




 本文深入解析Spark中的核心概念——弹性分布式数据集(RDD),探讨其创建、特性、结构及操作方式,包括转换操作与行动操作,旨在帮助读者全面理解RDD的工作原理。
本文深入解析Spark中的核心概念——弹性分布式数据集(RDD),探讨其创建、特性、结构及操作方式,包括转换操作与行动操作,旨在帮助读者全面理解RDD的工作原理。
参考链接:
(1)什么是 RDD ?
https://www.jianshu.com/p/6411fff954cf
(2)spark的RDD中的action(执行)和transformation(转换)两种操作中常见函数介绍
https://blog.youkuaiyun.com/helloxiaozhe/article/details/78481784
(3)常见转换操作和行动操作
https://blog.youkuaiyun.com/wj1298250240/article/details/103938132/
一、RDD
RDD:弹性分布式数据集 (Resilient Distributed DataSet)。Spark 中最基本的数据抽象是 RDD。Spark是以RDD概念为中心运行的。RDD是一个容错的、可以被并行操作的元素集合。
(1)RDD的创建
创建一个RDD有两个方法:
1.在驱动程序中并行化一个已经存在的集合;
2.从外部存储系统中引用一个数据集。
(2)优点/好处/特性
1.RDD的一大特性是分布式存储,分布式存储在最大的好处是可以让数据在不同工作节点并行存储,以便在需要数据时并行运算。弹性指其在节点存储时,既可以使用内存,也可已使用外存,为使用者进行大数据处理提供方便。
2.RDD的另一大特性是延迟计算,即一个完整的RDD运行任务被分为两部分:Transformation和Action
(3)基本特征
RDD 有三个基本特征,分别为:分区,不可变,并行操作。
a.分区:每一个 RDD 包含的数据被存储在系统的不同节点上。逻辑上我们可以将 RDD 理解成一个大的数组,数组中的每个元素就代表一个分区 (Partition) 。
在物理存储中,每个分区指向一个存储在内存或者硬盘中的数据块 (Block) ,其实这个数据块就是每个 task 计算出的数据块,它们可以分布在不同的节点上。
所以,RDD 只是抽象意义的数据集合,分区内部并不会存储具体的数据,只会存储它在该 RDD 中的 index,通过该 RDD 的 ID 和分区的 index 可以唯一确定对应数据块的编号,然后通过底层存储层的接口提取到数据进行处理。
在集群中,各个节点上的数据块会尽可能的存储在内存中,只有当内存没有空间时才会放入硬盘存储,这样可以最大化的减少硬盘 IO 的开销。
b.不可变:不可变性是指每个 RDD 都是只读的,它所包含的分区信息是不可变的。由于已有的 RDD 是不可变的,所以我们只有对现有的 RDD 进行转化 (Transformation) 操作,才能得到新的 RDD ,一步一步的计算出我们想要的结果。
