 MySQL数据库与SQL基础教程
MySQL数据库与SQL基础教程





01 数据库
1.1 什么是数据库(DataBase)
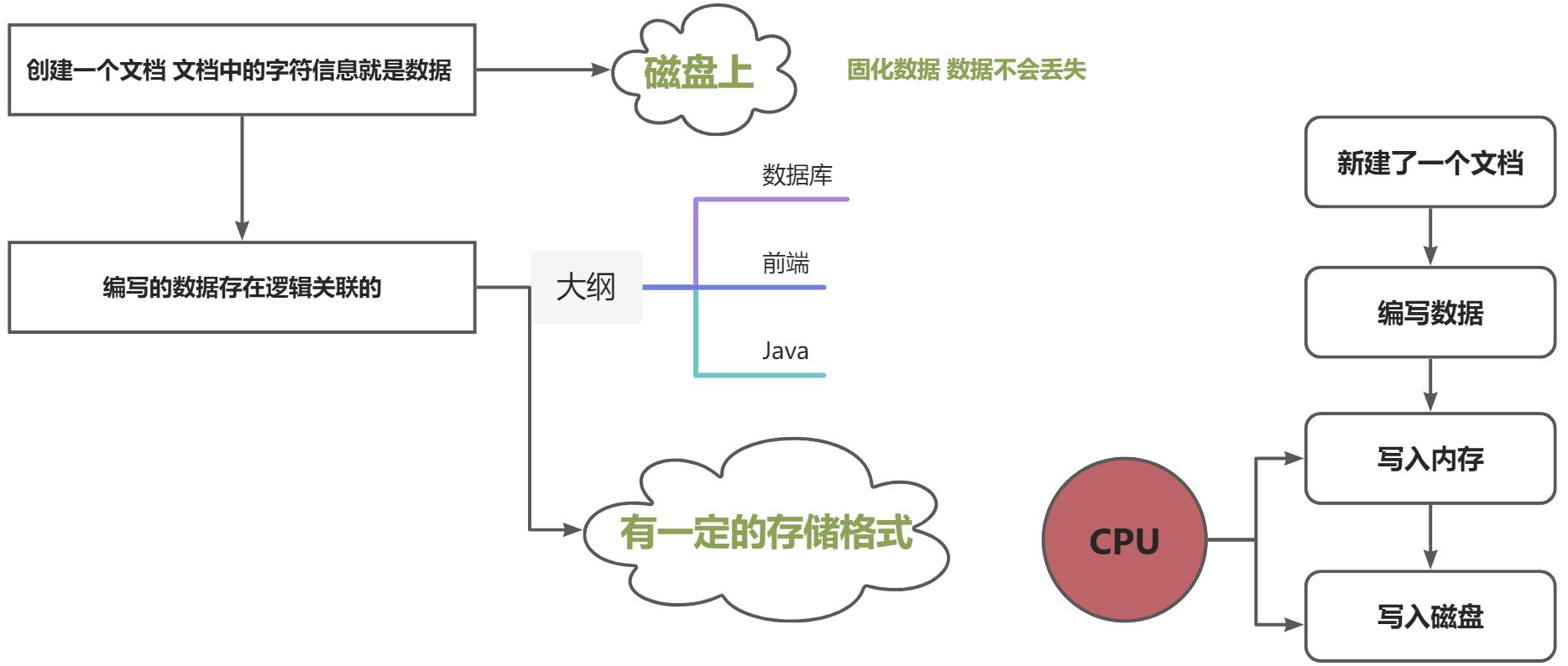
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。简称DB
数据库软件称为数据库管理系统(DBMS),全称为 DataBase Management System,如:Oracle、SQL Server、MySql、Sybase、 informix、DB2、interbase、PostgreSql
1.2 安装数据库
下载地址:https://www.mysql.com/downloads/
安装之后:测试是否安装成功
- 打开命令行 DOS
win+r 
##切换到mysql的安装目录
C:\Users\wanggang>cd C:\Program Files\MySQL\MySQL Server 8.0\bin
##连接mysql的服务
C:\Program Files\MySQL\MySQL Server 8.0\bin>mysql -uroot -p
Enter password: ****
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 14
Server version: 8.0.18 MySQL Community Server - GPL
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
1.3 MySQL的连接管理
1.4 常用命令和SQL指令
:::info
1: mysql中的SQL指令有可能很长,所以通过**;****结尾 **
2:SQL指令是不区分大小写
:::
--连接数据库服务
--ip地址如果不写,默认连接本机
mysql -u[用户名] -p[密码] -h[ip地址]
-- 查看整个mysql服务中的库信息
show databases;
-- 查看库中的信息
-- 1: 切换到指定的库里
use 库名称;
use sys; --切换到的sys库中
-- 2:查看库中的所有表信息
show tables;
-- 3:查看表中的所有列信息
show columns from dept;
-- 4:显示数据表的详细索引信息,包括PRIMARY KEY(主键)。
show index from dept;
--create database;
--创建数据库
--drop database;
--删除数据库
--创建表/删除表
--create table t_name;drop table t_name;
--删除数据的通用语法
--delete from t_name[where clause]
--插入数据
insert into t_name (f1,f2) values (value1,value2);
--举例,order by 升序,desc 倒序,count 查询的个数,升序第一条是0,降序最后一条是0
select ename from emp order by ename desc limit 0,5;
:::success
delete删除表内数据,表结构不变,数据空间不释放,可以回滚
truncate一次删除表中所有数据,保留表结构,立刻释放磁盘空间
drop永久抹去,空间释放.删除整个表,包括表结构/数据/定义
- 1、delete 和 truncate 仅仅删除表数据,drop 连表数据和表结构一起删除,打个比方,delete 是单杀,truncate 是团灭,drop 是把电脑摔了。
- 2、delete 是 DML 语句,操作完以后如果没有不想提交事务还可以回滚,truncate 和 drop 是 DDL 语句,操作完马上生效,不能回滚,打个比方,delete 是发微信说分手,后悔还可以撤回,truncate 和 drop 是直接扇耳光说滚,不能反悔。
- 3、执行的速度上,drop>truncate>delete,打个比方,drop 是神舟火箭,truncate 是和谐号动车,delete 是自行车
:::
02 SQL
2.1 SQL分类
:::info
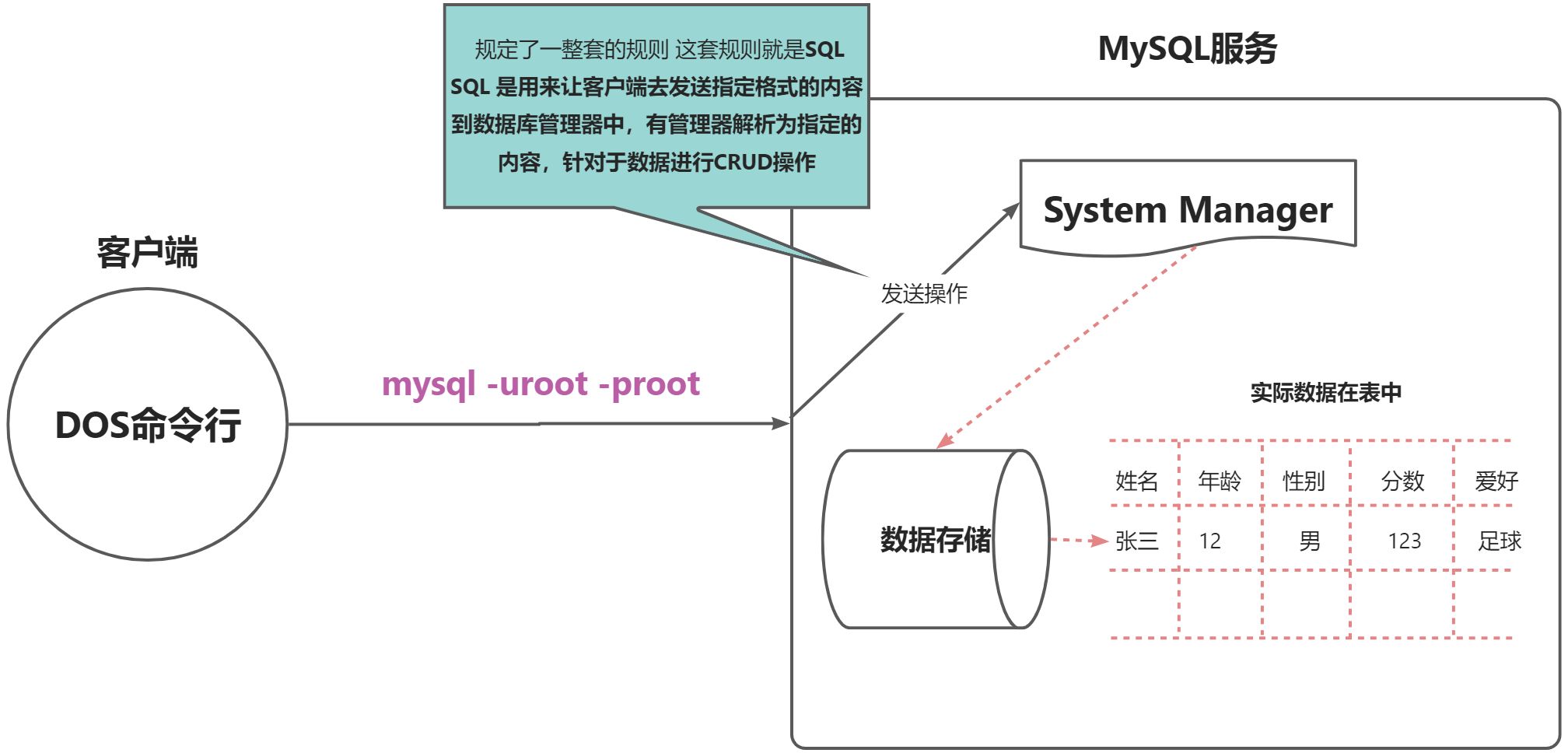
结构化查询语言(Structured Query Language)简称SQL,结构化查询语言是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;
SQL 的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。
sql 语句就是对数据库进行操作的一种语言。
