




文章目录
1. SAM-6D: Segment Anything Model Meets Zero-Shot 6D Object Pose Estimation

https://github.com/JiehongLin/SAM-6D

图1所示。我们提出了SAM-6D用于零拍摄6D物体姿态估计。SAM-6D以混乱场景的RGB图像(a)和深度图(b)为输入,对新对象©进行实例分割(d)和姿态估计(e)。我们给出了SAM-6D在BOP基准的七个核心数据集[54]上的定性(qualitative)结果,包括YCB-V、LM-O、HB、T-LESS、IC-BIN、ITODD和td - l,从左到右排列。以电子版浏览效果最佳。
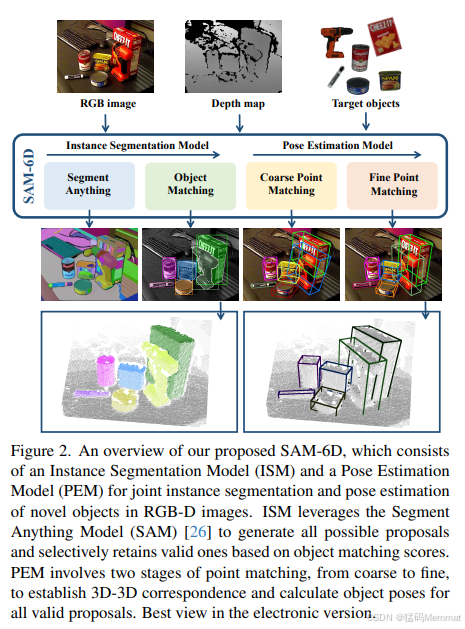
图2。我们提出的SAM-6D概述,它包括一个实例分割模型(ISM)和一个姿态估计模型(PEM),用于RGB-D图像中新对象的联合实例分割和姿态估计。ISM利用Segment Anything Model (SAM)[26]生成所有可能的提案,并根据对象匹配得分选择性地保留有效提案。PEM包括两个阶段的点匹配,从粗到细,建立3D-3D对应关系,并计算所有有效提议的目标姿态。以电子版浏览效果最佳。
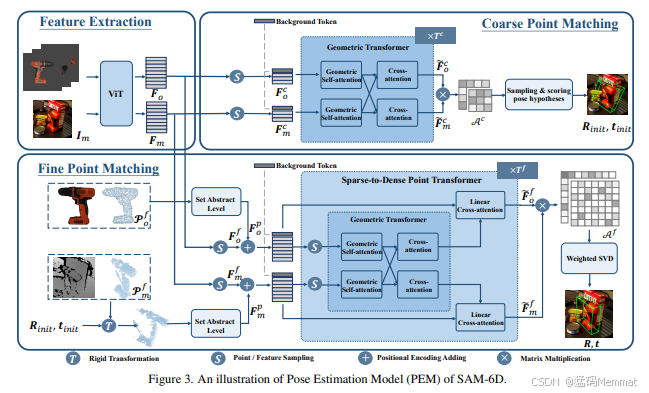
图3。SAM-6D的位姿估计模型(PEM)。
1.1 Method
- SAM-6D框架:提出了一个新颖的框架,用于通过两个步骤实现RGB-D图像中新对象的实例分割和姿态估计。
- 实例分割模型(ISM):利用Segment Anything Model (SAM) 生成所有可能的对象提议,并通过对语义、外观和几何学的对象匹配分数来选择有效的提议。
- 姿态估计模型(PEM):通过两阶段的点匹配过程来解决姿态估计问题,包括粗略点匹配和精细点匹配,使用背景标记的设计来构建密集的3D-3D对应关系。
- 对象匹配分数:设计了一种新颖的对象匹配分数,该分数考虑了语义、外观和几何三个方面,以评估提议与给定新对象的匹配程度。
- 背景标记:提出了一种使用背景标记的简单有效解决方案,通过在特征空间中学习非重叠点与背景标记的对齐,建立部分到部分的点匹配问题。
