







 本文总结了SQL优化技巧,包括利用索引提升查询效率、调整SGA配置、合理设计表结构,以及提供具体查询语句优化建议,助你提升数据库性能。
本文总结了SQL优化技巧,包括利用索引提升查询效率、调整SGA配置、合理设计表结构,以及提供具体查询语句优化建议,助你提升数据库性能。
一些sql优化的经验总结,结合了一些网上资料,有错误或者建议,望留言指正和指教!
据软件可以查看执行计划(比如PLSQL,选中语句按F5进入执行计划页面查看)
根据执行计划,逐步检查SQL的花费以及消耗时间等,对其进行改进优化。
(1)TABLE ACCESS BY INDEX ROWID:根据索引找到的ROWID来查找需要的数据。
(2)SELECT STATEMENT,GOAL = ALL ROWS:根据找到的数据,返回所有行。
(3)TABLE ACCESS FULL :全表扫描。
索引:
(1)index unique scan:索引唯一扫描。
(2)index range scan:索引范围扫描
(3)index skip scan:索引跳跃扫描。
(4)index full scan:索引全扫描。
(5)index fast full scan:索引快速扫描。
如图:
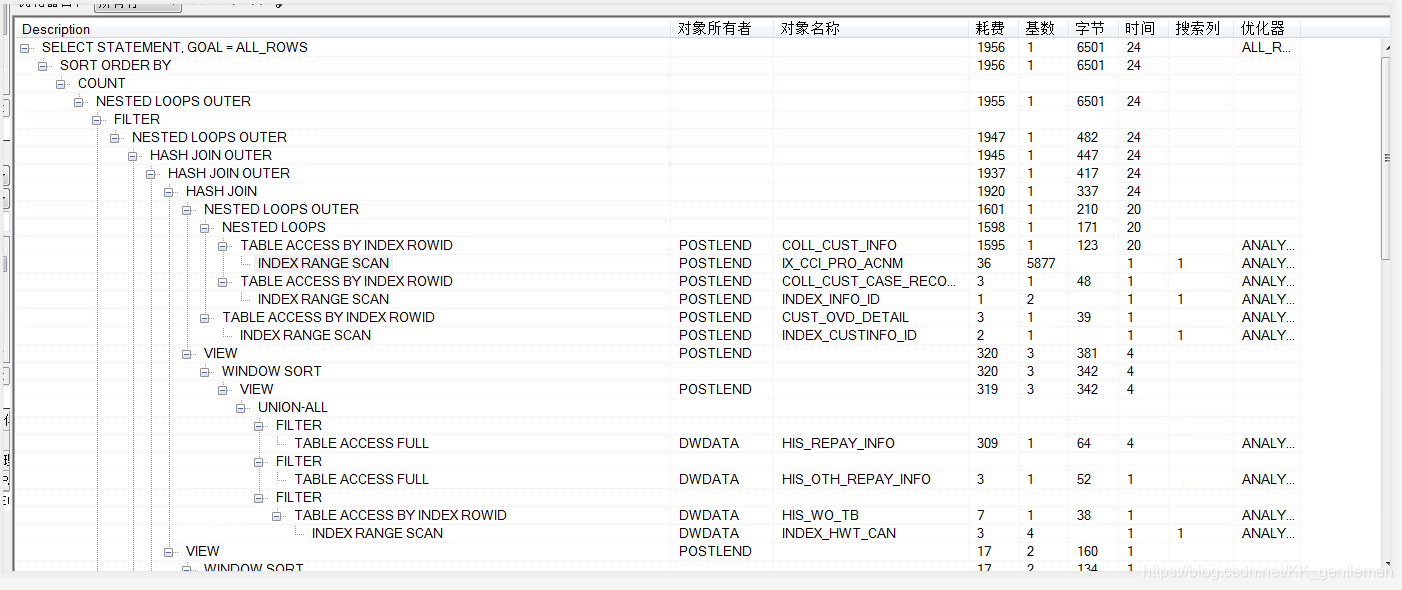
实际优化步骤:
一、数据库优化
1.根据服务器内存配置合理的SGA(数据库全局区),配置合适的共享池以及数据缓冲区(比如内存2G,SGA可以考虑分配1.2G,共享池300M到500M,剩下的给数据块缓冲区);
2.分析表和索引,更改优化模式。
Oracle默认优化模式是CHOOSE,在这种情况下,如果表没有经过分析,经常导致查询使用全表扫描,而不使用索引。这通常导致磁盘I/O太多,而导致查询很慢。如果没有使用执行计划稳定性,则应该把表和索引都分析一下,这样可能直接会使查询速度大幅提升。分析表命令可以用ANALYZE TABLE 分析索引可以用ANALYZE INDEX命令。对于少于100万的表,可以考虑分析整个表,对于很大的表,可以按百分比来分析,但是百分比不能过低,否则生成的统计信息可能不准确。可以通过DBA_TABLES的LAST_ANALYZED列来查看表是否经过分析或分析时间,索引可以通过DBA_INDEXES的LAST_ANALYZED列。