:::
:::info
tips:
事务控制语言(TCL-Transactional Control Language) : 代表关键字:commit ,rollback;
:::
2.2 DCL(Data Control Language):数据控制语句
-- 扩展 如果想要学习某个SQL关键词的用法 请按照如下方式
help 关键词;
-- 例子
help use; -- 查看use关键词的使用方式
-- 创建一个用户
-- 新创建的用户啥都干不了 需要授权之后才可以
create user '用户名'@'ip地址' identified by '密码';
-- 例子
create user 'zs'@'localhost' identified by '1234';
-- 删除用户
drop user '用户名'@'ip地址'
-- 例子
drop user 'zs'@'localhost';
-- 给用户授权
grant 哪些权限 on 哪些库? 哪些表? to 给谁?
grant all on sys to 'zs'@'localhost' -- 给张三这个用户sys这个库上的所有权限
-- 撤销权限
revoke 哪些权限 on 哪些库? 哪些表? from 从哪里?
revoke all on sys.* from 'zs'@'localhost';-- 撤销张三这个用户在sys这个库上的所有权限
-- 锁定账户
alter user 'zs'@'localhost' identified by '1234' account lock;
-- 解锁账户
alter user 'zs'@'localhost' identified by '1234' account unlock;
2.3DDL (Data Definition Languages):数据定义语言
-- 创建库
create database 库名称;
-- 例子
create database test;
-- 查看所有的库
show databases;
-- 查看库中的所有表
show tables;
-- 创建表
create table 表名 (列名1 列类型1,列名2 列类型2......);
-- 修改表之 添加列
alter table 表名 add column 列名 列类型;
-- 例子
alter table computer add column createtime date;
-- 修改表之 删除列
alter table 表名 drop column 列名;
-- 列子
alter table computer drop column createtime;
-- 修改表之 修改列名
alter table 表名 rename column 原列名 to 新列名;
-- 例子
alter table computer rename column type to c_type;
-- 修改表之 修改列类型
alter table 表名 modify column 列名 列类型;
-- 例子
alter table computer modify column c_type char(10);
2.4 DML(Data Manipulation Language):数据操作语句
-- 添加数据
insert into 表名 [(列名1,列名2......)] values (列值1,列值2.....);
-- 添加数据的时候不指定列名 需要添加所有列 添加的值要和当前表中的每个列的类型都匹配上
insert into teacher values( 'zs','12312312311');
--添加数据的时候指定列名 只需要添加指定列
insert into teacher (name) values('lisi');
-- 修改数据
update 表名 set 列名=列值;
-- 全表全部修改
update teacher set name='zl';
-- 删除数据
delete from 表名;
-- 全表删除
delete from teacher;
数据类型 参考连接:http://c.biancheng.net/sql/data-types.html
字符串类型
| 类型 | 说明 |
|---|---|
| CHAR(size) | 用于表示固定长度的字符串,该字符串可以包含数字、字母和特殊字符。size 的大小可以是从 0 到 255 个字符,默认值为 1。 |
| VARCHAR(size) | 用于表示可变长度的字符串,该字符串可以包含数字、字母和特殊字符。size 的大小可以是从 0 到 65535 个字符。 |
| TINYTEXT | 表示一个最大长度为 255(28-1)的字符串文本。 |
