




一、介绍:
docker 完全隔离需要在内核3.8 以上,所以Centos6 不行
所有docker解决不了的事情,k8s来解决。
k8s思维引导图vsdx-Linux文档类资源-优快云下载
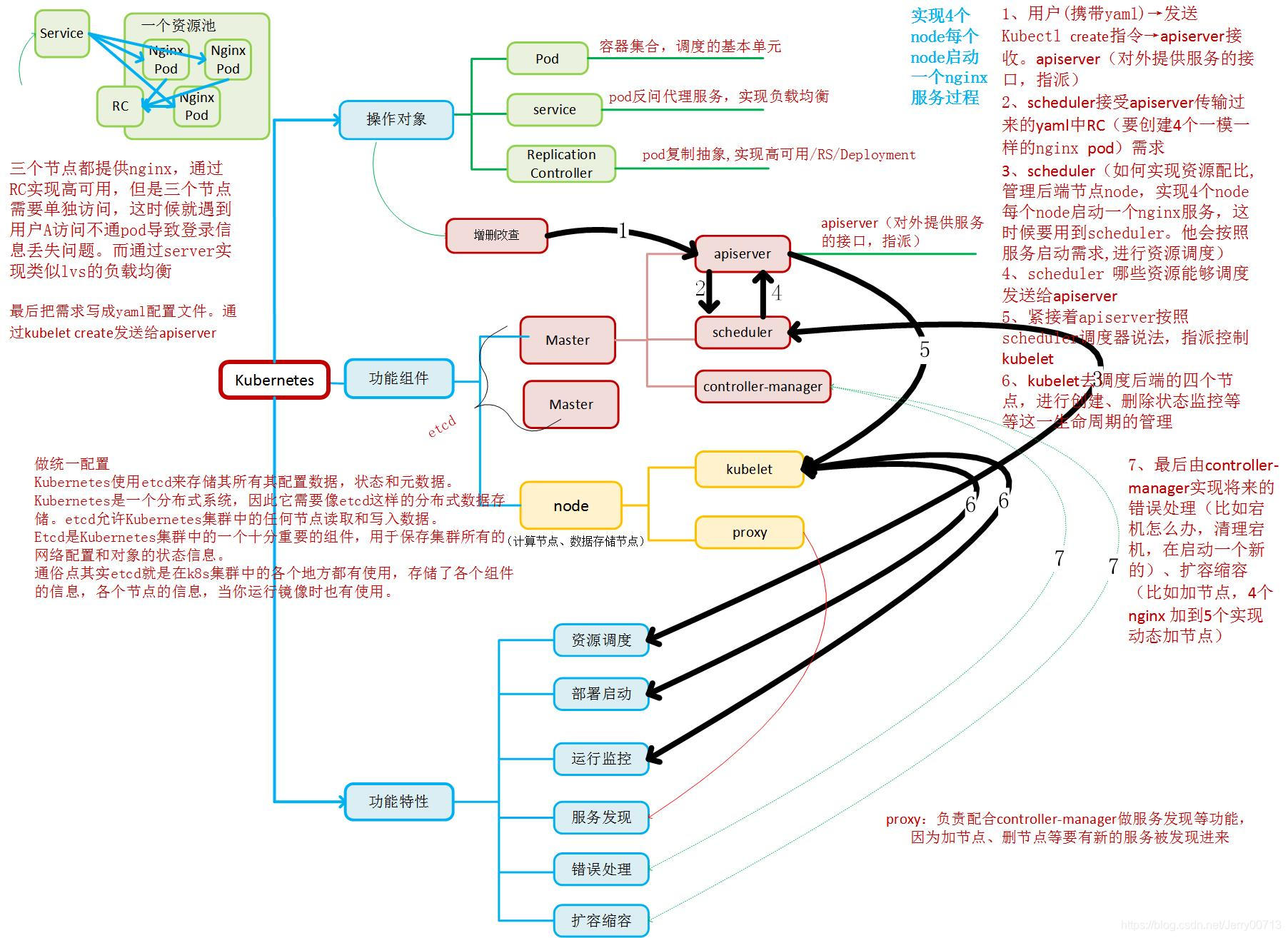
1、1Kubernetes优势
● 自动装箱,水平扩展,自我修复
● 服务发现和负载均衡
● 自动发布(默认滚动发布模式)和回滚
● 集中化配置管理和密钥管理
● 存储编排
● 任务批处理运行
1、2Kubernetes快速入门概念
※ 四组基本概念
➢ Pod/Pod控制器
➢ Name/Namespace
➢ Label/Label选择器
➢ Service/Ingress
➢ Pod
● Pod是K8S里能够被运行的最小的逻辑单元(原子单元),不是容器
● 1个Pod里面可以运行多个容器,容器与容器之间它们共享UTS+NET+IPC名称空间 ,
只隔离PID+MOUNT+USER 。容器有6个隔离空间(UTS+NET+IPC+PID+MOUNT+USER)
● 可以把Pod理解成豌豆荚,而同一Pod内的每个容器理解成是一颗颗豌豆
● 一个Pod里运行多个容器,又叫:边车( SideCar)模式➢ Pod控制器
● Pod控制器是Pod启动的一种模板,用来保证在K8S里启动的Pod 应始终按照人们的预期运行(副本数、生命周期、健康状态检查... )
Pod可以在k8s里面单独启动,不需要任何Pod控制器管控,启动Pod
● K8S内提供了众多的Pod控制器,常用的有以下几种:
● Deployment 部署
● DaemonSet 要求我们每个运算单位都启动一份
● ReplicaSet ReplicaSet 不直接对外提供服务,Deployment 管理ReplicaSet,ReplicaSet管理Pod,进而提供服务
● StatefulSet 管理有状态应用的 Pod控制器
● Job 管理任务
● Cronjob 管理定时任务
➢ Name
● 由于K8S内部,使用“资源”来定义每一种逻辑概念(功能),故每种“资源”, 都应该有自己的"名称”,每一种功能我们都叫做资源,每一种功能的实现都叫做资源的实例化
● 资源一共有5个维度的信息,每一种都有,“资源”有api版本( apiVersion )、类别( kind )、元数据( metadata )、定义清单( spec)、状态( status )(集群自己生成的,不需要人工定义)等配置信息
● "名称”通常定义在‘ '资源”的“元数据”信息里,
➢ Namespace
● 随着项目增多、人员增加、集群规模的扩大,需要一种能够隔离K8S内部各种“资源”的方法,这就是名称空间,通过名称空间各种资源进行分组
● 名称空间可以理解为K8S内部的虚拟集群组
● 不同名称空间内的“资源”, 名称可以相同,相同名称空间内的同种"资源”,"名称” 不能相同,重名不重名
● 合理的使用K8S的名称空间,使得集群管理员能够更好的对交付到K8S里的服务进行分类管理和浏览
● K8S里默认存在的名称空间有: default、kube-system、 kube-public
● 查询K8S里特定“资源”要带上相应的名称空间
➢ Label
● 标签是k8s特色的管理方式,便于分类管理资源对象。
● 一个标签可以对应多个资源,一个资源也可以有多个标签,它们是多对多的关系。
● 一个资源拥有多个标签,可以实现不同维度的管理。
● 标签的组成: key=value 键值对,有效的标签值必须不超过63个字符,并且必须为空或以字母数字字符([a-z0-9A-Z]),带破折号(-)、下划线(Uu)、点(.),和字母数字
● 与标签类似的,还有一-种“注解”( annotations ) 标 , 注解没有要求➢ Label选择器
● 给资源打上标签后,可以使用标签选择器过滤指定的标签
● 标签选择器目前有两个:基于等值关系(等于、不等于)和基于集合关系(属于、不属于、存在)
● 许多资源支持内嵌标签选择器字段
● matchl abels
● matchExpressions
➢ Service 集群网络
● 在K8S的世界里,虽然每个Pod都会被分配一个单独的P地址 ,但这个IP地址会随着Pod的销毁而消失。 Pod有生命周期的,不定时的启动,扩容,销毁,迁移。流量如何调度,Service 起到,无论你这组
pod怎么掉度、销毁等等,对外提供服务的接口统一,Service会有一个相对独立的接口,
● Service (服务)就是用来解决这个问题的核心概念
● 一个Service可以看作一 -组提供相同服务的Pod的对外访问接口
● Service作用于哪些Pod是通过标签选择器来定义 的
➢ Ingress
● Ingress是K8S集群里1工作在OSI网络参考模型下,第7层的应用,对外暴露的接口
● Service只能进行4流量调度, 表现形式是ip+ port
● Ingress则可以调度不同业务域、不同URL访问路径的业务流量
1、3核心组件
● 配置存储中心→etcd服务 状态、请求、集群资源情况等,也可以理解位Mysql
● 主控( master )节点
● kube-apiserver服务 集群的大脑,所有组件通过kube-apiserver 通信枢纽功能
● aplserver:
● 提供了集群管理的REST API接口( 包括鉴权、数据校验及集群状态变更)
● 负责其他模块之间的数据交互,承担通信枢纽功能
● 是资源配额控制的入口
● 提供完备的集群安全机制
● kube-controller-manager服务
● controller-manager : 管理控制器的控制器 需要高可用
● 由一系列控制器组成,通过piserver监控整个集群的状态,并确保集群处于预期的工作状态
● Node Controller 节点控制器
● Deployment Controller Pod控制器
● Service Controller server控制器
● Volume Controller 卷控制器
● Endpoint Controller 接入点控制器
● Garbage Controller 垃圾回收控制器
● Namespace Controller 名称空间资源配额
● Job Controller 任务资源配额
● Resource quta Controller 资源配额控制器
● kube-scheduler服务
● scheduler:调度器
● 主要功能是接收调度pod到适合的运算节点上 有一个请求通过apiserver,apiserver告诉controller-manager 需要启动那些Pod, controller-manager 找到scheduler,他会按照要求模板到那个节点创建一系列Pod
● 预算策略( predict ) 最适合运行Pod点,拉取
● 优选策略( priorities )
● 运算( node )节点
● kube-kubelet服务
● kubelet
● 简单地说, kubelet的主要功能就是定时从某个地方获取节点上pod的期望状态(运行什么容器、运行的副本数量网络或者存储如何配置等等) , 并调用对应的容器平台接口达到这个状态● 定时汇报当前节点的状态给apiserver,以供调度的时候使用
● 镜像和容器的清理工作,保证节点上镜像不会占满磁盘空间,退出的容器不会占用太多资源
● Kube-proxy服务
● kube- proxy
● 是K8S在每个节点上运行网络代理, service资源的载体
● 建立了pod网络和集群网络的关系( clusterip >podip ) 把clusterip 跟podip关联起来
● 常用三种流量调度模式
● Userspace (废弃) 早期1.2 版本,Userspace调度节点网络、Pod网络、集群网络要用到大量的内核态跟用户态之间的转换,消耗资源大
● Iptables (濒临废弃) 99%目前主流方法,nat表,nat映射,太多没办法维护
● Ipvs(推荐) lvs开源,加入Linux 内核,
● 负责建立和删除包括更新调度规则、通知apiserver自 己的更新,或者从apiserver哪里获取其他kube-proxy的调度规则变化来更新自己的一个集群中有若干节点,都起Kube-proxy,如何同步,通过apiserver找etcd● CLI客户端 命令行工具
● kubectl● 核心附件
● CNI网络插件> flannel/calico
● 服务发现用插件> coredns
● 服务暴露用插件> traefik
● GUI管理插件> Dashboard
核心组件图,三条网络,节点网洛(宿主机网洛)

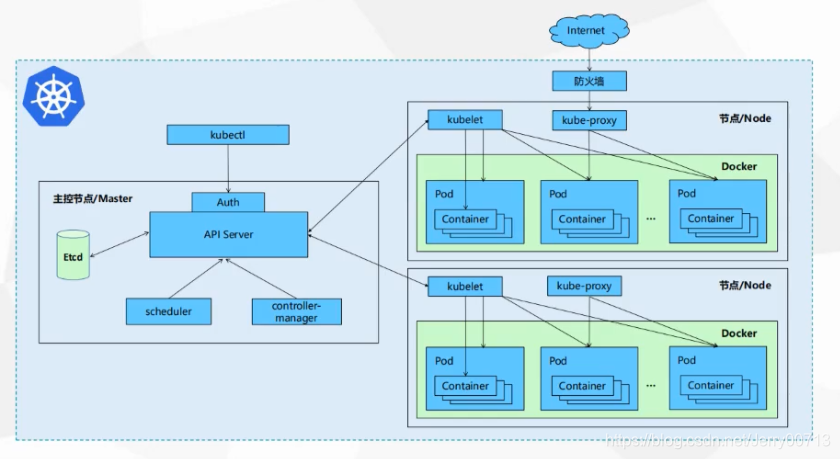
K8S安装部署方式:
二、准备工作:
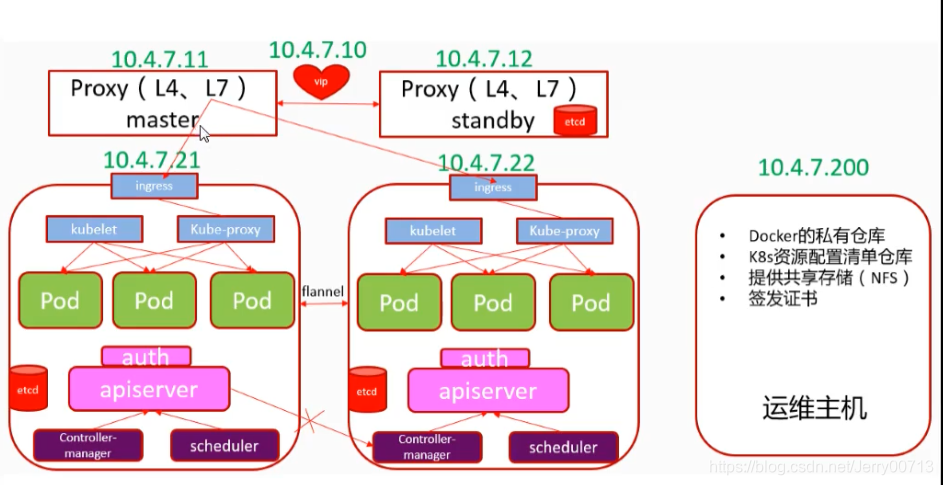
1、配置Linux:
1.1、修改主机名字,对所有的机器
Centos7 修改hostname(永久生效)
# hostnamectl set-hostname ***
重新启动shell 或者 reboot 显示规划:
hdss7-11 A 10.4.7.11
hdss7-12 A 10.4.7.12
hdss7-21 A 10.4.7.21
hdss7-22 A 10.4.7.22
hdss7-200 A 10.4.7.20010.4.7.11:[root@localhost ~]# hostnamectl set-hostname hdss7-11 10.4.7.12:[root@localhost ~]# hostnamectl set-hostname hdss7-12 10.4.7.21:[root@localhost ~]# hostnamectl set-hostname hdss7-21 10.4.7.22:[root@localhost ~]# hostnamectl set-hostname hdss7-22 10.4.7.200:[root@localhost ~]# hostnamectl set-hostname hdss7-200
1.2、关闭防火墙,selinux,对所有的机器
关闭防火墙:systemctl stop firewalld.service
systemctl disable firewalld.service
关闭selinux:
getenforce ## 返回Enforcing,selinux开启状态。返回Permissive,selinux关闭状态
setenforce 0 ## 设置SELinux 临时成为permissive关闭模式,重启失效
setenforce 1 ## 设置SELinux 临时成为Enforcing开启模式,重启失效
永久关闭selinux:sed -i -r 's#(^SELIN.*=)enforcing#\1disable#g' /etc/selinux/config关闭防火墙、selinux写成一句话:systemctl stop firewalld.service;systemctl disable firewalld.service;sed -i -r 's#(^SELIN.*=)enforcing#\1disable#g' /etc/selinux/config;setenforce 0
1.3、安装基础组件
centos7更新yum源:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo yum clean all yum makecache更新系统 yum -y update
yum install wget net-tools telnet tree nmap sysstat lrzsz dos2unisdx bind-utils -y
2、搭建dns -bind9
在10.4.7.11 上搭建:
[root@hdss7-11 ~]# yum install bind -y
[root@hdss7-11 ~]# vi /etc/named.conf # 修改options下的内容,注释去掉options { listen-on port 53 { 10.4.7.11; }; // 默认监听53端口,IP改成自己的本机的IP,要让内网的所有机器能够访问我的bind进行 dns解析,127.0.0.1只能自己用,注意bind语法严格,所以格式要写对 listen-on-v6 port 53 { ::1; }; //去掉这行,不需要IPV6 directory "/var/named"; dump-file "/var/named/data/cache_dump.db"; statistics-file "/var/named/data/named_stats.txt"; memstatistics-file "/var/named/data/named_mem_stats.txt"; recursing-file "/var/named/data/named.recursing"; secroots-file "/var/named/data/named.secroots"; allow-query { any; }; // 改成any,让任何人都可以访问你 forwarders { 10.4.7.254; }; // 增加一条,如果dns解析不了,王上一级dns,也就是网关 recursion yes; //递归模式 dnssec-enable no; //是否支持DNSSEC开关,默认为yes。 dnssec-validation no; //是否进行DNSSEC确认开关,默认为no。 dnssec-enable配置项用来设置是否启用DNSSEC支持,DNS安全扩展(DNSSEC)提供了验证DNS数据有效性的系统。[root@localhost ~]# named-checkconf # 检查是否有问题。无任何提示代表无问题
[root@hdss7-11 ~]# vi /etc/named.rfc1912.zones # 配置区域文件,在最末尾增加两条,注释去掉
[root@hdss7-11 ~]# vi /etc/named.rfc1912.zones # 主机域,在内部自己使用,比如物理机(10.4.7.11 ping 10.4.7.11) # 可以使用ping hdss7-12.host.com,所以host是可以变化的 zone "host.com" IN { type master; file "host.com.zone"; allow-update { 10.4.7.11; }; }; # 业务域,把流量引入到k8s中,比如访问jenkins,页面地址输入jenkins.od.com # 所以od是可以变化的,按照公司要求 zone "od.com" IN { type master; file "od.com.zone"; allow-update { 10.4.7.11; }; };
编写主机域的配置文件,需要域名解析的主机都写入才可通过域名访问:
[root@hdss7-11 ~]# vi /var/named/host.com.zone # 尽量用tab补全$ORIGIN host.com. $TTL 600 ; 10 minutes @ IN SOA dns.host.com. dnsadmin.host.com. ( 2020010501 ; serial 10800 ; refresh (3 hours) 900 ; retry (15 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) NS dns.host.com. $TTL 60 ; 1 minute dns A 10.4.7.11 HDSS7-11 A 10.4.7.11 HDSS7-12 A 10.4.7.12 HDSS7-21 A 10.4.7.21 HDSS7-22 A 10.4.7.22 HDSS7-200 A 10.4.7.200$TTL 600 ; 10 minutes 过期时间10分钟
@ IN SOA dns.host.com. dnsadmin.host.com. (
SOA记录,区域授权文件的开始 dnsadmin.host.com 等于dnsadmin@host.com
10800 ; refresh (3 hours) SOA参数
900 ; retry (15 minutes) SOA参数
604800 ; expire (1 week) SOA参数
86400 ; minimun (1 day) SOA参数
)
NS dns.host.com. NS记录
$TTL 60 ; 1 minute
dns A 10.4.7.11 记录记录 对应的A 记录
业务域配置文件,流量经过bind,通过业务域配置文件中对应的关系,解析出对应的IP:
[root@hdss7-11 ~]# vi /var/named/od.com.zone$ORIGIN od.com. $TTL 600 ; 10 minutes @ IN SOA dns.od.com. dnsadmin.od.com. ( 2020010501 ; serial 10800 ; refresh (3 hours) 900 ; retry (15 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) NS dns.od.com. $TTL 60 ; 1 minute dns A 10.4.7.11[root@localhost ~]# named-checkconf 检查是否有问题。无任何提示代表无问题
启动named服务:
[root@ hdss7-11 ~]# systemctl start named
[root@ hdss7-11 ~]# systemctl enable named测试:
[root@hdss7-11 ~]# dig -t A hdss7-12.host.com @10.4.7.11 +short # 代表主机域无问题
10.4.7.12解释:
Dig是一个在类Unix命令行模式下查询DNS包括NS记录,A记录,MX记录等相关信息的工具。 dig命令语法:dig [-t TYPE] name [@SERVER] [+trace] -t TYPE:表示解析类型 A:查询A记录 +short:表示以短格式显示解析的内容,即只显示域名解析后的IP
对所有的机器的网卡,配置DNS为10.4.7.11:
涉及机器:(hdss7-11、hdss7-12、hdss7-21、hdss7-22、hdss7-200)cat /etc/sysconfig/network-scripts/ifcfg-ens33 |grep "DNS1" DNS1=10.4.7.11重启网卡:systemctl restart network
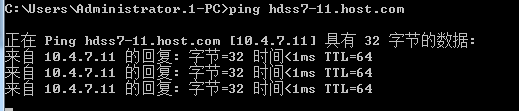
测试:ping hdss7-12.host.com 等等,如果可以说明已经生效[root@localhost ~]# ping hdss7-12.host.com PING HDSS7-12.host.com (10.4.7.12) 56(84) bytes of data. 64 bytes from 10.4.7.12 (10.4.7.12): icmp_seq=1 ttl=64 time=1.18 ms 64 bytes from 10.4.7.12 (10.4.7.12): icmp_seq=2 ttl=64 time=1.20 ms如何实现短域名ping(不带host.com)
[root@localhost ~]# ping hdss7-12
ping: hdss7-12: 未知的名称或服务方案:在resolv.conf文件中声明host.com(search host.com)
