[10]、[33]。生成的 VQG 任务比 VQA 更智能、更棘手,因为它在设计方法之前需要有关问题信息的深厚背景知识[30]。由于探索所需的努力,VQG 任务尚未经过太多探索[30]。即使可以从经过验证的现有数据集中自动生成数据集,医疗数据集仍然受到大小限制。 ImageCLEF 包含了 2019 年至 2021 年挑战赛中的 VQG 任务。Sarrouti 等人提出了一项全面的 VQG 最新调查[30]。表 2显示了三种数据集生成类型在大小、身份验证、错误、问题意义、成本和信任方面的比较。
使用了 11 种问题类型和 4 种答案类型(“是”或“否”、数字、类别和位置)。
B.现有的 VQA 数据集
2018 年,ImageCLEF-Med 挑战赛[3]号召研究人员开展医学 VQA 挑战赛。他们为 VQA-Med v1 数据集提供了 2,866 张来自 PubMed Central 文章的放射学图像和 6,413 个问答对。这些问题答案是使用 MS-COCO 数据集[34]从相应的图像标题自动生成的。因此,有些问题没有意义。这个数据集存在偏见。同年,VQA-RAD [10]数据集向公众开放。VQA-RAD 是第一个包含临床医生回答问题的手动数据集。它有 315 张放射解剖医学图像;因此,该数据集的一个限制是其规模较小。 2019 年和 2020 年,ImageCLEF-Med 提供了 VQA-Med v2 [31]和 VQA-Med v3 [35]数据集,分别包含 4,200 张放射学图像和 14,292 个问答对,以及 5,000 张放射学图像和 5,000 个问答对。所有 VQA-Med 数据集版本都与普通医学有关。2020 年创建的重置医学 VQA 数据集与特定专业有关。
PATHVQA [8]、RadVisDial [9]、BACH [7]、Tools 和 IDRiD [7]数据集分别涉及病理学、胸部 X 光片、乳腺癌组织学、手术工具和糖尿病视网膜病变专业化。PATHVQA 数据集有 4,998 张病理图像和 32,799 个开放式问题。PATHVQA 数据集的一个问题是,使用语言规则方法[8]从标题创建的问答对缺乏多样性和稳健性。RadVisDial [9]数据集包含 91,060 张 X 光片图像和 455,300 个问答对。这些被分成 77,205、7,340 和 6,515 张图像用于训练、验证和测试。RadVisDial [9]是可用的最大数据集,并且由于它提供外部信息而独一无二。 IDRiD 数据集[36]包含 516 张视网膜彩色眼底图像和 220,000 个问答对。BACH 数据集包含 420 张乳腺癌显微镜图像和 360 个问答对。Tools 数据集包含七种手术工具的数据:抓取器、钩子、双极、剪刀、冲洗器、夹子施放器和标本袋。该数据集包含 2,523 幅图像和一百万个问答对。IDRiD、Tools 和 BACH 数据集包含复杂问题。然而,这三个数据集使用数据集注释作为 QA 的生成方法,这意味着如果原始数据集注释有错误,则可能会出错。
另一个手动医疗 VQA 数据集是语义标记知识增强 (SLAKE) 数据集,该数据集于 2021 年创建[32]。与 VQA-RAD 数据集一样,SLAKE 基于人类专业知识来形成问答对,但它比 VQA-RAD 数据集更大,可以回答更复杂、更复杂的问题,包括疾病致病、器官功能或疾病治疗等查询。SLAKE 是一个公共医学双语数据集,包含英语和中文问答对。它比以前存在的数据集涵盖了更多的人体部位。它包含 642 张放射学图像和 14K 个问答对。它涵盖了 39 个人体部位的 12 种疾病。
2022 年的医疗数据集包括 OVQA 数据集[37]、糖尿病黄斑水肿 (DME) 数据集[28]、EndoVis-18-VQA [38]和 Cholec80-VQA [38]。
OVQA 数据集[37]是根据医院常见问题创建的。医生验证了问题和答案的模板。OVQA 有 19,020 个关于异常、模态、器官、平面、病情存在和属性等的问答对。该数据集分为训练、验证和测试数据集,分别有 2,000、1,235 和 1,234 张图像,与 15,216、1,902 和 1,902 个问答相关。所有问题都与两种模态有关:X 射线和 CT,涵盖六个身体部位:手、腿、头和胸部。该数据集包括 2001 张图像,其中 70% 为 CT,其余为 X 射线图像。
使用了从印度糖尿病视网膜病变图像数据集 (IDRiD) [36]和 e-Ophta 数据集[39]自动生成的糖尿病性黄斑水肿 (DME) 数据集[28]。该数据集有 679 幅图像,其中有 13470 个问答对,分布在 433,112、134 幅图像中,其中 9779、2380 和 1311 幅用于训练、验证和测试数据集。数据集包含有关渗出液等级的问题。数据集包含有五个答案的特定问题。问题已分配给某个区域或整个图像。它被归类为手动生成的数据集。
EndoVis-18-VQA 数据集是通过从 MICCAI 内窥镜视觉挑战赛 2018 [40]数据集中提取图像生成的。每幅图像有两种问题类型:一种是单词答案(EndoVis-18-VQA (C)),另一种是句子答案(EndoVis-18-VQA (S))。问题答案是根据用于工具-组织相互作用检测任务的组织、工具、相互作用注释和边界框生成的[41]。两个版本分别有 1,560 张图像和 9,014 个问答对,以及 447 张图像和 2,769 个问答对,分别用于训练和测试数据集。
Cholec80-VQA 数据集有 21591 张图像,这些图像是从 Cholec80 数据集[42]的 40 个视频序列中以 0.25 fps 采样生成的。每张图像使用原始数据集[42]中提供的相位注释和工具操作与 2 个问题相关。数据集分为两部分;第一部分用于对 14 个单词进行分类 (Cholec80-VQA (C)),第二部分用于句子答案 (Cholec80-VQA (S))。数据集的每一部分都有 17,000 张图像(包含 34,000 个问答对)和 4,500 张图像(包含 17,000 个问答对),用于训练和测试数据集。
最新的医疗数据集是 2023 年发布的面向患者的视觉问答 (P-VQA) [43]。该数据集包含从医院收集的 2169 张 X 射线、CT、MRI 和超声波图像,其中包含 12 个身体部位的 20 种疾病的 24,800 个问答对。p-VQA 数据集提供了一个知识图,显示了属性和疾病之间的 13 种关系类型。这些关系是基于患者的问题建立的。问答对是基于知识图和模板创建的,这些模板是手动编写的。该数据集有 12 种问题类型:症状、器官、疾病、治疗建议、药物、治疗、检查项目、预后、部门、检查建议、预防、发病机制和复查时间。数据集分为 1,526 张图像(包含 17,336 个问答对)、218 张图像(包含 2,575 个问答对)和 425 张图像(包含 4,889 个问答对),分别用于拍摄、验证和测试数据集。图 4 –9显示了上述数据集的示例。表 3显示了所述数据集的摘要。
评估指标
