




 本文深入探讨了大数据处理中distinct与group by两种去重方法的原理及应用,详细对比了它们在性能、空间占用和执行效率上的差异。通过具体实例,展示了在不同场景下选择合适去重策略的重要性。
本文深入探讨了大数据处理中distinct与group by两种去重方法的原理及应用,详细对比了它们在性能、空间占用和执行效率上的差异。通过具体实例,展示了在不同场景下选择合适去重策略的重要性。
在数据量比较大的情况下,几乎没人用distinct,因为用distinct去重,它会不使用map端的combiner,所以在后续的reduce阶段,不管你设置多少个set reduce task都不管用,都只用1个reduce ,这样肯定会造成倾斜,大部分公司在做hql去重的时候都是用的group by去重,下面举个例子,看一下distinct跟group by的关系。
比如我有一张表a
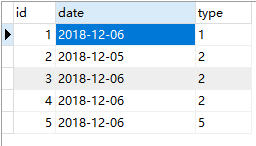
下面是三种查询方式,并且都起到了去重的作用
SELECT date,COUNT(DISTINCT type) from a;
SELECT COUNT(1) FROM(SELECT 1 FROM a GROUP BY type)t;
SELECT date,COUNT(1) FROM(SELECT date, 1 FROM a where date="2018-12-05" GROUP BY type )t GROUP BY date;
两种去重实现方式有所不同:
distinct的两种后台排序方式包括:排序(Sort)法,哈希(Hash)法。
排序法(Sort)将表格中的数据全部按照distinct指定的列为key进行排序,然后逐行迭代,
每迭代出一行数据都与上一行数据根据key作对比,如果相同,则丢弃当前行继续迭代下一行,
如果不同则输出。排序法带来的一个副作用就是数据输出按照key有序。
哈希法(Hash)将表格中的数据全部按照distinct指定的列值为key作为hash key进行分桶,key相同的行自然就被区分出来了。
distinct是将要去重的列中所有的数据放到一个内存中,可以理解为hash值key-value形式,key为列名,value为值,然后计算
group by一般是使用的sort排序,但是会多一个子查询,时间上比较长,但是占用的空间小,适合在大数据环境下,
工作时负责的语句我一般是单独拿出来然后join,自己留着备份
SELECT COUNT(1) FROM (SELECT 1 FROM yunpos_invoice GROUP BY invoice_type)tmp;
SELECT COUNT(DISTINCT invoice_type) FROM yunpos_invoice;
SELECT sid,COUNT(1) FROM (SELECT sid,1 FROM yunpos_invoice GROUP BY invoice_type)b;
SELECT sid,COUNT(invoice_type) FROM (SELECT sid,invoice_type FROM yunpos_invoice GROUP BY sid,invoice_type)b GROUP BY sid;
SELECT sid,COUNT(1) FROM (SELECT sid,1 FROM yunpos_invoice GROUP BY sid,invoice_type)b GROUP BY sid;
SELECT sid,COUNT(1) FROM (SELECT sid,1 FROM export.yunpos_invoice where etlmonth=11 and etlday=22 GROUP BY sid,invoice_type)b GROUP BY sid;后续会进一步研究distinct
参考博客:

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