涉及机器:(hdss7-11、hdss7-12、hdss7-21、hdss7-22、hdss7-200)
vi /etc/resolv.conf# Generated by NetworkManager search host.com nameserver 10.4.7.11测试:ping hdss7-12 等等
[root@localhost ~]# ping hdss7-12
PING HDSS7-12.host.com (10.4.7.12) 56(84) bytes of data.
64 bytes from 10.4.7.12 (10.4.7.12): icmp_seq=1 ttl=64 time=1.18 ms
64 bytes from 10.4.7.12 (10.4.7.12): icmp_seq=2 ttl=64 time=1.20 ms
问题:重启网卡或者机器,search host.com就会消失,/etc/resolv.conf文件会被重新还原。是被NetworkManager修改了
错误解决方案:
将NetworkManager停止,重启后,/etc/resolv.conf文件不会被重新还原查看Network Manager状态: systemctl status NetworkManager 停止Network Manager服务: systemctl stop NetworkManager 关闭Network Manager开机启动: systemctl disable NetworkManager但是发现ping不通百度,也就是上级dns解析不了了。所以NetworkManager停止会带来一系列问题,所以无奈只能在开机后,给/etc/resolv.conf 插入search host.com
涉及机器:(hdss7-11、hdss7-12、hdss7-21、hdss7-22、hdss7-200)
[root@hdss7-11 ~]# vi /etc/rc.d/rc.local # 开机向resolv.conf 插入短域名,注意脚本提权
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# 请注意,您必须运行'chmod+x/etc/rc.d/rc.local“以确保sed -i "2isearch host.com" /etc/resolv.conf[root@hdss7-12 ~]# chmod +x /etc/rc.d/rc.local
写成一句话:sed -i '$a\sed -i "2isearch host.com" /etc/resolv.conf' /etc/rc.d/rc.local;chmod +x /etc/rc.d/rc.local
注:为什么把语句插入到/etc/rc.d/rc.local ,不插入/etc/rc.local,我使用的是Centos,默认 /etc/rc.d/rc.local是有执行权限的,而/etc/rc.local只有读的权限,而且 /etc/rc.local也不是 /etc/rc.d/rc.local的连接文件,在 /etc/rc.d/rc.local 也写到,必须运行'chmod+x /etc/rc.d/rc.local.作为Centos 7 ,/etc/rc.d/rc.local.是开机默认执行那个文件,而 /etc/rc.local只是读
本地win配置cmd访问hdss7-11等
C:\Windows\System32\drivers\etc\hosts文件配置
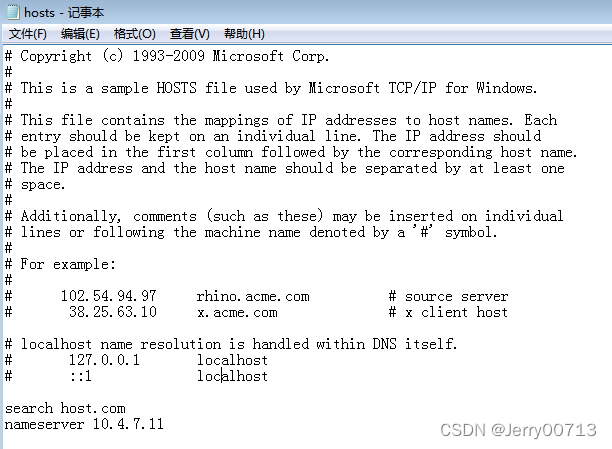
注意:如果后期做了其他服务,如dashboard.od.com,(hdss7-11、hdss7-12、hdss7-21、hdss7-22、hdss7-200、windows宿主机)有些ping dashboard.od.com能解析到,有些不能,大概率是因为hosts中,nameserver 写的不是10.4.7.11
3、K8S前置准备工作--准备签发证书环境
自签证书,k8s几乎所有组件通信都需要ssl
两种ssl组件:openssl、cfssl
这里用的是cfssl
在hdss7-200:
3.1、下载组件
[root@hdss7-200 ~]# wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/bin/cfssl
[root@hdss7-200 ~]# wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/bin/cfssl-json
[root@hdss7-200 ~]# wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/bin/cfssl-certinfo
[root@hdss7-200 ~]# chmod +x /usr/bin/cfssl*
3.2、配置自签证书
首先需要根证书也叫ca证书,他就是权威证书。
[root@hdss7-200 ~]# mkdir /opt/certs/ ; cd /opt/certs/
[root@hdss7-200 certs]# vim /opt/certs/ca-csr.json # 创建生成CA证书签名请求(csr)的JSON配置文件
{
"CN": "OldboyEdu",
"hosts": [
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "beijing",
"L": "beijing",
"O": "od",
"OU": "ops"
}
],
"ca": {
"expiry": "175200h"
}
}
# 根证书配置:
# CN 一般写域名,浏览器会校验
# names 为地区和公司信息
# expiry 为过期时间"names":
CN: Common Name .浏览器使用该字段验证网站是否合法。一般写的是域名。非常重要。浏览器使用该字段验证网站是否合法
C: Country,国家
ST:State,州,省
L: Locality ,地区,城市
O: Organization Name ,组织名称,公司名称
OU: Organization Unit Name ,组织单位名称,公司部门
3.3、签证书
cfssl gencert -initca ca-csr.json 生成证书,把证书跟私钥整合在一个,但是这个形式没有承载到文件里,需要承载文件中才能使用,所以加管道给 cfssl-json命令,让他变成 ca承载的文件
[root@hdss7-200 certs]# cfssl gencert -initca ca-csr.json | cfssl-json -bare ca
[root@hdss7-200 certs]# ll
-rw-r--r--. 1 root root 993 9月 16 20:20 ca.csr
-rw-r--r--. 1 root root 328 9月 16 20:14 ca-csr.json
-rw-------. 1 root root 1675 9月 16 20:20 ca-key.pem //根证书私钥
-rw-r--r--. 1 root root 1346 9月 16 20:20 ca.pem //根证书注:如果执行上面的语句中报(Failed to parse input: unexpected end of JSON input),需要查看/usr/bin/下的cfssl、cfssl-json、cfssl-certinfo是不是0kb
4、K8S前置准备工作--docker环境安装
需要安装docker的机器:hdss7-21 hdss7-22 hdss7-200,以hdss7-21为例
docker安装方式一:
[root@hdss7-21 ~]# wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@hdss7-21 ~]# yum install -y docker-cedocker安装方式二:
[root@hdss7-21 ~]# curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyundaemon.json解释:
# 不安全的registry中增加了harbor地址
# bip是容器IP范围,21、22、200各个机器上bip网段不一致,bip中间两段与宿主机最后两段相同,目的是方便定位问题 。比如看到172.7.21.1/24的容器,判断出是7.21的物理机的容器
[root@hdss7-21 ~]# mkdir /etc/docker/
[root@hdss7-21 ~]# vim /etc/docker/daemon.json
按照如下初级更改,会导致有后续问题,下文介绍
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["registry.access.redhat.com","quay.io","harbor.od.com"],
"registry-mirrors": ["https://registry.docker-cn.com"],
"bip": "172.7.21.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}
hdss7-21正确改法:
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["registry.access.redhat.com","quay.io","harbor.od.com","harbor.od.com:180"],
"registry-mirrors": ["https://6kx4zyno.mirror.aliyuncs.com"],
"bip": "172.7.21.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}
hdss7-22正确改法:
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["registry.access.redhat.com","quay.io","harbor.od.com","harbor.od.com:180"],
"registry-mirrors": ["https://6kx4zyno.mirror.aliyuncs.com"],
"bip": "172.7.22.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}
这里需要注意一下,"bip"在你kubectl创建容器后,容器的的IP范围是多少
如果发现容器为172.7.21.1/24,就可以知道这个是hdss7-21容器。
如果发现容器为172.7.22.1/24,就可以知道这个是hdss7-22容器。
hdss7-200正确改法:
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["registry.access.redhat.com","quay.io","harbor.od.com","harbor.od.com:180"],
"registry-mirrors": ["https://6kx4zyno.mirror.aliyuncs.com"],
"bip": "172.7.200.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}
其中 "bip": "172.7.21.1/24",一定要写,这是给容器分配IP,如果不写后期启动容器就会导致,可能跟宿主机IP冲突,甚至导致容器不能ping通宿主机网关/dns,导致容器不能上网。
[root@hdss7-21 ~]# mkdir -p /data/docker
[root@hdss7-21 ~]# systemctl start docker ; systemctl enable docker
5、 harbor安装
5.1、hdss7-200 安装harbor
# 创建目录说明:
# /opt/src : 源码、文件下载目录
# /opt/release : 各个版本软件存放位置
# /opt/apps : 各个软件当前版本的软链接
[root@hdss7-200 ~]# mkdir -p /opt/src;mkdir -p /data/harbor/logs
[root@hdss7-200 ~]# cd /opt/src
[root@hdss7-200 src]# wget https://github.com/goharbor/harbor/releases/download/v1.9.4/harbor-offline-installer-v1.9.4.tgz
[root@hdss7-200 src]# tar xf harbor-offline-installer-v1.9.4.tgz -C /opt/
[root@hdss7-200 opt]# mv harbor/ harbor-v1.9.4
[root@hdss7-200 src]# ln -s /opt/harbor-v1.9.4 /opt/harbor
[root@hdss7-200 opt]# ll |grep "harbor " # 用软连接的方式管理,为以后升级版本后,遇到未知因素回退等
lrwxrwxrwx. 1 root root 18 Mar 12 13:59 harbor -> /opt/harbor-v1.9.4
drwxr-xr-x. 2 root root 100 Mar 12 13:53 harbor-v1.9.4
[root@hdss7-200 src]#cd /opt/harbor
[root@hdss7-200 harbor]# ll
-rw-r--r--. 1 root root 642783197 12月 28 2019 harbor.v1.9.4.tar.gz
-rw-r--r--. 1 root root 5903 9月 17 22:27 harbor.yml
-rwxr-xr-x. 1 root root 5088 12月 28 2019 install.sh
-rw-r--r--. 1 root root 11347 12月 28 2019 LICENSE
-rwxr-xr-x. 1 root root 1748 12月 28 2019 prepare# 实验环境仅修改以下配置项,生产环境注意更改密码,注释去掉
[root@hdss7-200 src]# vim /opt/harbor/harbor.yml
hostname: harbor.od.com # 访问harbor的业务域名称
http:
port: 180 # 防止7-200上的nginx端口冲突
data_volume: /data/harbor
location: /data/harbor/logs
# harbor也是用docker启动的,所以依赖docker-compose进行管理启动harbor的docker
[root@hdss7-200 src]# yum install -y docker-compose
[root@hdss7-200 src]# cd /opt/harbor/
[root@hdss7-200 harbor]# systemctl start docker
[root@hdss7-200 harbor]# ./install.sh # ./install.sh会抽取harbor.v1.9.4.tar.gz,安装容器
...... ✔ ----Harbor has been installed and started successfully.---- [root@hdss7-200 harbor]# docker-compose ps Name Command State Ports -------------------------------------------------------------------------------------- harbor-core /harbor/harbor_core Up harbor-db /docker-entrypoint.sh Up 5432/tcp harbor-jobservice /harbor/harbor_jobservice ... Up harbor-log /bin/sh -c /usr/local/bin/ ... Up 127.0.0.1:1514->10514/tcp harbor-portal nginx -g daemon off; Up 8080/tcp nginx nginx -g daemon off; Up 0.0.0.0:180->8080/tcp redis redis-server /etc/redis.conf Up 6379/tcp registry /entrypoint.sh /etc/regist ... Up 5000/tcp registryctl /harbor/start.sh[root@hdss7-200 harbor]# docker-compose ps
Name Command State Ports
---------------------------------------------------------------------------------------------------
harbor-core /harbor/harbor_core Up
harbor-db /docker-entrypoint.sh Up 5432/tcp
harbor-jobservice /harbor/harbor_jobservice ... Up
harbor-log /bin/sh -c /usr/local/bin/ ... Up 127.0.0.1:1514->10514/tcp
harbor-portal nginx -g daemon off; Up 8080/tcp
nginx nginx -g daemon off; Up 0.0.0.0:180->8080/tcp,:::180->8080/tcp
redis redis-server /etc/redis.conf Up 6379/tcp
registry /entrypoint.sh /etc/regist ... Up 5000/tcp
registryctl /harbor/start.sh Up
[root@hdss7-200 harbor]# docker container ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6cecc830aa4e goharbor/nginx-photon:v1.9.4 "nginx -g 'daemon of…" 6 minutes ago Up 6 minutes (healthy) 0.0.0.0:180->8080/tcp, :::180->8080/tcp nginx
b7ee62f69f74 goharbor/harbor-jobservice:v1.9.4 "/harbor/harbor_jobs…" 6 minutes ago Up 6 minutes (healthy) harbor-jobservice
5388c96ed612 goharbor/harbor-core:v1.9.4 "/harbor/harbor_core" 6 minutes ago Up 6 minutes (healthy) harbor-core
