





1.头插法:将新结点插入到头结点之后、当前首元结点之前(插入后新结点成为新的首元结点)
(补充:头插法的核心是 “插在有效数据的最前端”,易误解为 “替换首元结点”,实际是插在首元结点前面,原首元结点变为第二个有效结点。)
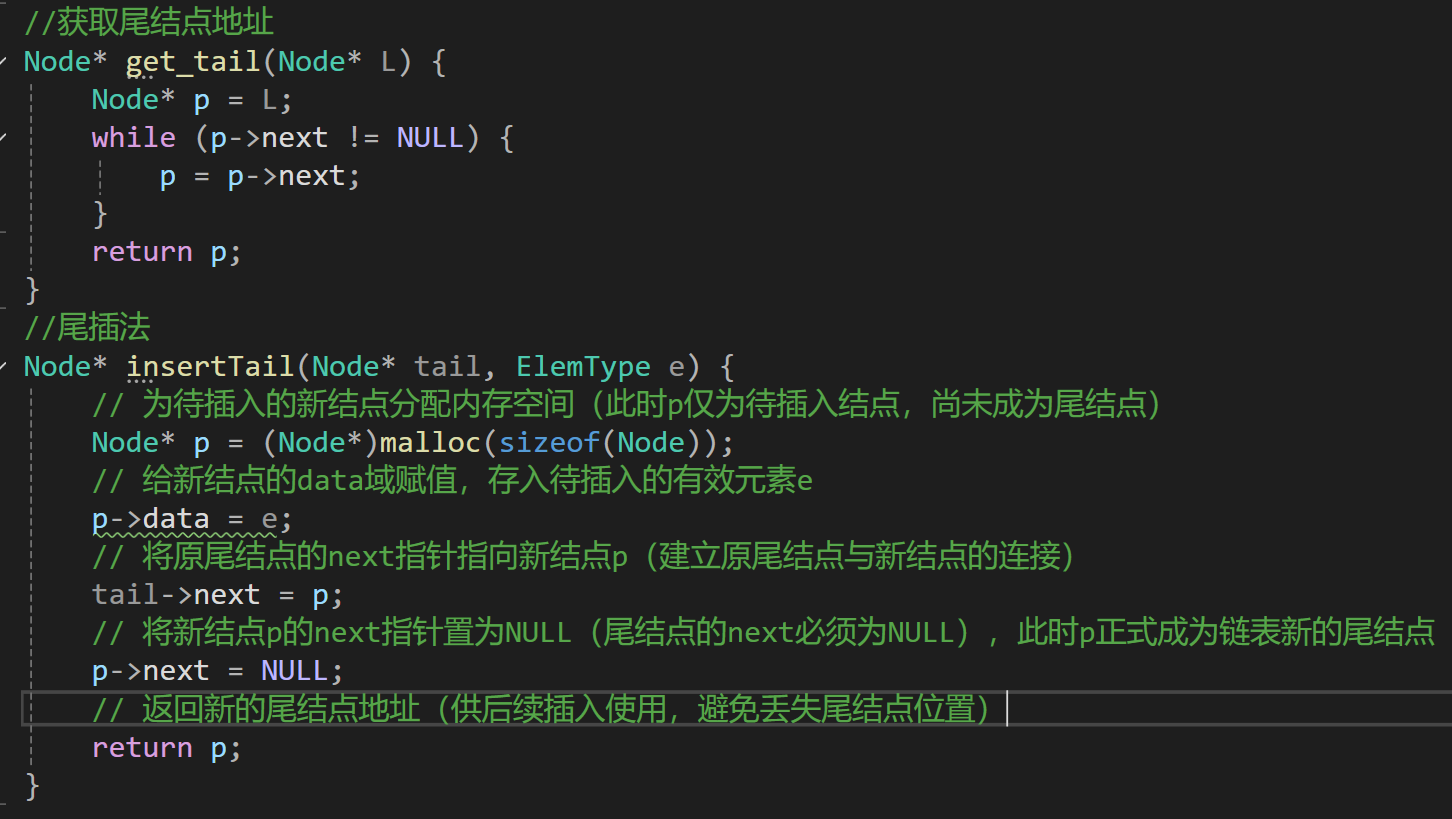
2.尾插法:将新结点插入到链表的尾结点之后(插入后新结点成为新的尾结点)。核心步骤:① 获取当前尾结点的地址:通过 while 循环遍历链表(从表头开始),当指针p->next == NULL时,p 即为当前尾结点;② 为待插入的新结点开辟内存空间(使用 malloc 创建新结点,建议命名为new_node,避免与遍历的 p 重名);③ 给新结点赋值:new_node->data = e;④ 建立连接:将原尾结点的next指针指向新结点(p->next = new_node);⑤ 标记新结点为尾结点:将新结点的next指针置为 NULL(new_node->next = NULL)。
3.在指定位置插入:
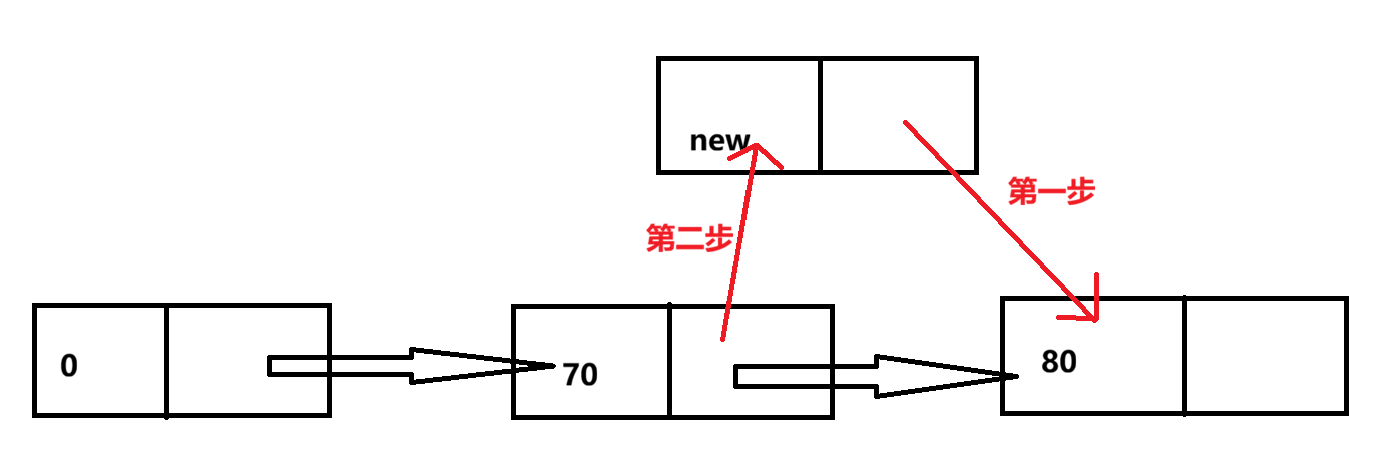
改变箭头指向时顺序要严格按照上图所示,目的是:防止断链,先让插入元素指向前一个元素指向的位置,再将前一个元素的指向改为要插入的元素
具体的插入操作:首先找到要插入位置的前一个结点(通过while遍历查找),其次为要插入的节点开辟新的内存空间,最后通过以下图片的操作,实现链表的连接

最后一行我在理解的时候出现了误区,为什么不是p->next=q->data(从图2的指向中会得到这样的结论),可以从以下两个角度理解:
1.类型不匹配:p->next指向的是结点,而结点是指针类型的变量,data是数据内容,存放的是int类型的变量
2.逻辑上讲不通:插入q的本质是将q这个完整的结点插到p和p原先的后继结点之间
4.豆包总结:
链表插入的核心是操作 “结点的 next 指针”(而非 “箭头”),所有插入方法的本质都是:
- 头插法:新结点插在头结点后、首元结点前,成为新首元;
- 尾插法:新结点插在尾结点后,成为新尾结点(需先找尾、再连原尾到新结点、最后新结点 next 置 NULL);
- 指定位置插入:先让新结点连后继,再让前驱连新结点(防断链);
- 所有插入中,
next指针只能指向 “结点(Node*)”,不能指向 “数据(data)”—— 类型和逻辑都不允许。

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