| TEXT(size) | 表示一个最大长度为 65,535(216-1)的字符串文本,也即 64KB。 |
| MEDIUMTEXT | 表示一个最大长度为 16,777,215(224-1)的字符串文本,也即 16MB。 |
| LONGTEXT | 表示一个最大长度为 4,294,967,295(232-1)的字符串文本,也即 4GB。 |
| ENUM(val1, val2, val3,…) | 字符串枚举类型,最多可以包含 65,535 个枚举值。插入的数据必须位于列表中,并且只能命中其中一个值;如果不在,将插入一个空值。 |
| SET( val1,val2,val3,…) | 字符串集合类型,最多可以列出 64 个值。插入的数据可以命中其中的一个或者多个值,如果没有命中,将插入一个空值。 |
:::success
MySQL5.0版本以上: 1.一个汉字占多少长度与编码有关;UTF-8一个汉字3个字节; GBK一个汉字=2个字节
2.varchar(n)表示n个字符,无论汉字和英文,MySQL都能存入n字符,仅是实际字节长度有区别
3.MySQL检查长度,可用SQL语言来查看select length(fieldname) from tablename
:::
:::success
问题001: char 和 varchar 的区别
:::
| 名称和区别 | 说明 | 长度 | 多余空格 | 运行速度 | 存储方式 | 字符空间差 |
|---|---|---|---|---|---|---|
| char | 定长字符串 | 不可变 | 跟空格 | 时间效率,快 | 最长255字符 | 英文字符占1字节,汉字占2 |
| varchar | 变长字符串 | 可变 | 去掉 | 空间效率,慢,节省空间 | 最长65535字符 | 英文,汉字都占2字节 |
:::success
float与double的区别
1.所占内存不同,f占用4个字节(32位)存储一个浮点数,包括符号位1位,阶码8位,尾数23位.d用8个字节(64位)包括符号位1位,阶码11位,尾数52位
2.所存数值范围不同: f数值范围为正负3.4的38次方,d的绝对值范围是-2.23的308次方和1.79的308次方
3.单精度浮点数最多7位十进制有效数字,双精度浮点数最多15或16位有效数字,超出部分会自动四舍五入
:::
数值类型
| 类型 | 大小(字节) | 有符号数取值范围 | 无符号数取值范围 | 说明 |
|---|---|---|---|---|
| TINYINT | 1 | (-128, 127) | (0, 255) | 超小整数 |
| SMALLINT | 2 | (-32 768, 32 767) | (0, 65 535) | 小整数 |
| MEDIUMINT | 3 | (-8 388 608, 8 388 607) | (0, 16 777 215) | 中等整数 |
| INT 或 INTEGER | 4 | (-2 147 483 648, 2 147 483 647) | (0, 4 294 967 295) | 整数 |
| BIGINT | 8 | (-263, 263-1) | (0, 264-1) | 大整数 |
| 类型 | 说明 | |||
| BOOL | 布尔类型,只有 true 和 false 两个有效值;零值被认为是 false,非零值被认为是 true。 | |||
| 注意,MySQL 并不真正支持 BOOL 类型,BOOL 是 TINYINT(1) 的别名。 |
| 类型 | 分类 | 说明 |
|---|---|---|
| FLOAT(size, d) | 浮点数(近似值) | 单精度浮点数类型,4 个字节大小。size 参数用来指定数字的总个数,d 参数用来指定小数部分(小数点后边)的数字个数。 |
| FLOAT§ | 单精度浮点数类型,参数 p 用来决定使用 FLOAT 类型还是 DOUBLE 类型: |
- 如果 p 的取值介于 0 和 24 之间,那么数据类型将变成 FLOAT();
- 如果 p 的取值介于 25 和 53 之间,那么数据类型将变成 DOUBLE()。
|
| DOUBLE(size, d) | | 双精度浮点数类型,size 参数用来指定数字的总个数,d 参数用来指定小数部分(小数点后边)的数字个数。 |
| DECIMAL(size, d) | 定点数(精确值) | 定点数类型,size 参数用来指定数字的总个数,d 参数用来指定小数部分(小数点后边)的数字个数。size 的最大值是 65,默认值是 10;d 的最大取值是 30,默认值是 0。 |
| DEC(size, d) | | 等价于 DECIMAL(size, d)。 |
时间日期类型
| 类型 | 说明 |
