







 本文全面介绍了使用R语言进行数据处理、统计分析、图形绘制及建模的技巧,涵盖基本概念、变量类型、数据结构操作、流程控制、概率统计、假设检验、回归分析等核心内容,适合初学者和进阶用户学习。
本文全面介绍了使用R语言进行数据处理、统计分析、图形绘制及建模的技巧,涵盖基本概念、变量类型、数据结构操作、流程控制、概率统计、假设检验、回归分析等核心内容,适合初学者和进阶用户学习。
This is a final review of Introduction of Data Analysis with R.
T
h
i
s
i
s
t
h
e
w
a
y
!
!
!
^{^{This~is~the~way!!!}}
This is the way!!!
Basic notation
| command | explanation |
|---|---|
| Inf | infinity, e.g. 1/0=Inf |
| NaN | not a number, e.g. 0/0=NaN |
| NULL | empty |
| basic command | explanation |
rm(list=ls()), rm(a) | remove all objects, or a single object in workspace |
class() #creat type, mode(a) #storing type > typeof( ) #for single value | show the variable type, e.g. c<-factor( data.frame(1,2,3))class=“factor”; typeof=“integer”; mode=“numeric” |
length(a) | show the length of the character |
%%, %/%, %*%, %in%, !, t() | modulus, integer divide, matrix multiply, is a in b?, not, transpose |
options(digits=x) | control number of displayed digits |
source('xx.r', echo=T) | load History file, echo=T show command and output/ echo=F only show output |
Sys.setlocale("LC_ALL","English") | set system language |
setwd('xx'), dir() | set path, show files in current path |
print(xxx), cat(numeric, character...,'hello world \n') | show variable value |
set.seed() |
Variable
Numeric
| Important type | generation command | ralated functions |
|---|---|---|
| integer/ complex/ double | b<-1,a<-c(1,2,3) | mode(a), length(a), a<2 (generate a sequence of logic vector), as.numeric() (where char converted into NA), ceiling, floor, trunc (ignore decimal), round(x, digits=#) (round(3.5)=4, round(2.5)=2) |
| sequence | x1:x_n, c(x1,..,xn), seq(x1,xn,step) | x<-c(1,2,3,4) (x[4] is 4, x[-4] is 1,2,3), cumsum, cumprod (cumulative product), range, rep (a repeating sequence of number) |
| random sample | sample(c(..),size=, replace=T/F, prob=c(...)) | used with set.seed() |
| matrix (every entry should be of same type) | matrix(sequence, nrow=, ncol=, byrow=T/F) | dim(), nrow(), ncol(), m[row,col](indexing), rbind()(row bind), cbind(), x%*%x: inter product, x%o%x: outer product, diag(seq): create diagonal matrix or retrieve diagonal entry in a matrix, solve(A,b): find solution, solve(A): find inverse |
List
just list
every entry of a list can be anything: w<-list(a,b,c)
| related functions | explanation |
|---|---|
names(w) or names(w)<-c('x1,'x2,'x3') | show name of w’s index, or give w entry name |
w[[1]] or w$x1 | indexing |
unlist() | |
max(x) | mx<-value, for (xxx) mx<-max(mx, value): nice comparison method |
dataframe (one mother class of list)
entry can be of different type: integer/numeric/factor: d<-data.frame(), d<-read.csv('xx.csv')
| related functions | explanation |
|---|---|
names(d) or names(d)<-c('xxx') | |
head(d, n=4L), tail(d) | display first(last) 4 lines(10 lines as default) |
d[row,col] or d$xx or d[d$xx=='xxx',] | indexing or select data |
dim(), nrow(), ncol() | basic info of dataframe |
mean(x, na.rm=T), colMeans(x, na.rm=T), rowMeans() | total mean or column mean, romove NA is false as default |
var(x, na.rm=T), sd(x, na.rm=T) | sample variance, sample sd |
median(x, na.rm=T) | |
apply(x, MARGIN=,FUN=) | margin=1 by row, 2 by col; function can be user-defined |