10a233f726e5 goharbor/harbor-registryctl:v1.9.4 "/harbor/start.sh" 6 minutes ago Up 6 minutes (healthy) registryctl
7b885f98798a goharbor/harbor-portal:v1.9.4 "nginx -g 'daemon of…" 6 minutes ago Up 6 minutes (healthy) 8080/tcp harbor-portal
ae9484cf3f3f goharbor/harbor-db:v1.9.4 "/docker-entrypoint.…" 6 minutes ago Up 6 minutes (healthy) 5432/tcp harbor-db
dca37e1eafb6 goharbor/redis-photon:v1.9.4 "redis-server /etc/r…" 6 minutes ago Up 6 minutes (healthy) 6379/tcp redis
82da782f4beb goharbor/registry-photon:v2.7.1-patch-2819-2553-v1.9.4 "/entrypoint.sh /etc…" 6 minutes ago Up 6 minutes (healthy) 5000/tcp registry
95fa6f05fcb1 goharbor/harbor-log:v1.9.4 "/bin/sh -c /usr/loc…" 6 minutes ago Up 6 minutes (healthy) 127.0.0.1:1514->10514/tcp harbor-log # 遇到的问题:由于selinux开启
- 设置harbor开机启动
[root@hdss7-200 harbor]# vim /etc/rc.d/rc.local # 增加以下内容
# start harbor
cd /opt/harbor
/usr/bin/docker-compose stop
/usr/bin/docker-compose start
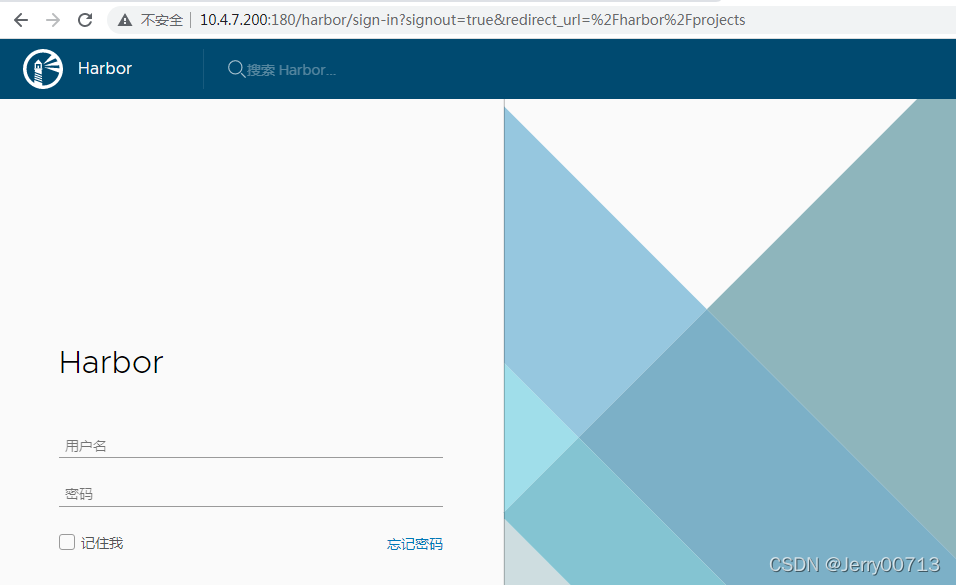
5.2、登录验证
访问http://10.4.7.200:180
默认密码在harbor.yaml配置文件中的harbor_admin_password: Harbor12345,账户是admin
6. 安装nginx反向代理harbor
安装Nginx反向代理harbor,实现访问harbor.od.com就能访问http://10.4.7.200:180
# 当前机器中Nginx功能较少,使用yum安装即可。如有多个harbor考虑源码编译且配置健康检查
# nginx配置,仅仅使用最简单的配置。
[root@hdss7-200 harbor]# yum install -y nginx
[root@hdss7-200 harbor]# vim /etc/nginx/conf.d/harbor.conf # 去掉注释
server { # 服务端:就是代理后的,实现访问哪个地址,哪个端口,就能显示代理前的哪个地址端口
listen 80; # nginx代理后是60端口
server_name harbor.od.com; # nginx代理后地址是harbor.od.com
client_max_body_size 1000m; # 1g,harbor每一层镜像都不一样,避免出现上传失败的情况
location / {
proxy_pass http://127.0.0.1:180; # nginx代理前是哪个地址,哪个端口
}
}
[root@hdss7-200 harbor]# nginx -t # 检查配置文件是不是正确
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@hdss7-200 harbor]# systemctl start nginx
[root@hdss7-200 harbor]# systemctl enable nginx
[root@hdss7-200 yum.repos.d]# curl harbor.od.com
curl: (6) Could not resolve host: harbor.od.com; 未知的错误
curl: (6) Could not resolve host: harbor.od.com; 未知的错误 访问不上,原因是harbor.od.com是域名,物理机的dns配置的是10.4.7.10,浏览器访问harbor.od.com后,到达10.4.7.10的bind9,通过bind9解析后发现是10.4.7.200,bind9无差别的把访问harbor.od.com的流量抛给10.4.7.200,流量被10.4.7.200的nginx发现,是访问harbor.od.com,正好匹配的是10.4.7.200:180
[root@hdss7-11 ~]# vim /var/named/od.com.zone # 去掉注释
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010502 ; serial # 序列号需要滚动一个2
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
harbor A 10.4.7.200 # 增加harbor
[root@hdss7-11 ~]# systemctl restart named
访问harbor.od.com:
配置宿主机能够访问harbor.od.com:
在C:\Windows\System32\drivers\etc\hosts文件中,最后末尾加上
search host.com
nameserver 10.4.7.5为什么我加的是10.4.7.5,因为我Vmware8配置的就是10.4.7.5,具体怎么配置,查看随手记录心得--vmware(nat)配置固定IP_Jerry00713的博客-优快云博客,保存后,浏览器访问harbor.od.com
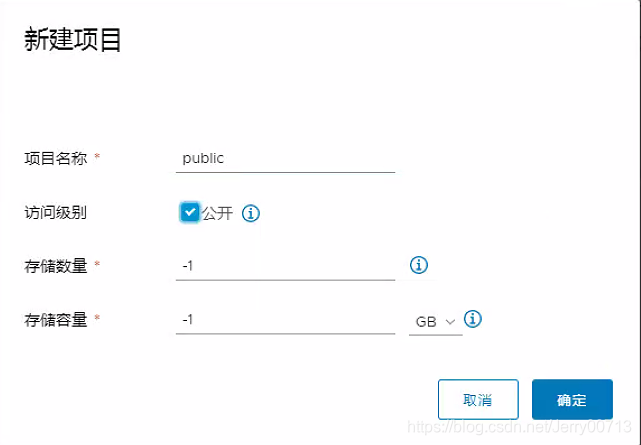
7、登录后创建一个公共public项目,测试验证上传镜像到harbor
注:docker默认全部发访问https,由于我们没有配置https,所以就得需要配置不安全insecure-registries(不安全配置)的选项
cat /etc/docker/daemon.json
"insecure-registries": ["registry.access.redhat.com","quay.io","harbor.od.com","harbor.od.com:180"],
7.1 下载(nginx:1.7.9)镜像
下载镜像,nginx:1.7.9
[root@hdss7-200 harbor]# docker pull nginx:1.7.9
1.7.9: Pulling from library/nginx
Image docker.io/library/nginx:1.7.9 uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker.com/registry/spec/deprecated-schema-v1/
a3ed95caeb02: Pull complete
6f5424ebd796: Pull complete
d15444df170a: Pull complete
e83f073daa67: Pull complete
a4d93e421023: Pull complete
084adbca2647: Pull complete
c9cec474c523: Pull complete
Digest: sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Status: Downloaded newer image for nginx:1.7.9
docker.io/library/nginx:1.7.9问题:如果拉取镜像超时
[root@hdss7-200 harbor]# docker pull nginx:1.7.9 Error response from daemon: Get https://registry-1.docker.io/v2/library/nginx/manifests/1.7.9: net/http: TLS handshake timeout解决方案:使用阿里云镜像仓库
[root@hdss7-200 harbor]# vi /etc/docker/daemon.json
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["registry.access.redhat.com","quay.io","harbor.od.com","harbor.od.com:180"],
"registry-mirrors": ["https://6kx4zyno.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}注意:这里要给hdss7-21 hdss7-22 hdss7-200都改到上述的配置(registry-mirrors:阿里云)跟(insecure-registries harbor.od.com:180),否则会导致hdss7-21 hdss7-22拉取不到hdss7-200的harbor上的镜像
重启docker,让配置生效
[root@hdss7-200 harbor]# systemctl daemon-reload
[root@hdss7-200 harbor]# systemctl restart docker由于重启docker,所以可能导致harbor加载失败,需要重启harbor
[root@hdss7-200 harbor]# chmod +x /usr/bin/docker-compose
[root@hdss7-200 harbor]# /usr/bin/docker-compose stop
[root@hdss7-200 harbor]# /usr/bin/docker-compose start
7.2 给镜像打标签:
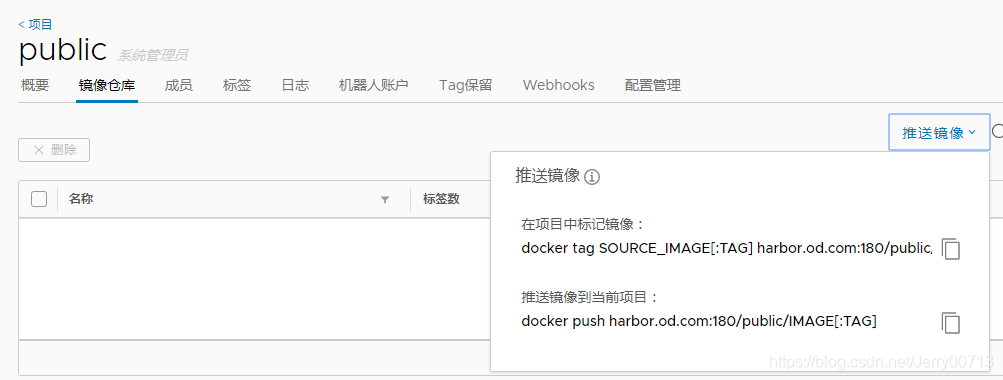
[root@hdss7-200 harbor]# docker image ls -a |grep nginx
nginx 1.7.9 84581e99d807 6 years ago 91.7MB
[root@hdss7-200 harbor]# docker image tag 84581e99d807 harbor.od.com:180/public/nginx:v1.7.97.3 nginx:1.7.9改标签后传入harbor
登录docker
# 第一次登录需要输入账户名密码,跟web页面的登录密码一致
# 账户:admin 密码:Harbor12345
[root@hdss7-200 harbor]# docker login harbor.od.com:180
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded如果登录docker失败问题:
[root@hdss7-200 harbor]# docker login harbor.od.com:180
Username: admin
Password:
Error response from daemon: Get http://harbor.od.com:180/v2/: dial tcp: lookup harbor.od.com on 10.4.7.11:53: no such host解析:
53端口: 53端口为DNS(Domain Name Server,域名服务器)服务器所开放,主要用于域名解析,DNS服务在NT系统中使用的最为广泛。
[root@hdss7-200 harbor]# ping hdss7-11
ping: hdss7-11: 未知的名称或服务解决方案:
[root@hdss7-200 ~]# vim /etc/hosts # 下增加一条记录
10.4.7.200 harbor.od.com重新测试:
[root@hdss7-200 ~]# docker login harbor.od.com:180 Username: admin Password: WARNING! Your password will be stored unencrypted in /root/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded
上传镜像
[root@hdss7-200 ~]# docker push harbor.od.com:180/public/nginx:v1.7.9
The push refers to repository [harbor.od.com:180/public/nginx]
5f70bf18a086: Pushed
4b26ab29a475: Pushed
ccb1d68e3fb7: Pushed
e387107e2065: Pushed
63bf84221cce: Pushed
e02dce553481: Pushed 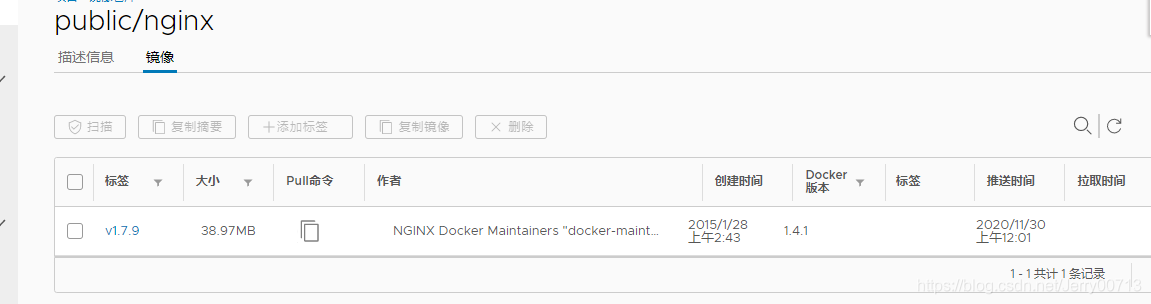
二、主控节点安装:
1、etcd安装
etcd 的leader选举机制,要求至少为3台或以上的奇数台。本次安装涉及:hdss7-12,hdss7-21,hdss7-22
1.1. 签发etcd证书
证书签发服务器 hdss7-200:
创建ca的json配置:
expiry 过期时间 "175200h"
server 表示服务端连接客户端时携带的证书,用于客户端验证服务端身份
client 表示客户端连接服务端时携带的证书,用于服务端验证客户端身份
peer 表示相互之间连接时使用的证书,如etcd节点之间需要互相通信
[root@hdss7-200 ~]# vim /opt/certs/ca-config.json
{
"signing": {
"default": {
"expiry": "175200h"
},
"profiles": {
"server": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"server auth"
]
},
"client": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
},
"peer": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}创建etcd证书请求的配置文件:
重点在hosts上,将所有可能的etcd服务器添加到host列表,不能使用网段,新增etcd服务器需要重新签发证书。理解:一个etcd的客户端,拿着peer证书,去跟其他etcd通信,其他的etcd会通过ca证书校验,你的证书是不是由我ca证书颁发,是不是由hosts里面的IP发出的请求。
[root@hdss7-200 ~]# vim /opt/certs/etcd-peer-csr.json # 在ca证书中配置了能够识别peer证书
{
"CN": "k8s-etcd",
"hosts": [
"10.4.7.11",
"10.4.7.12",
"10.4.7.21",
"10.4.7.22"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "beijing",
"L": "beijing",
"O": "od",
"OU": "ops"
}
]
}签发证书
[root@hdss7-200 ~]# cd /opt/certs/
[root@hdss7-200 certs]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=peer etcd-peer-csr.json |cfssl-json -bare etcd-peer
[root@hdss7-200 certs]# ll etcd-peer*
-rw-r--r-- 1 root root 1062 Jan 5 17:01 etcd-peer.csr
-rw-r--r-- 1 root root 363 Jan 5 16:59 etcd-peer-csr.json
-rw------- 1 root root 1675 Jan 5 17:01 etcd-peer-key.pem
-rw-r--r-- 1 root root 1428 Jan 5 17:01 etcd-peer.pem1.2 安装etcd
etcd地址:GitHub - etcd-io/etcd: Distributed reliable key-value store for the most critical data of a distributed system
实验使用版本: etcd-v3.1.20-linux-amd64.tar.gz
本次安装涉及:hdss7-12,hdss7-21,hdss7-22
下载etcd
[root@hdss7-12 ~]# useradd -s /sbin/nologin -M etcd # 使用etcd 先创建用户
[root@hdss7-12 ~]# mkdir /opt/src/;cd /opt/src/
[root@hdss7-12 src]# wget https://github.com/etcd-io/etcd/releases/download/v3.1.20/etcd-v3.1.20-linux-amd64.tar.gz
[root@hdss7-12 src]# tar xvf etcd-v3.1.20-linux-amd64.tar.gz -C /opt/
[root@hdss7-12 src]# cd /opt/
[root@hdss7-12 opt]# mv etcd-v3.1.20-linux-amd64/ etcd-v3.1.20
[root@hdss7-12 opt]# ln -s /opt/etcd-v3.1.20/ /opt/etcd
[root@hdss7-12 opt]# ll /opt/etcd
lrwxrwxrwx 1 root root 25 Jan 5 17:56 /opt/etcd -> /opt/etcd-v3.1.20
[root@hdss7-12 opt]# mkdir -p /opt/etcd/certs /data/etcd /data/logs/etcd-server
[root@hdss7-12 opt]# mkdir -p /opt/etcd/certs;cd /opt/etcd/certs下发证书到各个etcd上
[root@hdss7-200 ~]# cd /opt/certs/ [root@hdss7-200 certs]# for i in 12 21 22;do scp ca.pem etcd-peer.pem etcd-peer-key.pem hdss7-${i}:/opt/apps/etcd/certs/ ;done [root@hdss7-12 src]# md5sum /opt/apps/etcd/certs/* 8778d0c3411891af61a287e49a70c89a /opt/apps/etcd/certs/ca.pem 7918783c2f6bf69e96edf03e67d04983 /opt/apps/etcd/certs/etcd-peer-key.pem d4d849751a834c7727d42324fdedf92d /opt/apps/etcd/certs/etcd-peer.pem或者scp