这样会带来这样的好处:我们在 RDD 的计算过程中,不需要立刻去存储计算出的数据本身,我们只要记录每个 RDD 是经过哪些转化操作得来的,即:依赖关系,这样一方面可以提高计算效率,一方面是错误恢复会更加容易。如果在计算过程中,第 N 步输出的 RDD 的节点发生故障,数据丢失,那么可以根据依赖关系从第 N-1 步去重新计算出该 RDD,这也是 RDD 叫做"弹性"分布式数据集的一个原因。
c.并行操作:因为 RDD 的分区特性,所以其天然支持并行处理的特性。即不同节点上的数据可以分别被处理,然后生成一个新的 RDD。
(4)RDD 的结构
每个 RDD 里都会包括分区信息、依赖关系等等的信息,如下图所示:
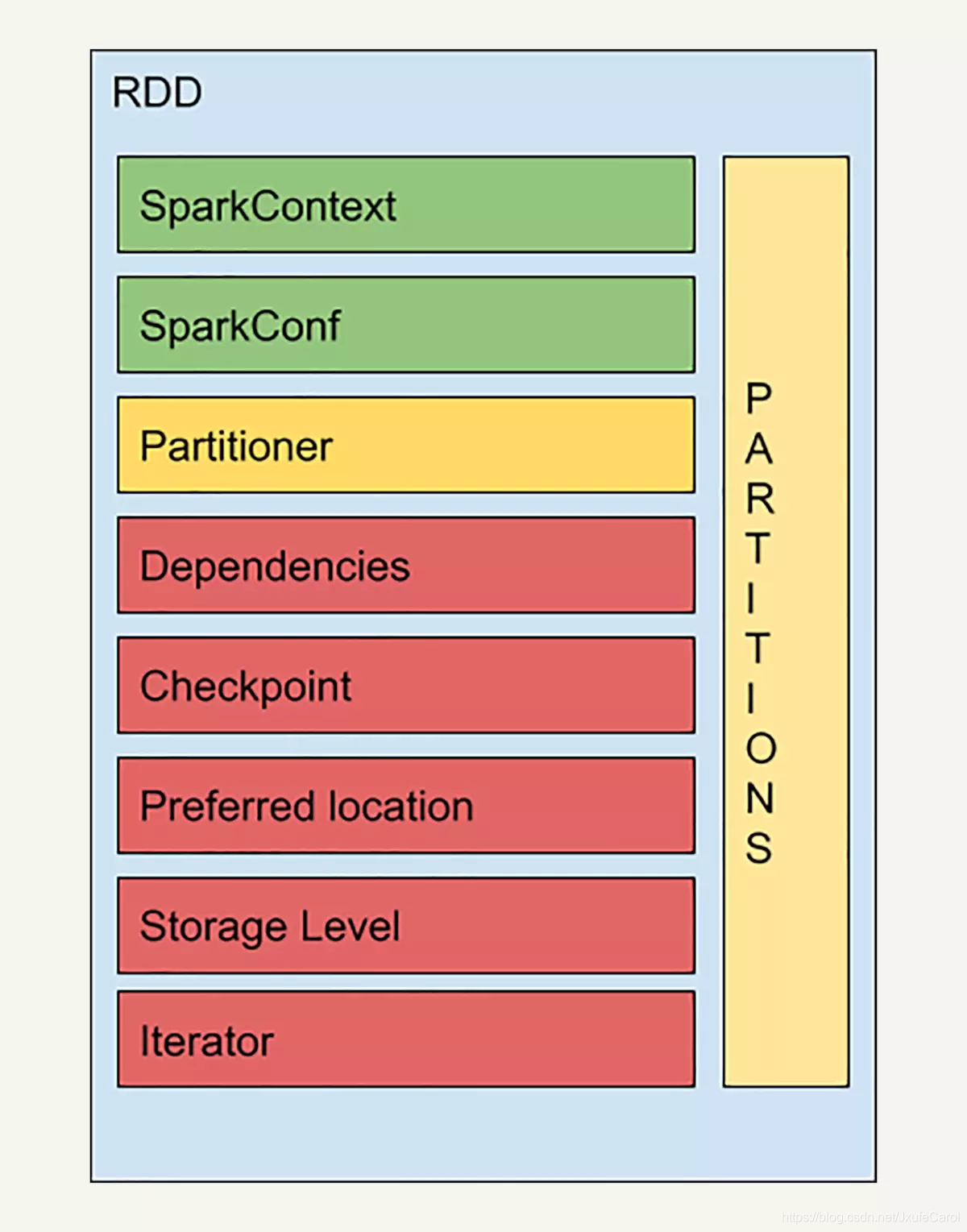
a.Partitions:Partitions 就是上面所说的,代表着 RDD 中数据的逻辑结构,每个 Partion 会映射到某个节点内存或者硬盘的一个数据块。
b.SparkContext:SparkContext 是所有 Spark 功能的入口,代表了与 Spark 节点的连接,可以用来创建 RDD 对象以及在节点中的广播变量等等。一个线程只有一个 SparkContext。
c.SparkConf:SparkConf 是一些配置信息。
d.Partitioner:Partitioner 决定了 RDD 的分区方式,目前两种主流的分区方式:Hash partioner 和 Range partitioner。Hash 就是对数据的 Key 进行散列分布,Rang 是按照 Key 的排序进行的分区。也可以自定义 Partitioner。
e.Dependencies:Dependencies 也就是依赖关系,记录了该 RDD 的计算过程,也就是说这个 RDD 是通过哪个 RDD 经过怎么样的转化操作得到的。
根据每个 RDD 的分区计算后生成的新的 RDD 的分区的对应关系,可以分成窄依赖和宽依赖。
窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区,宽依赖是说父 RDD 的每个分区可以被多个子 RDD 分区使用。如图:
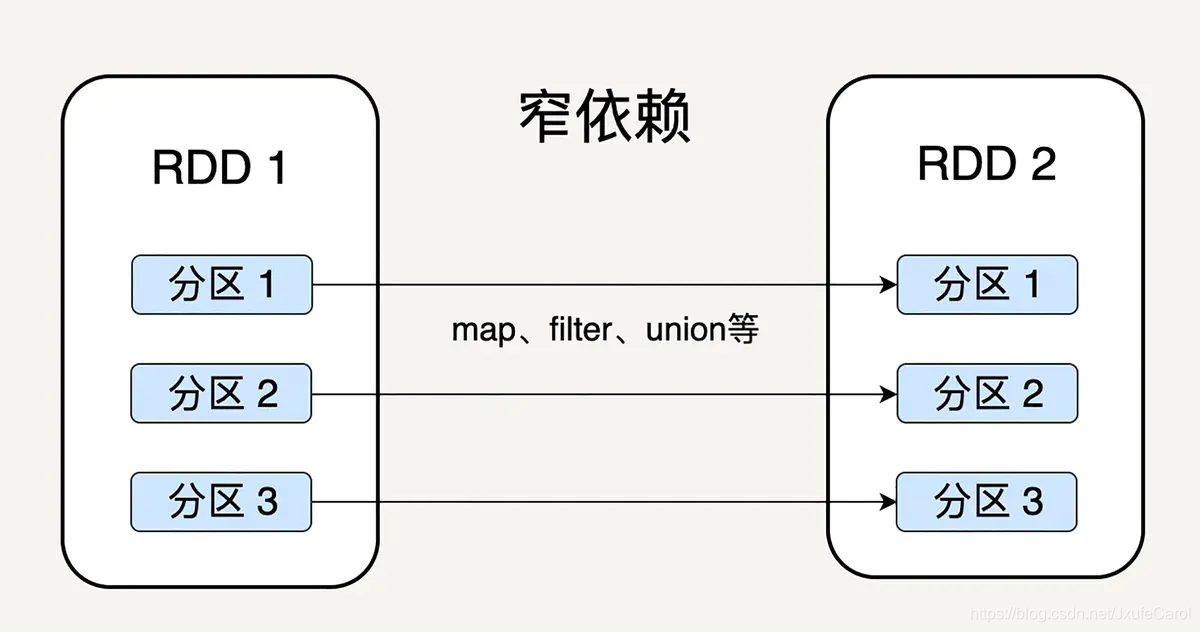
由于窄依赖的特性,窄依赖允许子 RDD 的每个分区可以被并行处理产生,而且支持在同一个节点上链式执行多条指令,无需等待其它父 RDD 的分区操作
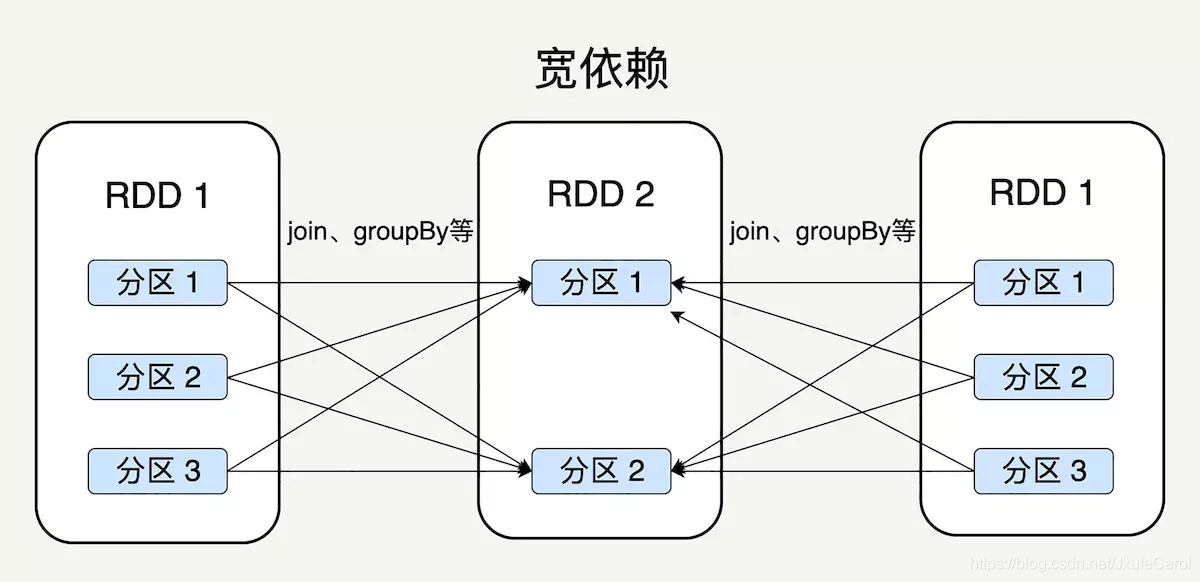
Spark 区分宽窄依赖的原因主要有两点:
1.窄依赖支持在同一节点上进行链式操作,比如在执行了 map 后,紧接着执行 filter 操作。相反,款依赖需要所有父分区都是可用的。
2.从失败恢复的角度考虑,窄依赖失败恢复更有效,因为只要重新计算丢失的父分区即可,而宽依赖涉及到 RDD 的各级多个父分区。
f.Checkpoint:检查点机制,在计算过程中有一些比较耗时的 RDD,我们可以将它缓存到硬盘或者 HDFS 中,标记这个 RDD 有被检查点处理过,并且清空它的所有依赖关系。同时,给它新建一个依赖于 CheckpointRDD 的依赖关系,CheckpintRDD 可以用来从 硬盘中读取 RDD 和生成新的分区信息。