d[order(d$xx),] | sort by row xx, order return a sequence |
d[complete.cases(d),] or na.omit(d) | select non-NA complete cases, not work on factor row/col |
merge(target, origin, by='Column name') | combine data with unique key in by='' |
by(just data part in dataset, classification standard in dataset, function) | apply function on data using classification, and generate a summary table |
| time series data | |
date<-as.Date(d$Date,"$d/$m/$Y") | change Date in dataframe d to date object in special fromat |
wkday<-weekdays(date) or wkday<- ordered(weekdays(date), c( "Monday", "Tuesday", "Wednesday", "Thursday", "Friday")) | find the corresponding weekday, the later code is ordered, instead of order |
unique(wkday) | display the unique levels in wkday |
ted<-as.ts(d$ClosePrice) | change ClosePrice in d to time series data |
lag(ted) | shift the time series 1 unit to the left and return the next value of the time series. |
by(ted, wkday, mean) | just a summary |
| write file | |
write.csv(d, file='xxx.scv', row.names=F | row.names=F suppress write number index in the first column |
Others
| variable type | generation command | related functions |
|---|---|---|
| logical | TRUE FALSE | & | (vec and/or), && || (control and/or, len=1) |
| charcater | z <- c('a','b',"c") | combine above types: c(num,logic)->num,c(num,char)->char |
| factor |
Graph
| related functions | explanation |
|---|---|
par(mfrow=c(row, col)) | define row × \times ×col multiple graph, fill-in by row; need to be reset next time |
par(mar=c(x1,x2,x3,x4)) | define marginal width of graph, bottom=x1, left=x2, top=x3, right=x4 |
plot(x,y,main='title', type='',xlab='',ylab'', ylim=c(y1,y2)), plot(x, y, pch=21, bg=c('red', 'blue')[binary]) | type: “p” for points, “l” for lines, “b” for both, “c” for the lines part alone of “b”, “o” for both ‘overplotted’, “h” for ‘histogram’ like (or ‘high-density’) vertical lines, “s” for stair steps, “S” for other steps, see ‘Details’ below, “n” for no plotting.//pchrepresent dot type, bgmeans use red for binary=1 and blue for binary=2 |
plot(d$"classification standard column"~d$"data column"), plot(d) | in plot(d), d is a dataframe, R will plot it by applying plot(d$"classification standard column"~d$"data column" multiple times |
abline(a=, b=, h=, v=) | a is intercept, b is slope, h is horizontal line, v is vertical line |
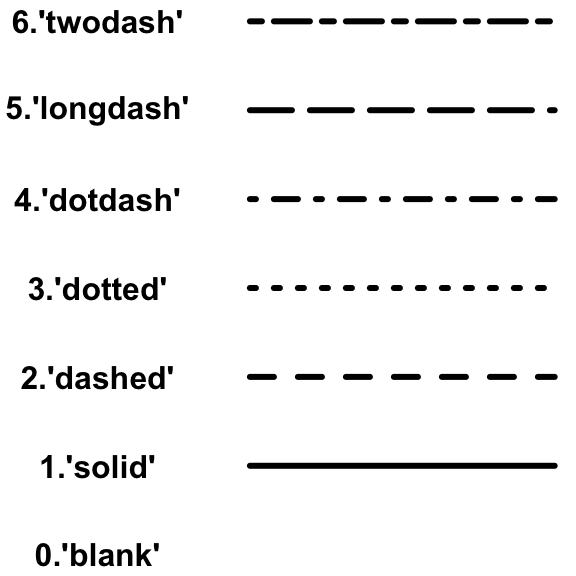
lines(c(x0, x1), c(y0, y1)), lines(x_seq, y_seq), lty=) | draw line from
(
x
0
,
y
0
)
(x_0,y_0)
(x0,y0) to
(
x
1
,
y
1
)
(x_1,y_1)
(x1,y1), or just a line through multiple points. lty: line style |
curve(y, x_start, x_end) | draw curve
⇔
\Leftrightarrow
⇔ plot(x,y, type='l') |
barplot(a table variable, beside=T, horiz=F, legend.text=c('xx'), main='xx', args.legend=list(horiz=T, bty='n', cex=0.6), ylim=c(0.2)) | log-transformation is frequently used. If beside=F, stack bar will be used. horiz=T will transpose the barplot |
| boxplot() | |
hist(x, freq=F, main='...') | freq=F produce histogram with density instead of frequency |
qqnorm(x, main='..'), qqline(x) | QQ-plot |
Function
Create
name <- function(x,y,..., OR no input) {
...a bunch of cumputation...
output
}
name <- function(...){
arg <- list(...)