3.将常用的小表、索引钉在数据缓存KEEP池中。
内存上数据读取速度远远比硬盘中读取要快,据称,内存中数据读的速度是硬盘的14000倍!如果资源比较丰富,把常用的小的、而且经常进行全表扫描的表给钉内存中,当然是在好不过了。可以简单的通过ALTER TABLE tablename CACHE来实现,在ORACLE8i之后可以使用ALTER TABLE table STORAGE(B?R_POOL KEEP)。
4.设置optimizer_max_permutations
对于多表连接查询,如果采用基于成本优化(CBO),ORACLE会计算出很多种运行方案,从中选择出最优方案。这个参数就是设置oracle究竟从多少种方案来选择最优。如果设置太大,那么计算最优方案过程也是时间比较长的。Oracle805和8i默认是80000,8建议改成2000。对于9i,已经默认是2000了。
二、看表结构,设计时
1.使用可以存下你的数据的最小的数据类型。
2.使用简单的数据类型。int要比varchar类型在mysql处理上更简单。
3.尽可能的使用 varchar 代替 char。
4.尽可能的使用not null定义字段。
5.尽量少用text类型,非用不可时最好考虑分表。
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要求,否则,将有很多基本操作在这样的关系模式中实现不了。
说明:每一列属性都是不可再分的属性值,确保每一列的原子性。两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
说明:每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF。
说明:数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
三、语句查询优化
1.联接查询操作的前提是笛卡儿积,即要将多表中所有的元组拿来运算,再从中找出符合条件的,其本身就增加了运算的负担,所以我们在做优化时尽量避免联接查询。如果必须要使用联接查询时也要尽量使用较少的联接表,查询优化力图找出给定等价的表达式,但执行效率更高,一个查询往往会有许多实现方法,关键是如何找出一个与之等价的且操作时间又少的表达式。优化的核心问题是尽可能减少查询中各表的参与加工的数据量,从而达到优化时间和空间的目的。
2.先筛选后联接,当查询多个数据表时,要先过滤后联接,尽量使用过滤多的条件进行数据筛选。
3.选择最有效率的表名顺序(只在基于规则的优化器中有效)。
ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理. 在FROM子句中包含多个表的情况下,优先选择记录条数最少的表作为基础表.(当ORACLE处理多个表时, 会运用排序及合并的方式连接它们.首先,从右到左扫描第一个表并对记录进行派序,然后扫描第二个表,最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并)。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表。
4.WHERE子句中优化事项
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。同时,应尽量避免在 where 子句中对字段进行进行函数、算术运算或其他表达式运算操作,这将导致引擎放弃使用索引而进行全表扫描。
5.减少访问数据库的次数
当执行每条SQL语句时, ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等等. 由此可见, 减少访问数据库的次数 , 就能实际上减少ORACLE的工作量.
6.建立索引。
优先考虑在 where 及 order by 涉及的列上建立索引,还有就是在连接表时对连接字段进行建立索引。(索引并不是越多越好,注意索引列的唯一性,建立索引的列不要有太多重复数据。一个表索引太多会影响insert和update语句的效率)。
在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,所以应尽可能的让字段顺序与索引顺序相一致
7.具体语句优化
A.SELECT子句中避免使用 ‘ * ‘ ,ORACLE在解析的过程中, 会将’*’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 会耗费更多的时间。
B.使用DECODE函数来减少处理时间
C.用EXISTS替代IN
D.尽量避免在 where 子句中使用!=或<>操作符(导致全表扫描)
E.尽量避免在 where 子句中使用 or 来连接条件(导致全表扫描)。可以考虑用union(all)
F.尽量避免在 where 子句中对字段进行 null 值判断(导致全表扫描)
G.事务操作时,尽量多使用COMMIT(在使用COMMIT时必须要注意到事务的完整性)
H.避免使用'%'被添加在参数前面(导致引擎不使用索引)

















 3852
3852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









