





向量模型的核心功能是测量语义相似度,但这个测量结果很容易受到多种干扰因素的影响。在本文中,我们将着眼于文本向量模型中一个普遍存在的偏差来源:输入内容的长度。
通常情况下,当与其它文本向量进行比较时,长文本向量往往得分更高,哪怕它们的实际内容没那么相似。当然,内容真正相似的文本,得分还是会比不相关的文本高。但是,长文本本身就会带来一种偏差:仅仅因为文本更长,它们的向量看起来(平均而言)就好像更相似。
这会在实际应用中带来问题。单靠向量模型本身,其实很难准确评估内容的“相关性”。在基于向量的搜索里,虽然总能找到一个“最佳匹配”的结果,但长度偏差的存在,导致我们无法单凭相似度分数,就判断这个“最佳匹配”或者其他得分较低的结果,内容是否真的相关。
比如,你不能简单地认为“余弦相似度高于 0.75 就代表内容相关”,因为一个完全不相关的长文档,可能仅仅因为够长,相似度得分就能达到这个水平。
💡 要点: 比较向量只能反映相对相似度,无法直接判断相关性。
下面,我们会用一些简单的例子演示这个问题,并说明为什么不能把文本 embedding 之间的余弦相似度,当作评估相关性的通用标准。
可视化长度偏差
为了具体展示长度偏差的影响,我们将使用 Jina AI 最新的文本向量模型 jina-embeddings-v3,并指定采用 text-matching 选项。我们还会用到一个信息检索领域广泛使用的数据集:CISI 数据集中的文本文档,你可以从 Kaggle 下载这个数据集。
数据集链接:https://www.kaggle.com/datasets/dmaso01dsta/cisi-a-dataset-for-information-retrieval
这个数据集经常被用来训练信息检索系统,所以里面既有查询 (queries),也有用来匹配的文档 (documents)。本文只用到其中的文档,它们都在 CISI.ALL 这个文件里。你可以用下面的命令下载它:
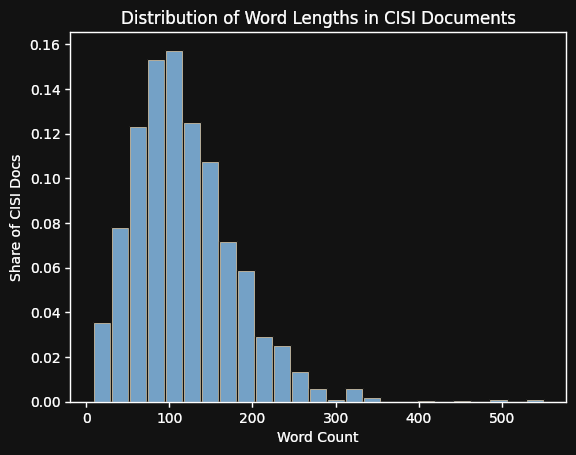
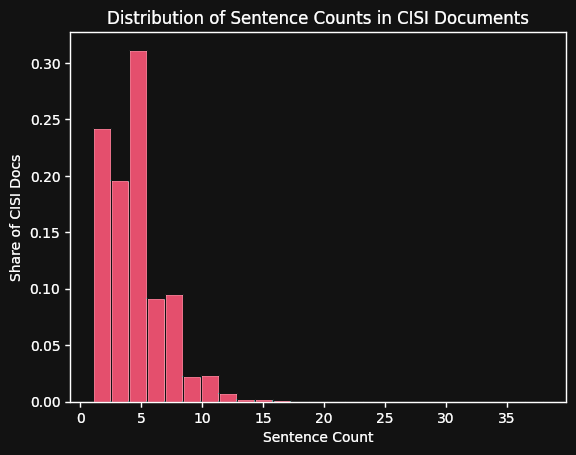
wget https://raw.githubusercontent.com/GianRomani/CISI-project-MLOps/refs/heads/main/CISI.ALLCISI 包含 1,460 个文档。下面的表格和直方图总结了文本大小及其分布的基本统计数据:
| 按词数统计 |
按句子数统计 |
|
|---|---|---|
| 平均文档长度 |
119.2 |
4.34 |
| 标准差 |
63.3 |
2.7 |
| 最大长度 |
550 |
38 |
| 最小长度 |
8 |
1 |
接下来,我们用 Python 读取这些文档,并生成它们的向量。下面的代码假定 CISI.ALL 文件位于当前目录下:
with open("CISI.ALL", "r", encoding="utf-8") as inp:
cisi_raw = inp.readlines()
docs = []
current_doc = ""
in_text = False
for line in cisi_raw:
if line.startswith("."):
in_text = False
if current_doc:
docs.append(current_doc.strip())
current_doc = " 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









