




软件包管理工具
什么是软件包
在 Linux 下安装软件,一个通常的办法是下载到软件程序的源代码,并进行编译, 然后得到可执行程序,这样就可以使用某个软件了;但是这样太麻烦了, 于是出现了一些大佬,他们把一些常用的软件提前编译好,做成软件包(可以理解成 windows 上的安装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包,此时只需直接进行安装就可使用这个软件程序了。
软件包和软件包管理器,就好比 “App” 和 “应用商店” 这样的关系。在 Linux 下 yum(Yellow dog Updater,Modified)是一种非常常用的一种包管理器,主要应用在 Fedora,RedHat,Centos 等发行版上。
注意事项
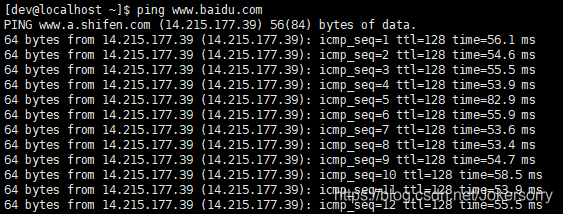
首先要确保你的虚拟机连接上网络,检查方法是输入指令ping www.baidu.com,如果出现下图所示内容则表示连接成功,这个会一直向下显示下去,此时按ctrl + c即可终止命令。
操作指令:
yum list:列出所有可安装软件;yum list | grep 软件名称:上一个命令列出可安装软件是非常多的,所以当我们可以使用筛选命令来找出我们想要的软件包,例如:

简要说明:
- “x86_64” 后缀表示 64 位系统的安装包,“i686” 后缀表示 32 位系统安装包,选择包时要和系统匹配。
- “el7” 表示操作系统发行版的版本.。“el7” 表示的是 centos7/redhat7。“el6” 表示 centos6/redhat6。
- 最后一列,base 表示的是 “软件源” 的名称,类似于 “小米应用商店”,“华为应用商店” 这样的概念。
yum search 软件名称:这个也可以查询软件,与上面略有不同;sudo yum install 软件名称:安装软件包,需要手动输入 ‘y’ 确认;sudo yum remove 软件名称:卸载软件;
需要注意的是,在安装软件或者删除软件时,需要管理员权限,所以要么是 root 用户,要么使用 sudo 提权;
这里我们可以安装这样一个软件来试一试上面这些命令,软件包名字叫 lrzsz,这个软件的作用是实现虚拟机和主机之间的文件传输,主要操作是输入命令rz:从 Windows 传如数据到 Linux,输入命令sz:从 Linux 传如数据到 Windows。
编辑器
在前面的指令学习过程中,我说到过一个指令echo 内容 > 文件名可以向文件中写入内容,但是这样子的写入十分的难看,而且格式还没发自己掌握,所以我们一般使用 vim 编辑器向文件中写入,vim 是 Linux 下的从 vi 发展出来的一个文本编辑器,代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
输入指令vim 文件名称即可进入 vim 编辑模式,在 vim 编辑器中由于不能使用鼠标操作,所有的功能都是由键盘来实现的,所以就存在了很多模式来更完全的实现所有功能,总共有 12 种操作模式,但是我们主要使用的就三种:普通模式,插入模式,底行模式;
插入模式
首先需要说明的是,在进入 vim 编辑器之后我们就是处在普通模式下,而在普通模式中是不能输入内容的,只有在插入模式下才可以写入内容,所以我们必须通过按键盘来进入:
i:在光标位置写入;I:在光标当前行的首位置写入;a:在光标下一个位置写入;A:在光标所在行的尾位置写入;o:在光标当前行的下一行写入(重新生成一行);O:在光标当前行的上一行写入(重新生成一行);
在进入插入模式之后,就可以正常进行内容的写入,并且在这个模式中最主要的功能是可以写入我们的代码,拥有自动换行、提示、高亮显示、颜色区别等功能,十分强大,等我们写入完毕之后,按Esc退回到普通模式。
底行模式
底行模式是由普通模式进入的,在普通模式下按英文冒号:即可进入,按Esc退回到普通模式。底行模式主要作用是在内容写入完毕之后进行保存用的:
w:保存写入的内容;q:退出 vim 编辑器;wq:保存并退出 vim;q!:强制退出 vim(打开一个不具备写权限的文件,修改后保存不了也推出不了,可以强制退出);
其他操作:set nu:在文件中的每一行前面列出行号;set nonu:不要在文件中的每一行前面列出行号;数字:输入一个数字,再按回车键就会跳到该行了;/ 关键字:从上至下查找指定关键字,按 n 向下继续查找下一个;? 关键字:从下至上查找指定关键字,按 n 向上继续查找下一个;小行号,大行号s/文中已有单词/要替换单词/g:将 [小行号,大行号] 范围内的文中已有单词全部替换为指定单词,如果不加最后的/g,那么将会替换每行出现的第一个已有字符;-
行号s/文中已有单词/要替换单词/g:将指定行号中的已有单词全部替换为指定单词,如果不加最后的/g,那么将会该行出现的第一个已有字符;
%s/文中已有单词/要替换单词/g:将全文范围内文中已有单词替换为指定单词,如果不加最后的/g,那么将会替换每行出现的第一个已有字符;
普通模式
光标移动:
hjkl:对应左下上右(上下左右键也可以操作);ctrl + f/b:向上 / 下翻页;gg/G:光标移动到文档首行 / 尾行;$:移动到光标所在行的行尾;^:移动到光标所在行的行首;w:光标跳到下个字的开头;e:光标跳到下个字的字尾;b:光标回到上个字的开头;%:选中一个括号,匹配另一个括号;
内容操作:
yy/nyy:复制一行或 n 行(从当前行为 1 开始数 n 行);p/np:向下粘贴一遍或 n 遍;P/nP:向上粘贴一遍或 n 遍;dd/ndd:剪切一行或 n 行(从当前行为 1 开始数 n 行,大写的话向上剪切);x:删除光标所在位置的字符;X:删除光标所在位置的前一个字符;数字 x:删除指定长度个字符(从光标位置开始计数);dw:删除光标所在位置的单词(一个小整体);
其他操作:
u:撤销上一步操作;ctrl + r:恢复上一步的撤销;ctrl + g:列出光标所在行的行号;数字 G:移动光标到指定行行首;gg = G:若代码没对齐,会进行全文对齐操作;
注意事项
另外需要在这提前说明一点的是,许多人在 vim 中的书写格式感觉不太符合自己的需求,还有一些其他的格式什么的也都不太满意,其实在 Linux 下,我们可以自己手动配置 vim 的格式,不过 vim 的配置不太容易,它有自己的语法,许许多多的命令,因此我自己也说不太清楚,不过可以给大家推荐一篇博客,可以学学那看大佬是怎么配置的:Vim的终极配置方案,完美的写代码界面! ——.vimrc
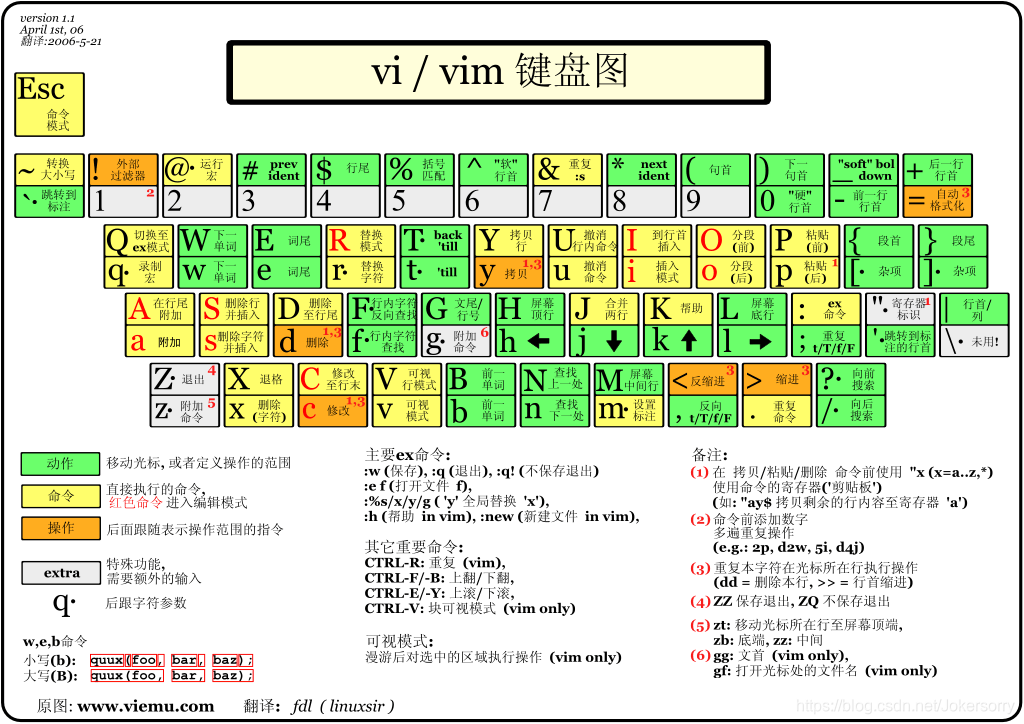
最后列出一张 vim 键盘图,是在网上搜到的,本图中列出了所有 vim 中键盘上的操作,十分详细,如下所示:
编译器
一个程序从诞生到执行经历了许多步骤:代码----预处理----编译----汇编----链接----可执行程序,若想了解的更多,详见我的程序的编译这篇博客,本次博客我们主要讲的是在 Linux 下如何使用编译器来执行代码。