这么做之后,当某个 RDD 需要错误恢复时,回溯到该 RDD,发现它被检查点记录过,就可以直接去硬盘读取该 RDD,无需重新计算。
g.Preferred Location:针对每一个分片,都会选择一个最优的位置来计算,数据不动,代码动。
h.Storage Level:用来记录 RDD 持久化时存储的级别,常用的有:
MEMORY_ONLY:只存在缓存中,如果内存不够,则不缓存剩余的部分。这是 RDD 默认的存储级别。
MEMORY_AND_DISK:缓存在内存中,不够则缓存至内存。
DISK_ONLY:只存硬盘。
MEMORY_ONLY_2 和 MEMORY_AND_DISK_2等:与上面的级别和功能相同,只不过每个分区在集群两个节点上建立副本。
i.Iterator:迭代函数和计算函数是用来表示 RDD 怎样通过父 RDD 计算得到的。
迭代函数首先会判断缓存中是否有想要计算的 RDD,如果有就直接读取,如果没有就查找想要计算的 RDD 是否被检查点处理过。如果有,就直接读取,如果没有,就调用计算函数向上递归,查找父 RDD 进行计算。
(5)转换操作and行动操作

二、转换操作(Transformation)
Transformation用于对RDD的创建,RDD只能使用Transformation创建,同时还提供大量操作方法,包括map,filter,groupBy,join等,RDD利用这些操作生成新的RDD,但是需要注意,无论多少次Transformation,在RDD中真正数据计算Action之前都不可能真正运行。
#转换操作
map()转换:对每一个元素进行转换
filter()转换:从数据集中选择符合条件的数据
.flatMap() : 返回扁平的结果,与.fliter()类似
.distinct():返回唯一值个数
.sample():返回随机样本集
.leftOuterJoin():左连接
join():内连接
reparttition()操作 重新分区,会带来巨大的性能开销
转换操作部分函数总结如下:
- map(func)
将func函数作用到数据集的每个元素,生成一个新的分布式的数据集并返回。 - filter(func)
选出所有func返回值为true的元素,作为一个新的数据集返回 - flatMap(func)
与map相似,但是每个输入的item能够被map到0个或者更多的items输出,也就是说func的返回值应当是一个Sequence,而不是一个单独的item - mapPartitions(func)
与map相似,但是mapPartitions的输入函数单独作用于RDD的每个分区(block)上,因此func的输入和返回值都必须是迭代器iterator。 - mapPartitionsWithIndex(func)
与mapPartitions相似,但是输入函数func提供了一个正式的参数,可以用来表示分区的编号。 - sample(withReplacement, fraction, seed)
从数据中抽样,withReplacement表示是否有放回,withReplacement=true表示有放回抽样,fraction为抽样的概率(0<=fraction<=1),seed为随机种子。