问题有两种类型:多项选择题和开放式问题。在多项选择题中,只有一个正确答案。因此,准确率、召回率和精确率等指标可以给出正确的评估,但由于释义和同义词,这些性能指标在开放式问题中不是精确率指标。因此,VQA 中的开放式问题使用了其他性能指标:Wu-Palmer 相似度 (WUPS) [44]、基于词的语义相似度 (WBSS) [45]、[46]、双语评估替补 (BLEU) [47]、基于概念的语义相似度 (CBSS) [46]、每种类型的平均值 (MPT) 和具有显式排序的翻译评估指标 (METEOR) [47]。下面将讨论每个指标的详细信息。
-
准确率:准确率是预测正确的答案与所有样本数量的比率。
准确性=电视磷+ T否电视磷+ T否+ F磷+ F否。(1)查看源代码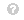
-
召回率/敏感度:召回率或敏感度表示正确预测的正面答案的数量与所有实际正面答案的数量之比。
召回/ S敏感度=电视磷电视磷= F否。(2)查看源代码
-
特异性:特异性是正确的预测的否定答案与所有实际否定答案的数量的比例。
年代特定我的城市=电视否电视否= F磷。(3)查看源代码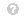
-
精确度:精确度是预测正确的正面答案与所有预测正面答案的数量之比。
磷重新计算=电视磷电视磷= F磷。(4)查看源代码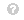
-
F1 分数:
F1 −分数= 2 ∗磷回忆磷撤销+召回(5)查看源代码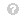
-
WUPS:该指标基于语义含义以及实际答案与预测答案的差异程度。预测答案的真假由阈值决定。WUPS 根据以下公式计算:
西乌磷年代(在)=1否∑我= 1否分钟{∏a∈N最大限度t∈N(在),∏t∈电视我最大限度一个∈电视我} .100(6)查看源代码
在哪里否,在 分别表示问题总数、预测答案和实际答案。西乌磷(在) 返回单词的位置一个 和吨 在分类法中相对于最小共同包含者的位置(在)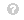
-
WBSS: WBSS 指标基于查找实际答案和预测答案之间的词语相似度得分。WBSS 根据以下公式计算:
年代(问、三)乌乌→我乌←我十我= softmax (西2最大(ReLU (西1乌),0 ))= [乌→;乌←;乌→⊙乌←;乌→−乌←]=格鲁吉亚政府单位(乌→我- 1,十我)=格鲁吉亚政府单位(乌←我+ 1,十我)= [ BERT (q);BERT (丙我)](7)查看源代码
在哪里问 和丙 是问题和背景。年代(问、三) 表示之间的相似度得分问 和丙 。乌 ,乌→ ,乌← 分别是输入嵌入、前向隐藏状态和后向隐藏状态。十我 是通过连接问题的 BERT 嵌入创建的输入嵌入问 和我 第上下文标记丙我 。 -
BLEU: BLEU 指标依赖于分析实际答案和预测答案之间的 n-gram 共现。BLEU 根据以下公式计算:
蓝牙乌= BP.经验(∑n = 1否西n日志磷n)(8)查看源代码
其中 BP、W 和 P 分别表示简洁性惩罚、总和为 1 的正权重和整个语料库的准确率分数。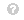
-
CBSS:它几乎与 WBSS 指标相同,只是使用 MetaMap13 进行生物医学概念提取,而不是将基本事实和系统生成的答案标记为文字。
-
MPT:提出此性能指标是为了解决数据集中问题类型分布不均衡或每种问题类型答案分布存在偏差的问题。它基于计算每种问题类型的调和或算术平均准确度。它使用以下公式计算。
米磷电视=∑t = 1电视一个吨/吨或M磷电视= T/∑t = 1电视一个− 1吨(9)查看源代码
其中 T 和 A 分别表示问题类型的数量和问题类型 t 的准确率。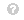
-
METEOR:该指标旨在通过将事实中的单词与预测答案一一对齐来找到相似性。并非总是能找到这样的对齐。以下公式用于计算 METEOR。
米埃电视埃或R = (1 − Pen ) ∗F米額(10)查看源代码
VQA 系统组件
如上所述,VQA 由四个部分组成:图像特征化、文本特征化、融合(联合)(结合图像特征化和文本特征化)、分类器和 V+L 预训练模型。在本节的统计分析中,我们基于我们的最新成果以及 Sharma 和 Jalal [22]在通用领域的 VQA 调查,比较了通用领域的方法和医学领域的方法。
A.图像特征化
为了方便地对图像进行数学运算,将图像表示为称为图像特征的数值向量。 计算图像特征的方法有很多种,例如尺度不变特征变换 (SIFT) [48]、简单的 RGB 向量、方向梯度直方图 (HOG) [49]和 Haar 变换[50]。 在深度学习系统中,例如 CNN,图像特征化向量由神经网络学习。 使用深度学习有两种选择:从头开始训练模型或使用预训练模型。 第一种方法需要高度特定的计算源和大量数据。 因此,预训练模型(如 AlexNet [51]、VGGNet [52]、GoogLeNet [53]和 ResNet [54] [14])已广泛应用于 VQA。 VQA 中最常用的预训练模型是 ResNet,因为它的计算资源成本合理[1]。也可以使用一些深度学习方法的集成[55],[56],[57]。
在此阶段提取视觉特征,最新的 VQA 图像模型基于预先训练的 CNN,例如 ResNet [58]、[59]、[60]、DenseNet-121 [9]和 VGGNet [18]、[46 ] 、[61]、[62]。其他用于关注 VQA 中问题的图像特征提取方法包括多模态低秩双线性 (MLB) [59]、多模态紧凑双线性池化 (MCB) [58]、全局多模态低秩双线性 (G-MLB) [7]和用于视觉问答的多模态 Tucker 融合 (MUTAN) 方法[60]。
B.文本特征
文本特征化阶段负责从问题中选择和提取特征,并使用词嵌入方法将它们表示为数值向量,以应用数学处理。词嵌入有三种类别,即基于计数的方法、基于预测的方法和混合方法。词嵌入中的一个问题是为给定问题选择合适的方法,这取决于反复试验的方法[1]。基于计数的方法使用独热编码、共现矩阵[63]和奇异值分解 (SVD) [64]来计算文本中单词的出现次数。在基于预测的方法中,词语表示是基于模型学习的。神经网络模型[65]、连续词袋 (CBOW) [66]、skip-gram [67](谷歌将其作为开源模型,称为 word2vec)[68]、长短期记忆 (LSTM) [69]、门控循环单元 (GRU) [70]、基于骨架的[55]都是基于预测的词嵌入的例子。混合方法是由基于计数和基于预测的方法创建的。Pennington 等人提出的全局向量 (Glove) 方法[71]就是混合方法的一个例子。问题模型中最常用的方法是 LSTM [8]、[9]、[72]、GRU [8]、[72]、RNN [46]、[73]、[74]、[75]、Faster-RNN [8]、[72]和编码器-解码器方法[7]、[58]、[59]、[60]、[61]、[76]。除了以前的方法之外,还使用了预训练模型,例如用于语言理解的广义自回归预训练(XLNet)[77]和 BERT 模型[61]、[78]。一些模型忽略了文本特征化,将问题转换为图像分类问题[57]、[79]、[80]