[root@hdss7-12 certs]# scp hdss7-200.host.com:/opt/certs/ca.pem ./ [root@hdss7-12 certs]# scp hdss7-200.host.com:/opt/certs/etcd-peer-key.pem ./ [root@hdss7-12 certs]# scp hdss7-200.host.com:/opt/certs/etcd-peer.pem ./
创建启动脚本(部分参数每台机器不同)
[root@hdss7-12 certs]# vi /opt/etcd/etcd-server-startup.sh # 去掉注释
#!/bin/sh
# listen-peer-urls etcd节点之间通信端口
# listen-client-urls 客户端与etcd通信端口
# quota-backend-bytes 配额大小
# 需要修改的参数:name,listen-peer-urls,listen-client-urls,initial-advertise-peer-urls
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/etcd/etcd --name etcd-server-7-12 \
--data-dir /data/etcd/etcd-server \
--listen-peer-urls https://10.4.7.12:2380 \ # 使用的peer,说明etcd集群内部通信走2380
--listen-client-urls https://10.4.7.12:2379,http://127.0.0.1:2379 \ # etcd集群外部通信走2379
--quota-backend-bytes 8000000000 \ # 后端配额
--initial-advertise-peer-urls https://10.4.7.12:2380 \
--advertise-client-urls https://10.4.7.12:2379,http://127.0.0.1:2379 \
--initial-cluster etcd-server-7-12=https://10.4.7.12:2380,etcd-server-7-21=https://10.4.7.21:2380,etcd-server-7-22=https://10.4.7.22:2380 \
--ca-file ./certs/ca.pem \
--cert-file ./certs/etcd-peer.pem \
--key-file ./certs/etcd-peer-key.pem \
--client-cert-auth \ # 验证证书
--trusted-ca-file ./certs/ca.pem \
--peer-ca-file ./certs/ca.pem \
--peer-cert-file ./certs/etcd-peer.pem \
--peer-key-file ./certs/etcd-peer-key.pem \
--peer-client-cert-auth \
--peer-trusted-ca-file ./certs/ca.pem \
--log-output stdout
[root@hdss7-12 certs]# chown etcd.etcd -R /opt/etcd-v3.1.20/
[root@hdss7-12 certs]# cd /opt/etcd
[root@hdss7-12 certs]# chmod +x /opt/etcd/etcd-server-startup.sh
[root@hdss7-12 certs]# mkdir /data/etcd;mkdir -p /data/logs/etcd-server/
[root@hdss7-12 certs]# chown etcd.etcd -R /data/etcd/
[root@hdss7-12 certs]# chown etcd.etcd -R /data/logs/etcd-server/
1.3 supervisord 工具
考虑到我们要在k8s集群外部安装部署(etcd、flanned、apiserver等等组件),而这些组件都需要启动为后台进程,而且希望这些组件如果异常崩掉(进程不在了),能够自主拉起来,所以我们需要使用后台管理工具supervisord
[root@hdss7-12 certs]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@hdss7-12 certs]# yum clean all;yum makecache
[root@hdss7-12 certs]# yum install -y supervisor
[root@hdss7-12 certs]# systemctl start supervisord
[root@hdss7-12 certs]# systemctl enable supervisord1.4 启动etcd
[root@hdss7-12 certs]# vi /etc/supervisord.d/etcd-server.ini
[program:etcd-server-7-12]
command=/opt/etcd/etcd-server-startup.sh ; the program (relative uses PATH, can take args)
numprocs=1 ; number of processes copies to start (def 1)
directory=/opt/etcd ; directory to cwd to before exec (def no cwd)
autostart=true ; start at supervisord start (default: true)
autorestart=true ; retstart at unexpected quit (default: true)
startsecs=30 ; number of secs prog must stay running (def. 1)
startretries=3 ; max # of serial start failures (default 3)
exitcodes=0,2 ; 'expected' exit codes for process (default 0,2)
stopsignal=QUIT ; signal used to kill process (default TERM)
stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10)
user=etcd ; setuid to this UNIX account to run the program
redirect_stderr=true ; redirect proc stderr to stdout (default false)
stdout_logfile=/data/logs/etcd-server/etcd.stdout.log ; stdout log path, NONE for none; default AUTO
stdout_logfile_maxbytes=64MB ; max # logfile bytes b4 rotation (default 50MB)
stdout_logfile_backups=5 ; # of stdout logfile backups (default 10)
stdout_capture_maxbytes=1MB ; number of bytes in 'capturemode' (default 0)
stdout_events_enabled=false ; emit events on stdout writes (default false) 解释:
[program:etcd-server-7-12] command=/opt/etcd/etcd-server-startup.sh # 如何启动 numprocs=1 # 要启动的进程数,意思是supervisord帮助你启动几次etcd-server-startup.sh directory=/opt/etcd # 在那个目录下执行启动等命令 autostart=true # 是不是自动启动,每次重启supervisord或者重启系统,是不是自动启动 autorestart=true # 有异常的时候,是不是自动重启 startsecs=30 # 进程启动后,检测进程多长时间判断为正常启动 startretries=3 # 异常后,重启的次数 exitcodes=0,2 # 异常退出模拟信号(解释器) stopsignal=QUIT # 用于终止进程的信号 stopwaitsecs=10 # 等待b4 SIGKILL的最大秒数(默认值10)) user=etcd # 以etcd用户启动运行该程序 redirect_stderr=true # 是否重定向到stdout日志 stdout_logfile=/data/logs/etcd-server/etcd.stdout.log # 配置了标准输出,把标准错误输出重定向到标准输出 stdout_logfile_maxbytes=64MB # 单个日志最大不能超过多少(默认50MB) stdout_logfile_backups=5 # stdout日志文件备份的数量(默认为10) stdout_capture_maxbytes=1MB # 设定capture管道的大小,当值不为0的时候,子进程可以从stdout发送信息, 而supervisor可以根据信息,发送相应的event。默认为0,为0的时候表达关闭管道,非必须项capturemode”中的字节数(默认为0) stdout_events_enabled=false # 当设置为ture的时候,当子进程由stdout向文件描述符中写日志的时候,将触发supervisord发 送PROCESS_LOG_STDOUT类型的event默认为false。非必须设置
[root@hdss7-12 certs]# supervisorctl update # 使用update,让supervisorctl加载etcd-server.ini
[root@hdss7-12 certs]# supervisorctl status # 查看supervisorctl 中组件状态
etcd-server-7-12 STARTING # etcd 进程状态查看
[root@hdss7-12 certs]# supervisorctl status
etcd-server-7-12 RUNNING pid 5674, uptime 0:00:52
[root@hdss7-12 certs]# cat /data/logs/etcd-server/etcd.stdout.log # 查看etcd的日志
[root@hdss7-12 certs]# netstat -tulpn |grep etcd # 查看etcd的端口
tcp 0 0 10.4.7.12:2379 0.0.0.0:* LISTEN 5678/etcd
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 5678/etcd
tcp 0 0 10.4.7.12:2380 0.0.0.0:* LISTEN 5678/etcd [root@hdss7-12 ~]# /opt/etcd/etcdctl member list # 查看etcd集群领导状态,随着etcd重启,leader会变化
988139385f78284: name=etcd-server-7-22 peerURLs=https://10.4.7.22:2380 clientURLs=http://127.0.0.1:2379,https://10.4.7.22:2379 isLeader=false
5a0ef2a004fc4349: name=etcd-server-7-21 peerURLs=https://10.4.7.21:2380 clientURLs=http://127.0.0.1:2379,https://10.4.7.21:2379 isLeader=true
f4a0cb0a765574a8: name=etcd-server-7-12 peerURLs=https://10.4.7.12:2380 clientURLs=http://127.0.0.1:2379,https://10.4.7.12:2379 isLeader=false
[root@hdss7-12 ~]# /opt/etcd/etcdctl cluster-health # 查看etcd集群健康状态
member 988139385f78284 is healthy: got healthy result from http://127.0.0.1:2379
member 5a0ef2a004fc4349 is healthy: got healthy result from http://127.0.0.1:2379
member f4a0cb0a765574a8 is healthy: got healthy result from http://127.0.0.1:2379
cluster is healthyetcd 启动、停止、重启、状态方式
[root@hdss7-12 ~]# supervisorctl start etcd-server-7-12
[root@hdss7-12 ~]# supervisorctl stop etcd-server-7-12
[root@hdss7-12 ~]# supervisorctl restart etcd-server-7-12
[root@hdss7-12 ~]# supervisorctl status etcd-server-7-12
2 apiserver 安装
2.1. 下载kubernetes服务端
aipserver 涉及的服务器:hdss7-21,hdss7-22
下载 kubernetes 二进制版本包需要科学上网工具
进入kubernetes的github页面: https://github.com/kubernetes/kubernetes
进入tags页签: https://github.com/kubernetes/kubernetes/tags
选择要下载的版本: https://github.com/kubernetes/kubernetes/releases/tag/v1.15.2
点击 CHANGELOG-${version}.md 进入说明页面: https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.15.md#downloads-for-v1152
下载Server Binaries: https://dl.k8s.io/v1.15.2/kubernetes-server-linux-amd64.tar.gz
[root@hdss7-21 ~]# cd /opt/src
[root@hdss7-21 src]# wget https://dl.k8s.io/v1.15.2/kubernetes-server-linux-amd64.tar.gz
[root@hdss7-21 src]# tar -xf kubernetes-server-linux-amd64.tar.gz -C /opt/
[root@hdss7-21 src]# mv /opt/kubernetes /opt/kubernetes-v1.15.2
[root@hdss7-21 src]# ln -s /opt/kubernetes-v1.15.2 /opt/kubernetes
[root@hdss7-21 src]# ll /opt/
lrwxrwxrwx 1 root root 23 9月 24 08:22 kubernetes -> /opt/kubernetes-v1.15.2
drwxr-xr-x 4 root root 79 8月 5 2019 kubernetes-v1.15.2
[root@hdss7-21 src]# cd /opt/kubernetes
[root@hdss7-21 kubernetes]# rm -f kubernetes-src.tar.gz # go源码包
[root@hdss7-21 kubernetes]# cd server/bin/
[root@hdss7-21 bin]# rm -f *.tar *_tag # *.tar *_tag 镜像文件
[root@hdss7-21 bin]# ll
total 884636
-rwxr-xr-x 1 root root 43534816 Aug 5 18:01 apiextensions-apiserver
-rwxr-xr-x 1 root root 100548640 Aug 5 18:01 cloud-controller-manager
-rwxr-xr-x 1 root root 200648416 Aug 5 18:01 hyperkube
-rwxr-xr-x 1 root root 40182208 Aug 5 18:01 kubeadm
-rwxr-xr-x 1 root root 164501920 Aug 5 18:01 kube-apiserver
-rwxr-xr-x 1 root root 116397088 Aug 5 18:01 kube-controller-manager
-rwxr-xr-x 1 root root 42985504 Aug 5 18:01 kubectl # 客户端cli工具
-rwxr-xr-x 1 root root 119616640 Aug 5 18:01 kubelet
-rwxr-xr-x 1 root root 36987488 Aug 5 18:01 kube-proxy
-rwxr-xr-x 1 root root 38786144 Aug 5 18:01 kube-scheduler
-rwxr-xr-x 1 root root 1648224 Aug 5 18:01 mounter2.2.部署签发 kube-apiserver证书:
签发证书实现apiserver跟etcd通信的证书:etcd是server端,apiserver 是客户端,所以需要一个client证书给apiserver
签发证书涉及的服务器:hdss7-200
签发client证书(apiserver和etcd通信证书)
[root@hdss7-200 ~]# cd /opt/certs/
[root@hdss7-200 certs]# vim /opt/certs/client-csr.json
{
"CN": "k8s-node",
"hosts": [
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "beijing",
"L": "beijing",
"O": "od",
"OU": "ops"
}
]
}
[root@hdss7-200 certs]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=client client-csr.json |cfssl-json -bare client
[root@hdss7-200 certs]# ll |grep "client"
-rw-r--r-- 1 root root 993 9月 23 19:32 client.csr