|---|---|
| DATE | 日期类型,格式为 YYYY-MM-DD,取值范围从 ‘1000-01-01’ 到 ‘9999-12-31’。 |
| DATETIME(fsp) | 日期和时间类型,格式为 YYYY-MM-DD hh:mm:ss,取值范围从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’。 |
| TIMESTAMP(fsp) | 时间戳类型,它存储的值为从 Unix 纪元(‘1970-01-01 00:00:00’ UTC)到现在的秒数。TIMESTAMP 的格式为 YYYY-MM-DD hh:mm:ss,取值范围从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-09 03:14:07’ UTC。 |
| TIME(fsp) | 时间类型,格式为 hh:mm:ss,取值范围从 ‘-838:59:59’ 到 ‘838:59:59’。 |
| YEAR | 四位数字的年份格式,允许使用从 1901 到 2155 之间的四位数字的年份。此外,还有一个特殊的取值,就是 0000。 |
二进制类型
| 类型 | 说明 |
|---|---|
| BIT(size) | 二进制位(Bit)类型,位数由 size 参数指定;size 的大小从 1 到 64,默认值为 1。 |
| BINARY(Size) | 等价于 CHAR() 类型,但是存储的是二进制形式的字节串。size 参数以字节(Byte)为单位指定列的长度,默认值为1。 |
| VARBINARY(Size) | 等价于 VARCHAR() 类型,但是存储的是二进制形式的字节串。size 参数以字节(Byte)为单位指定列的最大长度。 |
| TINYBLOB | 存储较小的二进制数据,最多可容纳 255 (28-1)个字节。 |
| BLOB(size) | 用来储存二进制数据,最多可以容纳 65,535(216-1)个字节,也即 64KB。 |
| MEDIUMBLOB | 存储中等大小的二进制数据,最多可以容纳 16,777,215(224-1)字节,也即 16MB。 |
| LONGBLOB | 存储较大的二进制数据,最多可容纳 42,94,967,295(232-1)字节,也即 4GB。 |
03 DQL数据查询语言(Data Query Language)
准备工作:表的介绍
- emp 员工表

- dept 部门表

- salgrade 工资等级表

3.1 简单查询和条件查询
-- 查询全表
select * from 表名;
-- * 代表通配符
select * from teacher;
-- 查询指定列
select 列1,列2.... from 表名;
select name from teacher;
-- 注释 这个属于说明的文字 只能注释一行
/*
可以注释多行
*/
-- 查询员工表中的员工姓名以及员工的工资
select ename,sal from emp;
-- 查询的过程中可以进行运算的
select 列 from 表;
-- 查询每个员工的年薪
select sal*12 from emp;
-- 查询之后的列可以通过起别名的方式来使用
select sal*12 as '年薪' from emp;
-- 希望查询的时候过滤掉一些其他数据 where
-- 查询一下员工的工资大于2000的员工信息
select * from emp where sal > 2000;
-- > < >= <= = !=
-- 查询员工的年薪>=50000的员工的姓名和年薪
-- 查询员工的工作是'clerk'的员工的姓名和工作以及工资
-- 查询员工的工作不是'analyst'的员工的姓名和工作以及工资
-- 查询员工的奖金<500的员工姓名和奖金
-- 查询员工的姓名是'scott'的员工信息
-- 查询员工的上级是'ford'的员工编号以及员工的姓名
-- 查询员工的入职日期早于'1987-12-12'的员工信息
-- 查询员工不是20部门的员工姓名和部门编号
-- 查询员工的年薪>=50000的员工的姓名和年薪
select ename,sal*12 from emp where sal*12>=50000;
-- 查询员工的工作是'clerk'的员工的姓名和工作以及工资
select ename,job,sal from emp where job='clerk';
-- 查询员工的工作不是'analyst'的员工的姓名和工作以及工资
select ename,job,sal from emp where job != 'analyst';
-- 查询员工的奖金<500的员工姓名和奖金
