




 本文详细介绍了机器翻译seq2seq模型结合注意力机制的工作原理,包括编码器、解码器的构建以及注意力机制的计算过程,并通过代码实战展示了如何在PyTorch中实现这一模型。
本文详细介绍了机器翻译seq2seq模型结合注意力机制的工作原理,包括编码器、解码器的构建以及注意力机制的计算过程,并通过代码实战展示了如何在PyTorch中实现这一模型。
导语:看本文之前,你应该熟悉RNN(LSTM、GRU)工作原理、pytorch中LSTM的使用以及一些张量操作。
1.前言
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。如下是 Seq2Seq 模型工作的流程:
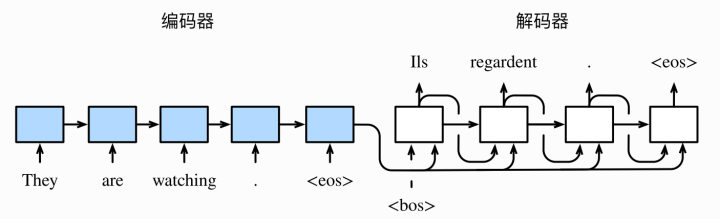
图1中无论是编码器还是解码器,都是用的循环神经网络,编码器用来分析输入序列,解码器用来生成输出序列。我们可以看到在编码器最后一个位置的输入是""(end of sequence)来表示序列的终止,编码器中每个时间步的输入依次为英语句子中的单词、标点和特殊符号""。在图1中使用了最终的时间步的隐藏状态作为输⼊句⼦的表征或编码信息。解码器在各个时间步中使⽤输⼊句⼦的编码信息和上个时间步的输出以及隐藏状态作为输⼊。我们希望解码器在各个时间步能正确依次输出翻译后的法语单词、标点和特殊符号""。需要注意的是,解码器在最初时间步的输⼊⽤到了⼀个表示序列开始的特殊符号""(beginning of sequence)。
2.编码器
这里的编码器是把一个不定长的序列变成了一个定长的背景变量ccc,那么该背景变量就包含了输入序列的信息。常用的编码器就是循环神经网络。
假设输⼊x1x_{1}x1,······,xTx_{T}xT,其中xix_{i}xi是句子中第iii个词,在时间步ttt,循环神经网络将输入xtx_{t}xt的特征向量xt\boldsymbol{x}_{t}xt和上个时间步的隐藏状态ht−1h_{t-1}ht−1变换为当前时间步的隐藏状态hth_{t}ht,在这里使用函数fff表达循环神经网络隐藏层的变换:
ht=f(xt,ht−1) \boldsymbol{h}_{t}=f\left(\boldsymbol{x}_{t}, \boldsymbol{h}_{t-1}\right) ht=f(xt,ht−1)
下面我们定义函数qqq将各个时间步的隐藏状态变换为背景变量:
c=q(h1,…,hT) \boldsymbol{c}=q\left(\boldsymbol{h}_{1}, \ldots, \boldsymbol{h}_{T}\right) c=q(h1,…,hT)
例如,当选择q(h1,…,hT)=hTq\left(\boldsymbol{h}_{1},\ldots,\boldsymbol{h}_{T}\right)=\boldsymbol{h}_{T}q(h1,…,hT)=hT时,背景变量是输⼊序列最终时间步的隐藏状态hT{h}_{T}hT。
以上描述的编码器是⼀个单向的循环神经⽹络,每个时间步的隐藏状态只取决于该时间步及之前的输⼊⼦序列。我们也可以使⽤双向循环神经⽹络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的⼦序列(包括当前时间步的输⼊),并编码了整个序列的信息。
3.解码器
我们已经知道编码器输出的背景变量ccc,编码了整个输⼊序列x1x_{1}x1,······,xTx_{T}xT的信息。给定训练样本中的输出序列y1,y2,…,yT′y_{1}, y_{2}, \ldots, y_{T^{\prime}}y1,y2,…,yT′,对每个时间步t′t^{\prime}t′(符号与输⼊序列或编码器的时间步ttt有区别),解码器输出yt′y_{t^{\prime}}yt′的条件概率可以写成下面的公式:
P(yt′∣y1,…,yt′−1,c) P\left(y_{t^{\prime}} \mid y_{1}, \ldots, y_{t^{\prime}-1}, \boldsymbol{c}\right) P(yt′∣y1,…,yt′−1,c)</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