C. 融合方法
由于文本和图像特征化都是独立处理的,因此需要将两者融合才能生成答案。融合类型有三种:基线融合模型、端到端神经网络模型和联合注意模型[1]。在基线融合中,使用各种方法,例如串联[81]、元素乘法、元素加法[82]、所有这些方法[83],或这些方法与多项式函数的混合[84]。端到端神经网络模型可用于融合图像和文本特征化。目前使用的各种方法包括神经模块网络(NMN)[85]、多模态 MCB [58]、动态参数预测网络(DPPN)[86]、多模态残差网络(MRN)[87]、跨模态多步融合(CMF)网络[88]、具有深度注意神经张量网络(DA-NTN)模块的基本 MCB 模型[89]、多层感知器 (MLP) [90]和编码器-解码器方法[91]、[92 ] 。使用联合注意模型的主要原因是为了解决文本注意和问题注意之间的语义关系[1]。有各种联合注意模型,如词到区域注意网络(WRAN)[93]、共同注意[94]、问题引导注意图(QAM)[95]和问题类型引导注意(QTA)[96]。
融合阶段还使用了 LSTM 和编码器-解码器等神经网络方法。Verma 和 Ramachandran [61]设计了一个使用编码器-解码器、LSTM 和 GloVe 的多模型。
VQA 注意方案:注意力机制用于识别问题、图像或两者中的语义特征。它通过关注问题中的特定单词并将它们与图像中的特定区域或对象联系起来,改善问题与视觉特征之间的交互。根据注意层数,注意机制可分为单跳注意和多跳注意[22]。Shih 等人[97]开发了一种基于注意机制的 VQA 方法,该方法最近已成为几乎所有架构中的关键元素。当前的研究方向涵盖了共同注意架构,用于在文本和视觉模态中同时产生注意,从而提高预测的准确性[81]、[94]。然而,全局共同注意机制的一个重要挑战是它们对单个图像区域和文本段之间的交互和注意进行建模的能力有限,例如在单词标记级别。为了解决这一难题,人们开发了密集的共同注意网络,包括 BAN [98]和 DCN [99],其中每个图像区域都可以与问题中的任何单词进行交互。因此,这类模型可以对图像与问题的关系产生更精细的理解和推理,从而提高 VQA 性能。尽管如此,在 BAN 和 DCN 等密集共同注意网络中,每个模态都缺乏自注意力,这是一个瓶颈,例如问题中的字与字关系和图像中的区域与区域关系[100]。Yu 等人[100]开发了一个深度模块化共同注意网络(MCAN)来解决这个瓶颈,它由各种模块化共同注意(MCA)层组成。而 MCA 层又包含两个通用注意单元:引导注意(GA)和自注意(SA)。对于后者,SA 可以捕获模型内交互,例如词与词和区域与区域的交互,而 GA 可以捕获跨模型交互,例如词与区域和区域与词,这是使用多头注意架构实现的。尽管这种注意灵活且富有表现力,但也存在问题;特别是,结果始终是模型正在关注的值对的加权组合。当模型无法关注密切相关的上下文时,这可能会带来挑战,例如当某个词没有对应的图像区域或上下文词时。在这种情况下,注意力会导致过多的噪音,或者更严重的是,导致输出向量的分散,从而影响性能。基于 Huang 等人[101]的研究。之后,Rahman 等人使用注意力叠加(AoA)模块解决了这一限制。AoA 模块多次级联,生成新的模块化协同注意力网络(MCAoAN),它是 MCAN [100]的增强版本。通过两个独立的线性变换[101],类似于 GLU [102],AoA 模块既能生成信息向量,又能生成注意门。为了生成信息向量,将查询上下文与注意结果连接起来,然后应用线性变换。Ben-Younes 等人设计了 MUTAN [60],它使用基于多模态张量的 Tucker 分解来参数化问题和图像特征之间的双线性交互。Minh 等人利用内积运算代替应用低秩双线性池化,设计了一个满秩双线性变换 G-MLB [103]来获得显著的答案范围。所有先前的方法都同等重视问题和图像特征。Vu 等人声称,更加关注问题会提高结果。因此,他们设计了一种以问题为中心的多模态低秩双线性 (QC-MLB) 方法[7]。
VQA 模型中使用了各种注意力方案。许多模型使用了 SAN [9]、[10]、[12]、[46]、双线性注意力网络 (BAN) [12]、MCB [10]、[46]和 MFB [61]注意力。2020 年,Kovaleva 等人[9]在模型中应用了两种注意力架构:后期融合网络 (LF) 和递归视觉注意力网络 (RVA)。
D.答案分类与生成
此阶段负责生成答案。大多数研究人员出于方便的考虑设计了分类 VQA 模型,而其他人则设计了答案生成模型。使用了几种方法,例如用于分类的 Softmax 层和用于生成的 LSTM 或 CNN 模型。
E.视觉和语言预训练模型
ResNet [54]、GoogLeNet [53]和 VGG [52]以及其他在 ImageNet [104]上预训练的模型为实现各种下游 CV 任务做出了重大贡献。在一些 NLP 应用中,有一些预训练模型,如 XLNet [77]、BERT [78]和 RoBERTa [105],与最先进的其他基于 Transformer 的模型相比,获得了高精度结果。为了解决这一难题,多名研究人员分别在视觉和语言领域使用了 Transformer 学习,试图在特征融合训练之前使用外部数据对图像特征进行预训练并生成预测[33]。然而,这些研究忽视了预训练特征对跨模型融合的适用性和兼容性程度[33]。
受 XLNET [77]、BERT [78]和其他大规模预训练语言模型的实用性和价值的驱动,最近的研究人员试图在 V+L 数据集[92]上从基于预训练 Transformer 的模型生成图像-文本联合嵌入。反过来,联合嵌入通过一组 V+L 任务进行微调,这已被证明可以产生显著的效果。这些模型的区别在于它们的预训练策略和跨模态架构。具体来说,UNITER [106]和 VisualBert [92]使用单一 Transformer 流来联合学习图像-文本嵌入。相比之下,LXMERT [107]和 ViLBERT [108]在图像和文本输入上合并了一对分离的 Transformer 块,以及用于跨模态的第三个融合 Transformer 块[92]。
该领域的活跃研究提出了预先训练的 V+L 模型[92]、[107]、[108]、[109]、[110]、[111]、[112]、[113]、[106]、[114]、[115]、[116]、[117]、[118]、[119]、[120]、[121]、[122]、[123]、[124]、[125]、[126]、[127]、[128]、[129]、[130]、[131]、[132]、[133]、[134]、[135]、[136]、[137],[138]、[139]、[140]、[141]、[142]、[ 143]、 [144] 、[145]来学习特定 V+L 任务的 V+L 表示。然而,几乎所有先前的研究都没有尝试通过明确解开多模态和结合视觉概念来解决学习这些表示的问题,而且它们不能直接执行下游生成任务[146]。