-rw-r--r-- 1 root root 280 9月 23 19:31 client-csr.json
-rw------- 1 root root 1679 9月 23 19:32 client-key.pem
-rw-r--r-- 1 root root 1363 9月 23 19:32 client.pem
给apiserver签发server证书(apiserver和其它k8s组件通信使用),实现apiserver是server端,其他程序是client端,其他程序想要找我apiserver,需要ssl认证
# hosts中将所有可能作为apiserver的ip添加进去,VIP 10.4.7.10 也要加入
[root@hdss7-200 certs]# vim /opt/certs/apiserver-csr.json
{
"CN": "k8s-apiserver",
"hosts": [
"127.0.0.1",
"192.168.0.1",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local",
"10.4.7.10",
"10.4.7.21",
"10.4.7.22",
"10.4.7.23"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "beijing",
"L": "beijing",
"O": "od",
"OU": "ops"
}
]
}解释:
"10.4.7.10", apiserver可能存在的地址---虚拟IP
"10.4.7.21", apiserver可能存在的地址
"10.4.7.22", apiserver可能存在的地址
"10.4.7.23" apiserver可能存在的地址
制作证书:
[root@hdss7-200 certs]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=server apiserver-csr.json |cfssl-json -bare apiserver
[root@hdss7-200 certs]# ll
-rw-r--r-- 1 root root 1249 9月 23 19:40 apiserver.csr
-rw-r--r-- 1 root root 566 9月 23 19:37 apiserver-csr.json
-rw------- 1 root root 1679 9月 23 19:40 apiserver-key.pem
-rw-r--r-- 1 root root 1598 9月 23 19:40 apiserver.pem
[root@hdss7-21 bin]# mkdir /opt/kubernetes/server/bin/cert;cd /opt/kubernetes/server/bin/cert
证书下发:
[root@hdss7-200 certs]# for i in 21 22;do echo hdss7-$i;ssh hdss7-$i "mkdir /opt/apps/kubernetes/server/bin/certs";scp apiserver-key.pem apiserver.pem ca-key.pem ca.pem client-key.pem client.pem hdss7-$i:/opt/apps/kubernetes/server/bin/certs/;done或者scp
[root@hdss7-21 bin]# scp hdss7-200.host.com:/opt/certs/ca.pem ./
[root@hdss7-21 bin]# scp hdss7-200.host.com:/opt/certs/ca-key.pem ./
[root@hdss7-21 bin]# scp hdss7-200.host.com:/opt/certs/client-key.pem ./
[root@hdss7-21 bin]# scp hdss7-200.host.com:/opt/certs/client.pem ./
[root@hdss7-21 bin]# scp hdss7-200.host.com:/opt/certs/apiserver.pem ./
[root@hdss7-21 bin]# scp hdss7-200.host.com:/opt/certs/apiserver-key.pem ./
7.3. 配置apiserver日志审计
aipserver 涉及的服务器:hdss7-21,hdss7-22
[root@hdss7-21 ]# cd /opt/kubernetes/server/bin/
[root@hdss7-21 bin]# mkdir conf # 给apiserver 创建配置
[root@hdss7-21 bin]# vim /opt/kubernetes/server/bin/conf/audit.yaml # 打开文件后,输入 :set paste,在按i,避免自动缩进
apiVersion: audit.k8s.io/v1beta1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"7.4. 配置启动脚本
aipserver 涉及的服务器:hdss7-21,hdss7-22
创建启动脚本 kube-apiserver
/opt/kubernetes/server/bin 下的kube-apiserver本身就是启动文件,正常通过启动脚本附带参数形式,就可以正常启动。具体参数参考(/opt/kubernetes/server/bin/kube-apiserver --help)。而kube-apiserver附带的参数很多,索性把需要带的参数,写成一个脚本,也方便supervisor管理
[root@hdss7-21 bin]# vim /opt/kubernetes/server/bin/kube-apiserver-startup.sh
#!/bin/bash
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/kubernetes/server/bin/kube-apiserver \
--apiserver-count 2 \
--audit-log-path /data/logs/kubernetes/kube-apiserver/audit-log \
--audit-policy-file ./conf/audit.yaml \
--authorization-mode RBAC \
--client-ca-file ./cert/ca.pem \
--requestheader-client-ca-file ./cert/ca.pem \
--enable-admission-plugins NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota \
--etcd-cafile ./cert/ca.pem \
--etcd-certfile ./cert/client.pem \
--etcd-keyfile ./cert/client-key.pem \
--etcd-servers https://10.4.7.12:2379,https://10.4.7.21:2379,https://10.4.7.22:2379 \
--service-account-key-file ./cert/ca-key.pem \
--service-cluster-ip-range 192.168.0.0/16 \
--service-node-port-range 3000-29999 \
--target-ram-mb=1024 \
--kubelet-client-certificate ./cert/client.pem \
--kubelet-client-key ./cert/client-key.pem \
--log-dir /data/logs/kubernetes/kube-apiserver \
--tls-cert-file ./cert/apiserver.pem \
--tls-private-key-file ./cert/apiserver-key.pem \
--v 2解释:
--apiserver-count 2 \ 数量2
--audit-policy-file ./conf/audit.yaml \ 日志审计规则指向audit.yaml
--authorization-mode RBAC \ 健权模式RBAC基于角色的访问控制
[root@hdss7-21 bin]# chmod +x /opt/kubernetes/server/bin/kube-apiserver-startup.sh
[root@hdss7-21 bin]# mkdir -p /data/logs/kubernetes/kube-apiserver/
配置supervisor启动配置
[root@hdss7-21 bin]# vim /etc/supervisord.d/kube-apiserver.ini
[program:kube-apiserver-7-21]
command=/opt/kubernetes/server/bin/kube-apiserver-startup.sh
numprocs=1
directory=/opt/kubernetes/server/bin
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/kubernetes/kube-apiserver/apiserver.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=5
stdout_capture_maxbytes=1MB
stdout_events_enabled=false
[root@hdss7-22 bin]# supervisorctl update
kube-apiserver-7-22: added process group
[root@hdss7-22 bin]# supervisorctl status
etcd-server-7-22 RUNNING pid 6101, uptime 0:52:15
kube-apiserver-7-22 RUNNING pid 6231, uptime 0:00:34如果发现kube-apiserver-7-22出问题(FATAL)
[root@hdss7-22 ~]# supervisorctl status etcd-server-7-22 RUNNING pid 4645, uptime 0:00:38 kube-apiserver-7-22 FATAL Exited too quickly (process log may have details)[root@hdss7-22 ~]# tail -200 /data/logs/kubernetes/kube-apiserver/apiserver.stdout.log # 查看日志 [root@hdss7-21 bin]# systemctl start kube-apiserver-7-22 # 找到问题并解决后,启动kube-apiserver-7-22 [root@hdss7-21 bin]# systemctl restart supervisord # 如果重启kube-apiserver-7-22不好使,可以重启supervisord [root@hdss7-22 ~]# supervisorctl update # 可以在update一下
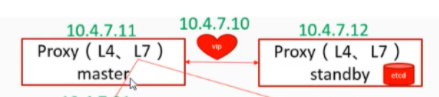
3. 配置apiserver L4代理
[root@hdss7-21 bin]# netstat -tulpn |grep apiserver # apiserver 启动后监听本机的8080跟6443端口
tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 6315/kube-apiserver
tcp6 0 0 :::6443 :::* LISTEN 6315/kube-apiserver 我们需要在hdss7-11,hdss7-12 这两个机器做虚拟VIP10.4.7.10,端口是7443 ,来反向代理hdss7-21,hdss7-22 的 apiserver的L4 (4层) 6433端口,保证了6443端口的高可用、负载均衡
3.1. nginx配置
L4 代理涉及的服务器:hdss7-11,hdss7-12
# 末尾加上以下内容,stream模块 跟 http模块 都是一个平级,所以stream模块只能加在 main中,不能加载http模块下,stream是4层代理的,stream模块是写入的是四层代理,http 模块是写入的是七层代理,所以不要写错位置
# 此处只是简单配置下nginx,实际生产中,建议进行更合理的配置
需求:把10.4.7.21的apiserver(10.4.7.21:6443 )、10.4.7.22的apiserver(10.4.7.22:6443 ) 代理给10.4.7.11、10.4.7.12 的7443 端口
注:不能安装nginx太高的版本,否则提示无法识别stream,hdss7-11,hdss7-12都要安装
[root@hdss7-11 ~]# rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
[root@hdss7-11 ~]# ll /etc/yum.repos.d/nginx.repo
-rw-r--r--. 1 root root 113 Jul 15 2014 /etc/yum.repos.d/nginx.repo
[root@hdss7-11 ~]# yum install -y nginx-1.14.2-1.el7_4.ngx.x86_64
[root@hdss7-11 ~]# vim /etc/nginx/nginx.conf
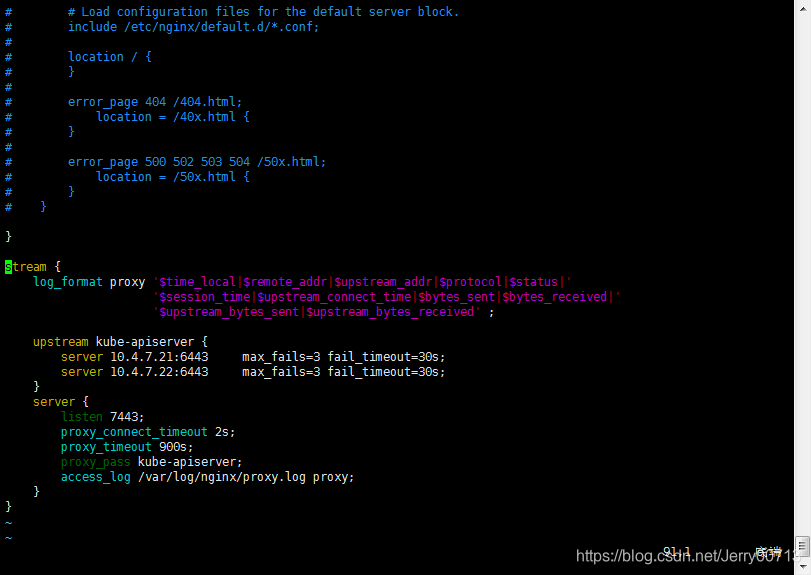
[root@hdss7-12 ~]# vim /etc/nginx/nginx.conf # 追加,不要修改源文件
stream {
log_format proxy '$time_local|$remote_addr|$upstream_addr|$protocol|$status|'
'$session_time|$upstream_connect_time|$bytes_sent|$bytes_received|'
'$upstream_bytes_sent|$upstream_bytes_received' ;
upstream kube-apiserver {
server 10.4.7.21:6443 max_fails=3 fail_timeout=30s;
server 10.4.7.22:6443 max_fails=3 fail_timeout=30s;
}
server {
listen 7443;
proxy_connect_timeout 2s;
proxy_timeout 900s;
proxy_pass kube-apiserver;
access_log /var/log/nginx/proxy.log proxy;
}
}
检查nginx 配置:
[root@hdss7-11 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful注:如果报错,提示unknown directive "stream" in /etc/nginx/nginx.conf
解决方案:
1、可能由于上述添加到/etc/nginx/nginx.conf中格式有问题,比如空格是tab
2、网上说在nginx.conf的第一行插入:load_module /usr/lib/nginx/modules/ngx_stream_module.so; 测试无效
3、可能是版本的问题,当前安装(nginx version: nginx/1.20),建议使用yum 安装低版本,yum list nginx,在安装对应的版本
4、最后我是通过rpm安装低版本nginx version: nginx/1.14.2
rpm -ivh http://nginx.org/packages/centos/7/x86_64/RPMS/nginx-1.14.2-1.el7_4.ngx.x86_64.rpm ,然后重启nginx systemctl restart nginx
启动:
[root@hdss7-11 ~]# systemctl start nginx
[root@hdss7-11 ~]# systemctl enable nginx
[root@hdss7-11 ~]# curl 127.0.0.1:7443 # 测试几次,在日志中就有几条
Client sent an HTTP request to an HTTPS server.
[root@hdss7-11 ~]# cat /var/log/nginx/proxy.log # 查看日志,127.0.0.1负载均衡后端21、22的6443
30/Nov/2020:13:43:14 +0800|127.0.0.1|10.4.7.21:6443|TCP|200|0.004|0.003|76|78|78|76
30/Nov/2020:13:43:15 +0800|127.0.0.1|10.4.7.22:6443|TCP|200|0.004|0.002|76|78|78|76
30/Nov/2020:13:43:16 +0800|127.0.0.1|10.4.7.21:6443|TCP|200|0.005|0.004|76|78|78|76
30/Nov/2020:13:43:17 +0800|127.0.0.1|10.4.7.22:6443|TCP|200|0.003|0.001|76|78|78|76
3.2. keepalived配置
aipserver L4 代理涉及的服务器:hdss7-11,hdss7-12
如果不配置虚拟IP,bind解析后IP写谁,10.4.7.11或者10.4.7.12? 一个节点宕机,apiserver不能访问了?安装keepalive,使其让7443端口在11、12两个节点飘起来。
[root@hdss7-11 ~]# yum install -y keepalived
[root@hdss7-11 ~]# vim /etc/keepalived/check_port.sh # 配置监听7443端口的检查脚本
# keepalived 监控端口脚本
# 使用方法
# 在keepalived的配置文件中
# vrrp_script check_port {#创建一个vrrp_script脚本,检查配置
# script "/etc/keepalived/check_port.hs 66379" # 配置监听的端口
# interval 2 # 检查脚本的频率,单位(秒)
# 配置以2s检测一次,本机的7443端口,如果不通,进行飘逸
#!/bin/bash
if [ $# -eq 1 ] && [[ $1 =~ ^[0-9]+ ]];then
[ $(netstat -lntp|grep ":$1 " |wc -l) -eq 0 ] && echo "[ERROR] nginx may be not running!" && exit 1 || exit 0
else
echo "[ERROR] need one port!"