例如:从1-100之间抽取样本,被抽取为样本的概率为0.2
注意:Spark中的sample抽样,当withReplacement=True时,相当于采用的是泊松抽样;当withReplacement=False时,相当于采用伯努利抽样,fraction并不是表示抽样得到的样本占原来数据总量的百分比,而是一个元素被抽取为样本的概率。fraction=0.2并不是说明要抽出100个数字中20%的数据作为样本,而是每个数字被抽取为样本的概率为0.2,这些数字被认为来自同一总体,样本的大小并不是固定的,而是服从二项分布。 - union(otherDataset)
并集操作,将源数据集与union中的输入数据集取并集,默认保留重复元素(如果不保留重复元素,可以利用distinct操作去除,下边介绍distinct时会介绍)。 - intersection(otherDataset)
交集操作,将源数据集与union中的输入数据集取交集,并返回新的数据集。 - distinct([numTasks])
去除数据集中的重复元素。 - groupByKey([numTasks])
作用于由键值对(K, V)组成的数据集上,将Key相同的数据放在一起,返回一个由键值对(K, Iterable)组成的数据集。
注意:1. 如果这一操作是为了后续在每个键上进行聚集(aggregation),比如sum或者average,此时使用reduceByKey或者aggregateByKey的效率更高。2. 默认情况下,输出的并行程度取决于RDD分区的数量,但也可以通过给可选参数numTasks赋值来调整并发任务的数量。 - reduceByKey(func, [numTasks])
作用于键值对(K, V)上,按Key分组,然后将Key相同的键值对的Value都执行func操作,得到一个值,注意func的类型必须满足 - aggregateByKey(zeroValue, seqOp, comOp, [numTasks])
在于键值对(K, V)的RDD中,按key将value进行分组合并,合并时,将每个value和初始值作为seqOp函数的参数,进行计算,返回的结果作为一个新的键值对(K, V),然后再将结果按照key进行合并,最后将每个分组的value传递给comOp函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给comOp函数,以此类推),将key与计算结果作为一个新的键值对(K, V)输出。 - sortByKey([ascending=True], [numTasks])
按照Key进行排序,ascending的值默认为True,True/False表示升序还是降序 - join(otherDataset, [numTasks])
类似于SQL中的连接操作,即作用于键值对(K, V)和(K, W)上,返回元组 (K, (V, W)),spark也支持外连接,包括leftOuterJoin,rightOuterJoin和fullOuterJoin。 - cogroup(otherDataset, [numTasks])