不过在此之前呢,我想对链接这一步做一补充,我们在写代码的过程中使用到了很多库,我们在链接的这一过程中就进行了链接库,从而保证代码在执行的时候能够使用到库中的内容,而库被分为:动态库、静态库,因此连接库的方式也被分为:动态链接、静态链接;在 gcc 编译器中采用的是动态链接;
ldd 程序名:查看程序所依赖的库文件所在位置;
- 动态链接:链接动态库生成可执行程序,并没有把库中函数的实现指令直接拿过来写入可执行程序中,而是在可执行程序中记录了库中函数的符号信息表,在执行程序的时候需要去加载动态库到内存中;
- 优点:程序小,运行时动态库被加载到内存中;可共享,可以多个程序使用同一份内存中库函数的代码,减小冗余;便于模块代码替换;
- 适用:一些模块化、便于功能替换的接口适用动态库;
- 缺点:依赖强,运行需要依赖动态库,若动态库不存在,则无法运行;
- 静态链接:链接静态库生成可执行程序,直接将库中我们用到的函数的实现代码指令,写入到了可执行程序文件中;
- 优点:无依赖,不需要任何外物就可直接运行;
- 适用:功能改动小,并且只有当前程序使用的时候使用静态库;
- 缺点:程序大,可执行程序中会加载很多函数;冗余高,若多个程序使用同一个库函数,则这个库函数会被包含多份;
gcc/g++
编译器是将高级语言代码进行解释,使之成为机器可识别的指令,然后再对指令进行组织生成可执行程序;
指令操作:
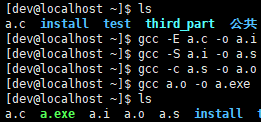
gcc -v:查看编译器版本信息,将 gcc 换成 g++ 即可查看 g++ 版本信息;执行结果 -o 指定文件:将执行结果输出(重定向)到指定文件;gcc -E 代码文件.c -o 指定文件.i:对代码文件只进行预处理,需要把它重定向到一个输出文件里面;gcc -S 预处理文件.i -o 指定文件.s:将预处理结果编译成汇编语言,需要把它重定向到一个输出文件里面;gcc -c 汇编文件.s -o 指定文件.o:链接头文件、代码文件等等,将其合并到一起,需要把它重定向到一个输出文件里面;gcc 链接文件.o -o 指定文件.exe:通过 gcc 生成可执行文件;
在 Linux 中是不靠后缀名来区分文件的,我们弄得这些后缀,完全是为了让我们自己能够知道每个文件是干什么的;
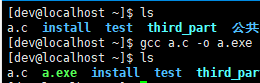
gcc 代码文件 -o 指定文件:我们通过 vim 写完代码之后,并不是每次都需要通过上述步骤才能生成可执行文件,只需执行此命令即可;
文件路径/文件名:输入文件名即可执行程序,此处的输入可以是相对路径,也可以是绝对路径;
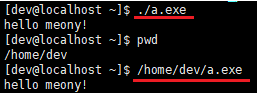
g++ 实际使用和 gcc 一样,唯一不同的是代码文件中的代码时由 c++ 语言进行编写的。
gdb
调试器是调试、观察程序的运行过程,通常是为了排查可执行程序的运行错误。可执行程序分为debug:调试版,不对代码进行优化,并加入调试信息;release:发布版,不包含调试信息,并对代码进行优化。
gcc/g++ 默认生成release版本,因此我们想要调试程序就要使用指令:gcc -g 代码文件 -o 指定文件;以此来将代码文件变为debug版本;