select ename,comm from emp where comm<500;
-- 查询员工的姓名是'scott'的员工信息
select * from emp where ename = 'scott';
-- 查询员工的上级是'ford'的员工编号以及员工的姓名
select empno from emp where ename='ford';
select empno,ename from emp where mgr=7902;
select empno,ename from emp where mgr
= (select empno from emp where ename='ford');
-- 查询员工的入职日期早于'1987-12-12'的员工信息
select * from emp where hiredate < '1987-12-12';
-- 查询员工不是20部门的员工姓名和部门编号
select ename,deptno from emp where deptno!=20;
-- 查询员工都从属于哪些部门?distinct 去重
select distinct deptno from emp;
select * from emp;
select distinct job,sal from emp;
-- 查询工资是>1000并且工资小于1500的员工信息
select * from emp where sal>=1000 and sal<=1500;
-- between v1 and v2 求的是[v1,v2]
select * from emp where sal between 1000 and 1500;
-- 查询工资>2000 或者工资<1000的员工信息
select * from emp where sal>2000 or sal<1000;
-- 查询员工的工资是1000或1500 或者5000的员工信息
select * from emp where sal=1000 or sal=1500 or sal=5000;
select * from emp where sal in (1000,1500,5000);
-- 模糊查询
-- 查询员工的姓名中包含s的员工信息
-- % 代表的是 匹配任意长度的任意字符
-- _ 代表的是 匹配一个长度的任意字符
-- \ 转义字符 将原本有含义的字符信息转变含义
select * from emp where ename like '%s%';
-- 查看员工的第二个字母是A的员工信息
select * from emp where ename like '_a%';
-- 查看员工姓名中包含%的员工信息
select * from emp where ename like '%\%%';
-- 查看员工姓名中包含\的员工信息
select * from emp where ename like '%\\%';
-- 查看员工中没有奖金的员工信息
select * from emp where comm is null;
-- 查看员工中有奖金的员工信息
select * from emp where comm is not null;
3.2 排序数据
-- 按照薪水增序
select * from emp ORDER BY sal;
-- 取得 job 为 MANAGER 的员工,按照薪水由小到大排序
select * from emp where job = 'MANAGER' ORDER BY sal;
-- 按照多个字段排序,如:首先按照job 排序,再按照 sal 排序
select * from emp ORDER BY job,sal;
-- 按照薪水由大到小排序
select * from emp ORDER BY sal desc;
-- 按照 job 和薪水倒序
select * from emp order by job desc,sal desc;
-- 按照字段位置排序(不推荐使用,数字含义不准确,程序不健壮)
select * from emp order by 6;
3.3 单行函数(数据处理函数)/多行函数(分组函数/聚合函数)
-- 转小写
select lower(ename) from emp;
-- 查询job是经理的员工
select * from emp where job = upper('manager');
-- 查询A开头的多有员工
select * from emp where substr(ename,1,1) = upper('a');
select * from emp where ename like 'A%';
-- 员工姓名长度5的
select * from emp where length(ename) = 5;