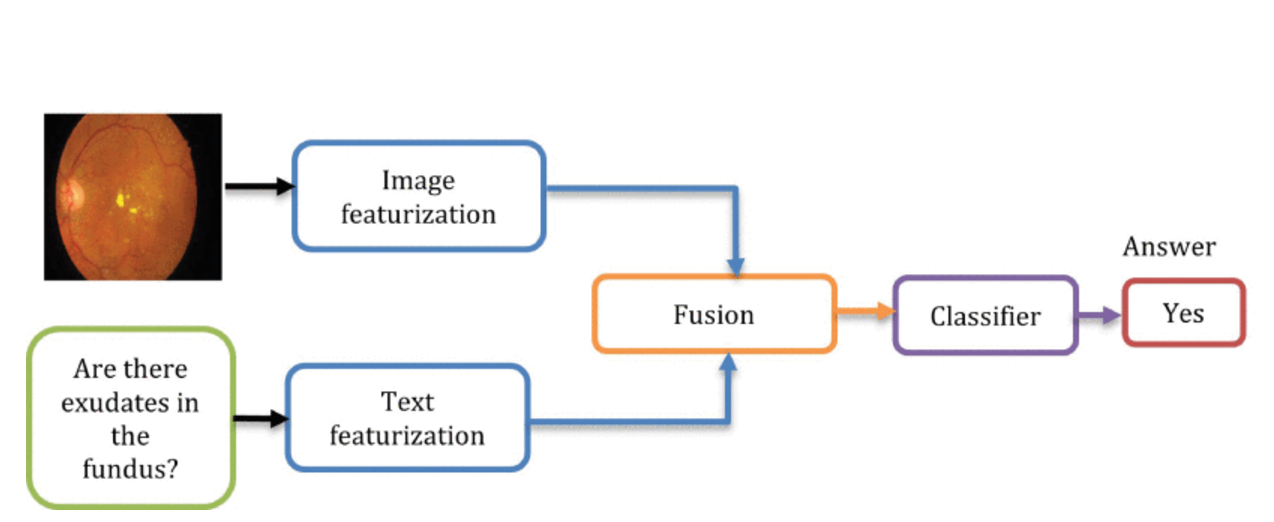
针对视觉或 NLP 进行训练的预训练模型(如 VGGNet 或 Transformers 的双向编码器表示 (BERT))对于 VQA 模型来说效率不高[147]。针对视觉和文本数据集进行训练的其他预训练模型对于 VQA 使用更有效。这些预训练模型的示例包括 UNITER [106]、LXMERT [107]、VisualBERT [92]、PixelBERT [114]和 ClinicalBERT [148]。Li et al. [92]比较了四个 V+L 预训练模型,分别是 VisualBERT [92]、LXMERT [107]、PixelBERT [114]、UNITER [106]、CTL [144]、VLMixter [145]、BLIP [149]、OFA [150]、CoCa [151]、BEIT-3 [152]、PaLI [153]和 BLIP-2 [154]。 他们认为,使用 VisualBERT 的预训练模型的 AUC 性能最高,为 0.987,而使用 PixelBERT 的模型得分最低。表 4展示了在 VQA-Med 2019 数据集上微调的现有预训练模型的性能,以及哪个模型用于医疗领域。
医疗 VQA 模型
医疗 VQA 是一个活跃的话题,已经进行了大量研究。在本节中,我们基于 ImageCLEF VQA 挑战中的模型、基于 CNN-LSTM 的模型、基于图像分类的模型、基于集成的模型、视觉和语言 (V+L) 迁移学习模型以及基于外部知识的模型,提出了医疗领域的 VQA 模型。
A.ImageCLEF VQA 挑战
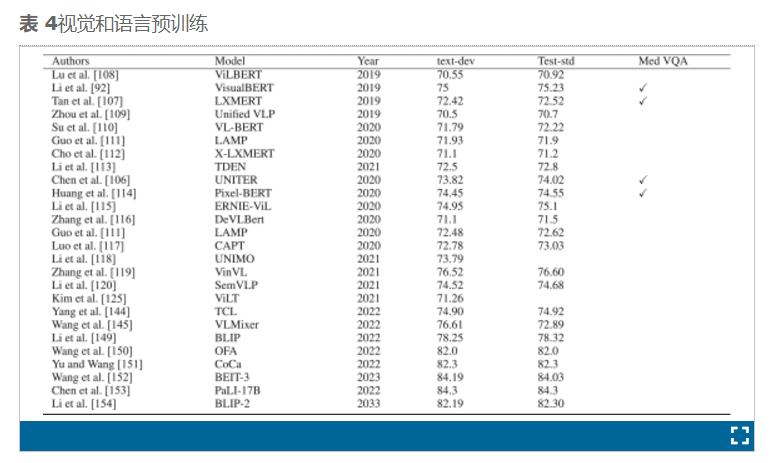
ImageCLEF 每年都会发起挑战,于 2018 年发起了第一届医学挑战赛[3]。虽然有 28 个团队注册参加本次挑战赛,但只有 5 个团队在 17 次运行中提交了结果[46]、[73]、[74]、[75]、[93]。
大多数团队都基于深度学习构建了模型。RNN(例如 BiLSTM 和 LSTM)用于文本特征化,而基于编码器-解码器的框架 VGG、ResNet 和 Inception-ResNet-v2 用于视觉特征化。NLM 参与者[46]使用了 SAN 和 MCB 注意力机制,而 UMMS 参与者[93]使用了 MFB 和 ETM 。他们的模型分别获得了 BLEU 和 WBSS 的最高分数 0.162 和 0.186。NLM 模型获得了最高的 WBSS 性能,得分为 0.338。
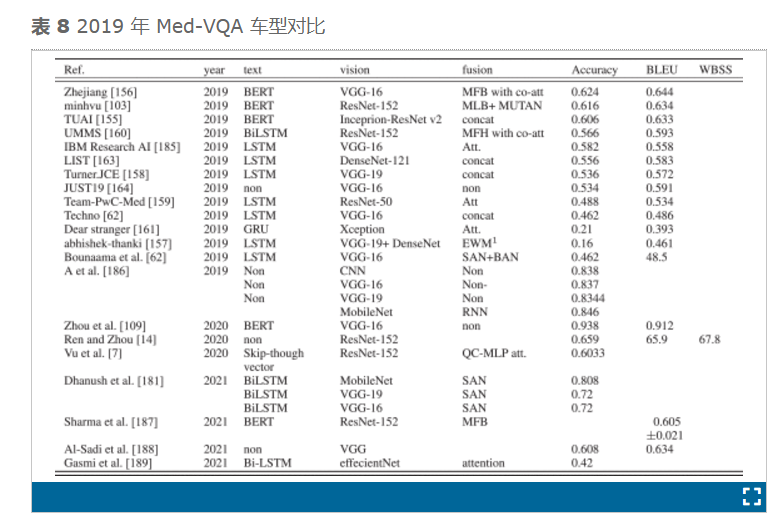
Peng 等人[93]提供了 ImageCLEF 2018 挑战赛的获胜模型。该模型基于 ResNet152,使用 ETM 进行微调以用于视觉,使用 LSTM 进行文本,使用 MFH 进行共同注意,然后使用卷积层和 ReLu 层进行融合。这些模型在第一个挑战赛中的表现被认为很差,但在第二个挑战赛中,性能水平有所提高[31]。最佳 BLEU 得分为 0.644,而 2018 年的最佳 BLEU 性能为 0.162。这一进展表明该领域如何鼓励研究人员开发更强大的医学 VQA 模型。在这次挑战中,17 支队伍[62]、[103]、[155] 、[156 ] 、[157]、[158]、[159]、[160]、[161]、[162]、 [ 163]、[164]提交了 90 次运行[31]。与第一个挑战一样,基于深度学习的模型使用 RNN 和 CNN(带或不带预训练模型),并专注于将文本与图像对齐。获胜的 Hanlin 模型分别基于 VGG-16 和全局平均布尔、BERT 和视觉文本和融合阶段的共同注意[156]。
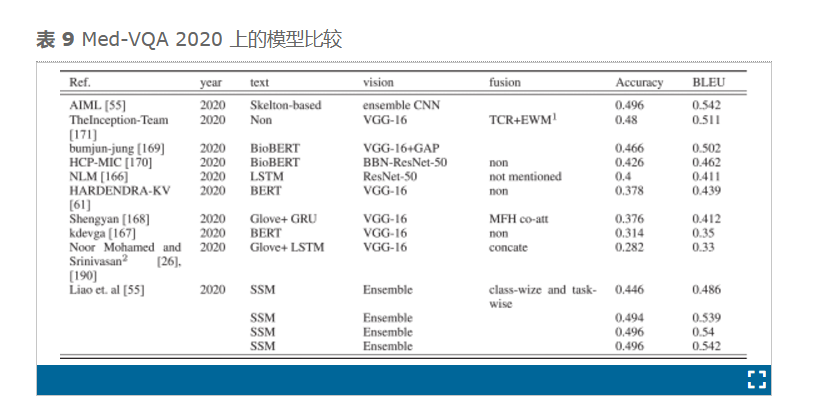
与前两届挑战赛一样,ImageCLEF 2020 和 ImageCLEF 2021 也基于深度学习[35]、[165]。在 ImageCLEF 2020 挑战赛中,有 30 支团队报名,11 支[35]、[61]、 [ 166 ] 、[ 167]、[168]、 [169] 、[170]、[171]和 62 支团队参加比赛。本次挑战赛采用了 CNN(例如 VGGNet 和 ResNet)、Transformer(例如 RNN 和 BERT)、多模态分解双线性 (MFB) 池化和多模态分解高阶池化 (MFH),分别用于视觉、文本和融合。廖等人[55]是 2020 年的获胜者。他们设计了一种基于骨架的句子映射 (SSM) 的方法。在视觉方面,他们基于 VGGNet、DenseNet、ResNet、NextNet 和 mobileNet 制作了几个模型,并从所有这些视觉部分制作了几个集成模型。获胜模型是所有这些模型的集成,但版本不同。对于融合,使用了类别和任务。使用最后预训练视觉模型的集成的最佳模型分别实现了 0.496 和 BLEU 性能。
在 ImageCLEF 2021 中,在 VQA 任务中分别有 48、13 [57]、[79]、[80]、[ 165 ] 、[172]、 [173] 、[174]、[175]、[176]和 68 个注册团队、提交团队和运行[165]。大多数 VQA 多模型的视觉部分基于 CNN 模型,例如 ResNet、VGG 和 DenseNet,而文本部分基于 LSTM 和基于 Transformer 的模型,例如 BioBERT 和 BERT。融合部分基于池化策略,例如 MFH 和 MFB。获胜的 SYSU-HCP 模型基于集成学习,BLEU 和准确率分别为 0.416 和 0.382 [57]、[165]。他们的模型基于八个模型:ResNeSt-50、ResNet-50、VGG-19、VGG-16、ResNeSt-50-HAGAP、ResNet-50-HAGAP、VGG-19-HAGAP 和 VGG-16-HAGAP。他们在训练过程中使用混合策略增强了数据。表 6总结了 2018 年至 2021 年的 ImageCLEF 挑战。
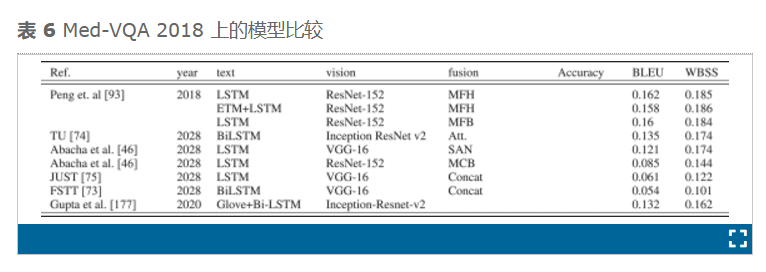
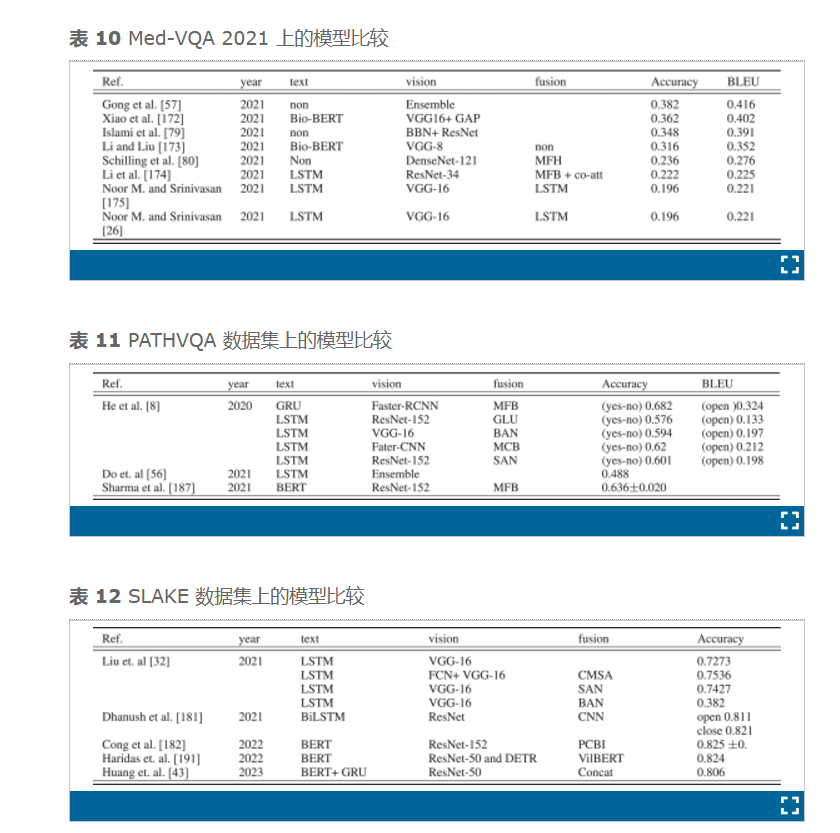

Al-Hadhrami 等人2是基于贪婪汤技术的多个 Al-Hadhrami 等人 1 模型的融合。
B.基于 CNN-LSTM 的模型
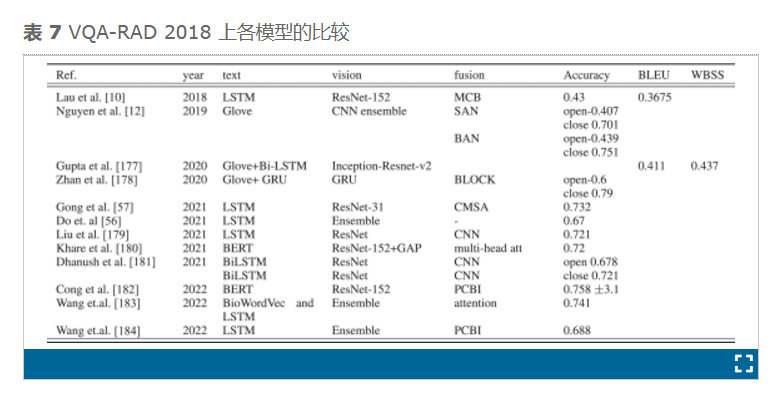