exit 1
fi[root@hdss7-11 ~]# chmod +x /etc/keepalived/check_port.sh
keepalived配置主节点/etc/keepalived/keepalived.conf
hdss7-11 :
keepalived 的日志输出配置此处省略,生产中需要进行处理。
[root@hdss7-11 ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf_old
[root@hdss7-11 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 10.4.7.11
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 7443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 251
priority 100
advert_int 1
mcast_src_ip 10.4.7.11
nopreempt
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
10.4.7.10
}
}解释:
router_id 10.4.7.11
vrrp_script chk_nginx { 脚本弄进来
script "/etc/keepalived/check_port.sh 7443" 给脚本传参7443,脚本声明了$1
interface ens33 绑定在那个网卡
配置备节点:/etc/keepalived/keepalived.conf
hdss7-12 :
[root@hdss7-12 ~]# mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf_old
[root@hdss7-12 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 10.4.7.12
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 7443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 251
mcast_src_ip 10.4.7.12
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
10.4.7.10
}
}启动keepalived(hdss7-11,hdss7-12)
[root@hdss7-11 ~]# systemctl start keepalived;systemctl enable keepalived
[root@hdss7-12 ~]# systemctl start keepalived;systemctl enable keepalived
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@hdss7-11 ~]# ip addr show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a7:7d:c7 brd ff:ff:ff:ff:ff:ff
inet 10.4.7.11/8 brd 10.255.255.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.4.7.10/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fea7:7dc7/64 scope link
valid_lft forever preferred_lft forever
[root@hdss7-12 ~]# ip addr show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:82:ed:65 brd ff:ff:ff:ff:ff:ff
inet 10.4.7.12/8 brd 10.255.255.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe82:ed65/64 scope link
valid_lft forever preferred_lft forever注:
主节点中keepalived.conf ,必须加上 nopreempt 非抢占式
因为主备节点一旦因为网络抖动,导致备节点到主节点网络不可达,进而触发备节点keepalived未检测到主节点7443端口。就会触发VIP漂移,这样备节点就会启动10.4.7.10,如果只是单纯的主、备节点互相网络不通,那就会存在网络中两个10.4.7.10。一旦网络无问题,可以互相访问了,备节点检测主节点活着,7443端口启动,主节点发现备启动VIP,由于主节点是抢占式,会立马恢复到主节点,这种情况在生产算是重大的责任。为了不让它由于网络抖动问题来回飘逸,所以必须配置 nopreempt:非抢占式,飘逸到备节点后,即使检测主节点7443存活,也不会迁移VIP到主节点,主节点如果启动VIP,会主动停止。但这种情况会导致,必须要分析原因后手动迁移VIP到主节点!如主节点确认正常后,重启备节点的keepalive,让VIP飘到主节点。如:
[root@hdss7-11 ~]# ip addr show ens33
inet 10.4.7.10/32 scope global ens33
[root@hdss7-11 ~]# systemctl stop nginx
[root@hdss7-11 ~]# ip addr show ens33 无10.4.7.10/32
[root@hdss7-12 ~]# ip addr show ens33
inet 10.4.7.10/32 scope global ens33
[root@hdss7-11 ~]# systemctl start nginx
[root@hdss7-11 ~]# ip addr show ens33 无10.4.7.10/32
这时候需要:
重启keepalived
[root@hdss7-11 ~]# systemctl start nginx
[root@hdss7-11 ~]# systemctl restart keepalived
[root@hdss7-11 ~]# ip addr show ens33
inet 10.4.7.10/32 scope global ens33
[root@hdss7-12 ~]# systemctl restart keepalived
4. controller-manager 安装
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
controller-manager 涉及的服务器:hdss7-21,hdss7-22
controller-manager 设置为只调用当前机器的 apiserver,走127.0.0.1网卡,因此不配制SSL证书
[root@hdss7-21 ~]# vim /opt/kubernetes/server/bin/kube-controller-manager-startup.sh
#!/bin/sh
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/kubernetes/server/bin/kube-controller-manager \
--cluster-cidr 172.7.0.0/16 \
--leader-elect true \
--log-dir /data/logs/kubernetes/kube-controller-manager \
--master http://127.0.0.1:8080 \
--service-account-private-key-file ./cert/ca-key.pem \
--service-cluster-ip-range 192.168.0.0/16 \
--root-ca-file ./cert/ca.pem \
--v 2[root@hdss7-21 ~]# mkdir -p /data/logs/kubernetes/kube-controller-manager
[root@hdss7-21 ~]# chmod u+x /opt/kubernetes/server/bin/kube-controller-manager-startup.sh
配置supervisord文件:
[root@hdss7-21 ~]# vim /etc/supervisord.d/kube-controller-manager.ini
[program:kube-controller-manager-7-21]
command=/opt/kubernetes/server/bin/kube-controller-manager-startup.sh ; the program (relative uses PATH, can take args)
numprocs=1 ; number of processes copies to start (def 1)
directory=/opt/kubernetes/server/bin ; directory to cwd to before exec (def no cwd)
autostart=true ; start at supervisord start (default: true)
autorestart=true ; retstart at unexpected quit (default: true)
startsecs=30 ; number of secs prog must stay running (def. 1)
startretries=3 ; max # of serial start failures (default 3)
exitcodes=0,2 ; 'expected' exit codes for process (default 0,2)
stopsignal=QUIT ; signal used to kill process (default TERM)
stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10)
user=root ; setuid to this UNIX account to run the program
redirect_stderr=true ; redirect proc stderr to stdout (default false)
stdout_logfile=/data/logs/kubernetes/kube-controller-manager/controller.stdout.log ; stderr log path, NONE for none; default AUTO
stdout_logfile_maxbytes=64MB ; max # logfile bytes b4 rotation (default 50MB)
stdout_logfile_backups=4 ; # of stdout logfile backups (default 10)
stdout_capture_maxbytes=1MB ; number of bytes in 'capturemode' (default 0)
stdout_events_enabled=false[root@hdss7-21 ~]# supervisorctl update
kube-controller-manager-7-21: added process group
[root@hdss7-21 ~]# supervisorctl status
etcd-server-7-21 STARTING
kube-apiserver-7-21 STARTING
kube-controller-manager-7-21 STARTING
[root@hdss7-21 bin]# supervisorctl status
etcd-server-7-21 RUNNING pid 1429, uptime 0:00:31
kube-apiserver-7-21 RUNNING pid 1428, uptime 0:00:31
kube-controller-manager-7-21 RUNNING pid 1427, uptime 0:00:315. kube-scheduler安装
kube-scheduler 涉及的服务器:hdss7-21,hdss7-22
在kube-scheduler-startup.sh中配置(master http://127.0.0.1:8080\kube-scheduler)说明kube-scheduler设置只调用本地的apiserver(127.0.0.1:8080),所以走127.0.0.1本机回环lo网卡,因此不配制SSL证书,如果是交叉找apiserver,比如10.4.7.21的kube-scheduler找10.4.7.22的apiserver必须的配置SSL (client.pem client-key.pem )
[root@hdss7-21 ~]# vim /opt/kubernetes/server/bin/kube-scheduler-startup.sh
#!/bin/sh
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/kubernetes/server/bin/kube-scheduler \
--leader-elect \
--log-dir /data/logs/kubernetes/kube-scheduler \
--master http://127.0.0.1:8080 \
--v 2[root@hdss7-21 ~]# mkdir -p /data/logs/kubernetes/kube-scheduler
[root@hdss7-21 ~]# chmod u+x /opt/kubernetes/server/bin/kube-scheduler-startup.sh
配置supervisord文件:
[root@hdss7-21 ~]# vim /etc/supervisord.d/kube-scheduler.ini
[program:kube-scheduler-7-21]
command=/opt/kubernetes/server/bin/kube-scheduler-startup.sh
numprocs=1
directory=/opt/kubernetes/server/bin
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/kubernetes/kube-scheduler/scheduler.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_events_enabled=false
[root@hdss7-21 ~]# supervisorctl update
kube-scheduler-7-21: added process group
etcd-server-7-21 RUNNING pid 1457, uptime 0:14:20
kube-apiserver-7-21 RUNNING pid 1458, uptime 0:14:20
kube-controller-manager-7-21 RUNNING pid 1456, uptime 0:14:20
kube-scheduler-7-21 RUNNING pid 1507, uptime 0:01:076. 检查主控节点状态
主控节点已经部署完毕,我们检查集群健康状态,用到kubectl
[root@hdss7-21 ~]# ln -s /opt/kubernetes/server/bin/kubectl /usr/local/bin/
[root@hdss7-22 ~]# ln -s /opt/kubernetes/server/bin/kubectl /usr/local/bin/
[root@hdss7-21 ~]# which kubectl
/usr/local/bin/kubectl
[root@hdss7-21 ~]# kubectl get cs # 检查集群的健康状态
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
controller-manager Healthy ok [root@hdss7-22 bin]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
controller-manager Healthy ok
三、运算节点(nod)部署
1. kubelet 部署
1.1. 签发证书
签发证书 kubelet也对外提供https服务,apiserver主动找 kubelet问节点的一些信息,所以kubelet需要给自己签发server 证书,而且server 证书中还的列出 kubelet 可能用到的所有节点,不能写IP段。注意:如果要后加节点,重新签发新的证书,以前的节点不需要动还使用以前的证书,新的证书给新的机节点用,随后重启服务,但是这时候有两套证书 。所以,以前的节点在流量低谷的时候,更新证书 ,然后节点重启
证书签发在 hdss7-200 操作:
[root@hdss7-200 ~]# cd /opt/certs/
[root@hdss7-200 certs]# vim kubelet-csr.json # 将所有可能的kubelet机器IP添加到hosts中
{
"CN": "k8s-kubelet",
"hosts": [
"127.0.0.1",
"10.4.7.10",
"10.4.7.21",
"10.4.7.22",
"10.4.7.23",
"10.4.7.24",
"10.4.7.25",
"10.4.7.26",
"10.4.7.27",
"10.4.7.28"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "beijing",
"L": "beijing",
"O": "od",
"OU": "ops"
}
]
}
[root@hdss7-200 certs]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=server kubelet-csr.json | cfssl-json -bare kubelet
2020/09/24 20:45:33 [INFO] generate received request
2020/09/24 20:45:33 [INFO] received CSR
2020/09/24 20:45:33 [INFO] generating key: rsa-2048
2020/09/24 20:45:34 [INFO] encoded CSR
2020/09/24 20:45:34 [INFO] signed certificate with serial number 56157483360560431242806622846202389257750601914
2020/09/24 20:45:34 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for
websites. For more information see the Baseline Requirements for the Issuance and Management
of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org);
specifically, section 10.2.3 ("Information Requirements").
[root@hdss7-200 certs]# ll
-rw-r--r-- 1 root root 1115 9月 24 20:45 kubelet.csr
-rw-r--r-- 1 root root 452 9月 24 20:45 kubelet-csr.json
-rw------- 1 root root 1679 9月 24 20:45 kubelet-key.pem
-rw-r--r-- 1 root root 1468 9月 24 20:45 kubelet.pemhdss7-21、hdss7-22 获取证书:
方式一:hdss7-200操作
[root@hdss7-200 certs]# scp kubelet.pem kubelet-key.pem hdss7-21:/opt/kubernetes/server/bin/certs/ [root@hdss7-200 certs]# scp kubelet.pem kubelet-key.pem hdss7-22:/opt/kubernetes/server/bin/certs/方式二:hdss7-21、hdss7-22操作
[root@hdss7-21 ~]# cd /opt/kubernetes/server/bin/cert [root@hdss7-21 cert]# scp hdss7-200:/opt/certs/kubelet.pem ./ [root@hdss7-21 cert]# scp hdss7-200:/opt/certs/kubelet-key.pem ./ [root@hdss7-22 ~]# cd /opt/kubernetes/server/bin/cert [root@hdss7-22 cert]# scp hdss7-200:/opt/certs/kubelet.pem ./ [root@hdss7-22 cert]# scp hdss7-200:/opt/certs/kubelet-key.pem ./
1.2. 创建kubelet配置
kubelet配置在 hdss7-21 或者 hdss7-22一个节点操作即可,另一个节点通过scp拷贝
[root@hdss7-21 conf]# cd /opt/kubernetes/server/bin/conf
第一步:set-cluster # 创建需要连接的集群信息,可以创建多个k8s集群信息
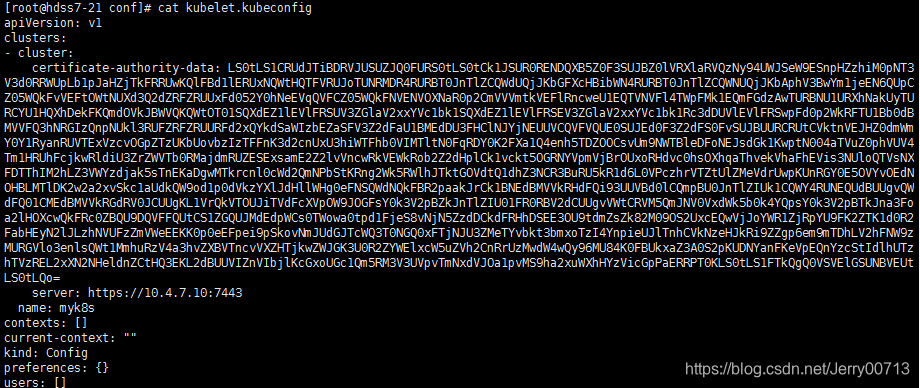
[root@hdss7-21 conf ]# kubectl config set-cluster myk8s \ --certificate-authority=/opt/kubernetes/server/bin/cert/ca.pem \ --embed-certs=true \ --server=https://10.4.7.10:7443 \ --kubeconfig=/opt/kubernetes/server/bin/conf/kubelet.kubeconfig 解释: [root@hdss7-21 conf ]# kubectl config set-cluster myk8s \ --certificate-authority=/opt/kubernetes/server/bin/cert/ca.pem \ 根证书ca指进来 --embed-certs=true \ 承载式证书 --server=https://10.4.7.10:7443 \ 指server=vip --kubeconfig=/opt/kubernetes/server/conf/kubelet.kubeconfig 目的是要给kubectl做一个k8s用户,k8s客户体系很复杂,有普通、特殊等用户,这里是普通用户,普通用户要跟 apiserver通信的时候要有一个接入点,接入点就是https://10.4.7.10:7443,防止kubectl只找本地自己的 apiserver,一旦本地apiserver宕机,本机kubectl就用不了了
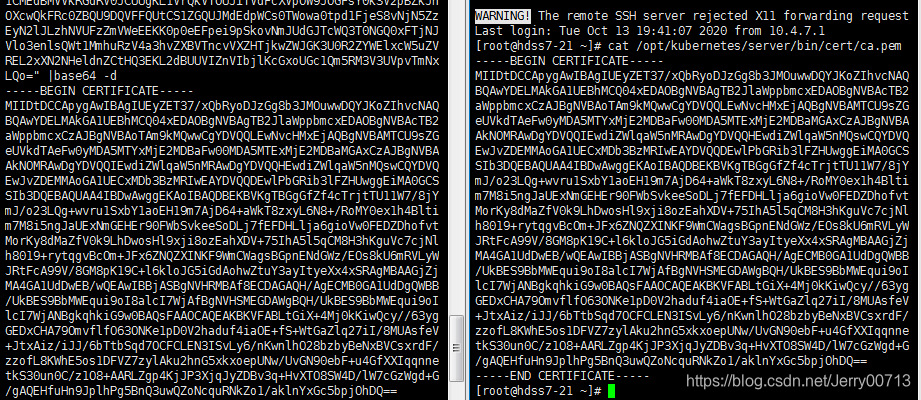
讲解:查看/opt/kubernetes/server/bin/conf/kubelet.kubeconfig,这里ca已经加入进来
把里面使用base64位编码加密的ca数据,解密查看:使用echo "ca数据 " 传递给base64 -d
结果跟ca对比 /opt/kubernetes/server/bin/cert/ca.pem, 一模一样


第二步:set-credentials # 创建用户账号,即用户登陆使用的客户端私有和证书,可以创建多个证书
[root@hdss7-21 ~]# cd /opt/kubernetes/server/bin/conf [root@hdss7-21 conf]# kubectl config set-credentials k8s-node \ --client-certificate=/opt/kubernetes/server/bin/cert/client.pem \ --client-key=/opt/kubernetes/server/bin/cert/client-key.pem \ --embed-certs=true \ --kubeconfig=kubelet.kubeconfig 解释: [root@hdss7-21 conf]# kubectl config set-credentials k8s-node \ --client-certificate=/opt/kubernetes/server/bin/cert/client.pem \ 把client.pem放进来 --client-key=/opt/kubernetes/server/bin/cert/client-key.pem \ 把client-key.pem 放进来 --embed-certs=true \ --kubeconfig=kubelet.kubeconfig 把client.pem 、client-key.pem 放进来,说明kubectl要跟apiuserver通信, 这时候apiserver是我的服务 端,因为是ssl, 所以kubectl必须拿着clinet证书才能跟apiuserver通信,kubectl作为客户端。

第三步:set-context # 设置context,即确定账号和集群对应关系
[root@hdss7-21 ~]# cd /opt/kubernetes/server/bin/conf [root@hdss7-21 conf]# kubectl config set-context myk8s-context \ --cluster=myk8s \ --user=k8s-node \ --kubeconfig=kubelet.kubeconfig 解释: [root@hdss7-21 ~]# kubectl config set-context myk8s-context \ --cluster=myk8s \ --user=k8s-node \ 指定了一个user=k8s-node --kubeconfig=kubelet.kubeconfig

第四步:use-context # 设置当前使用哪个context,任意路径下执行即可
[root@hdss7-21 ~]# cd /opt/kubernetes/server/bin/conf [root@hdss7-21 conf]# kubectl config use-context myk8s-context --kubeconfig=kubelet.kubeconfig 解释: [root@hdss7-21 conf]# kubectl config use-context myk8s-context --kubeconfig=kubelet.kubeconfig 切换到k8s-node
查看[root@hdss7-21 conf]# cat /opt/kubernetes/server/bin/conf/kubelet.kubeconfig
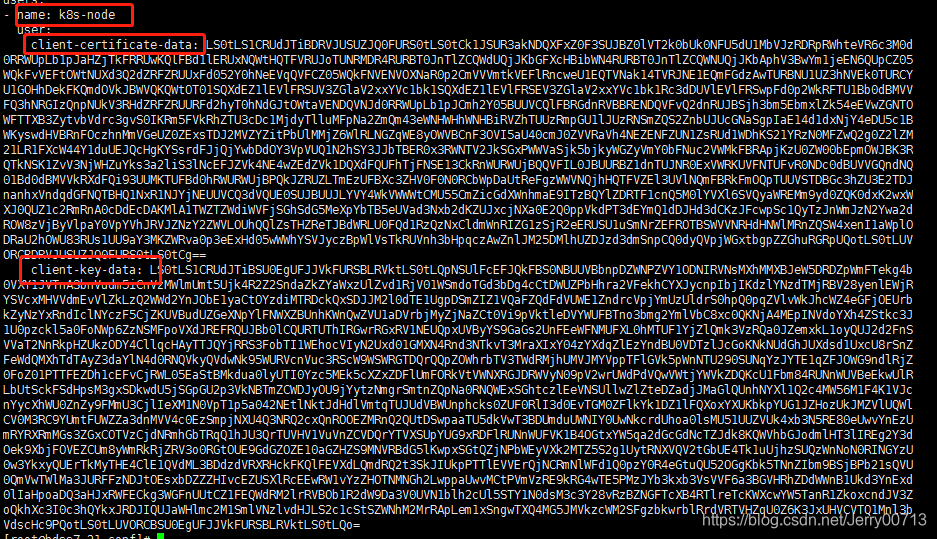
1.3. 授权k8s-node用户
给name: k8s-node 授一个权限,利用rbac规则让他具有集群里面成为节点的权限
此步骤只需要在一台master节点执行(因为这两个节点,只要创建一次,他已经进入k8s,已经落入到etcd里面,无论在那个节点执行,他都已经把资源创建出来,因此需要在一台master节点执行)
让 (k8s-node) 用户跟集群角色(system:node )绑定:
我创建了一个k8s用户k8s-node,给k8s-node用户,授予集群权限(system:node ),让k8s-node用户具备管理运算节点的权限。所以kubectl通过使用 k8s-node 用户,在k8s集群中拥有system:node管理运算节点的权限。
[root@hdss7-21 conf]# cd /opt/kubernetes/server/bin/conf
[root@hdss7-21 conf]# vim k8s-node.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: k8s-node