-- 员工首字母大写,其余字母小写
select concat(SUBSTR(ename,1,1),lower(substr(ename,2,length(ename)-1))) result from emp;
-- 去除空格
select * from emp where ename = trim(' Ford ');
select * from emp where ename = ' Ford '; -- 这样有空格查询不到结果
-- 日期(和数据库格式匹配)
select * from emp where HIREDATE = '1981-02-20';
select * from emp where HIREDATE=str_to_date('1981-02-20','%Y-%m-%d');
select * from emp where HIREDATE=str_to_date('02-20-1981','%m-%d-%Y');
-- 四舍五入
select round(123.56,0) -- 保留整数位
select round(123.56,1) -- 保留一位小数
select round(123.56,-1) -- 保留到十位
-- 随机数
select rand(); -- 随机数,小数点后16位
select round(rand()*100); -- 100以内随机数
select * from emp order by rand() limit 2; -- 随机抽取
-- case when then else end
select empno, ename, job, sal as oldSal,
(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then
sal*1.5 else sal end) as newsal from emp;
-- 对Null的处理
select ename,sal,comm,(sal+ifnull(comm,0))*12 as res from emp;
-- 分组函数
select count(*) from emp;
select count(comm) from emp; -- 采用 count(字段名称),不会取得为 null 的记录
select count(DISTINCT(job)) from emp;
select sum(sal) from emp;
select sum(comm) from emp;
select sum(sal + ifnull(comm,0)) from emp; -- ifnull 对Null值进行处理
select avg(sal) from emp;
select max(sal) from emp;
select min(sal) from emp;
select max(sal),min(sal),avg(sal),count(sal),sum(sal) from emp;
:::info
tips:
分组函数注意点:(max/min/count/avg/sum)
第一点 : 分组函数自动忽略null,不需要提前对Null进行处理
第二点 : count() 和 count(具体字段) 有什么区别?
count(): 统计表当中的总行数
count(具体字段): 表示统计该字段下所有不为null 的元素总数
第三点 : 分组函数不能直接使用在where 子句中(需要用嵌套查询),因为执行顺序,先where过滤,再分组
第四点 : 分组函数可以组合起来使用
第五点 : 分组函数必须先分组再使用,假如没有对数据分组,那么默认整张表是一组
:::
3.4 分组查询(重要)
-- 每个工作岗位的工资和
select job,sum(sal) from emp group by job;
-- 找部门最高薪资
select deptno,max(sal) from emp group by deptno;
-- 每个部门不同工作岗位的最高薪资\
select deptno,job,max(sal) from emp group by deptno,job ORDER BY deptno;
:::info
tip:
第一点 : 书写顺序 select 字段/组函数 from 表名 where 行过滤条件 group by 分组字段 having 组过滤 order by 字段名
第二点 : 执行顺序 from -> where -> group by -> having -> select -> order by
第三点 : 查询语句里,如果group by 之后,select 后面只能跟参加分组的字段; 以及分组函数,其余一律不行,否则在mysql里没有意义,在oracle里会报错!