gdb 运行文件指令:此时可进入代码的调试界面,在此界面下可进行下面的指令操作:r 或者 run:直接运行程序;start:开始进行调试;l 或者 list:查看调试行附近的代码;l 或者 list 文件名:行号:查看指定行号附近的代码;n 或者 next:逐过程下一步,遇到函数直接运行完毕;s 或者 step:逐语句下一步,遇到主函数则进入函数继续调试;until 文件名:行号:直接运行到指定位置;c 或者 continue:继续从当前调试位置向下运行;b 或者 break 文件名:行号:在指定位置打断点;b 或者 break 函数名字:在指定函数内部第一行打断点;i b 或者 info break:查看断点信息,且每个断点都会有一个编号;d 或者 delete 断点编号:删除指定断点;watch 变量名字:变量监控断点,当变量发生改变的时候就停下来;q 或者 quit:退出 gdb 调试模式,可能会有询问信息,按 y 即可;p 或者 print 变量名:查看此时变量内容;p 或者 print 变量名=值:设置指定变量为指定值;bt 或者 backtrace:查看函数调用栈,通常用语检测程序运行崩溃时位置,栈顶位置的函数就是程序发生崩溃的位置;
make/makefile
Makefile:是一个文本文件,记录一个项目的构建流程规则;
vim Makefile:进入 Makefile 文件编写;Makefile的编写规则:

- 举例如下:下面是 hello.c 代码和 Makefile 中的内容,以及运行结果图;
//hello.c 代码
#include<stdio.h>
int main(){
printf("hello money!\n");
return 0;
}
//Makefile 文件内容
hello.exe:hello.c
gcc hello.c -o hello.exe

Makefile文件编写完毕之后,只需敲击make命令即可执行;- 预定义变量的使用:
$@:表示目标对象;$^:表示所有依赖对象;$<:表示依赖对象的第一个;变量名=$(wildcard ./*.c):表示将当前目录下以 ‘.c’ 结尾的文件名称放到变量中;找 ‘.c’ 文件只是一种常见用法,这个可以灵活运用;在这里面使用的*是可以匹配任意字符的,要使用多个具有相同部分的文件时,可以使用该符号代替不同部分,省去很多麻烦;变量名1=$(patsubst %.c, %.o, $(变量名2)):将变量名 2 中的内容放到变量名 1 中,并将以 ‘.c’ 结尾的文件替换成 ‘.o’ 结尾的文件;这也只是一种常见用法,可以灵活多变;在这里面使用的%也可以匹配字符,成对使用时可以让两个使用者匹配相同字符,就相当于对应匹配;$(变量名):使用变量中的文件,例如将变量中的文件当做依赖文件;- 上面的几种方法在依赖对象很多时,可以起到很重要的作用,例如:下面为 a.c、b.c 代码内容和 Makefile 文件内容,以及运行结果图:
//a.c 代码
#include<stdio.h>
void test(){
printf("hello meony!\n");
int i = 10;
while(i--){
printf("%d ",i);
}
printf("\n");
}
int main(){
test();
return 0;
}
//b.c 代码,随便一些内容
int add(int a, int b){
return a + b;
}
//Makefile 内容
src=(wildcard ./*.c)
test.exe:$(src)
gcc $^ -o $@
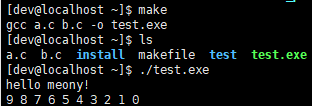