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:node
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: k8s-node
解释:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: k8s-node
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole 做了一个集群角色绑定,让kind:User 中name:k8s-node这个用户,具备集群角色,这个集群角色叫system:node
name: system:node
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: k8s-node
资源:rbac建立权限也是一种资源,大致有apiVsersion、kind、metadata(元数据)下有名称name、roleRef、subjects
[root@hdss7-21 conf]# kubectl create -f k8s-node.yaml
clusterrolebinding.rbac.authorization.k8s.io/k8s-node created
[root@hdss7-21 conf]# kubectl get clusterrolebinding k8s-node
NAME AGE
k8s-node 40s
[root@hdss7-21 conf]# kubectl get clusterrolebinding k8s-node -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
creationTimestamp: "2020-10-13T12:52:31Z"
name: k8s-node
resourceVersion: "199975"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterrolebindings/k8s-node
uid: 35968595-30fe-4622-8a42-50f4a81f53f3
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:node
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: k8s-nodek8s-node.yaml 资源创建一次就行,他会自动把资源加载到etcd中,而我们只需要在hdss7-22用kubelet把配置文件拷贝过来
在hdss7-22上把hdss7-21的kubelet.kubeconfig拷贝过来:
[root@hdss7-22 cert]# cd /opt/kubernetes/server/bin/conf
[root@hdss7-22 conf]# scp hdss7-21:/opt/kubernetes/server/bin/conf/kubelet.kubeconfig ./试验:k8s-node.yaml 资源创建一次就行,如果在创建,报错说明资源已经存在
[root@hdss7-21 conf]# kubectl create -f k8s-node.yaml
Error from server (AlreadyExists): error when creating "k8s-node.yaml": clusterrolebindings.rbac.authorization.k8s.io "k8s-node" already exists[root@hdss7-21 conf]# kubectl apply -f k8s-node.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
clusterrolebinding.rbac.authorization.k8s.io/k8s-node configured
1.4. 装备pause镜像
kubectl在启动的时候,需要一个基础镜像,协助我们启动业务pod。
kubectl 在接收scheduler调度请求后,scheduler告诉kubectl在某个节点把对应的业务pod拉起来。由于k8s是基于docker的编排工具,所以其实kubectl 是按照资源配置清单,拉起一个什么样子的docker,所以kubectl 原理需要是去调度docker,让docker引擎把容器真正拉起来,但是拉时候必须有一个基础的小镜像,基础小镜像干什么用,小镜像跟要启动的docker业务容器进行了边车模式(可以理解为启动业务容器的时候,启动了一个小镜像的docker,启动了一个业务容器的docker,他俩在docker ps -a 看就是一个容器,但是他们内部资源是有共享、有不共享的)。让 kubectl 控制这个小镜像。先于我们业务容器起来,让他帮助我们给业务容器设置uts、nat、ipc, 他会先把命名空间占上,也就是业务容器还没有起来,我们的pod ip已经分配出来。镜像几kb。
将pause镜像放入到harbor私有仓库中,仅在 hdss7-200 操作:
[root@hdss7-200 certs]# docker image pull kubernetes/pause
docker.io/kubernetes/pause:latest
[root@hdss7-200 ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
kubernetes/pause latest f9d5de079539 6 years ago 240kB
[root@hdss7-200 ~]# docker image tag kubernetes/pause:latest harbor.od.com:180/public/pause:latest 给kubernetes/pause打一个标签,方便存入Harbor
[root@hdss7-200 ~]# docker login -u admin harbor.od.com:180
[root@hdss7-200 ~]# docker push harbor.od.com:180/public/pause:latestharbor 上传的镜像问题:
问题1:
由于更改了端口,所以在创建的时候提示是docker push harbor.od.com:180/public/IMAGE[:TAG]
问题2:
[root@hdss7-200 ~]# docker push harbor.od.com:180/public/pause:latest
The push refers to repository [harbor.od.com:180/public/pause]
Get https://harbor.od.com:180/v2/: http: server gave HTTP response to HTTPS client
问题原因:做hatbor的没有开启https,出现这问题的原因是:Docker自从1.3.X之后docker registry交互默认使用的是HTTPS,但是搭建私有镜像默认使用的是HTTP服务,所以与私有镜像交时出现以上错误。
解决方案:配置Docker加速器:增加"harbor.od.com:180",为什么是harbor.od.com:180不是10.4.7.200:180,由于/opt/harbor/harbor.yml hostname: harbor.od.com
[root@hdss7-200 harbor]# vi /etc/docker/daemon.json
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["10.4.7.200:180","registry.access.redhat.com","quay.io","harbor.od.com:180"],
"registry-mirrors": ["http://registry.docker-cn.com"],
"bip": "172.7.21.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}
修改好后重启docker 服务
systemctl daemon-reload
systemctl restart docker问题3:
[root@hdss7-200 certs]# docker push harbor.od.com:180/public/pause:latest
The push refers to repository [harbor.od.com:180/public/pause]
5f70bf18a086: Preparing
e16a89738269: Preparing
denied: requested access to the resource is denied
问题原因:拒绝对资源的访问请求
解决方案:登录harbor,注意是harbor.od.com:180
[root@hdss7-200 certs]# docker login harbor.od.com:180
[root@hdss7-200 certs]# docker push harbor.od.com:180/public/pause:latest
The push refers to repository [harbor.od.com:180/public/pause]
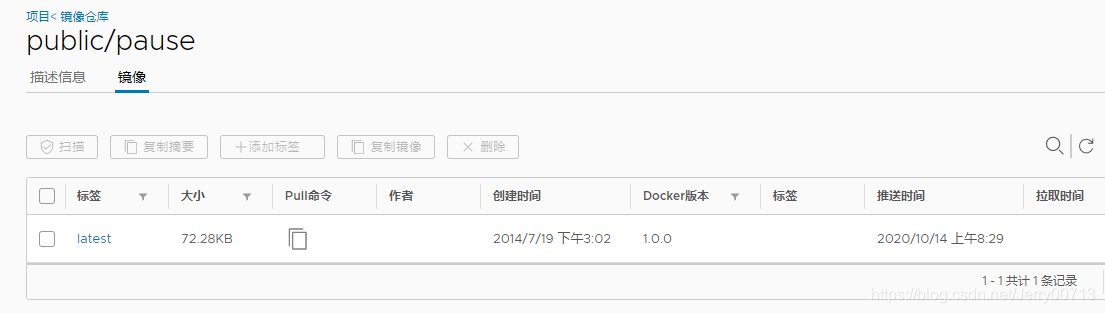
5f70bf18a086: Pushed
e16a89738269: Pushed
latest: digest: sha256:b31bfb4d0213f254d361e0079deaaebefa4f82ba7aa76ef82e90b4935ad5b105 size: 938
1.5. 创建kubelet启动脚本
在node节点创建脚本并启动kubelet,涉及服务器: hdss7-21 hdss7-22
[root@hdss7-21 ~]# vim /opt/kubernetes/server/bin/kubelet-startup.sh
#!/bin/sh
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/kubernetes/server/bin/kubelet \
--anonymous-auth=false \
--cgroup-driver systemd \
--cluster-dns 192.168.0.2 \
--cluster-domain cluster.local \
--runtime-cgroups=/systemd/system.slice \
--kubelet-cgroups=/systemd/system.slice \
--fail-swap-on="false" \
--client-ca-file ./cert/ca.pem \
--tls-cert-file ./cert/kubelet.pem \
--tls-private-key-file ./cert/kubelet-key.pem \
--hostname-override hdss7-21.host.com \
--image-gc-high-threshold 20 \
--image-gc-low-threshold 10 \
--kubeconfig ./conf/kubelet.kubeconfig \
--log-dir /data/logs/kubernetes/kube-kubelet \
--pod-infra-container-image harbor.od.com:180/public/pause:latest \
--root-dir /data/kubelet解释:
--anonymous-auth=false \ 不允许匿名登录,必须经过apiserver指挥我kubelet干活
--cgroup-driver systemd \ 我要跟docker 的cgroup-driver保持一致,docker也是systemd
--cluster-dns 192.168.0.2 \ 给一个固定cluster_ip
--cluster-domain cluster.local \ cluster.local配置
--runtime-cgroups=/systemd/system.slice \ 给cgroups做一些配置
--kubelet-cgroups=/systemd/system.slice \ 给cgroups做一些配置
--fail-swap-on="false" \ k8s在kubelet启动的时候默认是把运算节点上的swap关闭的。但一般都不关,交换分区有点用,而且当我在运算节点没有关闭swap分区,仍然正常启动不会报错
--client-ca-file ./cert/ca.pem \ 给启动脚本的根证书
--tls-cert-file ./cert/kubelet.pem \ 给启动脚本的kubelet证书
--tls-private-key-file ./cert/kubelet-key.pem \ kubelet作为服务端需要的根证书、私钥
--hostname-override hdss7-21.host.com \ 给他的主机名
--image-gc-high-threshold 20 \
--image-gc-low-threshold 10 \
--kubeconfig ./conf/kubelet.kubeconfig \ kubeconfig指定的是./conf/kubelet.kubeconfig
--log-dir /data/logs/kubernetes/kube-kubelet \ 待会创建出来日志
--pod-infra-container-image harbor.od.com:180/public/pause:latest \ k8s使用pause镜像,kubelet干脏活累活,启动业务容器时候,必须给业务容器初始化网络空间查看dockercgroup-driver
[root@hdss7-22 ~]# cat /etc/docker/daemon.json
"exec-opts": ["native.cgroupdriver=systemd"]
[root@hdss7-21 ~]# chmod a+x /opt/kubernetes/server/bin/kubelet-startup.sh
[root@hdss7-21 ~]# mkdir -p /data/logs/kubernetes/kube-kubelet /data/kubelet
[root@hdss7-21 ~]# touch /data/logs/kubernetes/kube-kubelet/kubelet.stdout.log
hdss7-22配置:
[root@hdss7-22 ~]# vim /opt/kubernetes/server/bin/kubelet-startup.sh
#!/bin/sh
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/kubernetes/server/bin/kubelet \
--anonymous-auth=false \
--cgroup-driver systemd \
--cluster-dns 192.168.0.2 \
--cluster-domain cluster.local \
--runtime-cgroups=/systemd/system.slice \
--kubelet-cgroups=/systemd/system.slice \
--fail-swap-on="false" \
--client-ca-file ./cert/ca.pem \
--tls-cert-file ./cert/kubelet.pem \
--tls-private-key-file ./cert/kubelet-key.pem \
--hostname-override hdss7-22.host.com \
--image-gc-high-threshold 20 \
--image-gc-low-threshold 10 \
--kubeconfig ./conf/kubelet.kubeconfig \
--log-dir /data/logs/kubernetes/kube-kubelet \
--pod-infra-container-image harbor.od.com:180/public/pause:latest \
--root-dir /data/kubelet
[root@hdss7-22 ~]# chmod a+x /opt/kubernetes/server/bin/kubelet-startup.sh
[root@hdss7-22 ~]# mkdir -p /data/logs/kubernetes/kube-kubelet /data/kubelet
[root@hdss7-22 ~]# touch /data/logs/kubernetes/kube-kubelet/kubelet.stdout.log
创建supervisor 配置
涉及服务器: hdss7-21 hdss7-22
[root@hdss7-21 ~]# vim /etc/supervisord.d/kube-kubelet.ini
[program:kube-kubelet-7-21]
command=/opt/kubernetes/server/bin/kubelet-startup.sh
numprocs=1
directory=/opt/kubernetes/server/bin
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/kubernetes/kube-kubelet/kubelet.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_events_enabled=false
[root@hdss7-21 conf]# supervisorctl update
[root@hdss7-21 conf]# supervisorctl status
etcd-server-7-21 RUNNING pid 1375, uptime 3:38:32
kube-apiserver-7-21 RUNNING pid 1393, uptime 3:38:32
kube-controller-manager-7-21 RUNNING pid 2986, uptime 1:56:10
kube-kubelet-7-21 RUNNING pid 3264, uptime 0:00:31
kube-scheduler-7-21 RUNNING pid 3015, uptime 1:49:00如果kube-kubelet-7-21 失败查看 /data/logs/kubernetes/kube-kubelet/kubelet.stdout.log
查看node节点是否加到节点里面:
[root@hdss7-21 conf]# kubectl get node NAME STATUS ROLES AGE VERSION hdss7-21.host.com Ready <none> 40m v1.15.2 hdss7-22.host.com Ready <none> 4m54s v1.15.2 [root@hdss7-21 conf]# kubectl get nodes NAME STATUS ROLES AGE VERSION hdss7-21.host.com Ready <none> 40m v1.15.2 hdss7-22.host.com Ready <none> 5m3s v1.15.2问题:发现 ROLES 都是 <none> ,如何给加角色
1.6. 修改节点角色(只是打标签,好看)
打标签有什么用:
过滤相应的节点,假如生产环境,可以主控节点跟node运算节点物理分开部署,
比如:主控节点部署apiserver,还有controller-manager、kube-scheduler都用容器镜像的方式托管到K8S。但主控节点还继续装了kubectl ,部署了kubectl 就说明他具有node节点的功能,可以把业务容器调度到这个节点上。然而不想主控节点运行业务容器,这时候用到标签选择器,给主控节点标签选择器打一个污点,让不能容忍这个污点的资源,无法通过scheduler调度到这个节点。
涉及服务器: hdss7-21、hdss7-22 随意一台node节点
[root@hdss7-21 conf]# kubectl get node
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready <none> 40m v1.15.2
hdss7-22.host.com Ready <none> 4m54s v1.15.2使用 kubectl get nodes 后,Node节点角色为空,如果对其修改:
[root@hdss7-21 conf]# kubectl label node hdss7-21.host.com node-role.kubernetes.io/master=
node/hdss7-21.host.com labeled
[root@hdss7-21 conf]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready master 44m v1.15.2 # 发现7-21 ROLES已经是master
hdss7-22.host.com Ready <none> 9m13s v1.15.2此文章设计hdss7-21、hdss7-22 既做主控又做运算节点,所以可以打(master,node)
[root@hdss7-21 conf]# kubectl label node hdss7-21.host.com node-role.kubernetes.io/node=
node/hdss7-21.host.com labeled
[root@hdss7-21 conf]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready master,node 45m v1.15.2
hdss7-22.host.com Ready <none> 10m v1.15.2
[root@hdss7-21 conf]# kubectl label node hdss7-22.host.com node-role.kubernetes.io/master=
node/hdss7-22.host.com labeled
[root@hdss7-21 conf]# kubectl label node hdss7-22.host.com node-role.kubernetes.io/node=
node/hdss7-22.host.com labeled
[root@hdss7-21 conf]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready master,node 46m v1.15.2
hdss7-22.host.com Ready master,node 10m v1.15.2
[root@hdss7-21 conf]# 2. kube-proxy部署 (集群网络跟pod网络如何通信)
2.1. 签发证书
证书签发在 hdss7-200 操作
[root@hdss7-200 ~]# cd /opt/certs/
[root@hdss7-200 certs]# vim kube-proxy-csr.json # CN 其实是k8s中的角色
{
"CN": "system:kube-proxy",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "beijing",
"L": "beijing",
"O": "od",
"OU": "ops"
}
]
}
[root@hdss7-200 certs]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=client kube-proxy-csr.json |cfssl-json -bare kube-proxy-client
注意:参数profile后接client(-profile=client) ,因为kube-proxy的client 证书跟之前配置kubelet 的client证书不通用,原因是"CN": "system:kube-proxy", CN变了
[root@hdss7-200 certs]# ll
-rw-r--r-- 1 root root 1005 10月 19 18:58 kube-proxy-client.csr
-rw------- 1 root root 1675 10月 19 18:58 kube-proxy-client-key.pem
-rw-r--r-- 1 root root 1375 10月 19 18:58 kube-proxy-client.pem
-rw-r--r-- 1 root root 267 10月 19 18:53 kube-proxy-csr.json
分发证书:
[rot@hdss7-200 certs]# scp kube-proxy-client-key.pem kube-proxy-client.pem hdss7-21:/opt/kubernetes/server/bin/certs/
[rot@hdss7-200 certs]# scp kube-proxy-client-key.pem kube-proxy-client.pem hdss7-22:/opt/kubernetes/server/bin/certs/或者scp,在hdss7-21,hdss7-22
[root@hdss7-21 bin]# cd /opt/kubernetes/server/bin/cert/
[root@hdss7-21 bin]# scp 10.4.7.200:/opt/certs/kube-proxy-client-key.pem ./
[root@hdss7-21 bin]# scp 10.4.7.200:/opt/certs/kube-proxy-client.pem ./
2.2. 创建kube-proxy配置
在所有node节点任选其一创建,涉及服务器:hdss7-21 或者 hdss7-22
[root@hdss7-21 bin]# cd /opt/kubernetes/server/bin/conf/ # 注意:要在conf下
[root@hdss7-21 ~]# kubectl config set-cluster myk8s \
--certificate-authority=/opt/kubernetes/server/bin/cert/ca.pem \
--embed-certs=true \
--server=https://10.4.7.10:7443 \
--kubeconfig=/opt/kubernetes/server/bin/conf/kube-proxy.kubeconfig
返回Cluster "myk8s" set.代表成功
[root@hdss7-21 ~]# kubectl config set-credentials kube-proxy \
--client-certificate=/opt/kubernetes/server/bin/cert/kube-proxy-client.pem \
--client-key=/opt/kubernetes/server/bin/cert/kube-proxy-client-key.pem \
--embed-certs=true \
--kubeconfig=/opt/kubernetes/server/bin/conf/kube-proxy.kubeconfig
返回User "kube-proxy" set.代表成功
[root@hdss7-21 ~]# kubectl config set-context myk8s-context \
--cluster=myk8s \
--user=kube-proxy \
--kubeconfig=/opt/kubernetes/server/bin/conf/kube-proxy.kubeconfig
返回Context "myk8s-context" created.代表成功
[root@hdss7-21 ~]# kubectl config use-context myk8s-context --kubeconfig=/opt/kubernetes/server/bin/conf/kube-proxy.kubeconfig
返回Switched to context "myk8s-context".代表成功
注:思考问题,在部署kubectl的时候/opt/kubernetes/server/bin/conf/k8s-node.yaml 中进行了ClusterRoleBinding集群角色绑定,把k8s资源跟账户绑定,kubectl才能有能力调度k8s资源,这里为什么没有集群角色绑定?