大多数模型都属于基于 CNN-LSTM 的方法。这些模型旨在解决该领域的问题,例如数据限制、所需的答案类型以及文本和视觉推理。医学问题的答案取决于最终用户[177]。当最终用户是患者或学生时,答案可能很简单;例如,“是”或“否”就足够了,但是当最终用户是医生或专家时,答案应该有更多细节。因此,Gupta 等人提出了一种分层多模型,该模型依赖于使用 SVM 传统机器学习分类对问题进行分离,以将答案提供给最终用户。他们的模型基于使用 Glove 和 BiLSTM 技术进行文本特征化,以及使用 Inception-Resnet-v2 预训练模型进行视觉特征化。他们使用连接层连接这些特征,然后使用批量归一化层。他们在两个公共数据集上评估了他们的模型:RAD-VQA 和 VQA-Med v1。在两个数据集和组合数据集上,带有隔离问题的模型的表现优于没有隔离问题的模型。该模型在 RAD、VQA-med、RAD-VQA+VQA-med 数据集上的 BLEU 分别为 0.411、0.132、0.257,在这三个数据集上的 WBSS 分别为 0.437、0.162 和 0.288。他们的模型表现并不优于 Zhou 等人[74] 的模型,后者与他们的模型不同之处在于使用了融合方法。Zhou 等人[74]也使用了注意力机制。他们的模型存在错误,他们声称这些错误可能会返回到自动生成数据集,或者显示出性能指标不合适。
在融合阶段之前使用预训练模型作为限制数据问题的解决方案可以提高准确率,但没有考虑文本和图像之间的对齐问题[33]。因此,Gong 等人提出了一种跨模型自注意力 (CMSA) 来解决这个问题,并使用外部数据集重新制定了预训练模型,以将其用于多模态数据集的多任务模型。他们的模型基于 ResNet-31 和一个解码器,其中三个 MLP 层用于视觉阶段,LSTM 用于文本阶段,CMSA 用于融合。他们使用 CMSA 将注意力集中在图像编码器上进行表示学习,而不是融合特征。作者在 RAD-VQA 和三个外部数据集上评估了他们提出的模型:胸部 X 光 2、脑部 MRI [193]和腹部 CT 1。该模型对开放式、封闭式和总体的准确率分别达到了 61.5%、80.9% 和 76.3%。
大多数 VQA 学习单一推理以进行融合表示,这更适合封闭式问题而不是开放式问题。Zhan 等人建立了一个多模型,学习每个 TCR 和 QCR 问题类型的不同推理表示[13]。他们的模型是一种多层次推理技能,适用于复杂的医学 VQA 任务。他们的模型以 Nguyen 模型[12]为基础。他们在 VQA-RAD 数据集上评估了他们的推理模块,对开放式、封闭式和整体问题分别取得了 60%、79.3% 和 71.6% 的准确率。
C.基于图像分类的模型
尽管视觉问题是模态问题,但一些作者更喜欢将问题转换为图像分类问题并使用答案作为标签。这种方法面临着一个普遍的问题,因为问题可能会发生变化。此外,模型无法知道问题是否被负面地提出。尽管情况确实如此,但 ImageCLEF 2021 挑战赛中的七个小组中有三个使用了这种方法[57]、[79]、[80],而所有者模型是基于这种方法[57]。Lubna 等人[186]提出了一个基于 ImageCLEF 2019 产生的模态问题的 VQA 系统。他们将问题转换为图像分类问题,并从头开始应用了四种模型结构,即 VGG-16、VGG-19、MobileNet 和 CNN。他们的模型准确率分别为 VGG-16、VGG-19、MobileNet 和 CNN 的 0.838、0.8344、0.846 和 0.838。
D.基于集成的模型
Nguyen 等人利用 MAML 解决了数据限制问题和嘈杂的医学图像[12]。该模型基于 LSTM、MEVF 和用于文本、视觉和融合阶段的注意机制。他们还使用卷积去噪自动编码器 (CDAE) 来降低噪音。他们的模型在 VQA-RAD 数据集上对开放式和封闭式问题的准确率分别为 43.9 和 71.5。该模型显示出其局限性,因为文本嵌入基于 GloVe,这可能会对较大的语料库造成问题,并且他们将问题缩减为 12 个单词。
大多数医学 VQA 在视觉阶段使用了迁移学习技术来避免数据限制,但对一般图像进行训练的预训练模型与医学图像不同。医学图像也是嘈杂的图像标签。为了解决这些问题,Do 等人设计了一种用于医学 VQA 的多元模型量化 (MMQ) 方法[56]。
他们利用模型激动元学习 (MAML) 来增加基于自动注释的元数据。MMQ 有三个模型:基于 MAML 的图像特征提取元训练;基于自动注释的数据细化,以增加数据并超越嘈杂标签的限制;以及具有元模型选择决策的元量化,以保证最佳性能。他们在两个数据集上评估了他们的模型:RAD-VQA 和 PathVQA。Glove 预训练模型用于文本阶段,而 SAN 和 BAN 交替用于注意。具有 BAN 注意力的模型在 PathVQA 和 RAD-VQA 上分别获得了最高的准确度得分,分别为 48.8% 和 67%。
VQA 需要高可靠性和性能,可靠的数据集可以实现这一点。只有一个数据集 (VQA-RAD) 经过专家验证,而其他数据集则通过半自动创建或自动创建[32]生成。由于 VQA-RAD 是一个小型数据集,Liu 等人创建了一个新的医学数据集 SLAKE,它由专家创建,比 VQA-RAD 更广泛[32]。此外,外部知识可以增强 VQA 模型的性能和鲁棒性。因此,他们创建了一个从维基百科的大规模知识库中提取的医学知识库。他们为文本、视觉和融合阶段构建了基于 LSTM、VGG 和 SAN 的两个模型。这两个模型的主要区别在于,一个模型基于在使用 VGG 之前对图像应用 FCN 分割。最后一种方法将英语的准确率从 72.73% 提高到了 75.36%。他们针对中文训练了没有使用 FCN 分割的模型,取得了 74.27% 的准确率,但这个准确率还未达到实际医疗应用所需的标准[32]。
2020 年和 2021 年最近两届 ImageCLEF 挑战赛的获胜者 Liao 等人和 Gong 等人使用了集成方法[55]、[57]。2021 年 ImageCLEF 挑战赛的另一支队伍使用集成技术获得第三名,准确率和 BLEU 值分别为 0.348 和 0.391。Eslami 等人[79]模型基于将 VQA 问题转换为图像分类问题并忽略文本部分。它也是这次挑战赛的获胜者[57]。
E.具有 V+L 预训练模型的模型
根据 Li 等人[147]的研究,V+L 预训练模型在视觉和文本任务中的表现优于 RNN-CNN 模型。他们比较了四个 V+L 预训练多模态模型:UNITER [106]、LXMERT [107]、VisualBERT [92]和 PixelBERT [114]。所有这些预训练模型都在文本嵌入上使用了 BERT。由于 clinicalBERT 预训练模型在医疗领域的效果优于 BERT,因此 Lie 等人认为用 clinicalBERT 替换 UNITER、LXMERT、VisualBERT 和 PixelBERT 预训练多模型中的 BERT 预训练模型,会得到比原始多模型更好的多模型。然而,所有新的多模型的表现都比原始多模型差。出现这种情况的原因有很多:1)他们只训练了模型 12 个 epoch,这可能不足以调整权重;2)UNITER 和 PixelBERT 有两个版本的模型:基本模型和更深层次的模型。他们只配置了基本模型,这不是最好的选择;3)在 PixelBERT 中,他们冻结了视觉部分并复制原始权重以将其与 clinicalBERT 文本嵌入一起使用。这些权重需要调整。在那四个 V+L 预训练模型的基线性能中,PixelBERT 在 COCO 数据集中取得了最高的性能,而 visualBERT 在相同数据集中取得了最差的性能。在 Li 等人的研究中,PixelBERT 在 MIMIC-CXR 数据集中取得了最低的性能,而 visualBERT 在相同数据集中取得了最高的性能。我们认为,出现这种结果是因为他们之前的实验存在局限性,选择了较浅的模型而不是较深的模型。