...}
or define own operator:
"%+-%" <- function(miu,criticalRegion){c(miu-criticalRegion,miu+criticalRegion)}
input: if a variable has no input value, it will be automatically assigned NA, so we can use if to test. if input is ..., then numbers of input is undefined.
output can be a single variable (not like in python, we have to write return output) or c(x1=var1, x2=var2,...) or outp<-list(var); names(outp)<-c('x') or list(x1=var1, x2=var2,...) as multiple output in one list.
Modify
fix(name) can modify function
⇔
\Leftrightarrow
⇔ edit(file='name') & source(‘name’) to make effect
Speed test
proc.time(): show current time
Flow control
for loop
for (i in 1:len) {
a[i] <- xxx
}
while loop
i <- 1
while (i <= Len){
a[i] <- xxx
i <- I+1
}
repeat
repeat {
if (i>Len) break
a[i] <- xxx
i<- I+1
}
if
if (condition){
} else if (condition){
} else if (condition){
}
or
ifelse(condition, expression 1 given T, expression 2 given F)
ifelse(condition, ifelse(condition, ...), ifelse(condition, ...))
switch
good for classification into several interval
swith(expression, 'expr I'=one type of computation, 'expr II'=another, ...)
next
terminates current loop and move to next
return(expression)
terminates current loop and return expression( or func name in recursion)
stop(message)
terminates current loop and give a warning message
readline()
get user’s input as a char.
Probability
simulation: set.seed()
⇒
\Rightarrow
⇒ sample()
distribution: d, p, q, r+distribution_name(parameters), show density, cdf, quantiles, random number of certain distribution. E.g., dnorm(0,0,1), rnorm(#numbers,0,1)
| code | Distribution | code | Distribution | code | Distribution |
|---|---|---|---|---|---|
| beta(x, α \alpha α, β \beta β) | beta | binom(x, size, prob) | binomial | cauchy(x, location, scale) | Cauchy |
| chisq(x, df) | chi-squared | exp(x, rate) | exponential | f(x, df1, df2) | F |
| gamma(x, shape, sclae) | gamma | geom(x, prob) | geometric | hyper(x, m, n, k) | hypergeometric |
| lnorm(x, meanlog, sdlog) | log-normal | logis(x, location, scale) | logistic/ multinomial | nbinom(x, size, prob) | negative binomial |
| norm(x, mean, sd) | normal | pois(x, λ \lambda λ) | Poisson | t(x, df) | Student’s t |
| unif(x, min, max) | uniform | weibull | Weibull | wilcox(x, m, n) | Wilcoxon |
1-pXXX(...): find
P
(
X
>
x
)
P(X>x)
P(X>x)
Statistics
Hypothesis testing
one sample t test: t.test(x, mu=#, alt='less'/'greater'/two.sided'). two.sided is default.
two sample t test: t.test(x, y, alt='', var.eq=F/T, paired=F/T). var.eq=T is two sample t test, F is Welch’s t test(default). paired=T is paired t test, F is default.
Construct testing table
one-way table
cut(): slice x sequence into several part and specify each part with labels
result <- cut(x_seq, breaks=c(n1,n2,...), lables=c('...', '...',...))
table(result)
table(d$Name): summary of a factor/character column
two-way table
table(d$Name, result): Cartesian product of two one-way tables
prob.table(table(d$Name, result), margin=): create frequency table. margin=1 means
P
(
r
o
w
)
=
1
P(row)=1
P(row)=1 (referred to row dimension), 2 means
P
(
c
o
l
u
m
n
)
=
1
P(column)=1
P(column)=1. Probability table can also be created using apply(), rowMeans(), colMeans().