- 程序的编译过程:预处理——编译——汇编——链接,在项目的构建中这个整体过程会分为两步:编译与链接,这样的好处是如果只修改了一个 .c 文件,那么此时再次运行,只需将改变的 .c 重新编译,然后和其他的进行连接,不需要将所有文件全部重新编译,节约了时间成本。
make的执行规则:- 在命令行中敲击
make指令后,则表示运行make解释程序,程序会在当前目录下找到名为Makefile的文件,解释执行其中构建的规则; - 在规则中,找到要生成的第一个目标对象,判断目标对象是否存在,如果存在则和依赖文件最后一次修改时间对比(时间最新,则不生成,否则需要执行生成指令),如果不存在,则执行生成对象指令;然后退出
Makefile文件; make在生成目标对象的时候,如果依赖对象不存在,则先生成依赖对象,然后再生成目标对象,举例如下,生成 hello.c 文件编译过程的所有文件:
- 在命令行中敲击
//hello.c 代码
#include <stdio.h>
int main()
{
printf("hello Makefile!\n");
return 0;
}
//Makefile 内容
//hello.o 不存在,则需先生成
hello:hello.o
gcc hello.o -o hello
//hello.s 不存在,则需先生成
hello.o:hello.s
gcc -c hello.s -o hello.o
//hello.i 不存在,则需先生成
hello.s:hello.i
gcc -S hello.i -o hello.s
//hello.i 不存在,则需先生成
hello.i:hello.c
gcc -E hello.c -o hello.i
- 另外我们可以利用上一条中的特性来进行多个编译代码的执行,此处的目标对象是一个无所谓的变量名,目标对象则是需要的编译生成的文件——
变量名:目标对象1 目标对象2 ...;
//Makefile文件如下
all:test1 test2
test1:test1.c
gcc $^ -o $@
test2:test2.c
gcc $^ -o $@
.PHONY::伪对象,声明一个目标对象与外部文件无关,表示每次这个对象不管是否最新都要重新生成,使用方法如下,声明 clean 为伪对象,每次都要执行删除命令,这个

git
相信大家对 git 应该不陌生吧,这是一种项目版本管理工具,在 Windows 下的 git 使用起来还是挺容易的,因为是图形化界面嘛,不过在 Linux 也没有麻烦多少,就是多掌握几个指令而已;
- 首先检查 Linux 下是否安装了 git,在终端敲击
git version命令,如果显示git version 一串数字,则说明已经安装,如果没有则需要使用 yum 命令先安装软件; - 在 GitHub 建立远程仓库;
- 将远程仓库的地址克隆到本地文件中,使用命令
git clone 地址; - 提交本次修改记录,提交当前文件夹下所有改动的命令
git add --all ./,提交当前文件夹下某个文件改动的命令git add 文件名(标明路径); - 提交本地仓库版本管理,使用命令
git commit -m "备注修改信息"; - 将本地版本同步到远程仓库,使用命令
git push origin master;

















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