F.基于知识库的模型
医疗 VQA 需要有关疾病和患者病史的信息。现有数据集中不包含此信息。因此,需要外部知识库来增强模型的鲁棒性并使其更加实用。Lui 等人[32]和 Zheng 等人[178]利用外部知识训练他们的模型。Lui 等人[32]创建了 SLAKE 数据集并在创建的数据集中展示了基线分数。Zheng 等人[178]设计了一个模型,该模型分别在文本、视觉和融合阶段使用了 BERT、带 GAP 的 VGG-16 和 BLOCK。该模型在 VQA-Med 2019 数据集上取得了最高分:BLEU、准确率、精确率、召回率和 F 均值分别为 91.2%、93.8%、95.7%、95.9% 和 95.8%。虽然分数很高,但模型训练的数据集具有较高的偏差;没有提到有关这个问题的澄清,也没有提到使用数据可视化来检查模型是否学习了文本和视觉之间的对齐,或者结果是否源于数据集偏差。
Kovaleva 等人[9]在 RedVisdial 数据集上使用患者病史训练模型,该模型使用 LSTM 和 DenseNet-121 作为文本和视觉部分。他们设计了三个具有相同文本和视觉部分的模型,并采用了三种不同的融合方法,即 SAN、LFM 和 RVA 注意力,这三种模型的宏观平均得分分别为 34、33 和 33。所使用的患者病史仅基于一句话。
G. VQA 与其他任务
最近,Cong 等人[182]利用图像标题任务给出了医学 VQA 中图像的汇总信息。此信息被嵌入并与问题和图像特征合并,以增强分类任务的性能。他们分别利用 ResNet-152、BERT 和渐进紧凑双线性交互 (PCBI) 进行视觉特征化、文本特征化和融合阶段。该方法在 RAD-VQA 和 SLAKE 数据集上进行了验证,在开放、封闭和整体数据集上分别取得了 69.8 (+8.7)、79.8 (-0.6)、75.8 (+3.1)、80.2 (-1.0)、86.1 (+2.7) 和 82.5 (+0.4)。该方法的一个局限性是图像标题任务会影响最终分类获得的错误信息。

第八部分。
讨论与分析
由于深度学习在医学对象检测和分类中的有效性,大多数研究人员倾向于利用 CNN 进行视觉特征提取。一些研究人员从头开始构建 CNN,而另一些研究人员则利用了预训练模型,如 ResNet、VGGNet 和 BERT。然而,专注于大型图像或文本数据集的预训练模型削弱了模型的泛化能力。Li 等人[147]证明基于 V+L 预训练模型的 VQA 模型优于基于 CNN-RNN 模型的模型。因此,现有模型的整体性能需要增强。虽然 Vu 等人[7] 的宏观准确率超过了 90%,但由于数据不平衡,他们在 BACH 和 VQA-Med v2 上的召回率不到 10%。Zheng 等人的模型在 VQA-Med v2 [178]上的准确率达到了 93.8% ,但 VQA-Med v2 的一个主要限制是偏差。例如,周等人未能表明这一结果是否是由于数据集偏差而获得的,这一点尤其令人担忧,尤其是考虑到 Lubna 等人[186]在未使用任何问题的情况下就达到了 80.8% 的准确率。
根据一个最先进的例子,我们得出结论,能够改进这种模型的因素包括利用视觉方面的集成学习、GAP 和使用外部知识库,例如[178]。我们进行了两种类型的分析:统计分析和 SWOT 分析。统计分析旨在帮助研究人员了解哪些方法主要用于医学 VQA,以及哪些方法对提高性能有显著影响。因此,这种分析可以帮助研究人员在决策过程中确定其模型所需的技术。同时,SWOT 分析可以帮助解释医学 VQA 的优势、劣势、机会和威胁,从而提供有助于未来研究的见解。
A.统计分析
在本小节中,我们旨在展示医学领域 VQA 模型的统计分析,并将结果与一般领域的结果进行比较,以检查后者如何启发医学研究人员。本讨论中还介绍了医学 VQA 基准的统计分析。
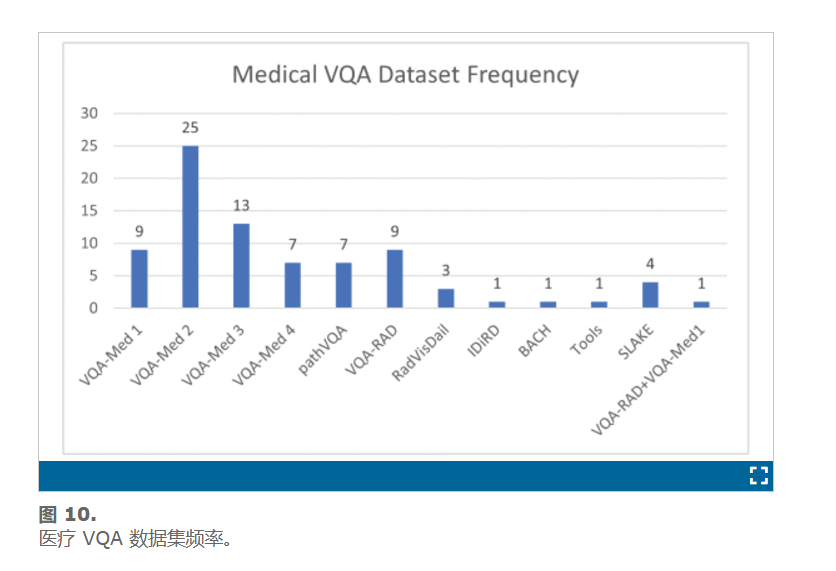
2)医疗 VQA 多模式
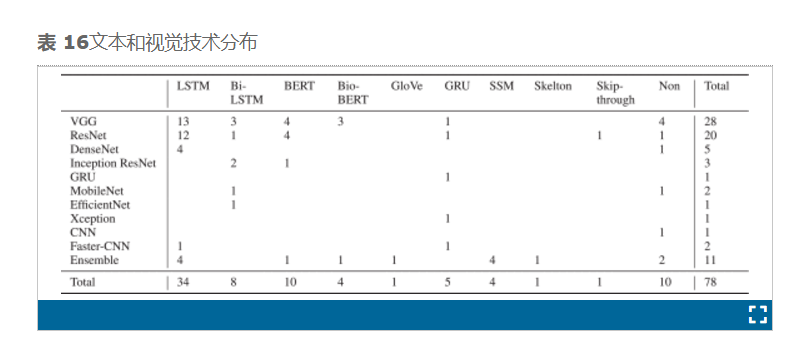
在表 6中–14中,我们比较了 75 多个 VQA 模型在医学领域的结构和性能。表 16总结了研究结果,其中详细介绍了研究人员经常使用的视觉和文本编码方法,并强调了主要使用哪种组合。长短期记忆 (LSTM) 是医学 VQA 中最常用的文本编码方法,使用率为 44%,其次是无文本编码和 BERT。然后将 VQA 转换为图像分类问题,使用率为 13%。忽略 VQA 中的文本特征化阶段会限制答案的生成,从而导致模型内的泛化问题。虽然一些使用这种方法的模型取得了显著的表现,比如 Gong 等人。[57],他在 ImageCLEF 2021 挑战赛中获胜,或在 ImageCLEF 2020 挑战赛中获得第二名的 Al-Sadi 等人,但这并不意味着它代表了实用 VQA 的好选择,尤其是在医学环境中。在 VQA 中取得高分而忽略多模态的一部分则表示数据集中存在偏差问题。除了这两种方法之外,还使用了 Bi-LSTM 和 GRU,分别实现了 10% 和 7% 的比率,而 SSM 和 BioBERT 的比率均为 5%。其他方法(例如基于骨架的方法、跳过方法和 Glove)很少使用。ImageCLEF 2020 中的获胜模型采用了基于骨架的方法[156]。
在视觉方面,共检测到 11 种方法。使用率最高的是 VGGNet、ResNet、Ensemble 和 DenseNet,占 95%。78 个模型中有 28 个使用了 VGGNet,占 34%。78 个模型中,分别有 20、14 和 5 个使用了 ResNet、Ensemble 和 DenseNet。虽然研究人员描述了他们选择多模态部分的各种原因,但本综述中所有提出的模型的表现都表明,这些解释揭示了对如何在模型内部操纵数据的理解不足。因此,需要一个更成功的表示来解释模型的行为和模型内部的数据可视化。图 11展示了文本特征化、视觉、融合和文本-视觉组合方法的分布率。
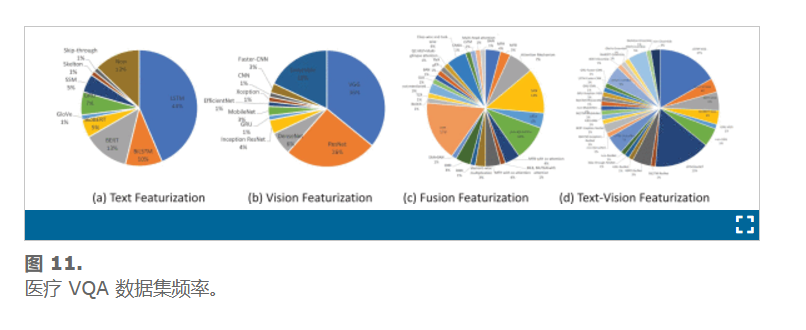
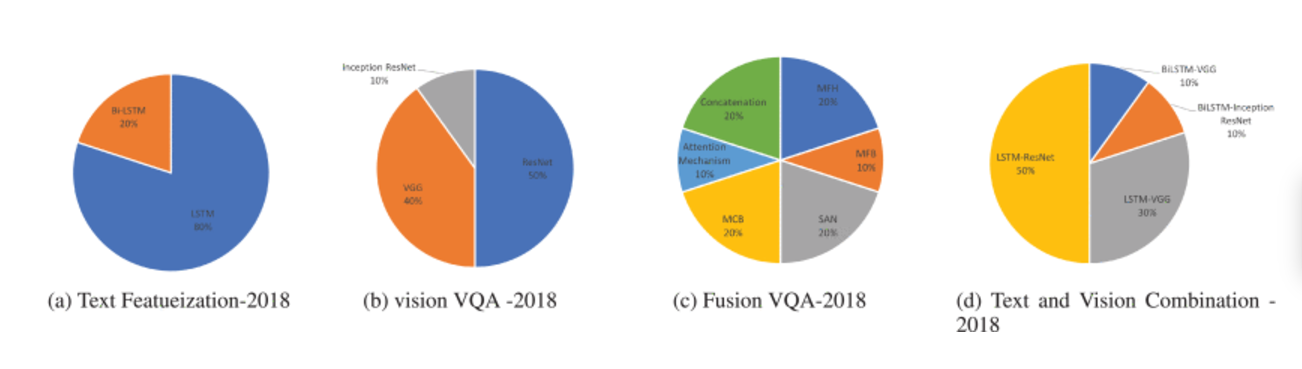
图 12.
医疗 VQA 技术 - 2018 年分布。
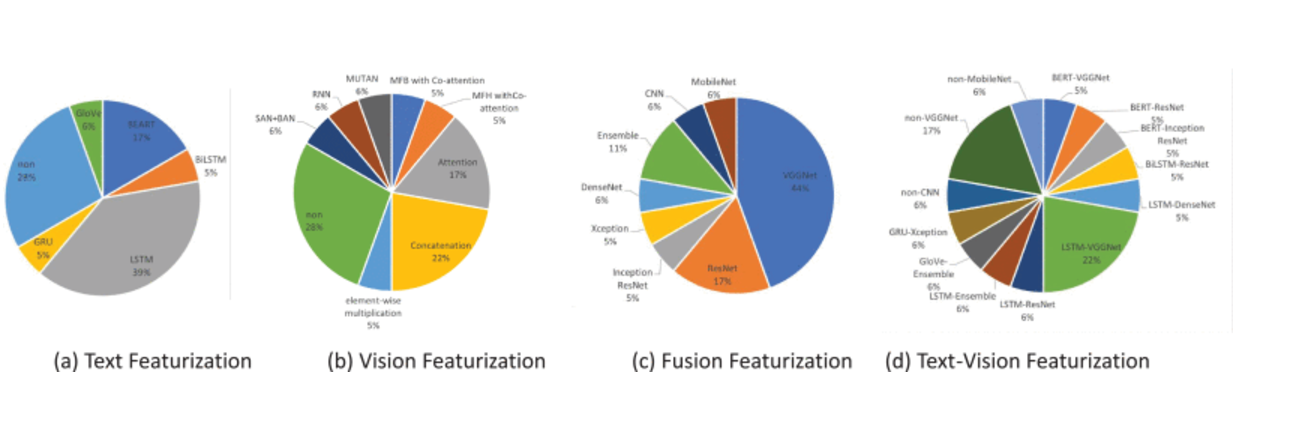
图 13.