第四点 : group by 后面可以跟多个分组字段,以逗号隔开
第五点: where 和 having ,优先选择where ,效率较高,实在完成不了,再选having,having是专门对分组后数据进行过滤;
:::
3.5 多表连查
第一种: SQL92 语法和99语法做内连接查询
-- 92语法 表起别名,效率问题
select ename,dname from emp e,dept d where e.DEPTNO = d.DEPTNO;
-- 但是匹配次数没有减少,只不过进行了四选一,次数没有减少
-- 99语法(等值连接) 用join on 替换表之间的逗号,和where 条件
select ename,dname from emp e join dept d on e.DEPTNO = d.DEPTNO;
-- 找员工姓名,工资和对应工资等级
-- 99语法(非等值连接)
select e.ename,e.sal,s.grade
from emp e join salgrade s on e.sal BETWEEN s.LOSAL and s.HISAL;
-- 92语法
select e.ename,e.sal,s.grade
from emp e,salgrade s where e.sal BETWEEN s.LOSAL and s.HISAL;
-- 自连接
-- 找员工和对应领导姓名 99语法
select e1.ename,e1.mgr,e2.empno,e2.ename
from emp e1 join emp e2 on e1.mgr = e2.empno;
-- 92语法
select e1.ename,e1.mgr,e2.empno,e2.ename
from emp e1,emp e2 where e1.mgr = e2.empno;
第二种: 外连接
-- 查询所有员工和部门信息
select e.ename,e.sal,d.dname from emp e right join dept d on e.deptno = d.deptno;
-- 查询所有员工和部门信息(没有部门的员工也需要显示)
SELECT
e.ename,
e.sal,
d.dname
FROM
emp e
RIGHT JOIN dept d ON e.deptno = d.deptno;
SELECT
e.ename,
e.sal,
d.dname
FROM
dept d
left JOIN emp e ON e.deptno = d.deptno;
左连接 右连接的区别:
- 左连接以左面的表为准和右边的表比较,和左表相等的不相等都会显示出来,右表符合条件的显示,不符合条件的不显示;
- 右连接恰恰相反,以上左连接和右连接也可以加入 outer 关键字,但一般不建议这种写法
- 左连接能完成的功能右连接一定可以完成
3.6 子查询
子查询就是嵌套的select 语句,可以理解为子查询是一张表
、在 where 语句中使用子查询,也就是在 where 语句中加入 select 语句
-- 查询员工信息,哪些人是管理者,显示其员工编号和姓名
-- 第一步:查管理编号
select DISTINCT mgr from emp where mgr is not null;
-- 再查结果
SELECT
empno,
ename
FROM
emp
WHERE
empno IN (
SELECT DISTINCT
mgr
FROM
emp
WHERE
mgr IS NOT NULL);
-- 查高于员工平均薪水,需要显示员工编号,姓名,薪水
-- 平均薪水
select avg(sal) as avgSal from emp;
select empno,ename,sal from emp where sal > (select avg(sal) as avgSal from emp);
、在 from 语句中使用子查询,可以将该子查询看做一张表
-- 查哪些人是管理者,显示编号姓名
-- 管理者编号
select distinct mgr from emp where mgr is not null;
select e.empno,e.ename from emp e join
(select distinct mgr from emp where mgr is not null) m on e.empno = m.mgr;
-- 查询各个部门平均薪水所属等级,显示部门编号,平均薪水,等级编号
-- 查各部门平均薪水
select deptno,avg(sal) as avg_sal from emp group by deptno;
select a.deptno,a.avg_sal,s.GRADE from
(select deptno,avg(sal) as avg_sal from emp group by deptno) a
join salgrade s on a.avg_sal between s.LOSAL and s.HISAL;
-- 查询员工信息,并显示出员工所属的部门名称
select e.ename,d.dname from emp e
join dept d on e.deptno = d.deptno;
-- 嵌套
select e.ename,e.deptno,(select d.dname from dept d where e.deptno = d.deptno) as dname
from emp e;
3.7 特殊单词(limit | distinct)
mySql 提供了 limit ,主要用于提取前几条或者中间某几行数据
select * from table limit m,n
其中 m 是指记录开始的 index,从 0 开始,表示第一条记录
n 是指从第 m+1 条开始,取 n 条。
select * from tablename limit 2,4
即取出第 3 条至第 6 条,4 条记录
:::info
tip:
limit是MySQL的方言,对于分页,有公式:Limit (m-1)*n,n (默认从0开始)
Oracle 里面用 rownum(其中rownum必须采取小于或者小于等于符号,默认从1开始)
SqlServer 里面用 top