Testing table
chi-square goodness of fit test: chisq.test(x, p=): p=sequence is the assumed distribution.
contingenty table on independence: chisq.test(x,y): y is considered when x is a factor
Regression
Simple linear regression
reg1 <- lm(y~x); summary(reg1)
plot(x,y);abline(reg1) #use reg1$coef
lm is linear regression function. In output, y-reg1$fit=reg1$resid. And multiple R-squared measures is cor(x,y,use='complete').
Check 4 assumptions of linear regression model and ways to check data: linearity(residual vs fitted value, residual vs index), normality(QQ-plot), independence(residual[i] vs residual[i-1]), constant variance(residual vs fitted value, residual vs index).
# produce 4 residual plots
# input residual vector and fitted values
#
residplot<-function(resid,fit) {
par(mfrow=c(2,2)) # define 2x2 multiframe grahpic
n<-length(resid) # get no of points
plot(fit,resid); abline(h=0) # plot e(i) vs fit(i), add x-axis to plot
plot(1:n,resid); abline(h=0) # plot e(i) vs i, add x-axis to plot
plot(resid[1:(n-1)],resid[2:n]); abline(h=0) # plot e(i) vs e(i-1), add x-axis to plot
qqnorm(resid); qqline(resid) # QQ-normal plot of e(i)
par(mfrow=c(1,1)) # reset multiframe graphic
}
If residual converges when n becomes larger, the randomness is false, then it’s not a linear form.
Then
H
0
:
α
=
0
H_0: \alpha=0
H0:α=0,
H
0
:
β
=
0
H_0:\beta=0
H0:β=0 testing on
y
i
=
α
+
β
×
x
i
+
ϵ
i
y_i=\alpha+\beta \times x_i+\epsilon_i
yi=α+β×xi+ϵi, where
ϵ
∼
N
(
0
,
σ
2
)
\epsilon \sim N(0, \sigma^2)
ϵ∼N(0,σ2):
We have test statistics: ,
T
=
a
^
σ
^
×
(
1
n
+
x
ˉ
2
S
x
x
)
T=\frac{\hat{a}}{\hat{\sigma} \times \sqrt(\frac{1}{n}+\frac{\bar{x}^2}{S_{xx}})}
T=σ^×(n1+Sxxxˉ2)a^,
T
=
b
^
σ
^
S
x
x
T=\frac{\hat{b}}{\frac{\hat{\sigma}}{\sqrt{S_{xx}}}}
T=Sxxσ^b^, where
S
x
x
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
S_{xx}=\sum_{i=1}^{n}(x_i-\bar{x})
Sxx=∑i=1n(xi−xˉ)
Multiple linear regression
For
[
y
1
.
.
.
y
n
]
n
×
1
\begin{bmatrix} y_1\\.\\.\\.\\y_n \end{bmatrix}_{n\times 1}
⎣⎢⎢⎢⎢⎡y1...yn⎦⎥⎥⎥⎥⎤n×1
=
=
=
[
1
x
11
.
.
.
x
1
p
.
.
.
.
.
.
.
.
.
1
x
n
1
.
.
.
x
n
p
]
n
×
(
p
+
1
)
\begin{bmatrix} 1 & x_{11} & ... & x_{1p}\\. & . & & . \\. & . & & . \\. & . & & . \\1 & x_{n1} & ... & x_{np} \end{bmatrix}_{n\times (p+1)}
⎣⎢⎢⎢⎢⎡1...1x11...xn1......x1p...xnp⎦⎥⎥⎥⎥⎤n×(p+1)
×
\times
×
[
β
0
β
1
.
.
β
p
]
(
p
+
1
)
×
1
\begin{bmatrix} \beta_0\\\beta_1\\.\\.\\\beta_p \end{bmatrix}_{(p+1)\times 1}
⎣⎢⎢⎢⎢⎡β0β1..βp⎦⎥⎥⎥⎥⎤(p+1)×1
+
+
+
[
ϵ
1
.
.
.