医疗 VQA 技术-2019 分布。
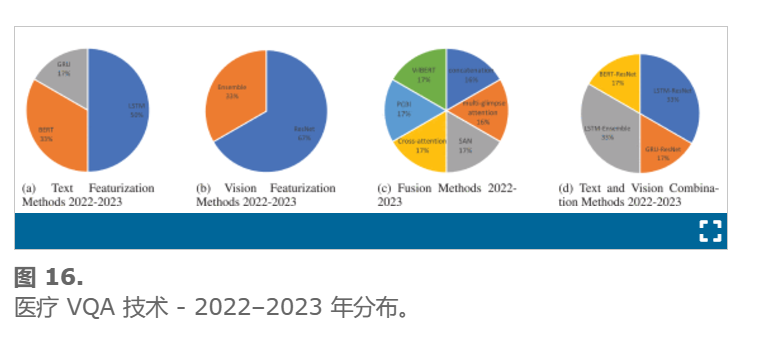
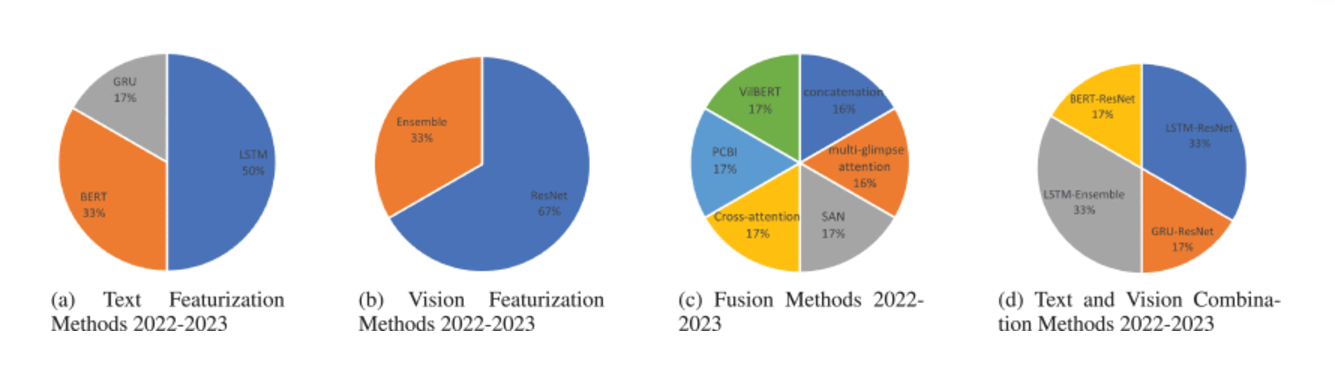
为了评估使用多模式部件随时间的变化,我们从 2018 年到 2023 年每年分析这些方法。图 14 –18显示了文本、视觉、融合以及文本和视觉技术在每个实例中的分布。每年的分布分别为 10、18、26、18、5 和 1 个模型。由于 2023 年只有一个模型,我们将其分析与前一年 2022 年合并。我们发现 VGGNet 是 2019 年、2020 年和 2021 年主要使用的视觉预训练模型,使用率分别为 40%、35% 和 42%。相比之下,ResNet 在 2018 年和 2022-2023 年的模型中使用率分别为 50% 和 67%,而 VGGNet 在 2018 年的使用率为 40%,在 2022-2023 年没有使用。另一方面,LSTM 是使用最广泛的文本特征化技术,六年间分别有 80%、39%、35%、50% 和 50% 的模型使用 LSTM 机器学习方法进行文本编码。因此,LSTM-CNN 组合技术是医学领域使用最多的多模态 VQA,2018 年至 2023 年的比例分别为 80%、49%、36%、50% 和 33%。然而,LSTM-CNN 的高利用率未能在这四年的任何医学 VQA 数据集上实现最高性能。融合部分是 VQA 多模态中最关键的阶段。采用了不同的技术,如图12所示-16(三)
我们对 2018-2021 年 ImageCLEF 挑战赛中使用的模型进行了统计分析。2022 年,ImageCLEF 没有要求 VQA 挑战赛。图 17显示了这些实例中基于其团队发布的模型使用的统计视觉、文本和融合技术。发表论文数量分别为 6 篇[46]、[46]、[62] 、[73 ] 、 [ 74]、[75]、[93],12 篇[103]、[155]、[156 ] 、[157]、[158]、[159]、[160]、[161]、[162 ] 、 [ 163]、[164],8 篇[35]、[61]、[166]、[167 ] 、 [ 168]、[169]、[170]、[171],以及 7 篇[57]、[79]、[80]、[165]、[172]、[173]、[174]、[175]、[176]。 2018、2019、2020 和 2021 年。在视觉阶段,从图 17可以清楚地看到,四个挑战赛中主要使用 VGG 和 ResNet 预训练模型。最近两年使用了 Ensemble 和 BBN-ResNet,因为它们对通用 VQA 和最近的医疗 VQA 有积极作用。这两年的获胜模型都是集成模型。
在文本阶段,2018 年和 2019 年的挑战赛中,大多数参赛者使用了 LSTM,而 2020 年则倾向于使用 BERT 和 BioBERT 等 Transformer。然而,在 2021 年,由于数据集仅包含异常问题,一些参赛者忽略了文本部分并将问题转换为图像分类。与其他方法相比,基于骨架的文本特征化在 2020 年的挑战赛中证明了其有效性。
挑战中部署的大多数融合技术都涉及使用注意力机制,如图17-(c)所示。在 2021 年的挑战中,大多数模型都没有使用融合方法,因为将问题转化为图像分类,或者因为作者在论文中没有提到它。
除了医学领域的 VQA 分析之外,我们还基于 Sahani 等人 (2021) [23]所做的最全面的调查,对视觉和文本特征化一般领域的 VQA 进行了分析。Sahani 等人[23]回顾了 2014 年至 2020 年一般领域的 VQA。自 2018 年医学 VQA 开始以来,我们将这些方法分为两个时间段进行分析:2014-2017 年[58]、[59]、[60]、[82]、[85 ] 、 [ 86 ]、[87]、[95]、[97 ] 、 [ 195 ]、[196]、[197]、[198]、 [199] 、[200]、[201]、[202]、[203]、[ 204]、 [205] 、[206]、[207]、[208]、[209]、[210]、[211 ] 、[212]、[213]、[214]、[215]、[216]、[217]、[218]、[219]和 2018–2020 年[4]、[81]、[88 ] 、[89]、[96]、[98]、[137]、[220]、[221]、[222]、[223]、[224]、[225]、[226]、[227]、[228]、[229]、[230]、[231]、[232]、[233]、[234]、[235]、[236]、[237]、[238]、[239]、 [240] 、[241 ]、[242]、[243]、[244]、[245]、[246]、[247]、[248]、[249]、[250]。图 20 显示了 2014 年至 2020 年期间通用领域中文本和视觉特征化方法的分布。我们还比较了多模态结构是否遵循 Sahani 等人的[23] ,以显示通用领域中使用的方法是否影响了医学 VQA 的研究人员。
从图 18中可以清楚看出,在文本特征化方面,2014 年至 2017 年,LSTM 是使用最广泛的技术,与其他方法的差异率很大。然而,从 2018 到 2020 年,它的使用减少了约 30%。但在医学领域情况并非如此,42% 的模型使用了 LSTM,如图11所示。研究人员在 2018 年至 2020 年更喜欢使用 GRU。然而,GRU 很少用于医学 VQA,在本文提出的方法中,使用率为 6%。另一方面,通用 VQA 模型在 2014 年至 2017 年使用 VGGNet 作为视觉特征化方法,但从 2018 到 2020 年,通用 VQA 使用 VGGNet 减少了约 75%,与之前相比,ResNet 的使用增加了约 66.7%。这一分析表明,医学领域的研究人员并没有遵循 VQA 的总体发展。
B. SWOT 分析
本节对医疗 VQA 数据集进行 SWOT 分析,以展示其主要特征,帮助研究人员创建新的数据集或找到可以克服其现有局限性的方法。它还对医疗领域现有的多模态 VQA 以及视觉和语言预训练模型进行了 SWOT 分析。
1)医疗 VQA 数据集
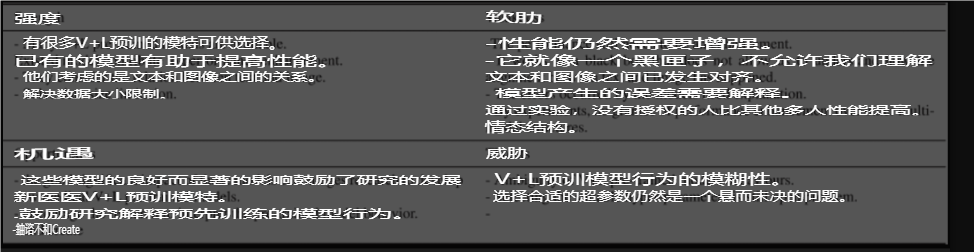
VQA 需要庞大的数据集。没有复杂问题的简单数据将导致无法回答复杂问题的简单模型。在医学 VQA 中,虽然 ImageCLEF-Med 每年都会提供最新数据,使研究人员可以增强现有数据或生成新数据,但这些数据在开发现实世界中使用的稳健实用模型方面仍然不足[8]。限制归结为细节的大小,细节需要足够大才能处理各种问题。此外,有限的数据以及有关图像或患者病史的信息不足限制了现实世界的医学 VQA 代理系统[8]。尽管 Kovaleva 等人[9]提出了患者病史数据,但这只是基于一句话提取的。此外,不平衡数据或有偏差的数据是另外两个数据限制,而使用的自动数据生成方法无法创建稳健的数据[10]。这些不同的数据障碍足以影响 VQA 模型的性能。虽然研究人员提出了不同的解决方案和多模型来超越现有边界并提高整体性能,但这些努力仍然无效。
表 17显示了医疗 VQA 数据集 SWOT 分析的摘要
2)医疗 VQA SWOT 分析
医疗 VQA 是一个新领域,需要进行全面分析才能实现一个可供医务人员信赖的实用 VQA 代理。虽然它代表了一个新的研究领域,但现有的研究已经取得了重大进展,这体现在过去四年中性能的提高。已经为 VQA 的融合阶段开发了各种技术。然而,就医疗 VQA 而言,仍然存在各种弱点,并且该领域的性能水平仍然被认为太差,无法在现实环境中部署。必须做大量工作来提高性能,特别是考虑到迄今为止对所提出的错误和模型行为提供的解释不足。专家验证的大量可信数据集的泄露也是一个持续存在的问题。目前还没有专门为医疗领域设计的 V+L 预训练模型,这为研究人员寻找解决方案提供了机会。
【
V+L 预训练模型即视觉与语言预训练模型,是一种旨在通过大规模的图像和文本数据进行预训练,从而学习到图像和文本之间的语义关联和联合表示的模型,以下是具体介绍:
模型背景
随着人工智能技术的发展,人们希望计算机能够像人类一样,同时理解视觉信息(如图像)和语言信息(如文本),并在两者之间建立有效的联系,因此 V+L 预训练模型应运而生.
模型原理
- 数据收集:收集大量的图像 - 文本对数据作为训练集,这些数据涵盖了各种主题和场景,例如自然风景图片与对应的文字描述、人物照片与人物简介等 。
- 特征提取:使用卷积神经网络(CNN)等图像编码器对图像进行特征提取,得到图像的特征表示;同时,使用词向量模型或 Transformer 架构等文本编码器对文本进行特征提取,得到文本的特征表示.
- 预训练任务设计:通过设计一系列预训练任务,让模型学习图像和文本之间的关系,常见的预训练任务包括:
- 图像 - 文本匹配(ITM):判断给定的图像和文本是否匹配或相关,例如判断一幅图片和一段文字描述是否对应同一内容.
- 掩蔽语言建模(MLM):类似于自然语言处理中的语言模型任务,随机掩蔽文本中的一些单词,让模型根据图像和其他未被掩蔽的文本信息预测这些被掩蔽的单词.