:::
distinct 去重,必须在字段前,放在最前方,作用范围是全部字段
注意:
如果指定了 SELECT DISTINCT,那么 ORDER BY 子句中的项就必须出现在选择列表中,否则会出现错误。
比如SQL语句:SELECT DISTINCT **Company **FROM Orders order by **Company **ASC是可以正常执行的。
但是如果SQL语句是:SELECT DISTINCT **Company **FROM Orders order by **Num **ASC是不能正确执行的,在ASP中会提示“ORDER BY 子句与 (Num) DISTINCT 冲突”错误。
SQL语句修改成:SELECT DISTINCT Company,**Num **FROM Orders order by **Num **ASC可以正常执行
04 约束
常见的约束
a) 非空约束,not null
b) 唯一约束,unique
c) 主键约束,primary key
d) 外键约束,foreign key
e) 自定义检查约束,check(不建议使用)(在 mysql 中现在还不支持)
05 存储引擎
| 类别 | MyISAM 存储引擎 | InnoDB | MEMORY |
|---|---|---|---|
| MySQL 最常用的引擎 | MySQL 的缺省引擎 | 使用 MEMORY 存储引擎的表,其数据存储在内存中,且行的长度固定,这两个特点使得 MEMORY 存储引擎非常快。 | |
| 特征 | 使用三个文件表示每个表: | ||
| • 格式文件 — 存储表结构的定义(mytable.frm) | |||
| • 数据文件 — 存储表行的内容(mytable.MYD) | |||
| • 索引文件 — 存储表上索引(mytable.MYI) | 每个 InnoDB 表在数据库目录以.frm 格式文件表示 | ||
| – InnoDB 表空间 tablespace 被用于存储表的内容 | |||
| – 提供一组用来记录事务性活动的日志文件 | |||
| – 用 COMMIT(提交)、SAVEPOINT 及ROLLBACK(回滚)支持事务处理 | |||
| – 提供全 ACID 兼容 | |||
| – 在 MySQL 服务器崩溃后提供自动恢复 | |||
| – 多版本(MVCC)和行级锁定 | |||
| – 支持外键及引用的完整性,包括级联删除和更新 | – 在数据库目录内,每个表均以.frm 格式的文件表示。 | ||
| – 表数据及索引被存储在内存中。 | |||
| – 表级锁机制。 | |||
| – 不能包含 TEXT 或 BLOB 字段。 | |||
| 应用场景 | 适合于大量的数据读而少量数据更新的混合操作 | 查询中包含较多的数据更新操作 | 存储非永久需要的数据,或者是能够从基于磁盘的表中重新生成的数据。 |
| 应用场景 | 另一种适用情形是使用压缩的只 | ||
| 读表 | 其行级锁机制和多版本的支持为数据读取和更新的混合 | ||
| 操作提供了良好的并发机制 |
06 事务
事务可以保证多个操作原子性,要么全成功,要么全失败。对于数据库来说事务保证批量的 DML 要么全成功,要么全失败。事务具有四个特征ACID
a) 原子性(Atomicity)
整个事务中的所有操作,必须作为一个单元全部完成(或全部取消)。
b) 一致性(Consistency)
在事务开始之前与结束之后,数据库都保持一致状态。
c) 隔离性(Isolation)
一个事务不会影响其他事务的运行。
d) 持久性(Durability)
在事务完成以后,该事务对数据库所作的更改将持久地保存在数据库之中,并不会被回滚。
事务中存在一些概念:
a) 事务(Transaction):一批操作(一组 DML)
b) 开启事务(Start Transaction)
c) 回滚事务(rollback)
d) 提交事务(commit)
e) SET AUTOCOMMIT:禁用或启用事务的自动提交模式
事务只对 DML 有效果。注意:rollback,或者commit 后事务就结束了。
四个隔离级别
• InnoDB 实现了四个隔离级别,用以控制事务所做的修改,并将修改通告至其它并发的事务:
–** 读未提交(READ UMCOMMITTED)**
允许一个事务可以看到其他事务未提交的修改。
– 读已提交(READ COMMITTED)
允许一个事务只能看到其他事务已经提交的修改,未提交的修改是不可见的。
– 可重复读(REPEATABLE READ)
确保如果在一个事务中执行两次相同的 SELECT 语句,都能得到相同的结果,不管其他事务是否提交这些修改。 (银行总账)
该隔离级别为 InnoDB的缺省设置。
– 串行化(SERIALIZABLE) 【序列化】
将一个事务与其他事务完全地隔离。

07 索引
索引被用来快速找出在一个列上用一特定值的行。没有索引,MySQL 不得不首先以第一条记录开始,然后读完整个表直到它找出相关的行。表越大,花费时间越多。对于一个
有序字段,可以运用二分查找(Binary Search),这就是为什么性能能得到本质上的提高。 MYISAM 和 INNODB 都是用 B+Tree 作为索引结构
(主键,unique 都会默认的添加索引)
什么时候需要给字段添加索引:
- 表中该字段中的数据量庞大
- 经常被检索,经常出现在 where 子句中的字段
- 经常被 DML 操作的字段不建议添加索引
索引等同于一本书的目录
主键会自动添加索引,所以尽量根据主键查询效率较高。
08 数据库设计的三范式
第一范式 数据库表中不能出现重复记录,每个字段是原子性的不能再分
有主键,具有原子性,字段不可分割
第二范式 所有非主键字段完全依赖主键,不能产生部分依赖
完全依赖,没有部分依赖
第三范式 非主键字段不能传递依赖于主键字段。( 不要产生传递依赖)
有时可能会拿冗余换速度,最终用目的要满足客户需求
不积跬步无以至千里,趁年轻,使劲拼,给未来的自己一个交代!
向着明天更好的自己前进吧!

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