- 稀疏到密集点变换器(Sparse-to-Dense Point Transformers):提出了一种新颖的设计,用于在第二阶段的精细点匹配中有效地建模密集的交互。
1.2 Innovation Point
-
零样本迁移性能:SAM-6D利用了SAM的零样本迁移性能,能够处理在训练期间未见过的新对象。
-
两阶段点匹配:通过粗略点匹配和精细点匹配的两阶段过程,提高了对遮挡、分割不准确和传感器噪声的鲁棒性。
-
背景标记设计:使用背景标记来解决点集之间的非重叠点的匹配问题,避免了使用迭代优化的最优传输方法,提高了效率。
-
稀疏到密集点变换器:提出了一种新颖的设计,通过在稀疏版本的密集特征上实现交互,然后将增强的稀疏特征分布回密集特征,有效地模拟了密集关系。
-
无需网络重新训练或微调:ISM基于SAM构建,不需要网络重新训练或微调,提高了模型的通用性和实用性。
-
跨数据集评估:在BOP基准的七个核心数据集上评估了SAM-6D的性能,证明了其在实例分割和新对象姿态估计方面的优越性能和鲁棒的泛化能力。
1.3 Conclusion
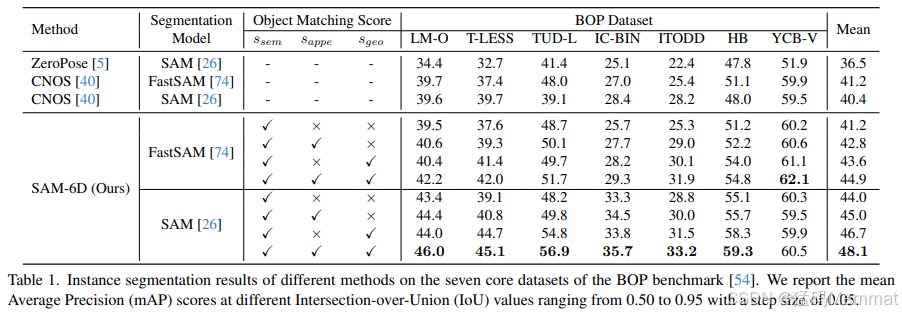
表1。不同方法在BOP基准的七个核心数据集上的实例分割结果[54]。我们报告了在不同路口- union (IoU)值下的平均平均精度(mAP)分数,范围为0.50至0.95,步长为0.05。
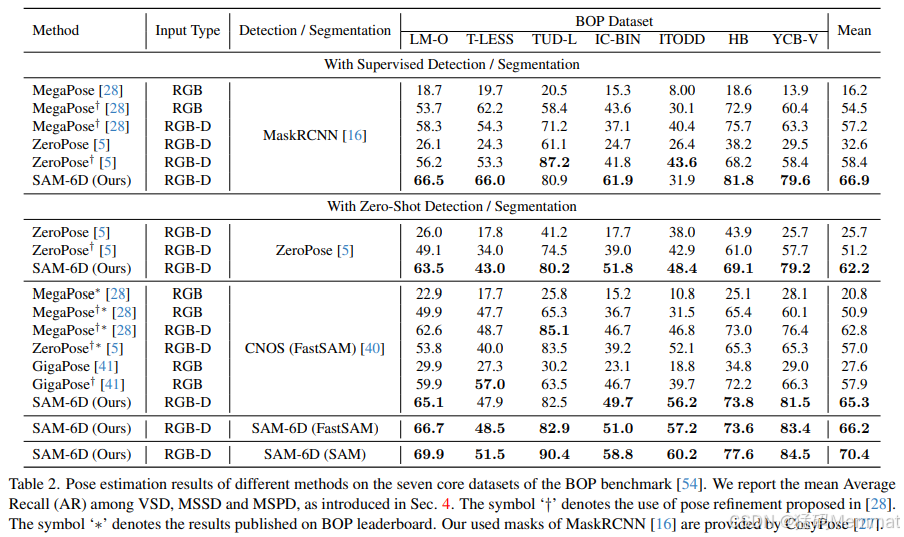
表2。不同方法在BOP基准的七个核心数据集上的位姿估计结果[54]。我们报告平均值VSD, MSSD和MSPD之间的召回(AR),如第4节所介绍的。符号“f”表示使用了[28]中提出的姿态细化。符号表示BOP排行榜上公布的结果。我们使用的MaskRCNN掩码[16]由CosyPose[27]提供。
本文以任意分割模型(SAM)作为zero-shot 6D目标姿态估计的高级起点,提出了一种新的SAM-6D框架,该框架由实例分割模型(ISM)和姿态估计模型(PEM)组成,分两步完成任务。ISM利用SAM对所有潜在的对象提案进行分割,并根据语义、外观和几何形状为每个提案分配对象匹配分数。PEM然后通过求解局部到局部点匹配问题来预测每个提案的目标姿态。粗点匹配和细点匹配两个阶段。在BOP基准测试的7个核心数据集上验证了SAM-6D的有效性,其中SAM-6D显著优于现有方法。
2. Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively
2.1 Method
-
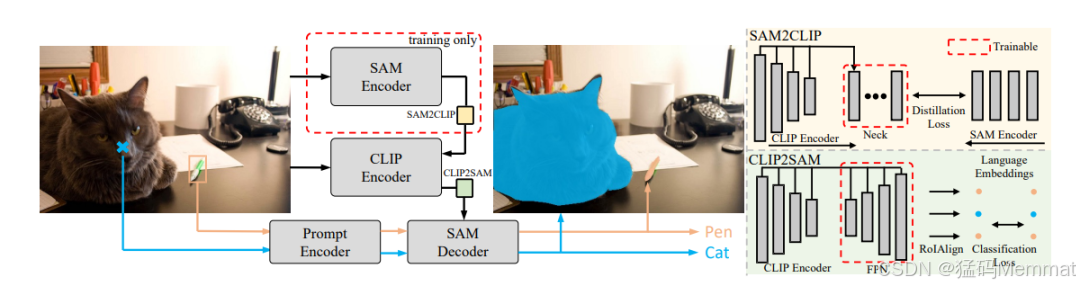
Open-Vocabulary SAM (OV-SAM): 该模型结合了Segment Anything Model (SAM) 和 CLIP模型的能力,用于同时进行交互式分割和识别。
-
知识转移模块:提出了两个独特的知识转移模块,SAM2CLIP 和 CLIP2SAM。SAM2CLIP 通过蒸馏和可学习的变换器适配器将SAM的知识转移到CLIP中,而CLIP2SAM 将CLIP的知识转移到SAM中,增强其识别能力。
-
统一框架:设计了一个统一的编码器-解码器框架,集成了CLIP编码器和SAM解码器,有效桥接了这两个不同的组件。
-
多尺度特征适配器:在SAM2CLIP中使用多尺度特征适配器,通过金字塔特征和双线性上采样对齐CLIP特征与SAM表示。
-
特征金字塔网络 (FPN):在CLIP2SAM中使用轻量级FPN来提取多尺度CLIP特征,并通过RoIAlign操作符提取区域特征。
-
分类损失:使用分类损失来优化模型,使其能够对提示进行分类。
-
交互式分割和识别:模型可以根据用户的输入(如框或点)进行交互式分割和标记。
2.2 Innovation Point
-
交互式分割和识别:首次提出交互式开放词汇量分割,允许用户通过视觉提示与模型交互。
-
知识蒸馏和适配器:通过SAM2CLIP和CLIP2SAM模块,实现了不同模型架构之间的有效知识转移。
-
计算效率:与简单结合SAM和CLIP的方法相比,OV-SAM在显著降低计算成本的同时,提高了对象识别的准确性。
-
多尺度特征融合:利用多尺度特征和FPN来改善小目标的识别能力。
-
统一框架:提出了一个统一的框架,该框架可以灵活地与不同的检测器集成,适用于封闭集和开放集环境。
-