作用于键值对(K, V)和(K, W)上,返回元组 (K, (Iterable, Iterable))。这一操作可叫做groupWith。 - cartesian(otherDataset)
笛卡尔乘积,作用于数据集T和U上,返回(T, U),即数据集中每个元素的两两组合。 - pipe(command, [envVars])
将驱动程序中的RDD交给shell处理(外部进程),例如Perl或bash脚本。RDD元素作为标准输入传给脚本,脚本处理之后的标准输出会作为新的RDD返回给驱动程序。 - coalesce(numPartitions)
将RDD的分区数减小到numPartitions个。当数据集通过过滤规模减小时,使用这个操作可以提升性能。 - repartition(numPartitions)
重组数据,数据被重新随机分区为numPartitions个,numPartitions可以比原来大,也可以比原来小,平衡各个分区。这一操作会将整个数据集在网络中重新洗牌。 - repartitionAndSortWithinPartitions(partitioner)
根据给定的partitioner函数重新将RDD分区,并在分区内排序。这比先repartition然后在分区内sort高效,原因是这样迫使排序操作被移到了shuffle阶段。
三、行动操作(Action)
Action是数据执行部分,其通过执行count,reduce,collect等方法真正执行数据的计算部分。实际上,RDD中所有的操作都是Lazy模式进行,运行在编译中不会立即计算最终结果,而是记住所有操作步骤和方法,只有显示的遇到启动命令才执行。这样做的好处在于大部分前期工作在Transformation时已经完成,当Action工作时,只需要利用全部自由完成业务的核心工作。
#行动操作
count() 返回数据集中的元素个数
countByKey 与count类似,但是是以key为单位进行统计
collect() 以数组的形式返回数据集中的所有元素 慎用
first() 返回数据集中的第一个元素
take(n) 以数组的形式返回数据集中的前n个元素 比较有用
takeSample(boolean, sampleNum,seed):该函数是抽取随机数
boolean 是否应该被替换
sampleNum: 为要随机抽取多少个在Rdd中的元素
seed : 即种子,在算法中充当着随机参数,根据随机参数的不同,最后产生的结果不同,seed参数相同,使用的算法boolean也相同
reduce(func) 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 多个分区和一个分区结果不一样
reduceByKey() 基于键-键的方式 ,多个分区和一个分区结果一样
foreach(func) 将数据集中的每个元素传递到函数func中运行
[补充] map() vs foreach()
1.map()会分配内存空间存储新数组并返回,forEach()不会返回数据。