ϵ
n
]
n
×
1
\begin{bmatrix} \epsilon_1\\ . \\. \\. \\ \epsilon_{n} \end{bmatrix}_{n\times 1}
⎣⎢⎢⎢⎢⎡ϵ1...ϵn⎦⎥⎥⎥⎥⎤n×1, where
ϵ
∼
N
(
0
,
σ
2
)
\epsilon\sim N(0, \sigma^2)
ϵ∼N(0,σ2):
We want to find Least Square Estimates of
β
\beta
β so that Sum of Squared Error
=
∑
i
=
1
n
ϵ
2
=
∑
i
=
1
n
(
y
−
X
×
β
)
2
=\sum_{i=1}^{n}{\epsilon^2}=\sum_{i=1}^{n}(y-X \times\beta)^2
=∑i=1nϵ2=∑i=1n(y−X×β)2 is minimized.
By minimizing SSE=
ϵ
′
ϵ
\epsilon'\epsilon
ϵ′ϵ, we can find
β
^
=
(
X
′
X
)
−
1
X
′
Y
\hat{\beta}=(X'X)^{-1}X'Y
β^=(X′X)−1X′Y with fitted value
y
^
=
X
b
\hat{y}=Xb
y^=Xb and
σ
^
2
=
(
y
−
X
b
)
′
(
y
−
X
b
)
n
−
p
−
1
\hat{\sigma}^2=\frac{(y-Xb)'(y-Xb)}{n-p-1}
σ^2=n−p−1(y−Xb)′(y−Xb)
Code: reg<- lm(y~x1+x2+x3+..., data=d), x1,x2,… are column names in d.
Choose model: step(reg), then insignificant
β
i
\beta_i
βi will be dropped.
Logistic regression
Y
Y
Y is binary variable, then
π
i
=
P
(
Y
i
=
1
∣
x
i
)
\pi_i=P(Y_i=1|x_i)
πi=P(Yi=1∣xi) is probability of success. Then logistic model is:
l
n
[
π
i
1
−
π
i
]
=
β
0
+
β
1
x
i
1
+
.
.
.
+
β
p
x
i
p
ln[\frac{\pi_i}{1-\pi_i}]=\beta_0+\beta_1 x_{i1}+...+\beta_{p}x_{ip}
ln[1−πiπi]=β0+β1xi1+...+βpxip. Assume LHS is linear on
x
i
x_i
xi, then
π
i
=
e
x
i
′
β
1
+
e
x
i
′
β
=
1
1
+
e
−
x
i
′
β
∈
[
0
,
1
]
\pi_i=\frac{e^{x_{i}'\beta}}{1+e^{x_{i}'\beta}}=\frac{1}{1+e^{-x_{i}'\beta}}\in[0,1]
πi=1+exi′βexi′β=1+e−xi′β1∈[0,1](logit transformation).
The likelihood function is
L
(
β
)
=
∏
i
=
1
n
[
π
i
y
i
(
1
−
π
i
)
(
1
−
y
i
)
]
L(\beta)=\prod_{i=1}^{n}[\pi_{i}^{y_i}(1-\pi_{i})^{(1-y_i)}]
L(β)=∏i=1n[πiyi(1−πi)(1−yi)], then do log-transformation and find MLE.
Code: reg2 <- glm(y~x1+x2+...+xn, data=d, binomial), binomial is needed for logistic regression, where y is binomial variable. Also use step() to drop insignificant regressor.
prediction:
b <- reg2$coef
X <- as.matrix(cbind(1,x1,x2,...))
c <- X%*%b
ps <- exp(c)/(1+exp(c)) # or directly use ps<-reg2$fit
pred <- ifelse(ps>0.5, "A", "B")
table(pred, oringinal list of "A"&"B") #show classification table
Nonlinear curve fitting
nls(y~f(x;a1,a2,a3,...), start=c(a1=#, a2=#, ...): nonlinear least square with parameters
a
1
,
a
2
,
a
3
,
.
.
.
a_1, a_2, a_3,...
a1,a2,a3,... and start value of all parameters are required to be used in searching the model.
nlsout <- summary(nls): to get coefficients, use nlsout$coefficients, or use y-nlsout$res to get fitted value.
If unclear form of y, then try log-transformation: log(y) or log(x). lm(log(y)~x may fit a good nonlinear form.


















 5329
5329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}