是因为在配置证书的时候,声明了 "CN": "system:kube-proxy", 其中CN是kube-proxy,在k8s资源中,CN对应的就是角色,而kube-proxy恰巧使用的是kube-proxy角色(--user=kube-proxy)。
在hdss7-22上把hdss7-21的kube-proxy.kubeconfig拷贝过来:
[root@hdss7-22 cert]# cd /opt/kubernetes/server/bin/conf
[root@hdss7-22 conf]# scp hdss7-21:/opt/kubernetes/server/bin/conf/kube-proxy.kubeconfig ./2.3. 加载ipvs模块,使得让kube-proxy使用ipvs调度算法
涉及服务器:hdss7-21 ,hdss7-22
kube-proxy 共有3种流量调度模式,分别是 namespace(做大量用户态跟内核太态互,太费资源),iptables(标准的,但是不科学,没有七层调度),ipvs (其中ipvs性能最好启动ipvs内核模块脚本)
[root@hdss7-21 ~]# lsmod | grep ip_vs # 查看ipvs模块
[root@hdss7-21 ~]# 空代表没有开启开启ipvs模块
开启方式一:
[root@hdss7-21 ~]# for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
ip_vs_dh
ip_vs_ftp
ip_vs
ip_vs_lblc
ip_vs_lblcr
ip_vs_lc
ip_vs_nq
ip_vs_pe_sip
ip_vs_rr
ip_vs_sed
ip_vs_sh
ip_vs_wlc
ip_vs_wrr
[root@hdss7-21 ~]#
开启方式二:
[root@hdss7-22 ~]# vi ipvs.sh
ipvs_mods_dir="/usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs"
for i in $(ls $ipvs_mods_dir|grep -o "^[^.]*")
do
/sbin/modinfo -F filename $i &>/dev/null
if [ $? -eq 0 ];then
/sbin/modprobe $i
fi
done
[root@hdss7-22 ~]# chmod a+x ipvs.sh
[root@hdss7-22 ~]# ./ipvs.sh 查看ipvs模块
[root@hdss7-21 ~]# lsmod | grep ip_vs # 查看ipvs模块(一个算法一个模块)
ip_vs_wrr 12697 0
ip_vs_wlc 12519 0
ip_vs_sh 12688 0
ip_vs_sed 12519 0 sed()
ip_vs_rr 12600 0
ip_vs_pe_sip 12740 0
nf_conntrack_sip 33780 1 ip_vs_pe_sip
ip_vs_nq 12516 0
ip_vs_lc 12516 0
ip_vs_lblcr 12922 0
ip_vs_lblc 12819 0
ip_vs_ftp 13079 0
ip_vs_dh 12688 0
ip_vs 145497 24 ip_vs_dh,ip_vs_lc,ip_vs_nq,ip_vs_rr,ip_vs_sh,ip_vs_ftp,ip_vs_sed,ip_vs_wlc,ip_vs_wrr,ip_vs_pe_sip,ip_vs_lblcr,ip_vs_lblc
nf_nat 26583 3 ip_vs_ftp,nf_nat_ipv4,nf_nat_masquerade_ipv4
nf_conntrack 139264 8 ip_vs,nf_nat,nf_nat_ipv4,xt_conntrack,nf_nat_masquerade_ipv4,nf_conntrack_netlink,nf_conntrack_sip,nf_conntrack_ipv4
libcrc32c 12644 4 xfs,ip_vs,nf_nat,nf_conntrack
https://blog.youkuaiyun.com/Jerry00713/article/details/109221616
https://blog.youkuaiyun.com/Jerry00713/article/details/109221616
解释:
静态调度算法:一般常用
ip_vs_rr中rr: 轮叫调度(Round-Robin Scheduling)
ip_vs_wrr中wrr: 加权轮叫调度(Weighted Round-Robin Scheduling)
ip_vs_lc中lc: 最小连接调度(Least-Connection Scheduling)
ip_vs_wlc中wlc: 加权最小连接调度(Weighted Least-Connection Scheduling)
动态算法:
ip_vs_lblc、ip_vs_lblcr、ip_vs_dh、ip_vs_sh 比较少用,一般只用于cdn纯静态的。ip_vs_sed、ip_vs_nq 常用
ip_vs_lblc中lblc: 基于局部性的最少链接(Locality-Based Least Connections Scheduling)
ip_vs_lblcr中lblcr: 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling)
ip_vs_dh中dh: 目标地址散列调度(Destination Hashing Scheduling)
ip_vs_sh中sh: 源地址散列调度(Source Hashing Scheduling)
ip_vs_sed中sed: 最短预期延时调度(Shortest Expected Delay Scheduling)
ip_vs_nq中nq: 不排队调度(Never Queue Scheduling)2.4. 创建kube-proxy启动脚本
涉及服务器:hdss7-21 ,hdss7-22
[root@hdss7-21 ~]# vim /opt/kubernetes/server/bin/kube-proxy-startup.sh
#!/bin/sh
WORK_DIR=$(dirname $(readlink -f $0))
[ $? -eq 0 ] && cd $WORK_DIR || exit
/opt/kubernetes/server/bin/kube-proxy \
--cluster-cidr 172.7.0.0/16 \
--hostname-override hdss7-21.host.com \
--proxy-mode=ipvs \
--ipvs-scheduler=nq \
--kubeconfig ./conf/kube-proxy.kubeconfig
解释:
--cluster-cidr 172.7.0.0/16 # 172.7.0.0/16 运算节点的范围
--proxy-mode=ipvs \ # 使用调度规则,如果使用iptables,只能用rr
--ipvs-scheduler=nq \ # 使用那种轮训
[root@hdss7-21 ~]# chmod a+x /opt/kubernetes/server/bin/kube-proxy-startup.sh
[root@hdss7-21 ~]# mkdir -p /data/logs/kubernetes/kube-proxy
[root@hdss7-21 ~]# vim /etc/supervisord.d/kube-proxy.ini
[program:kube-proxy-7-21]
command=/opt/kubernetes/server/bin/kube-proxy-startup.sh
numprocs=1
directory=/opt/kubernetes/server/bin
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/kubernetes/kube-proxy/proxy.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=5
stdout_capture_maxbytes=1MB
stdout_events_enabled=false[root@hdss7-21 ~]# supervisorctl update
[root@hdss7-21 cert]# supervisorctl status
etcd-server-7-21 RUNNING pid 11746, uptime 0:05:44
kube-apiserver-7-21 RUNNING pid 11747, uptime 0:05:44
kube-controller-manager-7-21 RUNNING pid 11748, uptime 0:05:44
kube-kubelet-7-21 RUNNING pid 11745, uptime 0:05:44
kube-proxy-7-21 RUNNING pid 11749, uptime 0:05:44
kube-scheduler-7-21 RUNNING pid 11751, uptime 0:05:44如果报错查看日志:tail -200 /data/logs/kubernetes/kube-proxy/proxy.stdout.log
如报错:E1026 18:38:28.615912 1040 reflector.go:125] k8s.io/client-go/informers/factory.go:133: Failed to list *v1.Service: Get https://10.4.7.10:7443/api/v1/services?labelSelector=%21service.kubernetes.io%2Fservice-proxy-name&limit=500&resourceVersion=0: dial tcp 10.4.7.10:7443: connect: no route to host 说不能连接10.4.7.10:7443,发现keepalived 挂了。
通过ipvsadm查看调度算法
[root@hdss7-21 cert ]# yum install -y ipvsadm
[root@hdss7-21 ~]# grep -i "Using ipvs" /data/logs/kubernetes/kube-proxy/proxy.stdout.log # 提示如下内容,说明使用了ipvs
I1026 19:00:26.422744 128714 server_others.go:170] Using ipvs Proxier.
[root@hdss7-22 conf]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 16h
[root@hdss7-21 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.1:443 nq # 默认把k8s集群网络(192.168.0.1:443) 反代到后端两个运算节点node的apiserver服务。说明cluster_ip跟node节点的ip绑定
-> 10.4.7.21:6443 Masq 1 0 0
-> 10.4.7.22:6443 Masq 1 0 0
kube-proxy维护了(节点网络、pod网络、cluster网络),这三种网络之间如何进行通信2.5 集群验证:
[root@hdss7-21 etc]# kubectl get cs # 查看etcd正常
NAME STATUS MESSAGE ERROR
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
controller-manager Healthy ok
etcd-1 Healthy {"health": "true"}
scheduler Healthy ok
[root@hdss7-21 etc]# kubectl get node # 查看node正常
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready master,node 12d v1.15.2
hdss7-22.host.com Ready master,node 12d v1.15.2创建一个资源配置清单,导入一个nginx ,启动pod控制器
[root@hdss7-21 ]#cd
[root@hdss7-21 ]#vim nginx-ds.yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nginx-ds
spec:
template:
metadata:
labels:
app: nginx-ds
spec:
containers:
- name: my-nginx
image: harbor.od.com:180/public/nginx:v1.7.9
ports:
- containerPort: 80 [root@hdss7-21 etc]# kubectl create -f nginx-ds.yaml
daemonset.extensions/nginx-ds created # 提示创建成功
查看状态:
一开始启动pod等待一段时间为ContainerCreating,若一直没有Running,会报错为异常
[root@hdss7-21 etc]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-ds-sxcwn 1/1 ContainerCreating 0 1min
nginx-ds-v66s4 1/1 ContainerCreating 0 1min
[root@hdss7-21 etc]# kubectl get pods # 正常
NAME READY STATUS RESTARTS AGE
nginx-ds-sxcwn 1/1 Running 0 11h
nginx-ds-v66s4 1/1 Running 0 11h如果一直没有Running异常排查:
[root@hdss7-21 etc]# kubectl describe pod nginx-ds-sxcwn # 通过describe查看容器启动详情
Name: nginx-ds-sxcwn
Namespace: default
Priority: 0
Node: hdss7-22.host.com/10.4.7.22
Start Time: Mon, 26 Oct 2020 21:03:38 +0800
Labels: app=nginx-ds
..........
Tolerations: node.kubernetes.io/disk-pressure:NoSchedule
node.kubernetes.io/memory-pressure:NoSchedule
node.kubernetes.io/not-ready:NoExecute
node.kubernetes.io/pid-pressure:NoSchedule
node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unschedulable:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedCreatePodSandBox 2m21s (x3065 over 11h) kubelet, hdss7-22.host.com Failed create pod sandbox: rpc error: code = Unknown desc = failed pulling image "harbor.od.com:180/public/pause:latest": Error response from daemon: Get https://harbor.od.com:180/v2/: http: server gave HTTP response to HTTPS client 说明镜像有问题测试本地pod拉取,一样的报错:
[root@hdss7-21 etc]# docker pull harbor.od.com:180/public/nginx:v1.7.9
解决方案:配置Docker加速器:增加"harbor.od.com:180",为什么是harbor.od.com:180不是10.4.7.200:180,由于/opt/harbor/harbor.yml 中 hostname: harbor.od.com
[root@hdss7-200 harbor]# vi /etc/docker/daemon.json
{
"graph": "/data/docker",
"storage-driver": "overlay2",
"insecure-registries": ["10.4.7.200:180","registry.access.redhat.com","quay.io","harbor.od.com:180"],
"registry-mirrors": ["http://registry.docker-cn.com"],
"bip": "172.7.21.1/24",
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}
修改好后重启docker 服务
systemctl daemon-reload
systemctl restart docker
[root@hdss7-21 etc]# kubectl get pods -o wide 查看详情
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READIKNESS GATES
nginx-ds-sxcwn 1/1 Running 0 29s 172.7.22.2 hdss7-22.host.com <none> <none>
nginx-ds-v66s4 1/1 Running 0 29s 172.7.21.2 hdss7-21.host.com <none> <none>
[root@hdss7-21 ~]# curl -I 172.7.21.2 # 在hdss7-21上去curl 172.7.21.2是可以通,因为172.7.21是在hdss7-21上启动的容器
HTTP/1.1 200 OK
Server: nginx/1.7.9
Date: Sun, 13 Mar 2022 04:13:57 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 23 Dec 2014 16:25:09 GMT
Connection: keep-alive
ETag: "54999765-264"
Accept-Ranges: bytes
# 在hdss7-21上去curl 172.7.22.2是不可以通,因为172.7.22是在hdss7-22上启动的容器
[root@hdss7-21 ~]# curl -I 172.7.21.2
HTTP/1.1 200 OK Server: nginx/1.17.6 Date: Tue, 07 Jan 2020 14:28:46 GMT Content-Type: text/html Content-Length: 612 Last-Modified: Tue, 19 Nov 2019 12:50:08 GMT Connection: keep-alive ETag: "5dd3e500-264" Accept-Ranges: bytes 但是无法访问172.7.22.2,缺少网络插件,无法跨节点通信。跨宿主机的容器如何访问
[root@hdss7-21 ~]# curl -I 172.7.22.2


















 5747
5747




 到【灌水乐园】发言
到【灌水乐园】发言