- 掩蔽区域建模(MRM):类似于 MLM,但针对图像中的区域进行掩蔽和预测,模型需要根据文本和其他未被掩蔽的图像区域来预测被掩蔽的图像区域信息.
- 对比学习:将正样本(匹配的图像 - 文本对)和负样本(不匹配的图像 - 文本对)进行对比,让模型学习区分它们,从而更好地理解图像和文本之间的语义相似性和差异性.
- 预训练过程:模型在大规模的图像 - 文本数据集上进行无监督的预训练,通过不断优化预训练任务的损失函数,调整模型的参数,使得模型能够学习到图像和文本的联合表示,预训练完成后,模型可以在各种下游任务上进行微调,以适应具体的任务需求.
模型优势
- 强大的语义理解能力:能够同时理解图像和文本的语义信息,从而在涉及图像和文本交互的任务中表现出色,如视觉问答、图像字幕生成等。
- 数据驱动的泛化能力:通过在大规模数据上进行预训练,模型可以学习到丰富的语义知识和通用的特征表示,从而能够更好地泛化到未见过的数据和新的任务场景中。
- 多模态融合能力:有效地融合了视觉和语言两种模态的信息,为多模态应用提供了更强大的基础,例如图像检索、视频理解等领域。
常见的 V+L 预训练模型
- VisualBERT:将 BERT 架构扩展到视觉领域,通过将图像特征与文本标记相结合,实现了图像和文本的联合建模.
- LXMERT:在 VisualBERT 的基础上进行了改进,引入了更多的跨模态交互机制和预训练任务,提高了模型对图像和文本的理解能力.
- UNITER:由微软团队提出,设计了掩蔽语言建模、图像 - 文本匹配和掩蔽区域建模等预训练任务,在多个视觉与语言下游任务上取得了优异的成绩.
- CLIP:通过对比学习的方式,将图像和文本映射到同一特征空间中,从而实现了图像和文本的快速匹配和检索,该模型在零样本学习和图像分类等任务上表现出色.
- FashionViL:针对时尚领域的特点,提出了多视图对比学习和伪属性分类等预训练任务,能够更好地处理时尚领域的图像和文本数据,在时尚相关的下游任务中达到了领先水平.
】
用于 VQA 的指标对于开放式问题无效,因此需要开发一种专门针对这些问题类型的新指标。与医学领域的 VQA 相关的一个限制是拥有大量手动验证的数据集,这是创建可信医学 VQA 代理的关键要求。表 18和表 19分别显示了 V+L 预训练模型和医学 VQA 的 SWOT 分析摘要。
表 18医疗 VQA 的 SWOT 分析



C. 挑战和建议
根据上一节详述的 SWOT 分析,我们提出了 VQA 在医疗领域面临的许多挑战,并为未来的研究人员提供了建议。
1)数据集大小有限
这一限制要求研究人员扩展数据集,要么使用其他现有数据集,要么创建新数据集。自动数据集生成有助于创建庞大的数据集,但这种方法有缺点。相关的限制是验证新数据集或扩展数据集的专家的流失、原始数据集错误和偏差。关于有限数据集大小的另一种解决方案是数据集增强经典方法或生成对抗网络 (GAN)。我们建议一种尚未应用的数据集增强方法。1这种方法基于问题,答案可以改写以增强数据集。然而,即使这种方法扩展了数据集,它仍然可能导致偏见障碍。这些挑战意味着研究人员必须花费大量精力来创建医疗数据集生成问题的解决方案。迁移学习是一种可能有助于解决有限数据集大小困境的潜在解决方案。根据最先进的示例,只有一项研究使用了 V+L 预训练模型。我们建议使用 V+L 预训练模型,因为它们是在庞大的 V+L 数据集上进行预训练的,并且文本与图像对齐。
2)问题多样性
如表 4所示, VQA-RAD [10]和 SLAKE [32]在所有医学 VQA 数据集中多样性最高,而其他数据集则受到多样性限制。未来的研究人员在创建新数据集时应该增加问题的多样性,因为多样性不足将导致医学 VQA 代理不切实际。增加数据集的问题多样性可以通过外部来源实现,例如知识库、书籍、其他数据集或患者病史。使用逻辑传导规则通过反例或多个问题的问题组合进行增强可以增加数据集的多样性。新数据集的问题多样性高于原始数据集,需要专家验证。此外,将多个数据集与不同类型的问题相结合将增加多样性。
3)单峰偏差问题
这一限制表示能够避免在具有显著性能的多模态中仅使用一种模态,例如 Lubna 等人[186],他们在 VQA-Med 2019 上取得了 84.6% 的成绩,而没有在模型的预训练中使用文本部分。这一限制会降低模型的鲁棒性。文本模态中的偏差称为文本先验。创建新数据集或扩展现有数据集以消除偏差是解决此问题的一种方法。然而,由于创建一个庞大的医学 VQA 基准很困难,研究人员需要找到有助于增强模型鲁棒性同时降低偏差敏感性的方法。集成方法已被证明可以减少数据集偏差[57],而在一般 VQA 领域已经提出了多种方法来帮助减少偏差[251]、[252]、[253]、[254]、[255]。Yuan 的调查提出了 VQA 中的语言偏差[256]。
4)多模态数据集
大多数现有的医学 VQA 数据集都是包含不同图像格式(即 MRI、X 射线和 CT)的多模态数据集。这种多模态性增加了学习难度。将数据集拆分为几个单模态数据集并使用不同的模型配置训练每个数据集可能是一种有效的方法。但是,由于原始数据集中存在数据集大小限制,这种方法可能会加剧数据集大小限制带来的障碍。要解决此限制,请参阅第 VIII-A 小节。
5)外部知识
疾病诊断可能取决于患者病史、实验室检查以及有关疾病本身及其与其他疾病的交叉点的其他信息。由于所有现有数据集都没有这些信息,因此最好使用外部知识来提高未来模型的学习能力。周等人[109]和刘等人[32]基于外部知识库建立了模型。我们建议研究人员使用外部知识和多种资源来使模型更加实用。
6)多幅图像
医学中一个必要的程序是通过定期检查患者的放射图像来跟踪患者的进展。由于目前还没有为此开发模型,我们建议创建一个包含多张图像的数据集,并开发一个强大而实用的模型来跟踪患者的进展。
7)非等价类
数据集包含非等价类,这意味着训练集中存在的类并非全部都包含在测试集中。这种情况对有效评估模型的性能提出了挑战。例如,在主要用于 med-VQA 的 VQA-RAD 和 SLAKE 的情况下,训练集和测试集分别包含 473 个和 121 个类以及 221 个和 33 个类。测试集和训练集之间的类数差异无法提供信任模型性能比较,因为一个模型可能比测试集中的类更好地预测不在测试集中的类,并且与无法检测不在测试集中的类的另一个模型相比,它被认为性能较差。另一方面,通过增加测试集中的新类示例,被认为比第二个模型更差的第一个模型优于第二个模型。因此,我们鼓励研究人员生成、扩展和利用等价类数据集。
8) 符合医疗应用要求
医学 VQA 的主要目的是构建实用的 AI 代理,以支持专家做出有关疾病的决策、医学生的学习以及患者在无需专家的情况下解释放射图像。只有开发出错误率低、泛化能力强的稳健模型,才能实现这些目标。研究人员必须考虑所有先前的评论和威胁,如表 9中所述–11。
9)模型解释
模型解释是研究人员面临的一大挑战。一个障碍是没有明确的模型行为,也没有关于选择特定答案的原因的任何解释。由于模型被当作黑匣子来操作,大多数现有模型都是基于反复试验来设计的,以选择和配置多模态部分。Vu 等人[7]已将注意力集中在可以帮助选择或生成答案的重点领域。虽然这种方法在某些样本中是正确的,但结果却不正确,研究人员无法解释原因。
结论
VQA 是一个视觉和语言领域,涉及回答关于给定图像的自然语言问题,而医学 VQA 用于回答有关医学图像的问题。本文全面回顾了大量医学 VQA 模型、结构和数据集以及 V+L 预训练模型,对 75 多个模型进行了统计和 SWOT 分析。本文还对一般领域的多模态部分进行了统计分析,强调医学背景下的 VQA 研究人员并没有受到一般 VQA 研究的启发。分析了文本和视觉方法的组合。根据统计分析,所研究的模型中分别有 42%、14% 和 12% 使用 LSTM、非文本和 BiLSTM 方法进行文本编码。使用最多的视觉方法是 VGG、ResNet 和 Ensemble,比例分别为 40%、22% 和 16%。在融合阶段,14% 的时间未使用任何方法,而 SAN 和连接方法的使用率分别为 13% 和 10%。我们发现 LSTM-VGGNet 和 LSTM-ResNet 组合主要应用于医疗 VQA,使用率分别为 18% 和 15%。除了对 2018-2023 年医疗 VQA 的统计分析外,我们还对每年的医疗 VQA 进行了统计分析,结果显示,除了 2018 年 ResNet 使用率最高外,每年 LSTM 和 VGGNet 分别是用于文本和视觉的主要方法。
这项分析表明,不同 VQA 领域使用的方法存在明显差异。我们的 SWOT 分析可以帮助未来的研究人员确定他们在这个领域需要注意的优势和劣势,同时详细说明这些劣势如何为他们创造贡献解决方案的机会。根据 SWOT 分析,建议的未来研究领域如下:数据集大小有限、问题多样性、单模态偏差问题、多模态数据集、外部知识、多幅图像、实际医学应用方面的完整性、模型解释和评估。
致谢
作者要感谢沙特国王大学和计算机与信息科学学院。此外,作者还要感谢沙特国王大学科学研究院长通过 DSR 研究生研究支持 (GSR) 计划资助和支持这项研究。这项工作部分由 KSU 和复杂工程系统中心 (麻省理工学院和 KACST 联合资助)。
缩写
本文使用了以下缩写:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