大规模数据集训练:通过使用包括COCO、LVIS和ImageNet-22k在内的多个数据集进行训练,模型能够识别和分割超过22,000个类别。
-
实时应用潜力:由于模型的效率和灵活性,OV-SAM有潜力被应用于实时的分割和标注工具中。
3. VRP-SAM: SAM with Visual Reference Prompt
3.1 Method
-
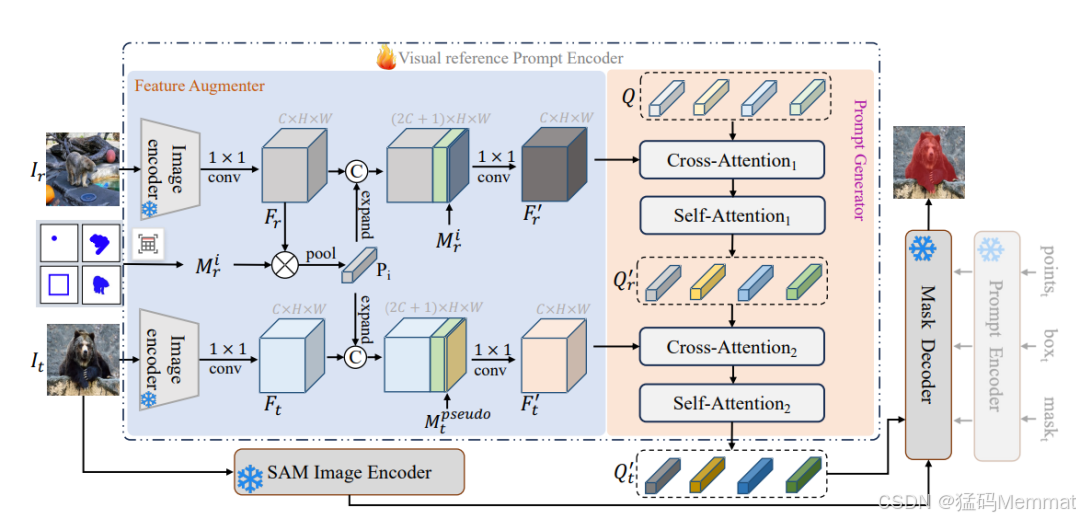
VRP-SAM模型:提出了一种新型的视觉参考提示(Visual Reference Prompt, VRP)编码器,该编码器增强了Segment Anything Model(SAM),使其能够利用标注过的参考图像作为分割的提示。
-
多格式支持:VRP编码器支持多种参考图像的注释格式,包括点、框、涂鸦和掩码。
-
元学习策略:为了增强VRP-SAM的泛化能力,VRP编码器采用了元学习策略。
-
特征增强器:通过元学习启发的特征增强器,将参考注释编码到参考和目标图像的特征中,以区分前景和背景表示。
-
提示生成器:利用一组可学习的查询(queries)与参考特征进行交互,提取目标对象的语义线索,然后与目标图像特征进行交互,生成用于掩码解码器的提示嵌入。
-
损失函数:使用二元交叉熵(BCE)损失和Dice损失来监督视觉参考提示编码器的学习,综合考虑了准确性和上下文效果。
3.2 Innovation Point
-
视觉参考提示编码器:提出了一种新的编码器,允许SAM使用视觉参考图像作为分割任务的提示,增强了用户交互性和模型的适用性。
-
多粒度注释支持:VRP-SAM能够处理不同粒度的注释,包括点、涂鸦、框和掩码,提供了更灵活的交互方式。
-
元学习在视觉分割中的应用:通过元学习策略,VRP-SAM在仅有少量可学习参数的情况下,展现出强大的泛化能力,尤其在处理新对象和跨域场景时。
-
特征和提示的增强方法:特征增强器和提示生成器的设计允许模型更好地理解和响应参考图像与目标图像之间的关系,提高了分割的准确性。
-
损失函数的创新结合:将BCE损失和Dice损失结合使用,以更全面地考虑分割任务中的准确性和上下文信息。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











