




在高并发下,需要对应用进行读写分离,配置多数据源,即写操作走主库,读操作则走从库,主从数据库负责各自的读和写,缓解了锁的争用,提高了读取性能。
实现读写分离有多种方式,如使用中间件MyCat、Sharding-JDBC等,这里我们使用Aop的方式在代码层面实现读写分离。
实现原理
实现读写分离,首先要对Mysql做主从复制,即搭建一个主数据库,以及一个或多个从数据库。
具体实现主从复制,可参照前一篇博客《基于docker配置MySQL主从复制》
使用Aop的方式,当调用业务层方法前,判断请求是否是只读操作,动态切换数据源,如果是只读操作,则切换从数据库的数据源,否则使用主数据库的数据源。
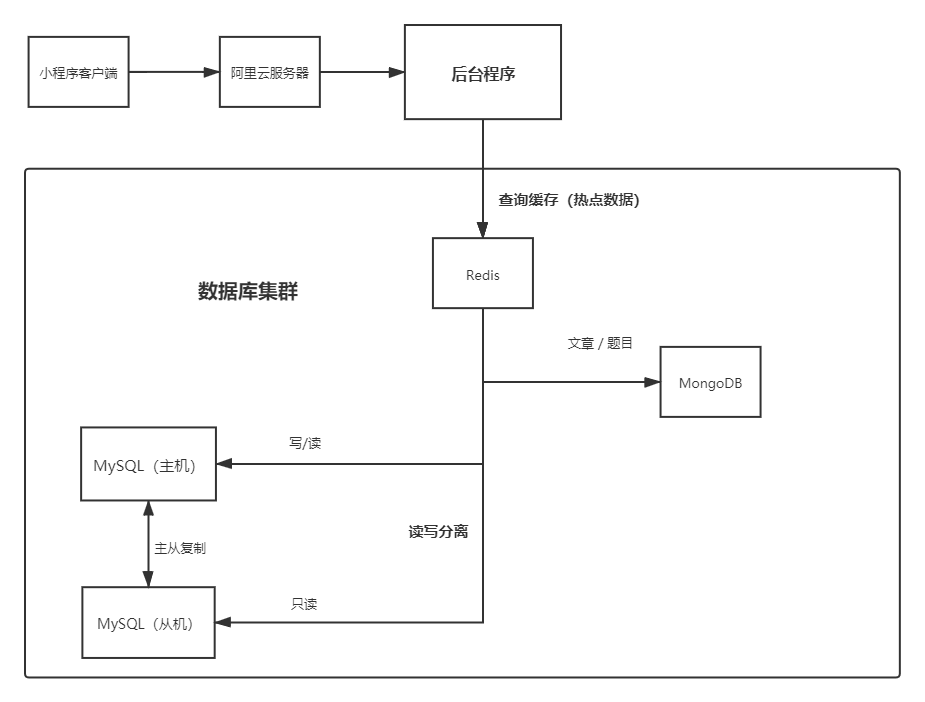
系统架构
这是我之前写的一个项目,项目就是使用了本文章介绍的读写分离方式,架构图大概如下:
代码实现
在application.yml配置MySQL
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
#主机
master:
username: root
password: 123456
url: jdbc:mysql://服务器ip:3306/letfit?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT
driver-class-name: com.mysql.cj.jdbc.Driver
#从机
slave:
username: root
password: 123456
url: jdbc:mysql://服务器ip:3307/letfit?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT
driver-class-name: com.mysql.cj.jdbc.Driver
#连接池
druid:
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
filters: stat,wall
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
创建 ReadOnly 注解
在业务层的方法上使用该注解,使用 ReadOnly 注解的方法只处理读操作,会切换到从机的数据源
package com.letfit.aop.annotation;
/**
* 只读注解
*/
@Target({
ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ReadOnly {
}
创建枚举类
定义两个枚举类型 MASTER、slave分别代表数据库类型
package com.letfit.common;
/**
* 数据库类型
*/
public enum DBTypeEnum {
/**
* 主数据库
*/
MASTER,
/**
* 从数据库
*/
SLAVE;
}
编写动态切换数据源的工具类
package com.letfit.util;
/**
* 动态切换数据源工具类
*/
@Slf4j
public class DynamicDbUtil {
/**
* 用来存储代表数据源的对象
*/
private static final ThreadLocal<DBTypeEnum> CONTEXT_HAND = new ThreadLocal<>();
/**
* 切换当前线程要使用的数据源
* @param dbTypeEnum
*/
public static void set(DBTypeEnum dbTypeEnum){
CONTEXT_HAND.set(dbTypeEnum);
log.info("切换数据源:{}", dbTypeEnum);
}
/**
* 切换 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