2.forEach()允许callback更改原始数组的元素。map()返回新的数组
Actions算子是Spark算子的一类,这一类算子会触发SparkContext提交job作业。
- reduce(func)
使用函数func(两个输入参数,返回一个值)对数据集中的元素做聚集操作。函数func必须是可交换的(我理解的就是两个参数互换位置对结果不影响),并且是相关联的,从而能够正确的进行并行计算。 - collect()
在driver程序中以数组形式返回数据集中所有的元素。这以action通常在执行过filter或者其他操作后返回一个较小的子数据集时非常有用。 - count()
返回数据集中元素的个数。 - first()
返回数据集中的第一个元素,相当于take(1)。 - take()
以数组形式返回数据集中前n个元素。需要注意的是,这一action并不是在多个node上并行执行,而是在driver程序所在的机器上单机执行,会增大内存的压力,使用需谨慎。 - takeSample(withReplacement, num, [seed])
以数组形式返回从数据集中抽取的样本数量为num的随机样本,有替换或者无替换的进行采样。可选参数[seed]可以允许用户自己预定义随机数生成器的种子。 - takeOrdered(n, [ordering])
返回RDD的前n个元素,可以利用自然顺序或者由用户执行排序的comparator。 - saveAsTextFile(path)
将数据集中的元素以文本文件(或者文本文件的一个集合)的形式写入本地文件系统,或者HDFS,或者其他Hadoop支持的文件系统的指定路径path下。Spark会调用每个元素的toString方法,将其转换为文本文件中的一行。 - saveAsSequenceFile(path)
将数据集中的元素以Hadoop SequenceFile的形式写入本地文件系统,或者HDFS,或者其他Hadoop支持的文件系统的指定路径path下。RDD的元素必须由实现了Hadoop的Writable接口的key-value键值对组成。在Scala中,也可以是隐式可以转换为Writable的键值对(Spark包括了基本类型的转换,例如Int,Double,String等等) - saveAsObjectFile(path)
利用Java序列化,将数据集中的元素以一种简单的形式进行写操作,并能够利用SparkContext.objectFile()加载数据。(适用于Java和Scala) - countByKey()
只能作用于键值对(K, V)形式的RDDs上。按照Key进行计数,返回键值对(K, int)的哈希表 - foreach(func)
在数据集的每个元素上调用函数func。这一操作通常是为了实现一些副作用,比如更新累加器或者与外部存储系统进行交互。注意:在foreach()之外修改除了累加器以外的变量可能造成一些未定义的行为。更多内容请参阅闭包进行理解。

















 24
24

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









